TeachObs: A Human-Validated Benchmark for Multimodal Teaching Observation and Model Evaluation
Pith reviewed 2026-06-28 23:09 UTC · model grok-4.3
The pith
TeachObs benchmark finds no single frontier LLM outperforms others across segment coding and lesson-level tracks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
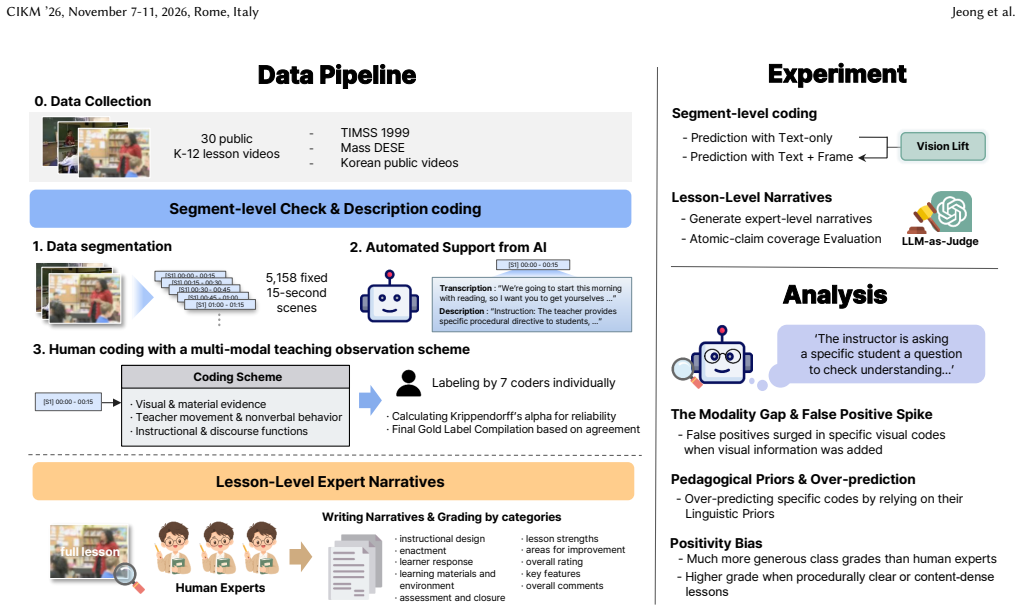
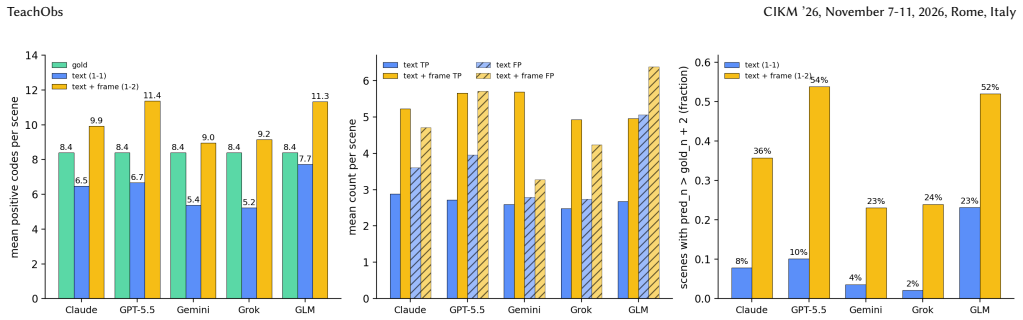
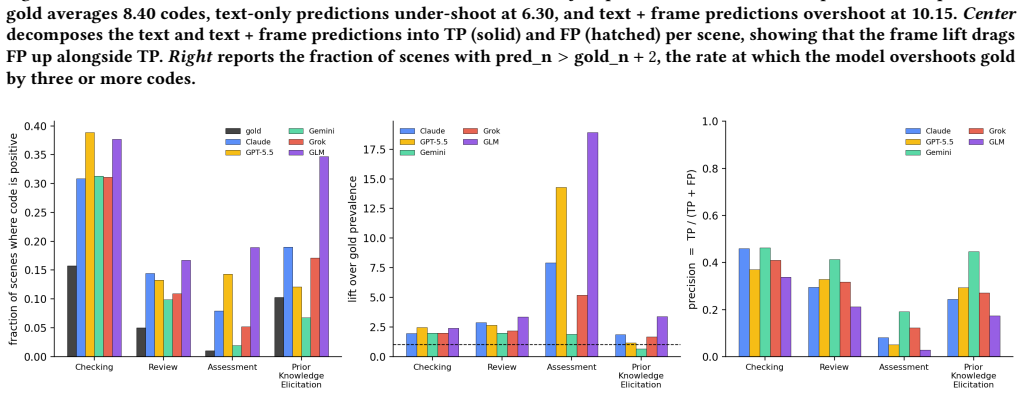
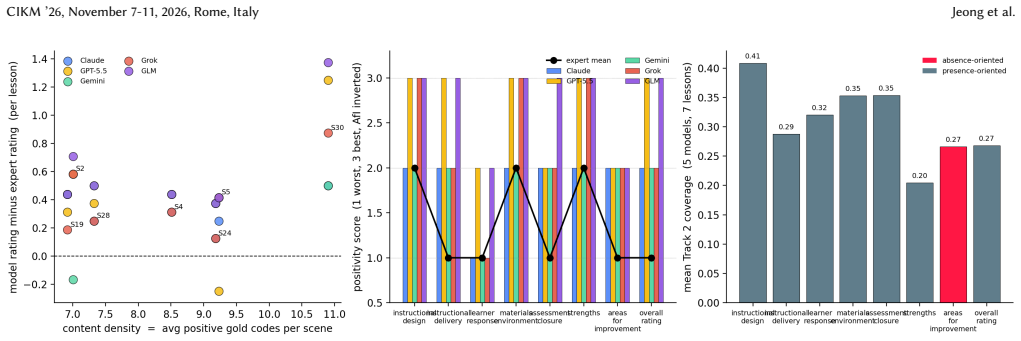
TeachObs supplies human-validated segment labels for 5158 scenes using 39 observation codes and lesson-level ratings from experts. Evaluation of frontier LLMs across three tracks demonstrates that performance varies by track with no overall leader, that including a mid-scene frame boosts both true and false positive attributions, and that automated lesson ratings diverge from those of human experts particularly on procedurally straightforward lessons.
What carries the argument
TeachObs benchmark of 30 videos segmented into fixed 15-second scenes, with gold labels built from multi-annotator binary codes via reliability- and prevalence-aware rules based on Krippendorff's alpha plus separate expert lesson-level ratings.
If this is right
- Different models may be better suited to different mixes of visual and nonvisual codes rather than one model serving all observation needs.
- Adding a single mid-scene frame changes attribution counts in both directions, so multimodal input does not produce uniform gains.
- LLM-as-judge scores on lesson quality can diverge from expert scores, especially when the lesson follows clear procedural steps.
- The dual reference layers (segment codes and lesson ratings) allow separate checks on fine-grained detection versus overall instructional assessment.
Where Pith is reading between the lines
- The observed inflation of both true and false attributions when frames are added points to a need for better ways to integrate visual evidence without over-triggering detections.
- Divergence between model and expert lesson ratings suggests that procedural clarity alone may be easier for current models to recognize than subtler learner-response or reflection elements.
- Because the videos span multiple countries and subjects, the benchmark can serve as a test bed for checking whether model strengths transfer across classroom formats.
- Future extensions could add more granular timing within scenes or additional expert raters to test how stable the current gold labels remain under different annotation conditions.
Load-bearing premise
The reliability- and prevalence-aware rules based on Krippendorff's alpha produce gold segment labels that accurately reflect observable teaching practices without substantial bias from scene length, annotator selection, or the specific 39 codes chosen.
What would settle it
Re-annotating a random subset of scenes with an independent group of annotators and re-applying the same Krippendorff-based rules yields gold labels that differ substantially from the published ones on a large fraction of the 39 codes.
