Probing the Prompt KV Cache: Where It Becomes Dispensable
Pith reviewed 2026-06-29 07:16 UTC · model grok-4.3
The pith
The prompt KV cache becomes dispensable in upper layers because it encodes chat template form rather than task-specific content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
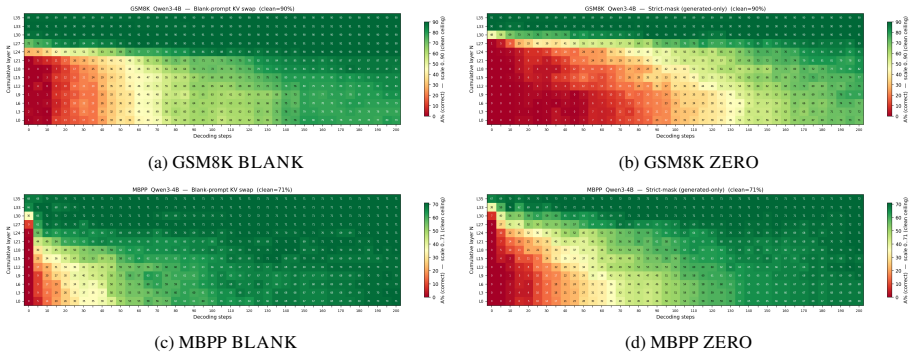
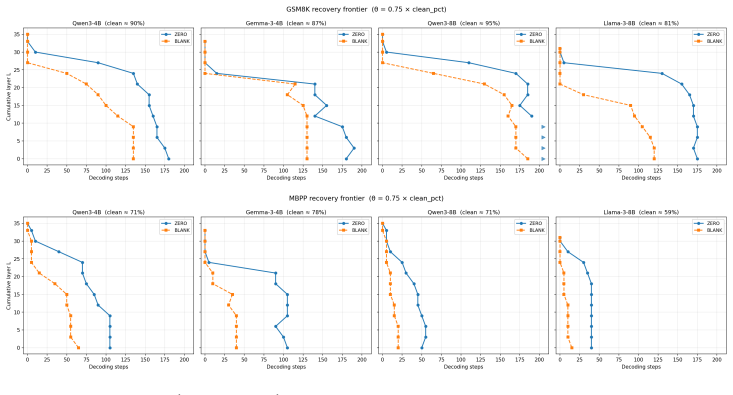
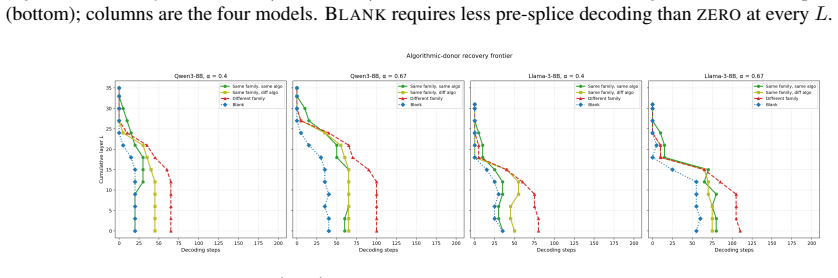
