HetCCL: Enabling Collective Communication For Mixed-Vendor Heterogeneous Clusters
Pith reviewed 2026-06-28 20:14 UTC · model grok-4.3
The pith
HetCCL enables high-bandwidth collective communication across mixed-vendor GPU clusters by combining direct P2P transport with vendor-native reductions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
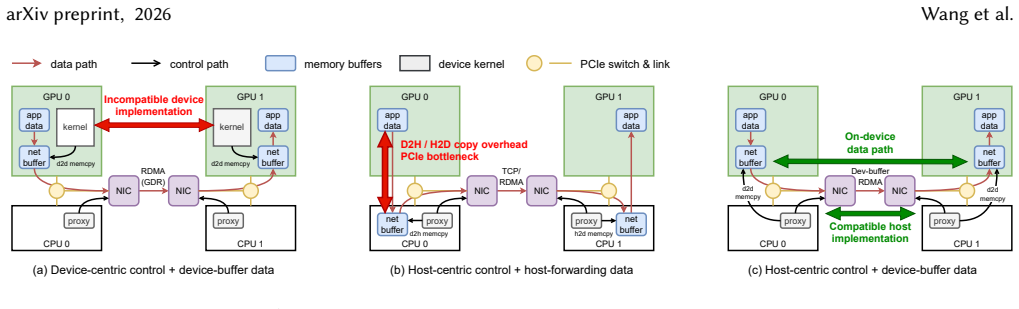
HetCCL achieves vendor independence for combining collectives by using the intrinsic reduction already present inside each vendor's collective communication library, while efficient heterogeneous P2P transport removes host-device copies and a hierarchical topology abstraction guarantees optimal cross-cluster data transfer volume.
What carries the argument
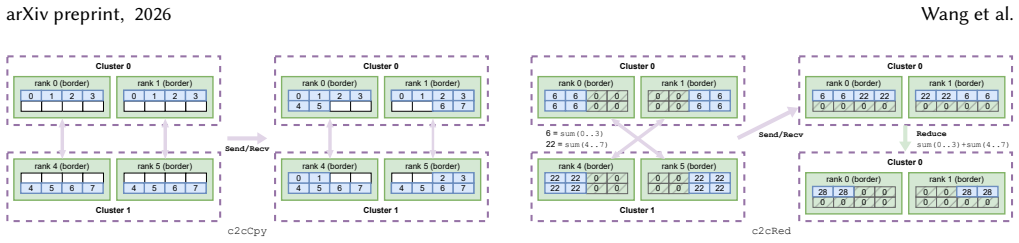
The border-communicator mechanism, which achieves vendor independence by using the intrinsic reduction in the combining collectives in vendor collective communication libraries without compatibility issues.
If this is right
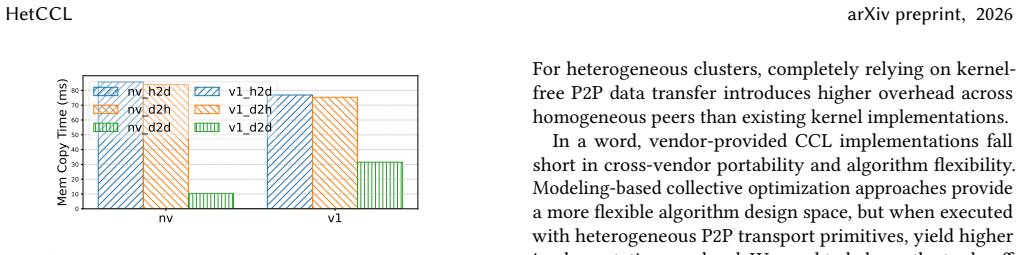
- HetCCL delivers 17-19x higher bandwidth than Gloo for heterogeneous communications.
- End-to-end LLM training per-step time improves by up to 16.9 percent.
- The framework supports four different vendors and four heterogeneous cluster settings.
- Collective communication is decomposed into cluster-level primitives that keep cross-cluster transfer volume minimal.
- Control is offloaded to CPUs while data movement stays on the devices.
Where Pith is reading between the lines
- The same P2P-plus-border pattern could be applied to non-combining collectives such as Broadcast or AllGather.
- Clusters could be assembled from lower-cost hardware mixes that were previously ruled out by communication limits.
