Graph-Conditioned Mixture of Graph Neural Network Experts for Traffic Forecasting
Pith reviewed 2026-06-29 08:24 UTC · model grok-4.3
The pith
A lightweight graph-conditioned router combines frozen spatio-temporal GNN experts to give each road node its own mixture, raising MAE accuracy while training only ~17K parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
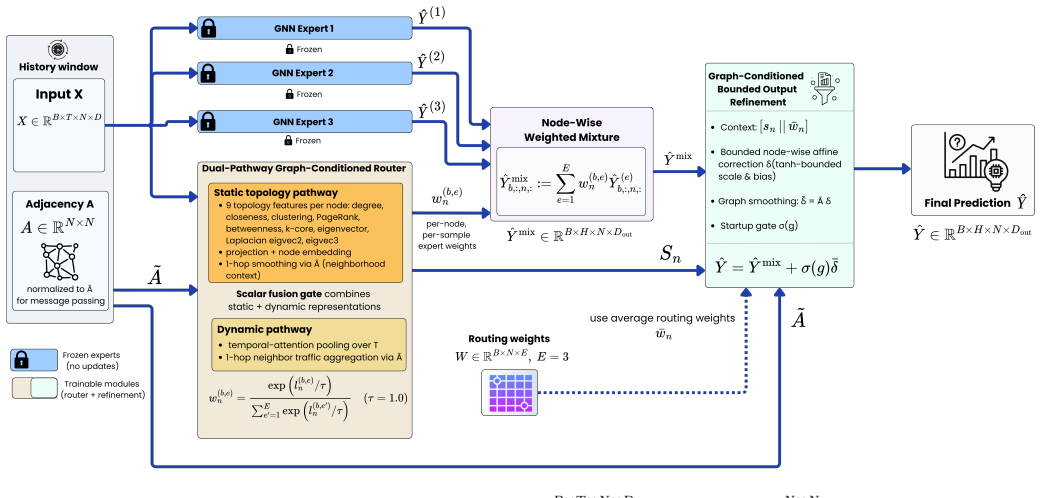
GC-MoE assigns each node a personalized convex combination of frozen forecasting experts; the combination is produced by a graph-conditioned router that receives both the adjacency structure and the recent traffic window, so that only the router parameters (~17 K) are trained on top of 1.5 M frozen expert weights, yielding lower MAE than a static ensemble on four standard benchmarks.
What carries the argument
The input-aware, spatially contextualized router that maps graph topology and recent traffic observations to per-node expert weights.
If this is right
- Road segments can receive different expert weightings without retraining the full forecasting stack.
- Total trainable parameters remain low because only the routing module is updated.
- The same router architecture can be added on top of any set of pretrained spatio-temporal GNNs.
- An optional bounded output refinement layer can be stacked without changing the expert pool.
Where Pith is reading between the lines
- If the router can be made to work with even fewer parameters, the approach scales to larger sensor networks.
- The method suggests a general pattern for other graph forecasting domains where local dynamics differ markedly.
- Replacing the frozen experts with a larger and more diverse pool could further improve accuracy at the same routing cost.
Load-bearing premise
The frozen experts already contain enough distinct traffic behaviors that a small router can usefully recombine them without any further training of the experts themselves.
What would settle it
An end-to-end trained single model that reaches the same or lower MAE on the four benchmarks while using comparable total parameters and training time would falsify the claim that the frozen-expert-plus-router design is advantageous.
Figures
read the original abstract
Spatio-temporal forecasting on sensor graphs is commonly tackled with a single backbone architecture applied uniformly across all nodes, although graph regions can exhibit different dynamics. Road segments differ in functional class, structure, and traffic behavior, suggesting that node-wise expert specialization can be useful. We propose GC-MoE, a graph-conditioned mixture of experts framework that assigns each node a personalized combination of frozen forecasting experts based on graph topology and the recent traffic input window. GC-MoE combines frozen pretrained spatio-temporal GNN experts with an input-aware, spatially contextualized router while training only a lightweight routing module. We also study a bounded graph-conditioned output refinement layer as an optional extension and include node-adaptive ST-LoRA adapters only as an ablation diagnostic. Across four standard benchmarks (PEMS04, PEMS07, METR-LA, and PEMS-BAY), GC-MoE improves MAE over a zero-parameter ensemble baseline, with competitive RMSE and MAPE, while training only ~17K parameters on top of 1.5M frozen expert weights. The implementation is available at https://github.com/Ahghaffari/gc_moe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GC-MoE, a graph-conditioned mixture of experts framework for spatio-temporal traffic forecasting on sensor graphs. It freezes multiple pretrained spatio-temporal GNN experts (totaling ~1.5M parameters) and trains only a lightweight (~17K-parameter) input-aware, spatially contextualized router that assigns node-specific combinations based on graph topology and recent traffic windows. An optional bounded graph-conditioned output refinement layer is studied, with node-adaptive ST-LoRA adapters included only as an ablation. On the PEMS04, PEMS07, METR-LA, and PEMS-BAY benchmarks the method reports MAE gains over a zero-parameter ensemble baseline while keeping RMSE and MAPE competitive.