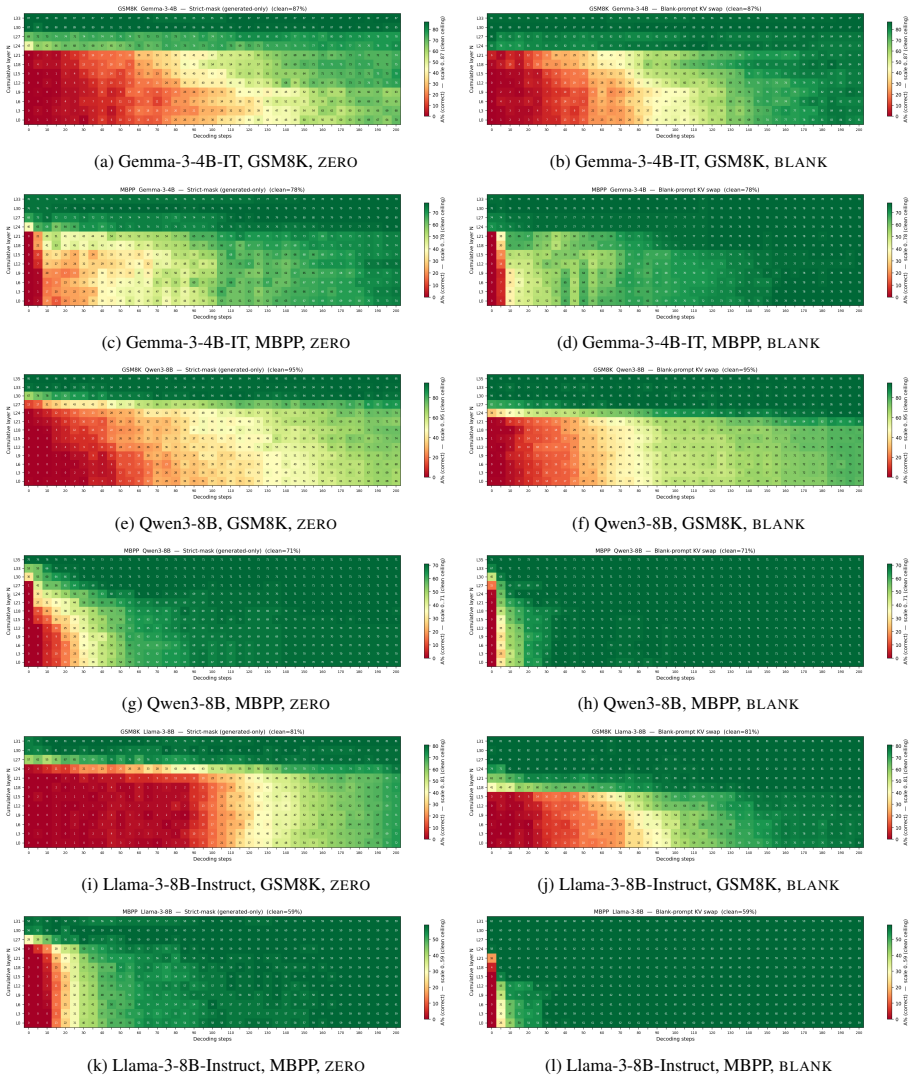
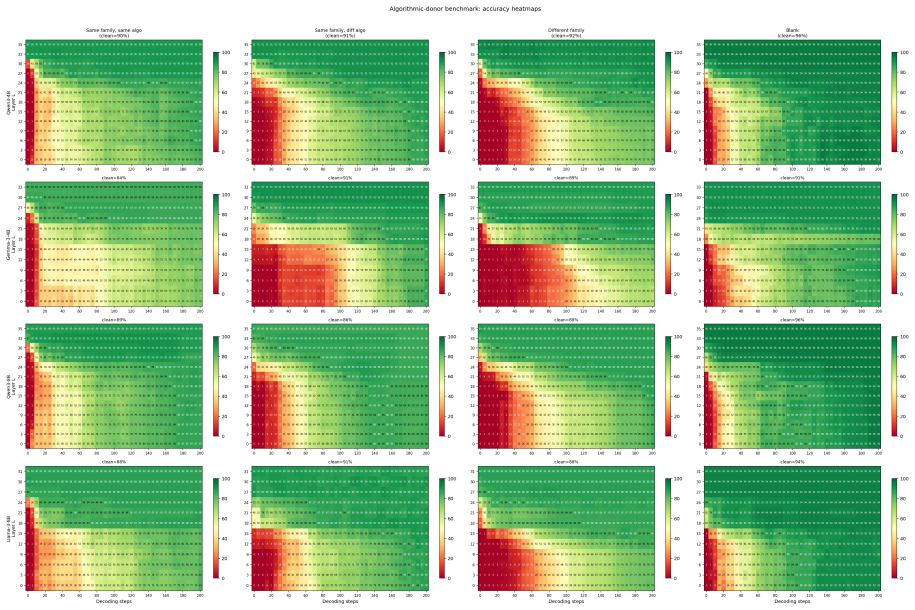
Replacing the upper layer prompt span KV cache with KV cache from a chat template scaffold whose user content is a neutral filler recovers near clean accuracy, while zeroing the same slots collapses accuracy. The dissociation replicates across the Qwen3, Gemma 3, and Llama 3 families on multiple datasets.