- The hierarchical topology abstraction may help schedulers decide when to place model layers across vendor boundaries.
Load-bearing premise
The border-communicator mechanism achieves vendor independence by using the intrinsic reduction in the combining collectives in vendor collective communication libraries without introducing compatibility issues or measurable overhead across all supported vendors.
What would settle it
A measurement on a previously untested vendor pair that shows either a compatibility failure or added latency when the border-communicator is active would falsify the claim of portable reduction without overhead.
Figures









read the original abstract
Training Large Language Models (LLMs) on heterogeneous clusters presents significant challenges for collective communication, as hardware from multiple vendors introduces diverse network and computational characteristics. Existing collective communication frameworks (e.g., NCCL, RCCL) designed for homogeneous environments fail to address mixed-hardware setups, while communication libraries with heterogeneous support (e.g., Gloo, OpenMPI) incur heavy overhead in the data path. This paper presents HetCCL, a framework that enables heterogeneous collective communication by efficient P2P transport across heterogeneous devices (e.g., GPUs), eliminating the host-device memory copy overhead while offloading the control to the CPUs. For combining collectives (e.g., AllReduce, ReduceScatter), HetCCL introduces a border-communicator mechanism that achieves vendor independence by using the intrinsic reduction in the combining collectives in vendor collective communication libraries. With efficient heterogeneous P2P transport and portable reduction mechanism, HetCCL proposes a hierarchical topology abstraction for heterogeneous clusters, dissecting collective communication into cluster-level primitives that guarantee optimal cross-cluster data transfer volume and optimal bandwidth utilization. We implement HetCCL with 4 different vendor support and evaluate it in 4 heterogeneous settings with benchmarks and end-to-end LLM tasks. Our evaluation shows that HetCCL achieves 17-19x higher bandwidth than Gloo in heterogeneous communications, and speeds up end-to-end training by up to 16.9% in the per-step-time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HetCCL, a framework for collective communication in mixed-vendor heterogeneous GPU clusters used for LLM training. It introduces efficient P2P transport across devices to avoid host-device copies, a border-communicator mechanism that delegates reduction to vendor-native combining collectives (AllReduce/ReduceScatter) for vendor independence, and a hierarchical topology abstraction that decomposes communication into cluster-level primitives for optimal data volume and bandwidth. The work claims support for four vendors and reports empirical results from four heterogeneous settings, including 17-19x higher bandwidth than Gloo and up to 16.9% improvement in per-step training time.
Significance. If the performance claims are substantiated, the work would be significant for practical deployment of large-scale training on cost-effective heterogeneous clusters, filling a gap left by homogeneous-focused libraries like NCCL/RCCL and high-overhead heterogeneous ones like Gloo. The empirical focus on end-to-end LLM tasks provides direct evidence of applicability, though the absence of reproducibility artifacts (e.g., code or detailed benchmarks) limits immediate impact.
major comments (2)
- [Abstract] Abstract: The headline claims of 17-19x bandwidth improvement over Gloo and 16.9% end-to-end per-step speedup are presented with no description of experimental setup, hardware configurations for the four heterogeneous settings, number of runs, error bars, statistical tests, or data exclusion rules. These numbers are load-bearing for the central empirical contribution and cannot be assessed without this information.
- [Design and Evaluation] Border-communicator mechanism (design and evaluation sections): The claim that this mechanism achieves vendor independence with zero measurable overhead by delegating to intrinsic reduction in each vendor's collective library (without compatibility issues or host fallbacks) is central to attributing the reported speedups to the framework rather than implementation artifacts. No per-vendor micro-benchmarks isolating delegation latency or confirming successful hand-off across all four vendors are described, leaving the weakest assumption untested.
minor comments (1)
- [Abstract] The abstract and evaluation summary refer to '4 different vendor support' and '4 heterogeneous settings' without naming the vendors or providing a table summarizing the cluster compositions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below with clarifications from the manuscript and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims of 17-19x bandwidth improvement over Gloo and 16.9% end-to-end per-step speedup are presented with no description of experimental setup, hardware configurations for the four heterogeneous settings, number of runs, error bars, statistical tests, or data exclusion rules. These numbers are load-bearing for the central empirical contribution and cannot be assessed without this information.
