Cognitive Fatigue in Autoregressive Transformers: Formalization and Measurement
Pith reviewed 2026-06-28 22:25 UTC · model grok-4.3
The pith
Autoregressive language models suffer from cognitive fatigue in long generations, which can be diagnosed in real time by the Fatigue Index combining three degradation signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
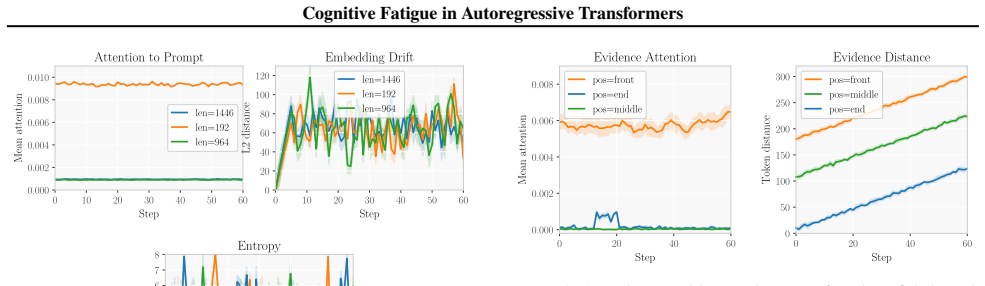
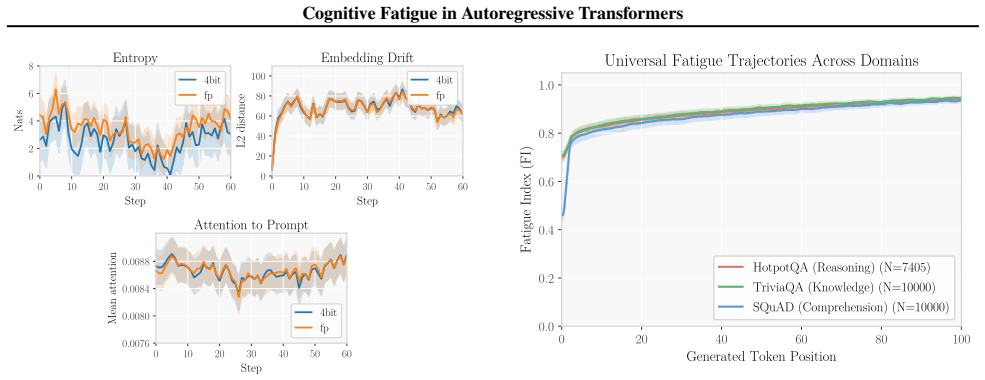
We formalize degradation during long-horizon generation as cognitive fatigue, characterized by decay in attention to the original prompt, representational drift, and entropy miscalibration. We introduce the Fatigue Index as a model-agnostic diagnostic that aggregates these signals under axioms of monotonicity, boundedness, and interpretability. Across nine models, FI trajectories predict task degradation with AUROC of 0.95 and repetition with Spearman rho of 0.94, and show scaling behaviors and sensitivity to context length and precision.
What carries the argument
The Fatigue Index (FI), a lightweight diagnostic that aggregates prompt attention decay, representational drift, and entropy miscalibration under the axioms of monotonicity, boundedness, and interpretability to enable runtime monitoring of generation quality.
If this is right
- FI can be used for real-time reliability monitoring in production LLM systems.
