Measuring, Localizing, and Ablating Alignment Signatures in LLMs
Pith reviewed 2026-06-29 08:05 UTC · model grok-4.3
The pith
Post-training creates a localized AI-like stylistic signature in LLMs that ablation can remove.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
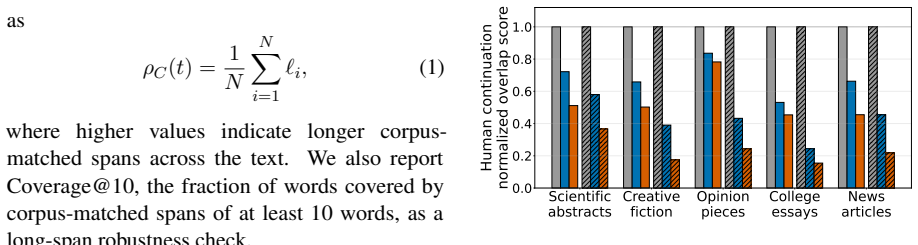
Post-training alignment introduces or amplifies AI-like stylistic regularities that appear as a consistent direction in the residual between aligned-model and base-model activations; ablating this direction during decoding reduces AI-detector scores while preserving relevance and coherence.
What carries the argument
PASTA (Post-training Alignment Signature Targeted Ablation), which estimates an alignment signature vector from aligned-minus-base activation residuals and subtracts a scaled version of that vector from hidden states at each decoding step.
If this is right
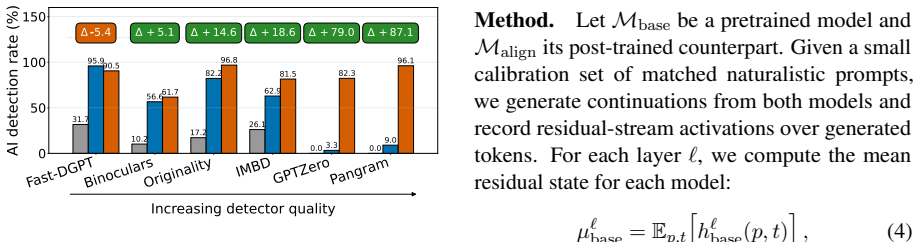
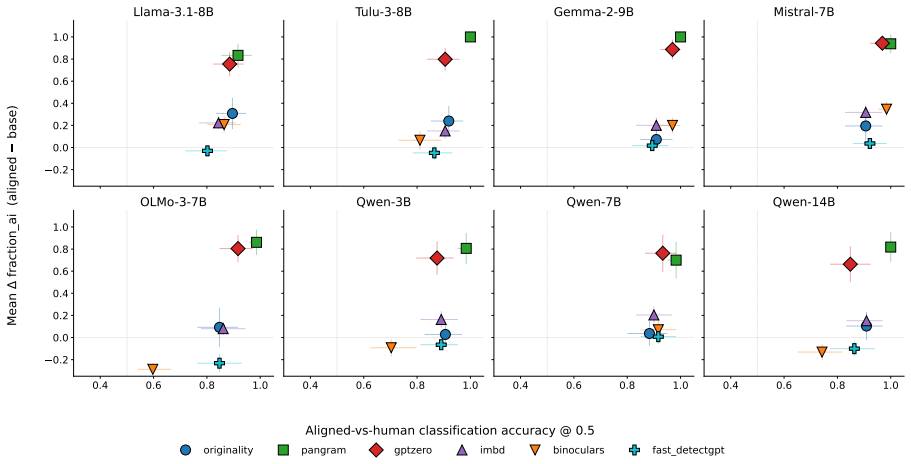
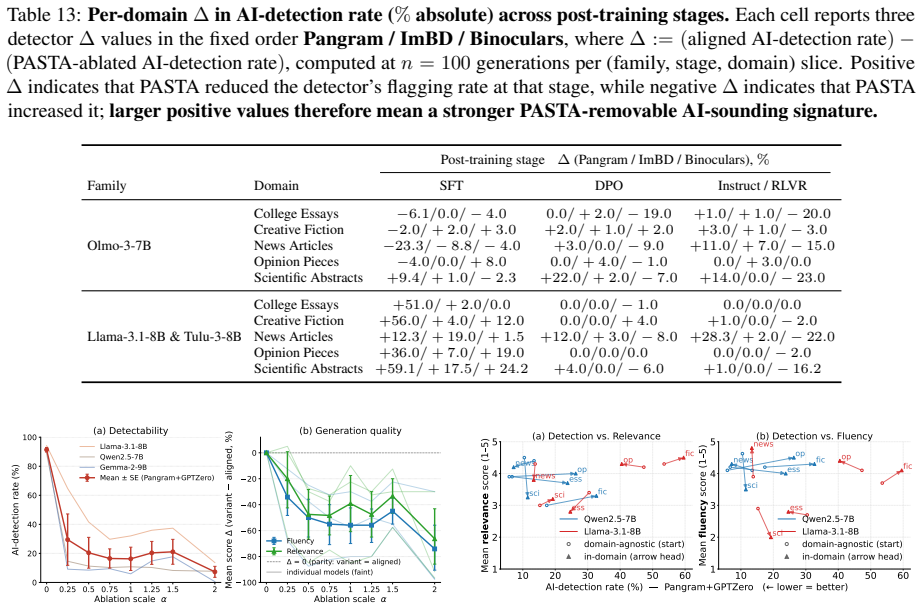
- Ablation lowers detection rates for most aligned models across multiple detectors.
- The reduction transfers across different AI detectors rather than being detector-specific.
- Random directions do not reproduce the detection-rate drop.