Authors: The abstract provides a concise summary of results; the Evaluation section contains the full experimental details, including hardware configurations for the four heterogeneous settings, number of runs, and performance metrics. To improve accessibility of the headline claims, we will revise the abstract to briefly reference the key experimental configurations and direct readers to the Evaluation section for complete setup, statistical, and reproducibility information. revision: yes
-
Referee: [Design and Evaluation] Border-communicator mechanism (design and evaluation sections): The claim that this mechanism achieves vendor independence with zero measurable overhead by delegating to intrinsic reduction in each vendor's collective library (without compatibility issues or host fallbacks) is central to attributing the reported speedups to the framework rather than implementation artifacts. No per-vendor micro-benchmarks isolating delegation latency or confirming successful hand-off across all four vendors are described, leaving the weakest assumption untested.
Authors: The border-communicator delegates reduction to each vendor's native combining collectives to ensure independence and avoid host fallbacks, with the four-vendor support and heterogeneous evaluation results demonstrating successful operation. While overall bandwidth and end-to-end gains provide supporting evidence, we agree that isolated per-vendor micro-benchmarks would more directly confirm zero delegation overhead. We will add these micro-benchmarks to the revised Design and Evaluation sections. revision: yes
Circularity Check
No circularity: empirical systems paper with benchmark-driven claims
full rationale
The paper describes an implementation framework (HetCCL) for heterogeneous collective communication, introducing mechanisms like border-communicator and hierarchical topology abstraction. All central claims (17-19x bandwidth improvement, 16.9% end-to-end speedup) are presented as outcomes of empirical evaluation across four vendors and settings, with no equations, fitted parameters, derivations, or self-citation chains that reduce the reported results to inputs by construction. The weakest assumption (zero-overhead vendor independence via intrinsic reduction) is an engineering claim tested in benchmarks rather than a self-definitional or fitted quantity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption P2P transport between heterogeneous devices eliminates host-device memory copy overhead
- domain assumption Vendor collective libraries expose intrinsic reduction operations that can be composed portably
invented entities (1)
-
border-communicator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024. OpenMPI. (2024).https://www.open-mpi.org/
2024
-
[2]
AMD. 2024. AMD Instinct Accelerators. (2024).https://www.amd. com/en/products/accelerators/instinct.html
2024
-
[3]
AMD. 2024. RCCL. (2024).https://github.com/ROCm/rccl
2024
-
[4]
AMD. 2024. ROCm. (2024).https://www.amd.com/en/products/ software/rocm.html
2024
-
[5]
Wei An, Xiao Bi, Guanting Chen, Shanhuang Chen, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Wenjun Gao, Kang Guan, et al
-
[6]
InSC24: International Conference for High Performance Computing, Networking, Storage and Analysis
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co- Design for Deep Learning. InSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–23
-
[7]
Zixian Cai, Zhengyang Liu, Saeed Maleki, Madanlal Musuvathi, Todd Mytkowicz, Jacob Nelson, and Olli Saarikivi. 2021. Synthesizing op- timal collective algorithms. InProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. 62–75
2021
-
[8]
Chen-Chun Chen, Kawthar Shafie Khorassani, Pouya Kousha, Qinghua Zhou, Jinghan Yao, Hari Subramoni, and Dhabaleswar K Panda. 2023. MPI-xCCL: A Portable MPI Library over Collective Communication Libraries for Various Accelerators. InProceedings of the SC’23 Work- shops of The International Conference on High Performance Computing, Network, Storage, and Ana...
