Annotations Are Not All You Need: A Cross-modal Knowledge Transfer Network for Unsupervised Temporal Sentence Grounding
Pith reviewed 2026-06-28 23:29 UTC · model grok-4.3
The pith
Transferring appearance knowledge from image-noun pairs and action knowledge from video-verb pairs enables accurate unsupervised temporal sentence grounding without any video-query training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
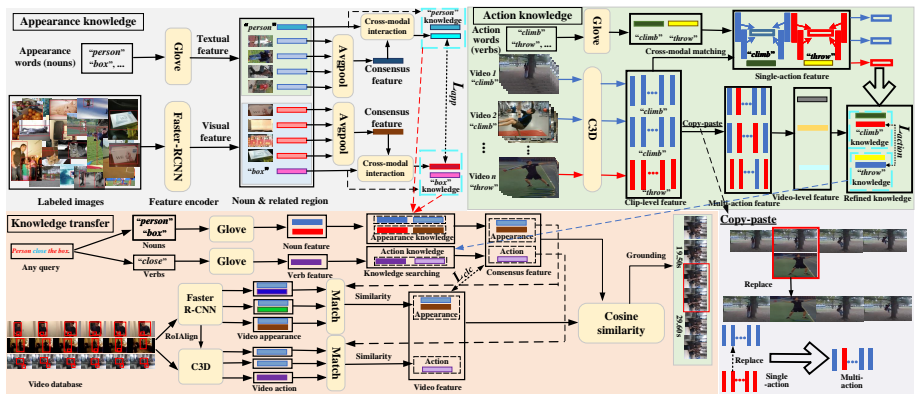
By collecting and transferring simple cross-modal alignment knowledge from the paired Image-Noun task for appearance and the paired Video-Verb task for actions, adapted respectively via object-guided methods and a copy-paste approach, the model directly utilizes this general knowledge to correlate videos and queries and accurately retrieve the relevant segment without any training on paired video-query data.
What carries the argument
The cross-modal knowledge transfer network that modulates and transfers entity-aware appearance knowledge from Image-Noun pairs and event-aware action knowledge from Video-Verb pairs into the unsupervised TSG task.
If this is right
- The model retrieves relevant video segments directly from transferred general knowledge without training on paired video-query data.
- The approach outperforms existing unsupervised methods on ActivityNet Captions and Charades-STA.
- Performance reaches levels competitive with supervised methods that rely on full annotations.
- Appearance knowledge is adapted into each independent video frame via object guidance.
- Action representations are refined for real-world cases using the copy-paste approach.
Where Pith is reading between the lines
- Similar transfers from static image and short-clip alignments could reduce annotation demands in related tasks like video question answering.
- The copy-paste refinement for actions suggests a general way to adapt short-clip knowledge to longer temporal sequences without new labels.
- Applying the same transfer pipeline to unlabeled video corpora from different domains would test how broadly the adapted knowledge generalizes.
Load-bearing premise
Simple cross-modal alignment knowledge from paired Image-Noun and Video-Verb tasks can be collected, adapted via object-guided and copy-paste methods, and transferred effectively to enable accurate retrieval in unsupervised temporal sentence grounding.
What would settle it
Evaluating the model on ActivityNet Captions or Charades-STA and finding no retrieval improvement over a no-transfer baseline would falsify the claim that the transferred knowledge enables accurate grounding.
Figures

read the original abstract
This paper addresses the task of temporal sentence grounding (TSG). Although many respectable works have made decent achievements in this important topic, they severely rely on massive expensive video-query paired annotations, which require a tremendous amount of human effort to collect in real-world applications. To this end, in this paper, we target a more practical but challenging TSG setting: unsupervised temporal sentence grounding, where both paired video-query and segment boundary annotations are unavailable during the network training. Considering that some other cross-modal tasks provide many easily available yet cheap labels, we tend to collect and transfer their simple cross-modal alignment knowledge into our complex scenarios: 1) We first explore the entity-aware object-guided appearance knowledge from the paired Image-Noun task, and adapt them into each independent video frame; 2) Then, we extract the event-aware action representation from the paired Video-Verb task, and further refine the action representation into more practical but complicated real-world cases by a newly proposed copy-paste approach; 3) By modulating and transferring both appearance and action knowledge into our challenging unsupervised task, our model can directly utilize this general knowledge to correlate videos and queries, and accurately retrieve the relevant segment without training. Extensive experiments on two challenging datasets (ActivityNet Captions and Charades-STA) show our effectiveness, outperforming existing unsupervised methods and even competitively beating supervised works.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address unsupervised temporal sentence grounding (TSG) by collecting and transferring cross-modal knowledge from simpler paired tasks: entity-aware object-guided appearance knowledge from Image-Noun pairs (adapted per video frame) and event-aware action representations from Video-Verb pairs (refined via a copy-paste approach for real-world complexity). By modulating and transferring both into the target task, the model directly correlates videos and queries to retrieve relevant segments without any training on paired video-query data, outperforming unsupervised methods and competing with supervised ones on ActivityNet Captions and Charades-STA.
Significance. If the central claim holds, the work would be significant for reducing reliance on expensive video-query annotations in TSG, a core video-language task. The concrete adaptations (object-guided appearance transfer and copy-paste action refinement) are specific, implementable contributions that could generalize to other unsupervised multimodal settings. The zero-training retrieval via transferred knowledge, if validated, offers a falsifiable prediction about the sufficiency of noun/verb alignments for compositional temporal grounding.
major comments (2)
- [Abstract] Abstract: the claim that the model 'accurately retrieve[s] the relevant segment without training' and 'outperform[s] existing unsupervised methods' is load-bearing for the central contribution, yet the abstract provides no quantitative results, ablation studies, or experiment details to support that the transferred features enable fine-grained alignment rather than coarse category matching.
