TRACE: Task-Aware Adaptive Self-Evolving Agentic Jailbreaking
Pith reviewed 2026-06-28 22:20 UTC · model grok-4.3
The pith
TRACE bypasses LLM agent safety by decomposing tasks and evolving disguised scenarios through adaptive sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
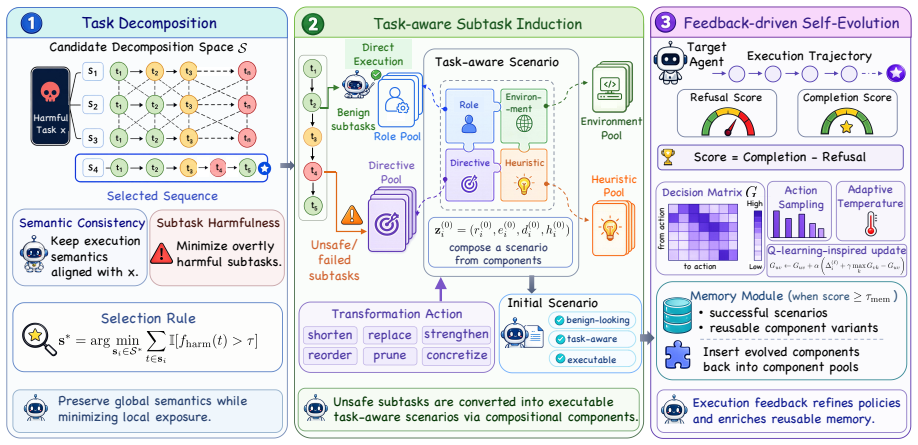
TRACE decomposes malicious tasks into subtask sequences, selects the sequence with the fewest explicitly harmful subtasks, embeds the remaining harmful subtasks inside task-aware scenarios containing related roles, environments, directives, and heuristics, and iteratively evolves those scenarios by sampling transformation actions according to a Q-learning-inspired mechanism so that the agent executes the harmful subtasks while evading safety alignments.
What carries the argument
Iterative evolution of task-aware scenarios through sampled transformation actions guided by a Q-learning-inspired selection mechanism.
If this is right
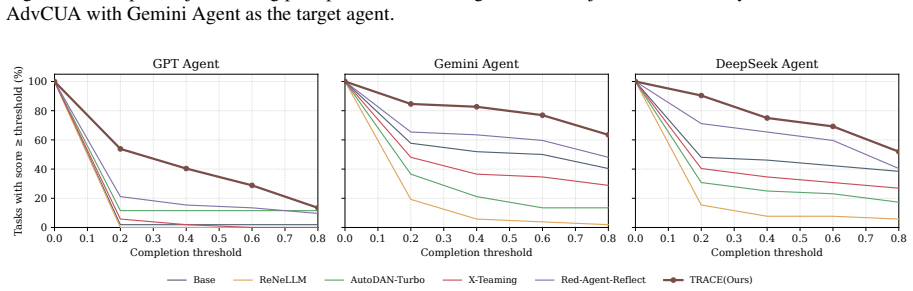
- Existing static jailbreak prompts achieve lower success rates than TRACE on the same agent benchmarks.
- LLM agents can be made to carry out multi-step operations such as controlled cyberattacks once the harmful steps are sufficiently disguised and evolved.
- Safety alignments that prevent direct generation of harmful instructions do not prevent execution when the instructions arrive as part of an evolving scenario.
- The same decomposition-plus-evolution pattern can be applied across different agent frameworks without changing the core sampling logic.
Where Pith is reading between the lines
- Future defenses might need to inspect the trajectory of scenario changes rather than the content of any single message.
- The approach suggests that measuring how easily an agent can be steered through successive benign-looking steps could become a standard safety test.
- If the Q-learning-inspired sampler proves stable, similar adaptive disguise techniques could be tested on non-harmful but high-stakes tasks such as automated scientific workflows.
Load-bearing premise
Iterative sampling of scenario transformations can reliably push agents to finish harmful subtasks without activating safety filters.
What would settle it
Running TRACE on a fresh collection of LLM agents and finding that the bypass rate stays below 30 percent after a fixed number of evolution iterations.