Significance. If the empirical results hold, the work demonstrates a parameter-efficient route to node-wise specialization in heterogeneous traffic graphs by routing among frozen experts rather than fine-tuning them. The public GitHub implementation is a clear strength that enables direct verification and extension.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim of MAE improvement over the zero-parameter ensemble baseline is stated without quantitative deltas, error bars, statistical tests, baseline construction details, or data-split specifications; these omissions are load-bearing because the soundness of the reported gains cannot be assessed from the given information.
- [§3 and §4] §3 (Method) and §4: the router's utility rests on the frozen experts producing meaningfully diverse node-level forecasts; no pairwise output correlations, per-node residual variances, or other diversity statistics are reported, leaving open the possibility that gains arise only from reweighting near-identical predictions rather than from learned specialization.
minor comments (1)
- [Abstract] The abstract refers to the bounded refinement layer and ST-LoRA ablation; ensure the main text explicitly states their relationship to the core GC-MoE pipeline and whether they are used in the primary reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point-by-point below and will incorporate revisions to strengthen the empirical presentation and analysis.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim of MAE improvement over the zero-parameter ensemble baseline is stated without quantitative deltas, error bars, statistical tests, baseline construction details, or data-split specifications; these omissions are load-bearing because the soundness of the reported gains cannot be assessed from the given information.
Authors: We agree that the abstract and §4 should include quantitative MAE deltas, error bars from multiple runs, statistical tests, baseline construction details, and data-split specifications to allow proper assessment of the gains. In the revised manuscript we will add these elements, reporting specific improvements (with standard deviations), p-values or similar tests where applicable, and explicit descriptions of the zero-parameter ensemble and the standard PEMS/METR data splits used. revision: yes
-
Referee: [§3 and §4] §3 (Method) and §4: the router's utility rests on the frozen experts producing meaningfully diverse node-level forecasts; no pairwise output correlations, per-node residual variances, or other diversity statistics are reported, leaving open the possibility that gains arise only from reweighting near-identical predictions rather than from learned specialization.
Authors: We concur that evidence of expert diversity is necessary to substantiate the router's value. We will revise §4 to include an analysis of pairwise output correlations across experts and per-node residual variances on the validation sets, demonstrating that the frozen experts produce sufficiently distinct forecasts to justify node-specific routing. revision: yes
Circularity Check
No circularity: empirical router training on frozen experts
full rationale
The paper presents GC-MoE as a training procedure that freezes 1.5M-parameter pretrained ST-GNN experts and trains only a ~17K-parameter graph-conditioned router on standard benchmarks. Performance claims rest on reported MAE/RMSE/MAPE numbers rather than any derivation or equation that reduces the output to the inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing; the router is learned separately from the experts. This is a standard empirical setup with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained spatio-temporal GNN experts capture sufficiently diverse dynamics across different road segments.
invented entities (1)
-
Graph-conditioned router
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
Y . Li, R. Yu, C. Shahabi, and Y . Liu, “Diffusion convolutional re- current neural network: Data-driven traffic forecasting,”arXiv preprint arXiv:1707.01926, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting
B. Yu, H. Yin, and Z. Zhu, “Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting,”arXiv preprint arXiv:1709.04875, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Graph WaveNet for Deep Spatial-Temporal Graph Modeling
Z. Wu, S. Pan, G. Long, J. Jiang, and C. Zhang, “Graph wavenet for deep spatial-temporal graph modeling,”arXiv preprint arXiv:1906.00121, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[4]
Spectral temporal graph neural network for multivariate time-series forecasting,
D. Cao, Y . Wang, J. Duan, C. Zhang, X. Zhu, C. Huang, Y . Tong, B. Xu, J. Bai, J. Tonget al., “Spectral temporal graph neural network for multivariate time-series forecasting,”Advances in neural information processing systems, vol. 33, pp. 17 766–17 778, 2020
2020
-
[5]
Stm-graph: A python framework for spatio-temporal mapping and graph neural network predictions,
A. Ghaffari, H. Nguyen, L. Lov ´en, and E. Gilman, “Stm-graph: A python framework for spatio-temporal mapping and graph neural network predictions,” inProceedings of the 34th ACM International Conference on Information and Knowledge Management, 2025, pp. 6377–6381
2025
-
[6]
Adaptive graph convolutional recurrent network for traffic forecasting,