Figures
read the original abstract
Classroom videos contain observable teaching practices, but their pedagogical and visual signals are rarely organized in forms suitable for model evaluation. We present \textit{TeachObs}, a human-validated benchmark for multimodal teaching observation in classroom videos. \textit{TeachObs} includes 30 public lesson videos from eight countries divided into 5,158 fixed 15-second scenes. Seven researchers annotated each scene with 39 binary observation codes, covering 20 visual codes, such as gesture, board work, pointing, and visual materials, and 19 nonvisual codes, such as instruction, monitoring, questioning, feedback, and reflection. Gold segment labels are constructed using reliability- and prevalence-aware rules based on Krippendorff's alpha. In addition to segment-level labels, three expert raters produced lesson-level ratings and qualitative evaluations of instructional design, instructional delivery, learner response, learning materials, and lesson closure across the 30 lessons, with rater coverage detailed in the body. Using these two human reference layers, we evaluate five vision-capable frontier LLMs across three tracks - text-only segment coding, text + frame segment coding, and lesson-level coverage scored under an LLM-as-judge protocol - and find that no single model consistently outperforms others across all three tracks, that adding a mid-frame inflates both true and false attributions per scene, and that model evaluations over-rate procedurally clear lessons relative to expert raters. \textit{TeachObs} therefore supports both fine-grained annotation benchmarking and whole-lesson evaluation, showing where AI systems can assist classroom video analysis and where expert judgment remains necessary across varied subjects, classroom formats, and annotation difficulty levels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TeachObs, a benchmark for multimodal teaching observation consisting of 30 public lesson videos from eight countries, segmented into 5,158 fixed 15-second scenes. Seven researchers annotated each scene with 39 binary codes (20 visual such as gesture and board work, 19 nonvisual such as instruction and questioning). Gold segment labels are created using reliability- and prevalence-aware rules based on Krippendorff's alpha. Three expert raters provide lesson-level ratings on five aspects of instructional quality. Five vision-capable frontier LLMs are evaluated on three tracks: text-only segment coding, text+frame segment coding, and lesson-level LLM-as-judge scoring. The results indicate that no model consistently outperforms the others across tracks, that including a mid-frame increases both true and false positive attributions, and that models over-rate procedurally clear lessons compared to expert raters.
Significance. If the gold labels are shown to be reliable and unbiased, this work would provide a valuable resource for evaluating AI systems on classroom video analysis, bridging a gap in benchmarks that organize pedagogical and visual signals. The dual reference layers (segment and lesson) allow for both fine-grained and holistic assessment, and the findings highlight specific limitations of current models in handling multimodal inputs and aligning with expert judgment across diverse educational contexts.
major comments (2)
- [Gold label construction] The abstract states that gold segment labels are constructed using 'reliability- and prevalence-aware rules based on Krippendorff's alpha' from seven annotators' binary judgments on 39 codes, but no alpha values, no explicit description of the aggregation rules, no prevalence adjustment formulas, and no quantitative inter-annotator agreement statistics or error analysis are provided. This directly undermines verification of the central claims about model performance across the three tracks, as the skeptic notes that prevalence or annotator biases could distort the gold labels.
- [Lesson-level expert ratings] The claim that 'model evaluations over-rate procedurally clear lessons relative to expert raters' depends on the lesson-level ratings produced by three expert raters; however, the abstract only alludes to 'rater coverage detailed in the body' without reporting inter-rater reliability, agreement metrics, or how the five rating dimensions (instructional design, delivery, learner response, materials, closure) were aggregated.
minor comments (1)
- [Data and code availability] The manuscript should explicitly state data availability for the annotated scenes, gold labels, expert ratings, and any code used for label aggregation or model prompting to enable independent verification.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive feedback on the transparency of our annotation and rating procedures. We will revise the manuscript to provide the requested details and statistics.
read point-by-point responses
-
Referee: [Gold label construction] The abstract states that gold segment labels are constructed using 'reliability- and prevalence-aware rules based on Krippendorff's alpha' from seven annotators' binary judgments on 39 codes, but no alpha values, no explicit description of the aggregation rules, no prevalence adjustment formulas, and no quantitative inter-annotator agreement statistics or error analysis are provided. This directly undermines verification of the central claims about model performance across the three tracks, as the skeptic notes that prevalence or annotator biases could distort the gold labels.