What carries the argument
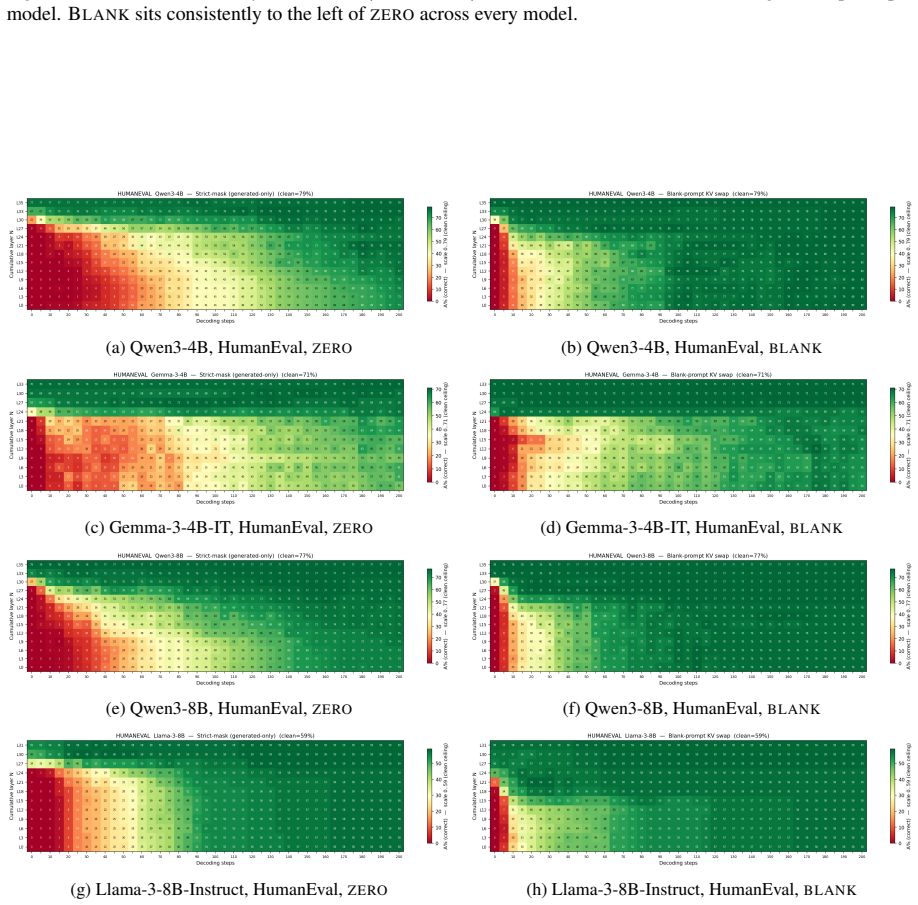
The controlled splice intervention that replaces prompt-span KV entries at chosen layers and decoding steps with entries generated from a neutral-filler chat template.
If this is right
- Prompt KV cache entries in upper layers primarily store chat template scaffolding after the first few decoding steps.
- Zeroing those entries breaks task performance while template-form substitution does not.
- The dispensability pattern appears consistently across Qwen3, Gemma 3, and Llama 3 on varied datasets.
- Redundancy can be probed by direct cache swaps rather than summarization or pruning alone.
Where Pith is reading between the lines
- Cache compression methods could store a single template-form cache and reuse it across prompts.
- The result suggests a separation between structural attention patterns and content-specific ones that may extend to other attention-based architectures.
- Future probes could test whether the same form-content split appears at different context lengths or task types.
Load-bearing premise
The neutral filler chat template isolates template form from task content without injecting its own confounding signals.
What would settle it
An experiment in which the neutral filler template is replaced by one carrying task-relevant signals and the accuracy recovery disappears, or in which zeroing the slots fails to collapse accuracy.
Figures
read the original abstract
Prior KV cache compression schemes empirically demonstrate that the prompt cache is partially redundant during decoding, dropping or summarising entries with little accuracy loss. We ask when and what kind of redundancy: at which layers, after how many decoding steps, and in what form can the prompt span KV cache be replaced without breaking the task. A controlled splice intervention swept over layer cutoff and decoding steps shows this redundancy is about form (chat template scaffolding) rather than content. Replacing the upper layer prompt span KV cache with KV cache from a chat template scaffold whose user content is a neutral filler recovers near clean accuracy, while zeroing the same slots collapses accuracy. The dissociation replicates across the Qwen3, Gemma 3, and Llama 3 families on multiple datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the conditions under which the prompt KV cache becomes redundant during decoding in large language models. Through a controlled splice intervention varying layer cutoffs and decoding steps, it claims that this redundancy primarily encodes chat-template form rather than task-specific content: replacing the upper-layer prompt-span KV cache with KV entries from a neutral-filler chat template recovers near-clean accuracy, whereas zeroing the same entries collapses performance. The dissociation is reported to replicate across the Qwen3, Gemma 3, and Llama 3 families on multiple datasets.