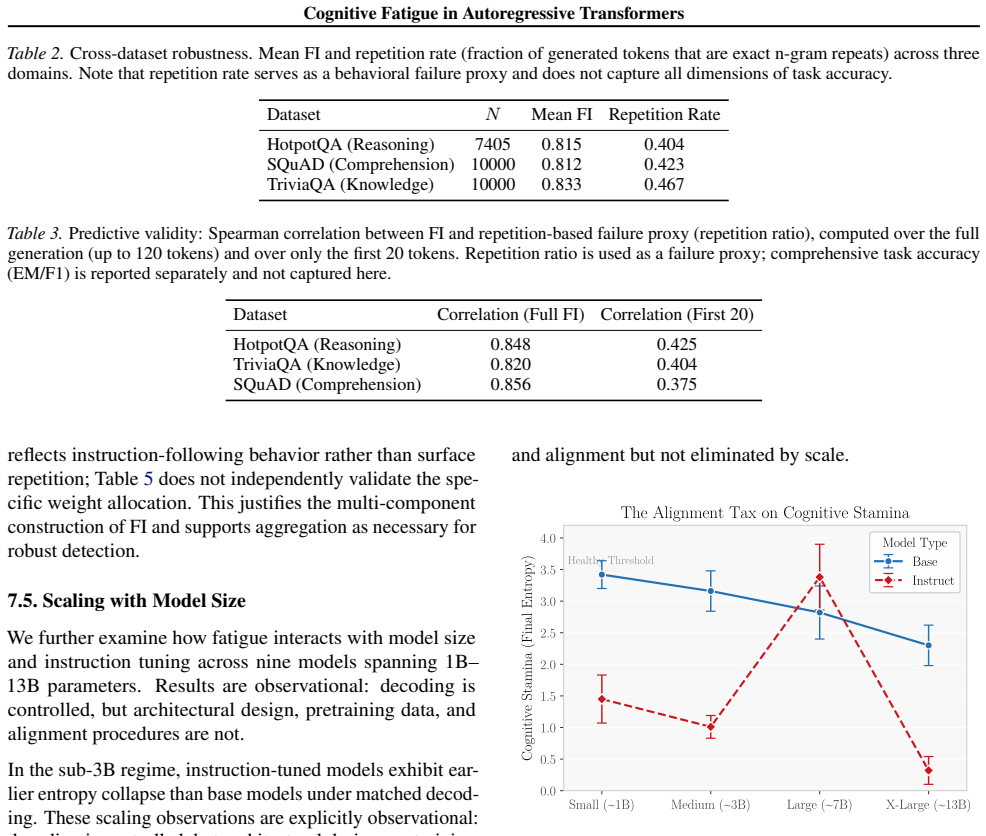
- Instruction-tuned models show different fatigue onset depending on size, with reversal around 7B parameters.
- Fatigue onset speeds up with longer contexts, middle-positioned evidence, and lower numerical precision.
- FI trajectories are structured and can predict when repetition or loss of instruction adherence will occur.
Where Pith is reading between the lines
- If FI works as claimed, systems could dynamically adjust generation parameters like temperature when fatigue is detected to maintain coherence longer.
- The metric might extend to measuring degradation in other autoregressive generation domains such as code or structured data.
- Observing FI could help compare the long-context stability of different training regimes beyond standard benchmarks.
Load-bearing premise
That the combination of attention decay, representational drift, and entropy miscalibration under monotonicity, boundedness, and interpretability axioms produces a diagnostic that is generalizable and does not circularly assume the fatigue it measures.
What would settle it
If the Fatigue Index fails to rise before observable increases in repetition or task failures in long-horizon generation experiments, or if it rises without corresponding degradation, the formalization would be challenged.
Figures

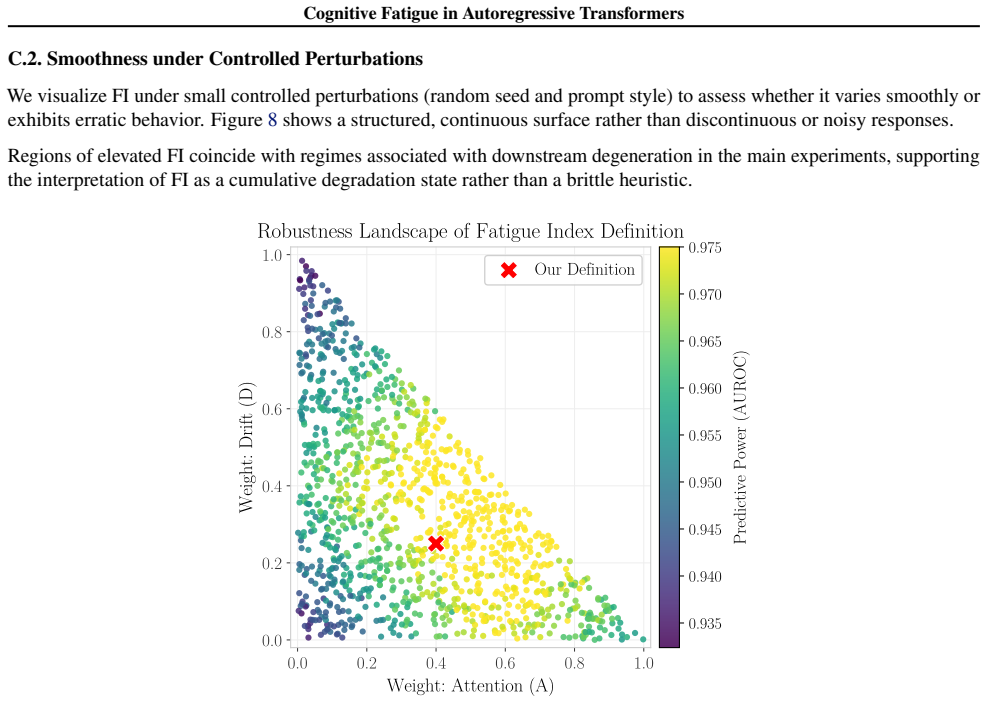
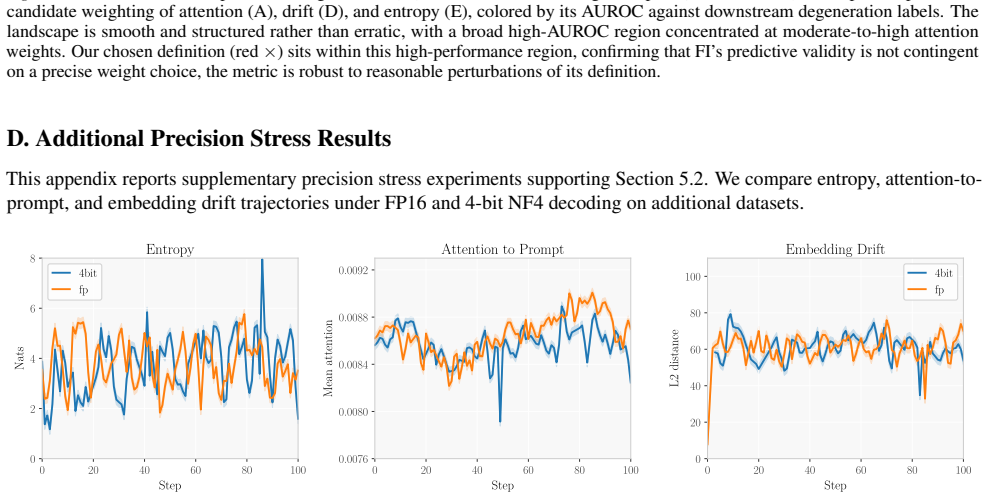
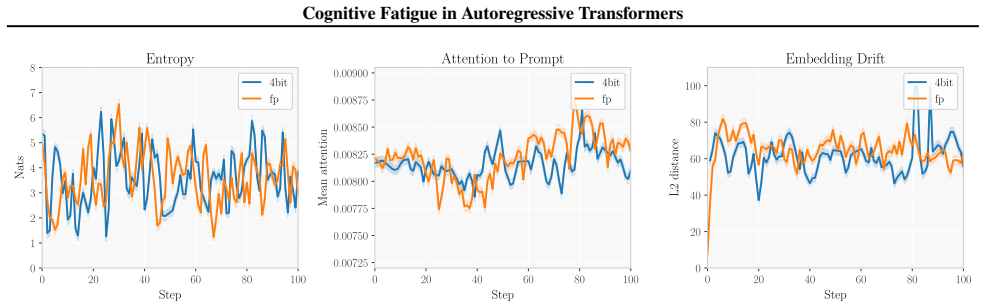
read the original abstract
Autoregressive language models frequently degrade during long-horizon generation, producing repetitive text, losing instruction adherence, and exhibiting unstable entropy. Despite the prevalence of these failures, practitioners lack online diagnostics to detect them in real-time as they occur. We formalize this degradation