TRACE: Discovering Task-Specific Parameter via Adaptation-Aware Probing for Continual Fine-Tuning
Pith reviewed 2026-06-28 23:11 UTC · model grok-4.3
The pith
A short warm-start probe identifies the minimal parameters needed for each task so that only those are updated during continual fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
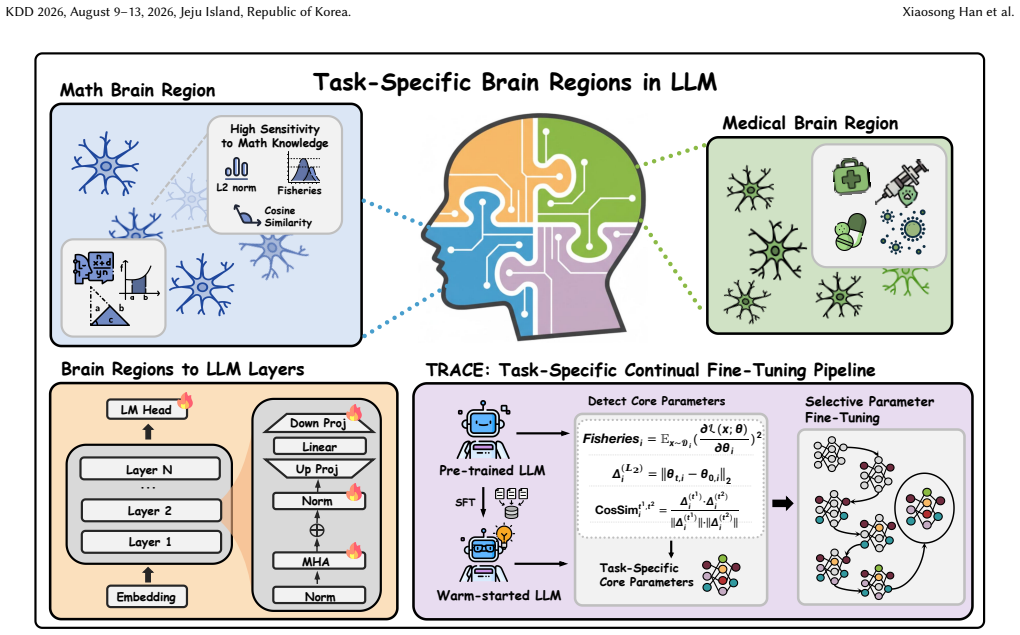
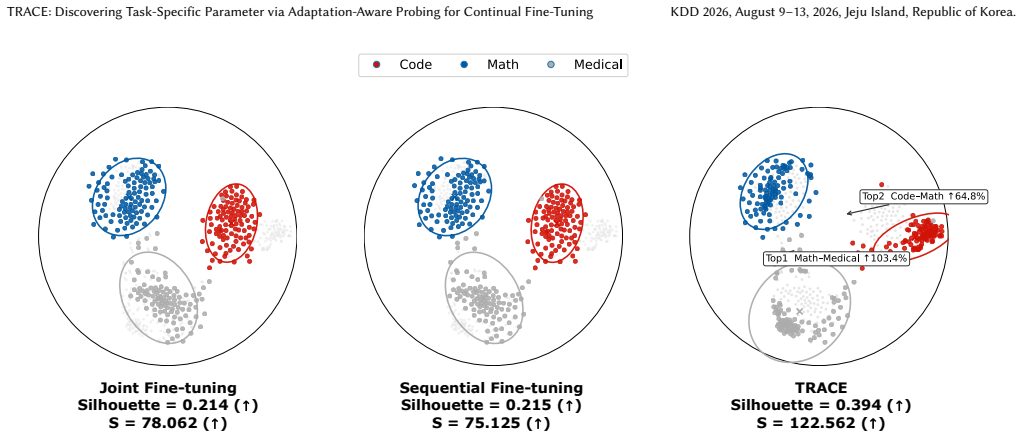
TRACE shows that a short warm-start fine-tune produces an adaptation trace from which task-specific core parameters can be extracted using L2 norm, Fisher information, and cosine similarity of updates; in subsequent continual fine-tuning only those parameters are updated while the rest remain frozen, thereby preserving performance on earlier tasks.