Significance. If the central dissociation holds under rigorous controls, the result would provide a concrete empirical distinction between structural scaffolding and semantic content in KV-cache usage, with direct implications for targeted compression and interpretability work. The multi-family replication is a positive feature; however, the absence of reported accuracy deltas, confidence intervals, exact cutoffs, or statistical tests limits assessment of effect magnitude and robustness.
major comments (2)
- [Abstract] Abstract: the central claim that replacement with a neutral-filler scaffold isolates form from content rests on an unverified assumption that the filler text (and surrounding template) carries zero task-relevant statistics; no description of the filler, selection criteria, or explicit controls is supplied, leaving open the possibility that recovery reflects leakage rather than dispensability of content.
- [Abstract] Abstract and intervention description: the splice is characterized only at the level of “upper layer prompt span” and “decoding steps”; without reported verification that attention masks, positional encodings, and cross-layer dependencies remain intact after replacement, the observed collapse under zeroing versus recovery under replacement could partly reflect intervention artifacts.
minor comments (1)
- [Abstract] The abstract reports replication across three model families and multiple datasets but supplies no quantitative accuracy numbers, error bars, exact layer/step cutoffs, or statistical tests; these should be added to the main text and abstract for evaluability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater clarity on the neutral filler and splice intervention. We will revise the manuscript to incorporate explicit descriptions and controls as detailed below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that replacement with a neutral-filler scaffold isolates form from content rests on an unverified assumption that the filler text (and surrounding template) carries zero task-relevant statistics; no description of the filler, selection criteria, or explicit controls is supplied, leaving open the possibility that recovery reflects leakage rather than dispensability of content.
Authors: We agree the abstract provides insufficient detail on the filler. The full manuscript describes the neutral filler as generic non-task content (e.g., repeated placeholder phrases matching template length but lacking semantic relevance to the datasets). In revision we will add explicit filler text examples, selection criteria (structural match to chat template without content overlap), and controls (e.g., filler variation ablations confirming no accuracy change attributable to filler statistics). This directly addresses the leakage concern. revision: yes
-
Referee: [Abstract] Abstract and intervention description: the splice is characterized only at the level of “upper layer prompt span” and “decoding steps”; without reported verification that attention masks, positional encodings, and cross-layer dependencies remain intact after replacement, the observed collapse under zeroing versus recovery under replacement could partly reflect intervention artifacts.
Authors: We agree explicit verification is warranted. The splice replaces only KV values for the prompt span in upper layers while retaining original positions, causal masks, and layer-wise dependencies. In revision we will expand the methods to document these invariants, include checks that zeroing and replacement use identical mask/position handling, and report that cross-layer attention patterns remain consistent post-splice (no new artifacts introduced). revision: yes
Circularity Check
No circularity: empirical intervention with independent measurements
full rationale
The paper's central claim rests on a controlled splice intervention that replaces prompt-span KV entries with those from a neutral-filler chat template and compares accuracy recovery against zeroing. No equations, fitted parameters, or self-citations appear in the provided text; the result is obtained by direct measurement across model families and datasets rather than by any definitional reduction or renaming of prior inputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Mukkesh Ganesh, Kaushik Iyer, and Arun Baalaaji Sankar Ananthan. 2025. Whose nar- rative is it anyway? a KV cache manipulation attack.arXiv preprint arXiv:2511.12752. Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Ji- awei Han, and Jianfeng Gao. 2024. Model tells you what t...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
A Python prompt asking for algorithm B
-
[3]
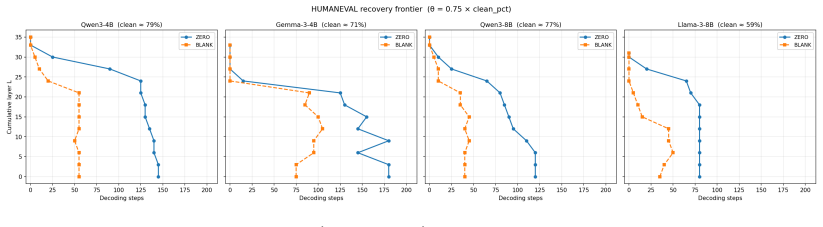
BLANKsits consistently to the left ofZEROacross every model
A Python solution using algorithm A Return a JSON array of 10 objects, each with keys: - ‘‘variant name’’: short description - ‘‘python b prompt’’: one-sentence Python prompt explicitly naming algorithm B Figure 5: HumanEval recovery frontierW ⋆(L;α= 0.75)forZERO(blue) andBLANK(orange), one panel per model. BLANKsits consistently to the left ofZEROacross ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.