2023
-
[9]
Hongzheng Chen, Jiahao Zhang, Yixiao Du, Shaojie Xiang, Zichao Yue, Niansong Zhang, Yaohui Cai, and Zhiru Zhang. 2024. Understanding the potential of fpga-based spatial acceleration for large language model inference.ACM Transactions on Reconfigurable Technology and Systems(2024)
2024
-
[10]
UCF Consortium. 2024. Unified Communication X Library Source Codehttps://github.com/openucx/ucx. (2024)
2024
-
[11]
UCF Consortium. 2024. Unified Communication Xhttps://openucx. org/. (2024)
2024
-
[12]
NVIDIA Corporation. 2026. GPU-Direct RDMA (GDR).https:// developer.nvidia.com/gpudirect. (2026). Accessed: 2026-02-07
2026
-
[13]
NVIDIA Corporation. 2026. NVSHMEM: NVIDIA SHMEM Library. https://developer.nvidia.com/nvshmem. (2026). Accessed: 2026-02-07
2026
-
[14]
Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
-
[15]
DeepSeek-V3 Technical Report. (2024). arXiv:cs.CL/2412.19437 https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Facebook. 2024. Gloo. (2024).https://github.com/facebookincubator/ gloo/
2024
-
[17]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch trans- formers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
2022
-
[18]
Graphcore. 2024. Graphcore. (2024).https://www.graphcore.ai/
2024
-
[19]
Khaled Hamidouche, Akshay Venkatesh, Ammar Ahmad Awan, Hari Subramoni, Ching-Hsiang Chu, and Dhabaleswar K Panda. 2015. Ex- ploiting GPUDirect RDMA in designing high performance OpenSH- MEM for NVIDIA GPU clusters. In2015 IEEE International Conference on Cluster Computing. IEEE, 78–87
2015
-
[20]
Seongmin Hong, Seungjae Moon, Junsoo Kim, Sungjae Lee, Minsub Kim, Dongsoo Lee, and Joo-Young Kim. 2022. Dfx: A low-latency multi- fpga appliance for accelerating transformer-based text generation. In 2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 616–630
2022
-
[21]
Yingbing Huang, Lily Jiaxin Wan, Hanchen Ye, Manvi Jha, Jinghua Wang, Yuhong Li, Xiaofan Zhang, and Deming Chen. 2024. New solutions on LLM acceleration, optimization, and application. InPro- ceedings of the 61st ACM/IEEE Design Automation Conference. 1–4
2024
-
[22]
Huawei. 2024. Ascend Computing. (2024).https://e.huawei.com/en/ products/computing/ascend
2024
-
[23]
Intel. 2024. OneCCL. (2024).https://www.intel.com/content/www/us/ en/developer/tools/oneapi/oneccl.html
2024
-
[24]
Xianyan Jia, Le Jiang, Ang Wang, Wencong Xiao, Ziji Shi, Jie Zhang, Xinyuan Li, Langshi Chen, Yong Li, Zhen Zheng, et al. 2022. Whale: Efficient giant model training over heterogeneous {GPUs }. In2022 USENIX Annual Technical Conference (USENIX ATC 22). 673–688
2022
-
[25]
Christoforos Kachris. 2025. A survey on hardware accelerators for large language models.Applied Sciences15, 2 (2025), 586
2025
-
[26]
Khronos. 2024. SYCL. (2024).https://www.khronos.org/sycl/
2024
-
[27]
Heehoon Kim, Junyeol Ryu, and Jaejin Lee. 2024. TCCL: Discovering Better Communication Paths for PCIe GPU Clusters. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. 999–1015
2024
-
[28]
Xuting Liu, Behnaz Arzani, Siva Kesava Reddy Kakarla, Liangyu Zhao, Vincent Liu, Miguel Castro, Srikanth Kandula, and Luke Marshall
-
[29]
InProceedings of the ACM SIGCOMM 2024 Conference
Rethinking machine learning collective communication as a multi-commodity flow problem. InProceedings of the ACM SIGCOMM 2024 Conference. 16–37
2024
-
[30]
Llama Team, AI @ Meta. 2024. The Llama 3 Herd of Models. (2024). arXiv:cs.AI/2407.21783https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Microsoft. 2024. MSCCL. (2024).https://github.com/microsoft/msccl
2024
-
[32]
NVIDIA. 2024. A100. (2024).https://www.nvidia.com/en-us/ data-center/a100/
2024
-
[33]
NVIDIA. 2024. NCCL. (2024).https://developer.nvidia.com/nccl
2024
-
[34]
OpenACC Organization. 2024. OpenACC. (2024).https://www. openacc.org/
2024
-
[35]
2020.{HetPipe}: Enabling large {DNN} training on (whimpy) heterogeneous {GPU } clusters through integration of pipelined model parallelism and data parallelism
Jay H Park, Gyeongchan Yun, M Yi Chang, Nguyen T Nguyen, Seung- min Lee, Jaesik Choi, Sam H Noh, and Young-ri Choi. 2020.{HetPipe}: Enabling large {DNN} training on (whimpy) heterogeneous {GPU } clusters through integration of pipelined model parallelism and data parallelism. In2020 USENIX Annual Technical Conference (USENIX ATC 20). 307–321. 14 HetCCL ar...