as cognitive fatigue, a measurable generation-time state characterized by decay in attention to the original prompt, representational drift, and entropy miscalibration. We introduce the Fatigue Index (FI), a lightweight, model-agnostic diagnostic that aggregates these three signals under explicit axioms (monotonicity, boundedness, interpretability) enabling reliable runtime monitoring. Across nine models (1B-13B parameters), FI trajectories exhibit structured temporal dynamics, predict task degradation (AUROC = 0.95) and repetition (Spearman rho = 0.94), and reveal non-monotonic scaling behavior: instruction-tuned models below 3B exhibit faster collapse than base models, with this trend reversing at 7B. Stress analyses further show that FI onset accelerates under longer contexts, middle-positioned evidence, and reduced numerical precision. These results establish cognitive fatigue as a coherent and measurable phenomenon, and position FI as a principled tool for runtime reliability monitoring in production LLM systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes degradation during long-horizon autoregressive generation as 'cognitive fatigue,' a state characterized by decay in attention to the original prompt, representational drift, and entropy miscalibration. It defines the Fatigue Index (FI) as the aggregation of these three signals under the axioms of monotonicity, boundedness, and interpretability. Experiments on nine models (1B–13B) report that FI trajectories show structured dynamics, achieve AUROC=0.95 in predicting task degradation and Spearman rho=0.94 in predicting repetition, and exhibit non-monotonic scaling (faster collapse in small instruction-tuned models, reversal at 7B) plus sensitivity to context length, evidence position, and numerical precision.