Authors: We agree that explicit reporting of these metrics is necessary for verification. In the revised manuscript, we will add a dedicated methods subsection with Krippendorff's alpha values computed per code across the seven annotators, the precise reliability- and prevalence-aware aggregation rules (including any formulas or thresholds applied), full inter-annotator agreement statistics, and an error analysis addressing potential biases. This will directly support evaluation of the segment-level tracks. revision: yes
-
Referee: [Lesson-level expert ratings] The claim that 'model evaluations over-rate procedurally clear lessons relative to expert raters' depends on the lesson-level ratings produced by three expert raters; however, the abstract only alludes to 'rater coverage detailed in the body' without reporting inter-rater reliability, agreement metrics, or how the five rating dimensions (instructional design, delivery, learner response, materials, closure) were aggregated.
Authors: We concur that inter-rater reliability and aggregation details for the lesson-level ratings must be reported explicitly to substantiate the over-rating claim. The revised manuscript will include quantitative agreement metrics (e.g., Krippendorff's alpha) for the three expert raters on the five dimensions, a description of the aggregation method (such as majority consensus or averaging), and clarification of rater coverage and qualitative procedures. revision: yes
Circularity Check
No significant circularity; empirical benchmark construction with external reliability measures
full rationale
The paper constructs TeachObs via human annotation of 5158 scenes with 39 binary codes by seven researchers, followed by gold label aggregation using standard Krippendorff's alpha-based rules and separate expert lesson-level ratings. No equations, fitted parameters presented as predictions, self-definitional loops, or load-bearing self-citations appear in the methodology. Model evaluations across the three tracks are direct comparisons against these externally produced human references. The central claims (no model dominates, mid-frame effects, over-rating of clear lessons) rest on observable empirical outcomes rather than any reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Michelle E. Alvarez. 2014. Danielson’s Framework for Teaching.ERIC Educational Resources (EJ1279029)(2014). https://files.eric.ed.gov/fulltext/EJ1279029.pdf
2014
-
[2]
Mu Cai, Reuben Tan, Jianrui Zhang, Bocheng Zou, Kai Zhang, Feng Yao, Fangrui Zhu, Jing Gu, Yiwu Zhong, Yuzhang Shang, Yao Dou, Jaden Park, Jianfeng Gao, Yong Jae Lee, and Jianwei Yang. 2024. TemporalBench: Benchmarking Fine- grained Temporal Understanding for Multimodal Video Models.arXiv preprint arXiv:2410.10818(2024). https://arxiv.org/abs/2410.10818
- [3]
-
[4]
Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, and Kai Chen. 2024. MMBench-Video: A Long-Form Multi-Shot Benchmark for Holistic Video Understanding. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track. https://arxiv.org/abs/2406. 14515 arXiv:2406.14515
-
[5]
Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zi- han Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yan- wei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Rongrong Ji, and Xing Sun. 2025. Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis. InP...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Sara Hennessy, Sylvia Rojas-Drummond, Rupert Higham, Ana María Márquez, Fiona Maine, Rosa María Rios, Rocío García-Carrión, Omar Torreblanca, and María José Barrera. 2016. Developing a coding scheme for analysing classroom dialogue across educational contexts.Learning, Culture and Social Interaction9 (2016), 16–44. doi:10.1016/j.lcsi.2015.12.001
- [7]
-
[8]
Todd D. Jick. 1979. Mixing Qualitative and Quantitative Methods: Triangulation in Action.Administrative Science Quarterly24, 4 (1979), 602–611. doi:10.2307/ 2392366
1979
-
[9]