- [Method] Method (transfer and modulation steps): the assumption that object-guided appearance knowledge and copy-paste-refined action knowledge suffice for handling compositional queries, temporal ordering, negation, or multi-event descriptions is central, but no analysis or test is described showing that the direct correlation step encodes the necessary relations; if only coarse matches are transferred, retrieval would fail on realistic queries.
minor comments (1)
- [Abstract] The abstract contains several long sentences that reduce readability; splitting the description of the three-step process would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work regarding unsupervised temporal sentence grounding via cross-modal knowledge transfer. Below we respond point-by-point to the major comments, clarifying our approach and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the model 'accurately retrieve[s] the relevant segment without training' and 'outperform[s] existing unsupervised methods' is load-bearing for the central contribution, yet the abstract provides no quantitative results, ablation studies, or experiment details to support that the transferred features enable fine-grained alignment rather than coarse category matching.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript reports extensive experiments, including comparisons to unsupervised and supervised baselines on ActivityNet Captions and Charades-STA, along with ablations on the transfer components. In the revised version, we will update the abstract to reference specific metrics (such as R@1 and mIoU gains) that demonstrate performance on queries requiring temporal and compositional alignment beyond coarse matching. revision: yes
-
Referee: [Method] Method (transfer and modulation steps): the assumption that object-guided appearance knowledge and copy-paste-refined action knowledge suffice for handling compositional queries, temporal ordering, negation, or multi-event descriptions is central, but no analysis or test is described showing that the direct correlation step encodes the necessary relations; if only coarse matches are transferred, retrieval would fail on realistic queries.
Authors: The benchmarks used (ActivityNet Captions and Charades-STA) contain realistic queries involving compositional elements, temporal ordering, and multi-event descriptions, and our method's competitive results with supervised approaches indicate that the transferred knowledge supports the required relations via the modulation and direct correlation. The copy-paste refinement specifically targets real-world complexity. That said, we acknowledge the value of more explicit analysis; we will add qualitative retrieval examples and a brief discussion of how the transferred features handle such cases in the revised manuscript. revision: partial
Circularity Check
No circularity; derivation relies on external tasks and adaptations without self-referential reduction
full rationale
The paper's core method collects appearance knowledge from the external Image-Noun task and action knowledge from the external Video-Verb task, then applies object-guided adaptation and copy-paste refinement before direct transfer to unsupervised TSG. No equations, predictions, or claims in the provided text reduce by construction to fitted parameters or self-citations; the unsupervised retrieval step is presented as using transferred external knowledge without target-domain training or self-definition. This matches the default expectation of a self-contained approach with independent content from outside sources.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-modal alignment knowledge from Image-Noun and Video-Verb tasks is transferable to unsupervised TSG
Reference graph
Works this paper leans on
-
[1]
Double Self-weighted Multi-view Clustering via Adaptive View Fusion
Modeling visual context is key to augmenting object detection datasets. InProceedings of the Euro- pean Conference on Computer Vision (ECCV), pages 364–380. Wanlong Fang, Tianle Zhang, and Alvin Chan. 2026a. To align or not to align: Strategic multimodal rep- resentation alignment for optimal performance. In Proceedings of the AAAI Conference on Artificia...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Xiang Fang, Daizong Liu, Pan Zhou, and Guoshun Nan
Multi-modal cross-domain alignment network for video moment retrieval.IEEE Transactions on Multimedia, 25:7517–7532. Xiang Fang, Daizong Liu, Pan Zhou, and Guoshun Nan. 2023b. You can ground earlier than see: An effective and efficient pipeline for temporal sentence ground- ing in compressed videos. InProceedings of the IEEE/CVF Conference on Computer Vis...
2017
-
[3]
International journal of computer vision, 123(1):32– 73
Visual genome: Connecting language and vi- sion using crowdsourced dense image annotations. International journal of computer vision, 123(1):32– 73. Mingjin Kuai, You Qin, Xiang Fang, Wei Ji, and Roger Zimmermann. 2026. Dynamic graph-enhanced event refinement for temporal sentence grounding of micro- moments.IEEE Transactions on Multimedia. Xiaohan Lan, Y...
2026
-
[4]
InEuropean Conference on Com- puter Vision, pages 447–463
Tvr: A large-scale dataset for video-subtitle moment retrieval. InEuropean Conference on Com- puter Vision, pages 447–463. Springer. Qian Li, Shu Guo, Cheng Ji, Xutan Peng, Shiyao Cui, Jianxin Li, and Lihong Wang. 2023a. Dual-gated fusion with prefix-tuning for multi-modal relation extraction. InFindings of the Association for Com- putational Linguistics:...
-
[5]
InProceedings of the 28th ACM Interna- tional Conference on Multimedia, pages 1283–1291
Reinforcement learning for weakly supervised temporal grounding of natural language in untrimmed videos. InProceedings of the 28th ACM Interna- tional Conference on Multimedia, pages 1283–1291. Zeyu Xiong, Daizong Liu, Xiang Fang, Xiaoye Qu, Jian- feng Dong, Jiahao Zhu, Keke Tang, and Pan Zhou
-
[6]
Zhenbo Xu, Ajin Meng, Zhenbo Shi, Wei Yang, Zhi Chen, and Liusheng Huang
Rethinking video sentence grounding from a tracking perspective with memory network and masked attention.IEEE Transactions on Multimedia, 26:11204–11218. Zhenbo Xu, Ajin Meng, Zhenbo Shi, Wei Yang, Zhi Chen, and Liusheng Huang. 2021. Continuous copy- paste for one-stage multi-object tracking and seg- mentation. InProceedings of the IEEE/CVF Interna- tiona...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.