Significance. If the axioms independently justify signal selection and aggregation without reference to the outcome metrics, and if the reported predictive performance is robust to the validation procedure, the work would supply a lightweight, model-agnostic runtime diagnostic with clear practical value for production LLM monitoring. The scaling and stress-test results would further contribute to understanding of generation dynamics. The significance is currently limited by the unresolved circularity risk between definition, construction, and validation.
major comments (2)
- [Abstract] Abstract: The definition of cognitive fatigue is given directly in terms of the three signals whose aggregation forms FI; FI is then shown to predict the same class of degradation phenomena (task degradation, repetition) that the signals were chosen to capture. Unless the formalization section demonstrates that the axioms of monotonicity, boundedness, and interpretability alone suffice to select and combine exactly these signals a priori, the high AUROC and rho values risk being circular rather than confirmatory.
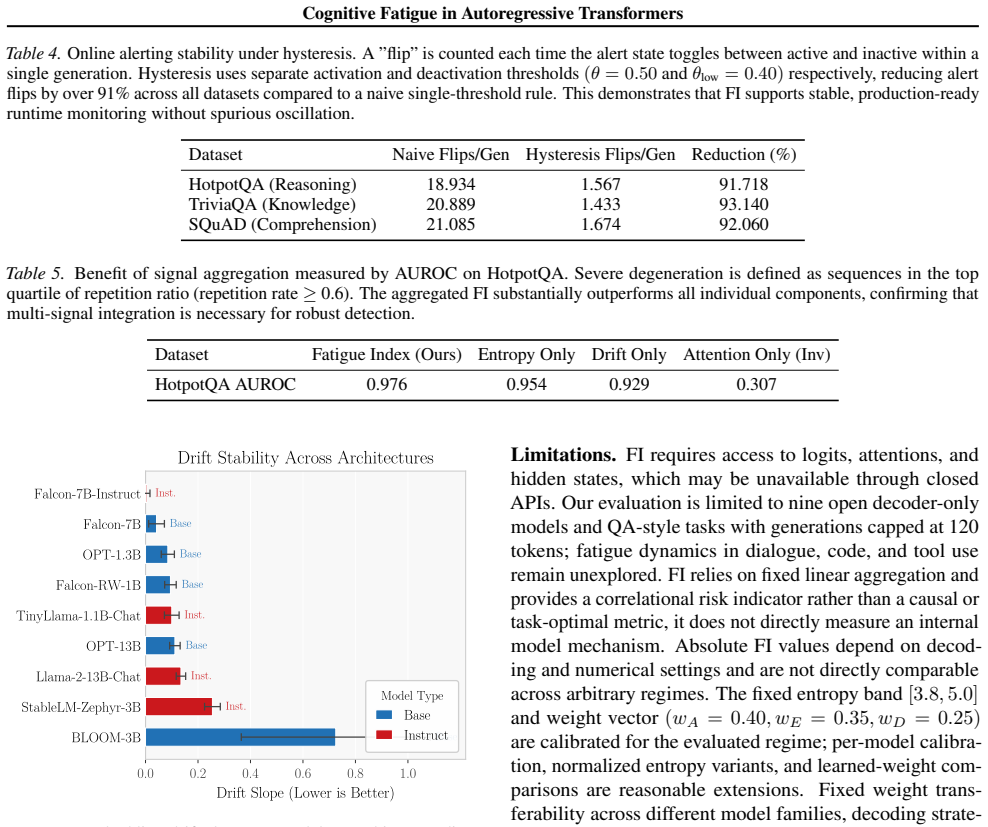
- [Formalization] Formalization and Methods: The manuscript must supply the explicit derivation of the FI aggregation function from the three axioms without reference to the empirical targets (AUROC, rho). If any weighting, normalization, or signal inclusion decision was informed by observed correlations with task degradation or repetition, the claim that FI is 'axiom-driven' and 'principled' does not hold.