What carries the argument
Adaptation-aware probing via a short warm-start fine-tune that exposes the adaptation trace and isolates essential parameters through combined importance and specificity metrics.
If this is right
- Only the current task's core parameters receive updates while all others stay frozen.
- Prior task performance is retained without replay data or additional adapter modules.
- Storage and compute costs remain close to standard fine-tuning rather than growing with the number of tasks.
- The same probing procedure transfers from smaller to larger models, supporting resource-efficient scaling.
Where Pith is reading between the lines
- The same short-probe technique could be applied to sequential training in vision or reinforcement-learning models if parameter redundancy follows similar patterns.
- If importance scores remain stable across scales, the method offers a practical route for adapting frontier-scale models when only limited compute is available for the probe step.
- The localization of task changes suggests that future architectures might expose explicit task modules rather than relying on implicit parameter subsets.
Load-bearing premise
The parameters chosen by the probe using L2 norm, Fisher information, and cosine similarity of updates form a minimal sufficient set that can be updated independently without harming performance on previously learned tasks.
What would settle it
An experiment that updates only the probed parameters during continual fine-tuning and measures either a large accuracy drop on the new task relative to full fine-tuning or measurable forgetting on prior tasks.
Figures

read the original abstract
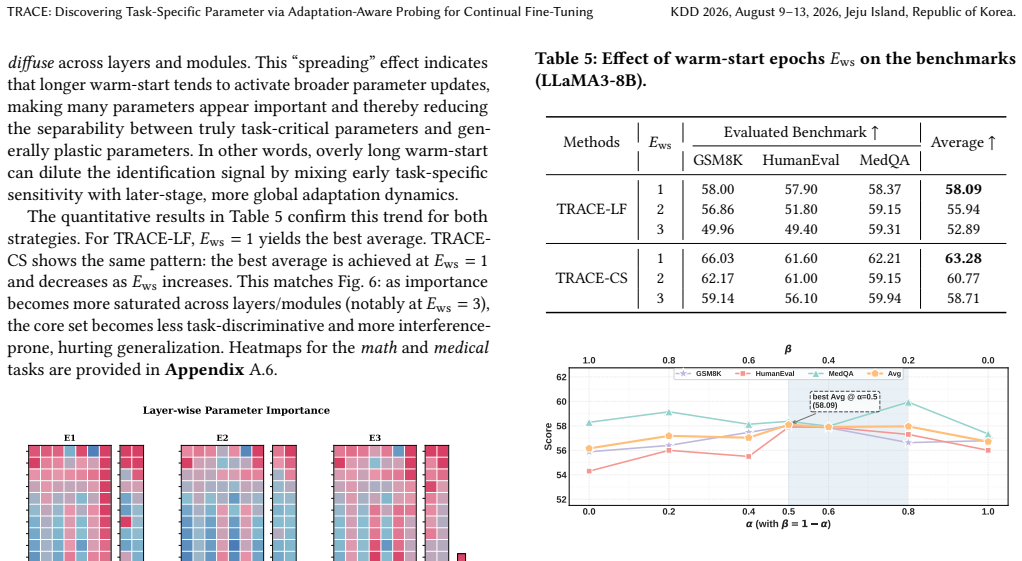
In real-world deployment, LLMs are often adapted continually across tasks to keep LLMs up-to-date in production, where new fine-tuning should preserve previously learned skills. However, indiscriminately mixing tasks can dilute task specialization, while sequential fine-tuning (full-parameter or low rank adaptation) often causes catastrophic forgetting due to destructive overwriting. Replay-based continual tuning and maintaining separate task-specific adapters can mitigate forgetting, but introduce additional compute, storage, and management overhead. Recognizing the redundancy of LLM parameters for any single task, we reframe continual task adaptation as task-specific parameter discovery via adaptation-aware probing: a short warm-start probe exposes a task's adaptation trace, enabling us to identify and isolate the small subset of parameters essential for each task to mitigate catastrophic forgetting. Building on this view, we introduce TRACE, a novel approach for discovering Task-specific paRameters via Adaptation-aware probing for Continual finE-tuning. We perform a short warm-start fine-tune to derive task-specific core parameters by comparing the warm-started and pre-trained models. Core parameters are