L. Bai, L. Yao, C. Li, X. Wang, and C. Wang, “Adaptive graph convolutional recurrent network for traffic forecasting,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 17 804–17 815
2020
-
[7]
Ensemble methods in machine learning,
T. G. Dietterich, “Ensemble methods in machine learning,” inInterna- tional workshop on multiple classifier systems. Springer, 2000, pp. 1–15
2000
-
[8]
Adaptive mixtures of local experts,
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,”Neural computation, vol. 3, no. 1, pp. 79–87, 1991
1991
-
[9]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,”arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
2022
-
[11]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[12]
St-lora: Low-rank adaptation for spatio-temporal forecasting,
W. Ruan, W. Chen, X. Dang, J. Zhou, W. Li, X. Liu, and Y . Liang, “St-lora: Low-rank adaptation for spatio-temporal forecasting,” inJoint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2025, pp. 345–361
2025
-
[13]
Pdformer: Propagation delay-aware dynamic long-range transformer for traffic flow prediction,
J. Jiang, C. Han, W. X. Zhao, and J. Wang, “Pdformer: Propagation delay-aware dynamic long-range transformer for traffic flow prediction,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 4, 2023, pp. 4365–4373
2023
-
[14]
Spatio-temporal adaptive embedding makes vanilla transformer sota for traffic forecasting,
H. Liu, Z. Dong, R. Jiang, J. Deng, J. Deng, Q. Chen, and X. Song, “Spatio-temporal adaptive embedding makes vanilla transformer sota for traffic forecasting,” inProceedings of the 32nd ACM international conference on information and knowledge management, 2023, pp. 4125– 4129
2023
-
[15]
Bigst: Linear complexity spatio-temporal graph neural network for traffic forecasting on large-scale road networks,
J. Han, W. Zhang, H. Liu, T. Tao, N. Tan, and H. Xiong, “Bigst: Linear complexity spatio-temporal graph neural network for traffic forecasting on large-scale road networks,”Proceedings of the VLDB Endowment, vol. 17, no. 5, pp. 1081–1090, 2024
2024
-
[16]
Unist: A prompt-empowered universal model for urban spatio-temporal prediction,
Y . Yuan, J. Ding, J. Feng, D. Jin, and Y . Li, “Unist: A prompt-empowered universal model for urban spatio-temporal prediction,” inProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, 2024, pp. 4095–4106
2024
-
[17]
Mixture-of-experts with expert choice routing,
Y . Zhou, T. Lei, H. Liu, N. Du, Y . Huang, V . Zhao, A. M. Dai, Q. V . Le, J. Laudonet al., “Mixture-of-experts with expert choice routing,” Advances in Neural Information Processing Systems, vol. 35, pp. 7103– 7114, 2022
2022
-
[18]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bam- ford, D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressandet al., “Mixtral of experts,”arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Deepseekmoe: Towards ultimate expert special- ization in mixture-of-experts language models,
D. Dai, C. Deng, C. Zhao, R. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y . Wuet al., “Deepseekmoe: Towards ultimate expert special- ization in mixture-of-experts language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 1280–1297
2024
-
[20]
Branch-train-mix: Mixing expert llms into a mixture-of-experts llm,
S. Sukhbaatar, O. Golovneva, V . Sharma, H. Xu, X. V . Lin, B. Rozi `ere, J. Kahn, D. Li, W.-t. Yih, J. Westonet al., “Branch-train-mix: Mixing expert llms into a mixture-of-experts llm,”arXiv preprint arXiv:2403.07816, 2024
-
[21]
From sparse to soft mixtures of experts,
J. Puigcerver, C. Riquelme Ruiz, B. Mustafa, and N. Houlsby, “From sparse to soft mixtures of experts,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 28 435–28 445
2024
-
[22]
Testam: A time-enhanced spatio-temporal attention model with mixture of experts,
H. Lee and S. Ko, “Testam: A time-enhanced spatio-temporal attention model with mixture of experts,”arXiv preprint arXiv:2403.02600, 2024
-
[23]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,”Advances in neural information processing systems, vol. 36, pp. 10 088–10 115, 2023
2023
-
[24]
Dora: Weight-decomposed low-rank adap- tation,
S.-Y . Liu, C.-Y . Wang, H. Yin, P. Molchanov, Y .-C. F. Wang, K.-T. Cheng, and M.-H. Chen, “Dora: Weight-decomposed low-rank adap- tation,” inForty-first International Conference on Machine Learning, 2024
2024
-
[25]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Q. Zhang, M. Chen, A. Bukharin, N. Karampatziakis, P. He, Y . Cheng, W. Chen, and T. Zhao, “Adalora: Adaptive budget allocation for parameter-efficient fine-tuning,”arXiv preprint arXiv:2303.10512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Loramoe: Alleviating world knowledge forgetting in large language models via moe-style plugin,
S. Dou, E. Zhou, Y . Liu, S. Gao, W. Shen, L. Xiong, Y . Zhou, X. Wang, Z. Xi, X. Fanet al., “Loramoe: Alleviating world knowledge forgetting in large language models via moe-style plugin,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 1932–1945
2024
-
[27]
Attention based spatial- temporal graph convolutional networks for traffic flow forecasting,
S. Guo, Y . Lin, N. Feng, C. Song, and H. Wan, “Attention based spatial- temporal graph convolutional networks for traffic flow forecasting,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 922–929
2019
-
[28]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.