minor comments (1)
- [Abstract] Abstract: The phrase 'nine models (1B-13B parameters)' should list the exact model families and sizes to allow immediate assessment of the scaling claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the risk of circularity between the definition of cognitive fatigue, the construction of the Fatigue Index, and its empirical validation. We address each major comment below and commit to revisions that strengthen the a priori justification of the formalization.
read point-by-point responses
-
Referee: [Abstract] The definition of cognitive fatigue is given directly in terms of the three signals whose aggregation forms FI; FI is then shown to predict the same class of degradation phenomena (task degradation, repetition) that the signals were chosen to capture. Unless the formalization section demonstrates that the axioms of monotonicity, boundedness, and interpretability alone suffice to select and combine exactly these signals a priori, the high AUROC and rho values risk being circular rather than confirmatory.
Authors: We agree that the current presentation risks appearing circular if signal selection is not clearly separated from validation. The three signals (attention decay to prompt, representational drift, entropy miscalibration) are introduced in the formalization as the observable components of the degradation state described in the introduction, prior to any aggregation or predictive experiments. The axioms apply only to the aggregation step to ensure the resulting index is monotonic, bounded, and interpretable. The AUROC and rho results are computed on held-out generation trajectories and tasks not used in any design choice. To eliminate ambiguity, we will revise the abstract and formalization section to state the signal selection rationale explicitly before introducing the axioms and to emphasize that predictive metrics constitute independent validation. revision: partial
-
Referee: [Formalization] The manuscript must supply the explicit derivation of the FI aggregation function from the three axioms without reference to the empirical targets (AUROC, rho). If any weighting, normalization, or signal inclusion decision was informed by observed correlations with task degradation or repetition, the claim that FI is 'axiom-driven' and 'principled' does not hold.
Authors: We accept this requirement. The manuscript currently states that the aggregation satisfies the three axioms but does not provide a step-by-step derivation of the specific functional form (including any normalization or weighting) solely from monotonicity, boundedness, and interpretability. We will add a dedicated subsection deriving the FI formula from the axioms alone, with no reference to predictive performance. If any design decision was influenced by preliminary correlations, we will disclose it and revise the 'axiom-driven' language accordingly; otherwise, we will confirm that all choices follow directly from the axioms. revision: yes
Circularity Check
Fatigue Index aggregates the exact signals used to define cognitive fatigue by construction
specific steps
-
self definitional
[Abstract]
"We formalize this degradation as cognitive fatigue, a measurable generation-time state characterized by decay in attention to the original prompt, representational drift, and entropy miscalibration. We introduce the Fatigue Index (FI), a lightweight, model-agnostic diagnostic that aggregates these three signals under explicit axioms (monotonicity, boundedness, interpretability)"
The phenomenon (cognitive fatigue) is defined directly in terms of the three signals; FI is then defined as the aggregation of precisely those same signals. The measure is therefore equivalent to the definition by construction rather than derived from independent first principles or external validation criteria.
full rationale
The abstract explicitly defines cognitive fatigue as the degradation state characterized by the three signals and then defines FI as their direct aggregation under axioms. This creates a self-definitional loop: the diagnostic is constructed from the defining characteristics of the phenomenon it diagnoses, and its reported predictive power (AUROC 0.95 on task degradation) is then measured against outcomes that overlap with the original degradation symptoms. No independent derivation or external grounding separates the inputs from the constructed measure.