2020
-
[36]
Sreeram Potluri, Khaled Hamidouche, Akshay Venkatesh, Devendar Bureddy, and Dhabaleswar K Panda. 2013. Efficient inter-node MPI communication using GPUDirect RDMA for InfiniBand clusters with NVIDIA GPUs. In2013 42nd International Conference on Parallel Pro- cessing. IEEE, 80–89
2013
-
[37]
PyTorch. 2024. Custom C++ and CUDA Extensions. (2024).https: //pytorch.org/tutorials/advanced/cpp_extension.html
2024
-
[38]
PyTorch. 2024. Third-party backends. (2024).https://pytorch.org/ docs/stable/distributed.html#third-party-backends
2024
-
[39]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
-
[40]
ZeRO: Memory Optimizations Toward Training Trillion Param- eter Models. (2020). arXiv:cs.LG/1910.02054https://arxiv.org/abs/1910. 02054
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[41]
Xiaozhe Ren, Pingyi Zhou, Xinfan Meng, Xinjing Huang, Yadao Wang, Weichao Wang, Pengfei Li, Xiaoda Zhang, Alexander Podolskiy, Grig- ory Arshinov, Andrey Bout, Irina Piontkovskaya, Jiansheng Wei, Xin Jiang, Teng Su, Qun Liu, and Jun Yao. 2023. PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing. (2023). arXiv:cs.CL/2303....
-
[42]
Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musuvathi, Todd Mytkowicz, Jacob Nelson, Olli Saarikivi, and Rachee Singh. 2023. {TACCL}: Guiding Collective Algorithm Syn- thesis using Communication Sketches. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). 593–612
2023
-
[43]
Graham Lopez, Matthew B
Pavel Shamis, Manjunath Gorentla Venkata, M. Graham Lopez, Matthew B. Baker, Oscar Hernandez, Yossi Itigin, Mike Dubman, Gilad Shainer, Richard L. Graham, Liran Liss, Yiftah Shahar, Sreeram Potluri, Davide Rossetti, Donald Becker, Duncan Poole, Christopher Lamb, Sameer Kumar, Craig Stunkel, George Bosilca, and Aurelien Bouteiller
-
[44]
In2015 IEEE 23rd Annual Symposium on High-Performance Interconnects
UCX: An Open Source Framework for HPC Network APIs and Beyond. In2015 IEEE 23rd Annual Symposium on High-Performance Interconnects
-
[45]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2020. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. (2020). arXiv:cs.CL/1909.08053https://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[46]
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. 2019. Triton: an intermediate language and compiler for tiled neural network computa- tions. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages. 10–19
2019
-
[47]
Taegeon Um, Byungsoo Oh, Minyoung Kang, Woo-Yeon Lee, Goeun Kim, Dongseob Kim, Youngtaek Kim, Mohd Muzzammil, and Myeong- jae Jeon. 2024. Metis: Fast Automatic Distributed Training on Hetero- geneous GPUs. In2024 USENIX Annual Technical Conference (USENIX ATC 24). USENIX Association, Santa Clara, CA, 563–578.https: //www.usenix.org/conference/atc24/presen...
2024
-
[48]
Manjunath Gorentla Venkata, Valentine Petrov, Sergey Lebedev, De- vendar Bureddy, Ferrol Aderholdt, Joshua Ladd, Gil Bloch, Mike Dubman, and Gilad Shainer. 2024. Unified Collective Communi- cation (UCC): An Unified Library for CPU, GPU, and DPU Collec- tives. InIEEE Symposium on High-Performance Interconnects, HOTI 2024, Albuquerque, NM, USA, August 21-23...
-
[49]
Jinkyu Yim, Jaeyong Song, Yerim Choi, Jaebeen Lee, Jaewon Jung, Hongsun Jang, and Jinho Lee. 2024. Pipette: Automatic Fine-Grained Large Language Model Training Configurator for Real-World Clusters. In2024 Design, Automation and Test in Europe Conference and Exhi- bition, DATE 2024 - Proceedings (Proceedings -Design, Automation and Test in Europe, DATE). ...
2024
- [50]
- [51]
-
[52]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210. 15 arXiv preprint, 2026 Wang et al. Border rank Internal ran...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.