identified via two strategies: importance scoring (L$_2$ norm and Fisher Information) and specificity analysis (cosine similarity of parameter updates). In continual fine-tuning settings, only the active task's core parameters are updated while others remain frozen, preserving prior knowledge. We conduct extensive experiments across multiple standard benchmarks to demonstrate the superior performance of our proposed method. Additionally, we validate the generalization of our method through a cross-model and scale transferability study, demonstrating a "small-to-large" paradigm that guides the fine-tuning of large-scale models under resource constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TRACE, a method for continual fine-tuning of LLMs that performs a short warm-start probe to identify a small subset of task-specific core parameters using L2 norm, Fisher information, and cosine similarity of updates. Only these parameters are updated for the active task while others remain frozen, with the goal of mitigating catastrophic forgetting without the overhead of replay buffers or separate adapters. The paper claims superior performance on standard benchmarks and demonstrates cross-model/scale transferability in a small-to-large paradigm.
Significance. If the empirical results hold and the selected parameters prove minimal and sufficient, the approach could reduce compute and storage costs relative to existing continual learning strategies for LLMs, enabling more practical sequential adaptation in production settings.
major comments (2)
- [Abstract] Abstract: the central claim of 'superior performance' and 'extensive experiments' is asserted without any quantitative results, baselines, effect sizes, or ablation details, rendering the effectiveness of the warm-start probe and core-parameter selection impossible to assess.
- [§3] §3 (Method): the claim that parameters selected via the three metrics form a minimal sufficient set that can be updated independently rests on the untested assumption that freezing the remainder preserves prior tasks; no controls, overlap analysis between metrics, or failure-case experiments are described to validate this.
minor comments (2)
- [§3.2] Notation for the importance and specificity scores is described in prose only; explicit equations would improve reproducibility.
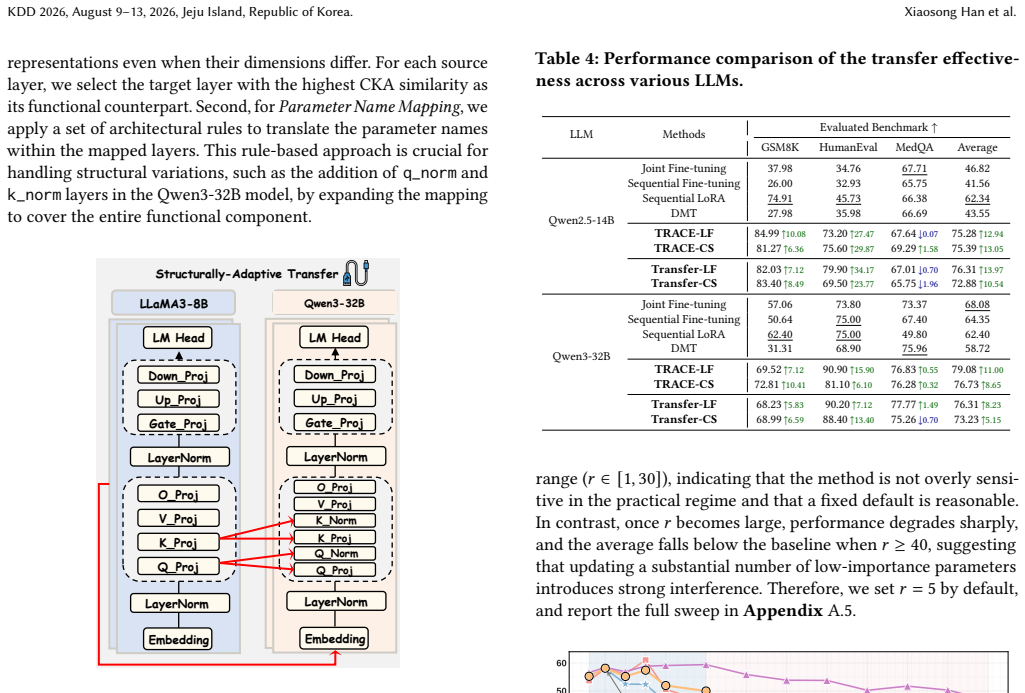
- [§5.3] The cross-model transfer study is mentioned but lacks details on how core parameters identified on small models are mapped or initialized for larger ones.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen clarity and validation where needed.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'superior performance' and 'extensive experiments' is asserted without any quantitative results, baselines, effect sizes, or ablation details, rendering the effectiveness of the warm-start probe and core-parameter selection impossible to assess.