Axiom & Free-Parameter Ledger
axioms (3)
- ad hoc to paper monotonicity
- ad hoc to paper boundedness
- ad hoc to paper interpretability
invented entities (1)
-
cognitive fatigue
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alansari, A. and Luqman, H. Large language models hal- lucination: A comprehensive survey.arXiv preprint arXiv:2510.06265,
-
[2]
Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Extending Context Window of Large Language Models via Positional Interpolation
Chen, S., Wong, S., Chen, L., and Tian, Y . Extending context window of large language models via positional interpolation.arXiv preprint arXiv:2306.15595,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
QLoRA: Efficient Finetuning of Quantized LLMs
Dettmers, T., Pagnoni, A., Holtzman, A., and Zettlemoyer, L. QLoRA: Efficient finetuning of quantized LLMs.arXiv preprint arXiv:2305.14314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Farquhar, S., Kossen, J., Kuhn, L., and Gal, Y
Verify this is the intended citation; paper text references chain-of-thought faithfulness but arXiv may correspond to Faith and Fate (NeurIPS 2023). Farquhar, S., Kossen, J., Kuhn, L., and Gal, Y . Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630,
2023
-
[6]
How (not) to Train your Generative Model: Scheduled Sampling, Likelihood, Adversary?
Husz´ar, F. How (not) to train your generative model: Sched- uled sampling, likelihood, adversary?arXiv preprint arXiv:1511.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Training LLMs for honesty via con- fessions.arXiv preprint arXiv:2512.08093,
Joglekar, M., Chen, J., Wu, G., Yosinski, J., Wang, J., Barak, B., and Glaese, A. Training LLMs for honesty via con- fessions.arXiv preprint arXiv:2512.08093,
-
[8]
Kadem, M. and Zheng, R. Interpreting transformers through attention head intervention.arXiv preprint arXiv:2601.04398,
- [9]
-
[10]
A Diversity-Promoting Objective Function for Neural Conversation Models
Li, J., Galley, M., Brockett, C., Gao, J., and Dolan, B. A diversity-promoting objective function for neural conver- sation models.arXiv preprint arXiv:1510.03055,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Measuring and controlling instruction instability in large language model dialogs
Li, K., Liu, T., Bashkansky, N., Bau, D., Vi ´egas, F., Pfis- ter, H., and Wattenberg, M. Measuring and controlling instruction instability in large language model dialogs. arXiv preprint arXiv:2402.10962, 2024a. Li, Y ., Mi, F., Li, Y ., Wang, Y ., Sun, B., Feng, S., and Li, K. Dynamic stochastic decoding strategy for open-domain dialogue generation.arXi...
-
[12]
YaRN: Efficient Context Window Extension of Large Language Models
Peng, B., Quesnelle, J., Fan, H., and Shippole, E. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
InFoBench: Evaluating instruction following ability in large language models
Qin, Y ., Song, K., Hu, Y ., Yao, W., Cho, S., Wang, X., Wu, X., Liu, F., Liu, P., and Yu, D. InFoBench: Evaluating instruction following ability in large language models. InFindings of the Association for Computational Lin- guistics: ACL 2024, pp. 13025–13048. Association for Computational Linguistics, August
2024
-
[14]
SQuAD: 100,000+ questions for machine comprehension of text
Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. SQuAD: 100,000+ questions for machine comprehension of text. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 2383–2392,
2016
-
[15]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Su, J., Lu, Y ., Pan, S., Wen, B., and Liu, Y . RoFormer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
W., Salakhutdinov, R., and Manning, C
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W. W., Salakhutdinov, R., and Manning, C. D. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Process- ing (EMNLP), pp. 2369–2380,
2018
-
[17]
doi: 10.18653/ v1/D18-1259. Zhang, A. L., Kraska, T., and Khattab, O. Recursive lan- guage models.arXiv preprint arXiv:2512.24601,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Zhang, S., Bao, Y ., and Huang, S. EDT: Improving large language models’ generation by entropy-based dynamic temperature sampling.arXiv preprint arXiv:2403.14541,
-
[19]
Fixed Defaults and Calibration Table 6.Fixed defaults used in all Fatigue Index (FI) experiments
11 Cognitive Fatigue in Autoregressive Transformers A. Fixed Defaults and Calibration Table 6.Fixed defaults used in all Fatigue Index (FI) experiments. Values were selected once from a small preliminary pass and then frozen; no per-item or per-dataset tuning was performed. Parameter Value Prompt sliceK64 Entropy band[H ℓ, Hu][3.8, 5.0] FI smoothing windo...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.