Will Kay, João Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. 2017. The Kinetics Human Action Video Dataset.arXiv preprint arXiv:1705.06950(2017). https://arxiv.org/abs/1705.06950
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. 2024. MVBench: A Comprehensive Multi-modal Video Understanding Benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). https://arxiv.org/abs/2311.17005 arXiv:2311.17005
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Aohua Liu et al. 2025. A Multi-Modal Dataset for Teacher Behavior Analysis in Offline Classrooms.Scientific Data(2025). doi:10.1038/s41597-025-05426-6
-
[12]
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. 2024. TempCompass: Do Video LLMs Really Understand Videos?. InFindings of the Association for Computational Linguistics (ACL). https: //arxiv.org/abs/2403.00476 arXiv:2403.00476
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Ye Liu, Zongyang Ma, Zhongang Qi, Yang Wu, Chang Wen Chen, and Ying Shan
-
[14]
Bench: Towards Open-Ended Event-Level Video-Language Under- standing
E.T. Bench: Towards Open-Ended Event-Level Video-Language Under- standing. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track. https://arxiv.org/abs/2409.18111 arXiv:2409.18111
-
[15]
Jakub Macina, Nico Daheim, Sankalan Pal Chowdhury, Tanmay Sinha, Manu Kapur, Iryna Gurevych, and Mrinmaya Sachan. 2023. MathDial: A Dialogue Tutoring Dataset with Rich Pedagogical Properties Grounded in Math Reasoning Problems. InFindings of the Association for Computational Linguistics: EMNLP 2023
2023
-
[16]
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. 2023. EgoSchema: A Diagnostic Benchmark for Very Long-form Video Lan- guage Understanding. InAdvances in Neural Information Processing Systems (NeurIPS) - Datasets and Benchmarks Track. https://arxiv.org/abs/2308.09126 arXiv:2308.09126
-
[17]
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. 2019. HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). https://arxiv.org/abs/1906. 03327 arXiv:1906.03327
-
[18]
Vijeta Sharma, Manjari Gupta, Ajai Kumar Pandey, Deepti Mishra, and Ankit Kumar. 2021. EduNet: A New Video Dataset for Understanding Human Activity in the Classroom Environment.Sensors21, 17 (2021), 5699. doi:10.3390/s21175699
-
[19]
Yixuan Shen, Peng He, Honglu Liu, Jinxuan Fan, Yuyang Ji, Tingting Li, Tianlong Chen, Kaidi Xu, and Feng Liu. 2026. Can Multimodal LLMs See Science Instruc- tion? Benchmarking Pedagogical Reasoning in K-12 Classroom Videos.arXiv preprint arXiv:2602.18466(2026). https://arxiv.org/abs/2602.18466
-
[20]
Katherine Stasaski, Kimberly Kao, and Marti A. Hearst. 2020. CIMA: A Large Open Access Dialogue Dataset for Tutoring. InProceedings of the 15th Workshop on Innovative Use of NLP for Building Educational Applications (BEA). https: //aclanthology.org/2020.bea-1.5/
2020
-
[21]
Kok-Sing Tang, Hyo-Jeong So, and Natasha Rappa. 2023. Examining the Multi- modal Design of Explainer Videos: A Multimodal Content Analysis of Khan Academy Online Resources.SSRN Working Paper 4561629(2023). https: //papers.ssrn.com/sol3/papers.cfm?abstract_id=4561629
2023
- [22]
-
[23]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. 2024. LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding.arXiv preprint arXiv:2407.15754(2024). https://arxiv.org/abs/2407.15754
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [24]
-
[25]
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. 2024. MLVU: A Comprehensive Bench- mark for Multi-Task Long Video Understanding.arXiv preprint arXiv:2406.04264 (2024). https://arxiv.org/abs/2406.04264
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Pengfei Zhou, Xiaopeng Peng, Fanrui Song, Zhuoyao Li, Xuyang Wang, Zhaopan Liu, Kai Wang, Yi Zhao, Yefei Zhang, Zixu Wang, et al . 2025. MDK12-Bench: A Multi-Discipline Benchmark for Evaluating Reasoning in Multimodal Large Language Models.arXiv preprint arXiv:2504.05782(2025). https://arxiv.org/abs/ 2504.05782
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.