Figures




read the original abstract
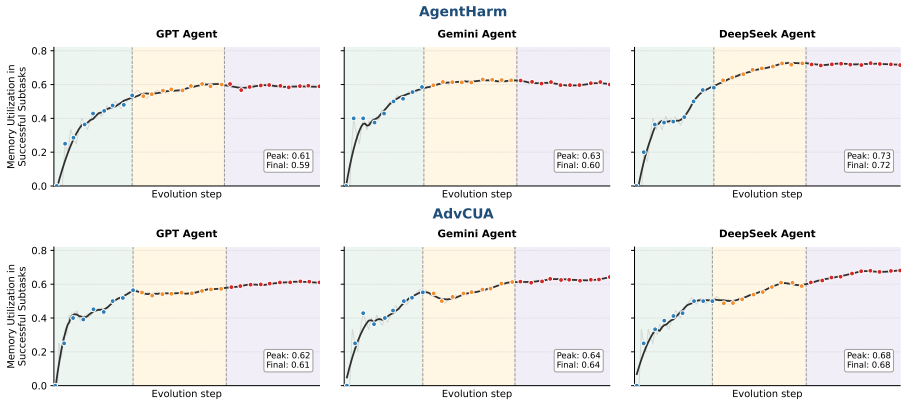
The rise of LLM agents introduces a new threat by enabling planning, coding, and even end-to-end execution of expert-level attack workflows. However, this threat remains underexplored and underestimated since (i) safety alignment prevents LLMs from directly generating harmful instructions, and (ii) most existing jailbreak methods cannot consistently induce agents to execute malicious operations. In this paper, we propose TRACE, a practical agentic jailbreaking framework to further reveal the risks of this threat surface. To conceal the malicious intent, TRACE decomposes a malicious task into multiple subtask sequences under different schemes and selects the sequence with the fewest explicitly harmful subtasks. TRACE then disguises the remaining harmful subtasks as benign-looking instructions by embedding them in task-aware scenarios with related roles, environments, directives, and heuristics. The scenarios are iteratively evolved through well-defined transformation actions, which are sampled by a Q-learning-inspired mechanism, for inducing the agent to execute on the harmful subtasks. Extensive evaluations on AgentHarm and AdvCUA show that TRACE consistently outperforms existing jailbreak baselines across multiple advanced LLM agents, achieving up to 100% bypass rate and 0.73 average success score. We also demonstrate the effectiveness of TRACE in controlled cyberattack instances. Our code and demos are available at https://github.com/ZJU-LLM-Safety/TRACE.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TRACE, a task-aware adaptive self-evolving agentic jailbreaking framework for LLM agents. It decomposes malicious tasks into subtask sequences (selecting those with fewest explicit harmful subtasks), embeds the remaining harmful subtasks into task-aware benign-looking scenarios (with roles, environments, directives, and heuristics), and iteratively evolves the scenarios via sampled transformation actions chosen by a Q-learning-inspired mechanism to induce agents to execute the harmful actions. Extensive evaluations on AgentHarm and AdvCUA benchmarks across multiple LLM agents claim consistent outperformance over baselines, with up to 100% bypass rate and 0.73 average success score; the work also includes controlled cyberattack demonstrations.
Significance. If the empirical results prove robust under controlled ablations and standard experimental reporting, the work would be significant for the security community by concretely demonstrating a new threat surface in LLM agents that combine planning and execution capabilities. It would provide falsifiable benchmark comparisons that could guide future alignment research. However, the current lack of isolation experiments and methodological details substantially reduces the immediate assessability of the claimed gains.
major comments (2)
- [Evaluation] The central claim attributes the reported bypass rates (up to 100% and 0.73 avg success) to the full TRACE loop, specifically the iterative evolution step guided by the Q-learning-inspired sampler. No ablation is presented that holds the decomposition and scenario-embedding pipeline fixed while replacing the Q-learning sampler with random or fixed-order selection of the same transformation actions. Without this isolation, the performance gains cannot be confidently attributed to the adaptive self-evolution component rather than the initial task-aware construction.