- Ablated outputs remain relevant and coherent while showing increased stylistic variation.
Where Pith is reading between the lines
- The same residual-contrast approach could be used to test whether other post-training effects, such as safety refusals, occupy separable directions.
- If the signature proves stable across model families, it offers a route to style adjustment without additional training data or fine-tuning.
Load-bearing premise
The activation difference between an aligned model and its base counterpart isolates the post-training stylistic change rather than other unrelated differences between the two models.
What would settle it
If ablating the estimated residual direction produces no drop in AI detection rates or if random directions produce equivalent drops, the claim that the residual isolates a post-training stylistic signature would be false.
Figures












read the original abstract
Aligned language models often exhibit a recognizable AI-like style, yet its connection to post-training and internal representations remains poorly understood. In this work, we study whether post-training introduces or amplifies AI-like stylistic regularities and whether these regularities have a localized internal signature. To this end, we compare human text, base-model generations, and aligned-model generations under matched human-source prefixes. Aligned generations show lower human-corpus affinity and higher AI-detection rates than base generations, suggesting that post-training shifts generated text away from human-corpus style and toward detector-visible AI-like text. We then introduce PASTA (Post-training Alignment Signature Targeted Ablation), a training-free method that estimates a post-training alignment signature from aligned-base residual contrasts and ablates the corresponding direction during decoding. Across 11 aligned models and 6 AI detectors, PASTA lowers the detection rate for most aligned models; this effect transfers well across detectors and is not reproduced by random directions. Qualitative analysis suggests that PASTA generations remain relevant and coherent while exhibiting greater stylistic variation. Together, these results show that AI-like stylistic effects of post-training can be measured, localized, and causally tested through activation ablation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that post-training shifts LLM generations toward AI-like style (lower human-corpus affinity, higher detector scores) relative to base models under matched prefixes, and that this shift has a localized activation signature. The authors introduce PASTA, a training-free method that extracts a direction from aligned-minus-base activation residuals and ablates it at inference; across 11 aligned models and 6 detectors this ablation reduces detection rates while random directions do not, and qualitative inspection indicates retained coherence with greater stylistic variation.
Significance. If the residual direction specifically isolates the stylistic component of alignment, the work supplies a causal, representation-level test of post-training effects on style and a practical intervention for modulating it. The breadth of models and detectors, together with the negative control of random directions, supplies useful empirical grounding.
major comments (1)
- [Abstract / PASTA definition] The central claim that the aligned-base residual isolates the post-training stylistic signature (rather than other differences in optimization trajectory, data mixture, or capability) is load-bearing yet unsupported by direct controls. No experiments contrast the style residual against residuals derived from non-style post-training interventions or cross-task activation differences (see Abstract and the description of PASTA).
minor comments (1)
- [Abstract] The abstract states that effects are consistent across models and detectors but reports neither error bars, exclusion criteria, nor the precise experimental protocol (layer selection, token aggregation, number of generations per condition).
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger controls to support the claim that the aligned-base residual specifically isolates stylistic effects of post-training. We address this point directly below and acknowledge the limitation.
read point-by-point responses
-
Referee: [Abstract / PASTA definition] The central claim that the aligned-base residual isolates the post-training stylistic signature (rather than other differences in optimization trajectory, data mixture, or capability) is load-bearing yet unsupported by direct controls. No experiments contrast the style residual against residuals derived from non-style post-training interventions or cross-task activation differences (see Abstract and the description of PASTA).
Authors: We agree that the aligned-base residual captures the net effect of post-training, which includes stylistic shifts but may also reflect differences in data mixture, optimization trajectory, or capability gains. Our evidence that the direction is relevant to style comes from the fact that its ablation consistently lowers scores on multiple AI detectors (which are trained on stylistic cues) while random directions produce no such effect, and that the resulting generations retain coherence and task relevance. However, we do not provide direct contrasts against residuals derived from non-style interventions (e.g., continued pre-training or capability-only fine-tuning) or cross-task activation differences. This is a genuine limitation of the current experiments. In the revision we will add an explicit limitations paragraph clarifying that PASTA targets the composite post-training direction and that style is the primary measured outcome rather than a fully isolated component; we will also note the absence of the suggested controls as an avenue for future work. revision: partial
Circularity Check
No significant circularity; derivation is empirical and self-contained
full rationale
The paper defines the PASTA signature directly from observed aligned-minus-base activation residuals and tests its ablation empirically against random directions across multiple models and detectors. No equations reduce a claimed prediction to a fitted input by construction, no self-citations are load-bearing for the central claim, and no uniqueness theorems or ansatzes are imported from prior author work. The results rest on external contrasts and controlled ablations rather than internal redefinitions or statistical forcing.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083. Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christo- pher Olah, Danny Hernandez, Dawn Drain...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
InInternational Conference on Machine Learning (ICML)
Spotting LLMs with binoculars: Zero-shot detection of machine-generated text. InInternational Conference on Machine Learning (ICML). John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. 2023. A watermark for large language models. InInterna- tional Conference on Machine Learning (ICML). Robert Kirk, Ishita Mediratta, C...
-
[3]
Steering Language Models With Activation Engineering
Get to the point: Summarization with pointer- generator networks. InProceedings of the 55th An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1073– 1083. Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott Johnston, Sha...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
2000:2019
because news leads are informationally dense and a shorter prefix is sufficient to fix the article’s framing. The CNN articles in this dataset were written between April 2007 and April 2015. Scientific Abstracts (sentence-transformers/s2orc, train split). The abstract field provides a paper abstract from the Semantic Scholar Open Research Corpus. The firs...
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.