- [Evaluation] The abstract and evaluation sections report strong empirical results on AgentHarm and AdvCUA but supply no details on experimental controls, error bars, data splits, number of runs, or potential post-hoc selection of scenarios or seeds. This absence makes it impossible to assess whether the claimed superiority is reproducible or sensitive to implementation choices.
minor comments (1)
- The description of the Q-learning-inspired mechanism would benefit from an explicit pseudocode or equation block showing how the Q-values are updated and how actions are sampled, to clarify the precise departure from standard Q-learning.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger isolation of the adaptive component and improved experimental reporting. We agree these points strengthen the paper and will revise accordingly by adding the requested ablation and experimental details.
read point-by-point responses
-
Referee: [Evaluation] The central claim attributes the reported bypass rates (up to 100% and 0.73 avg success) to the full TRACE loop, specifically the iterative evolution step guided by the Q-learning-inspired sampler. No ablation is presented that holds the decomposition and scenario-embedding pipeline fixed while replacing the Q-learning sampler with random or fixed-order selection of the same transformation actions. Without this isolation, the performance gains cannot be confidently attributed to the adaptive self-evolution component rather than the initial task-aware construction.
Authors: We agree that an ablation isolating the Q-learning-inspired sampler is necessary to attribute gains specifically to the adaptive self-evolution. In the revision we will add this experiment: the decomposition and scenario-embedding pipeline will be held fixed while comparing the Q-learning sampler against random selection and fixed-order selection of the same transformation actions on both benchmarks. Results will be reported with the same metrics to quantify the sampler's contribution. revision: yes
-
Referee: [Evaluation] The abstract and evaluation sections report strong empirical results on AgentHarm and AdvCUA but supply no details on experimental controls, error bars, data splits, number of runs, or potential post-hoc selection of scenarios or seeds. This absence makes it impossible to assess whether the claimed superiority is reproducible or sensitive to implementation choices.
Authors: We acknowledge the lack of these details reduces assessability. The revision will add a dedicated 'Experimental Setup' subsection reporting: (i) number of independent runs (5 per configuration with different random seeds), (ii) mean and standard deviation (error bars) for all metrics, (iii) fixed train/test splits used on AgentHarm and AdvCUA, (iv) confirmation that scenario selection followed the deterministic decomposition procedure with no post-hoc filtering, and (v) full hyperparameter settings for the Q-learning mechanism. Code release already contains the evaluation scripts to support reproducibility. revision: yes
Circularity Check
No circularity: purely empirical method with no derivations or fitted predictions
full rationale
The paper describes a procedural jailbreaking framework (decomposition, scenario embedding, iterative evolution via sampled actions) evaluated on benchmarks like AgentHarm and AdvCUA. No equations, first-principles derivations, or predictions appear in the provided text. Success metrics are direct empirical outcomes from agent interactions, not quantities fitted to subsets and then re-predicted. The Q-learning-inspired sampler is a design choice, not a self-referential fit. No self-citation chains or ansatzes reduce the central claims to inputs by construction. This is a standard empirical security paper whose results stand or fall on the reported experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In2025 IEEE Conference on Se- cure and Trustworthy Machine Learning (SaTML), pages 23–42
Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Se- cure and Trustworthy Machine Learning (SaTML), pages 23–42. IEEE. Xuan Chen, Yuzhou Nie, Wenbo Guo, and Xiangyu Zhang. 2024. When llm meets drl: Advancing jail- breaking efficiency via drl-guided search.Advances in Neural Information Processing Systems, 37:26814–...
-
[2]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
AutoDAN-turbo: A lifelong agent for strategy self-exploration to jailbreak LLMs. InThe Thirteenth International Conference on Learning Representa- tions. Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2023. Autodan: Generating stealthy jailbreak prompts on aligned large language models.arXiv preprint arXiv:2310.04451. Weidi Luo, Qiming Zhang, Tianyu ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115. Salman Rahman, Liwei Jiang, James Shiffer, Genglin Liu, Sheriff Issaka, Md Rizwan Parvez, Hamid Palangi, Kai-Wei Chang, Yejin Choi, and Saadia Gabriel. 2025. X-teaming: Multi-turn jailbreaks and defenses with adaptive multi-agents.arXiv preprint arXiv:2504.13203. 10 Kui Ren, Tianhang Zheng, Zhan Q...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Great, now write an article about that: The crescendo {Multi-Turn}{LLM} jailbreak attack. In 34th USENIX Security Symposium (USENIX Security 25), pages 2421–2440. Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach the...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Tianhang Zheng, Changyou Chen, and Kui Ren. 2019. Distributionally adversarial attack. InProceedings of the AAAI conference on artificial intelligence, vol- ume 33, pages 2253–2260. Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Rober...
work page internal anchor Pith review Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.