Authors: We agree that including quantitative highlights in the abstract would improve immediate assessability. In the revision we will add specific results (e.g., average accuracy gains over full fine-tuning and replay baselines on the reported benchmarks) while keeping the abstract concise. revision: yes
-
Referee: [§3] §3 (Method): the claim that parameters selected via the three metrics form a minimal sufficient set that can be updated independently rests on the untested assumption that freezing the remainder preserves prior tasks; no controls, overlap analysis between metrics, or failure-case experiments are described to validate this.
Authors: The observation is fair; the current manuscript relies on end-to-end benchmark gains to support the sufficiency claim but does not explicitly quantify metric overlap or include dedicated controls/failure cases. We will add an overlap analysis (Jaccard indices across the three selection criteria) and a short ablation on the effect of freezing non-selected parameters, plus one controlled failure-case scenario, in the revised §3 and appendix. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical probing procedure for identifying task-specific parameters via a short warm-start fine-tune followed by importance scoring (L2 norm, Fisher information) and specificity analysis (cosine similarity of updates). No equations, derivations, or formal reductions are presented that would equate any claimed prediction or result to its own inputs by construction. The method is framed as a practical, experimentally validated technique on standard benchmarks with cross-model transfer, without self-definitional loops, fitted-input predictions, or load-bearing self-citations that collapse the central claim into a tautology. The derivation chain is therefore self-contained as an empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, Douwe Kiela, Thomas Wolf, and Alexander M. Rush. 2024. A Survey on Data Selection for Language Models.TMLR(2024)
2024
-
[2]
Alignment-Lab-AI. 2024. Lawyer-Instruct. Hugging Face dataset. https:// huggingface.co/datasets/Alignment-Lab-AI/Lawyer-Instruct Reformatted from the original LawyerChat dataset
2024
-
[3]
Zeyuan Allen-Zhu and Yuanzhi Li. 2024. Physics of language models: part 3.1, knowledge storage and extraction. InICML. 1067–1077. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Xiaosong Han et al
2024
-
[4]
Hritik Bansal, Karthik Gopalakrishnan, Saket Dingliwal, Sravan Bodapati, Katrin Kirchhoff, and Dan Roth. 2023. Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale. InACL. 11833– 11856
2023
-
[5]
Sahil Chaudhary. 2023. Code Alpaca: An Instruction-following LLaMA model for code generation. https://github.com/sahil280114/codealpaca
2023
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Fahim Dalvi, Hassan Sajjad, Nadir Durrani, and Yonatan Belinkov. 2020. Analyz- ing Redundancy in Pretrained Transformer Models. InEMNLP. 4908–4926
2020
-
[9]
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. 2021. A continual learning survey: Defying forgetting in classification tasks.IEEE TPAMI44, 7 (2021), 3366– 3385
2021
-
[10]
Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. 2023. Parameter- efficient fine-tuning of large-scale pre-trained language models.Nature Machine Intelligence5, 3 (2023), 220–235
2023
-
[11]
Guanting Dong, Hongyi Yuan, Keming Lu, Chengpeng Li, Mingfeng Xue, Dayi- heng Liu, Wei Wang, Zheng Yuan, Chang Zhou, and Jingren Zhou. 2024. How abilities in large language models are affected by supervised fine-tuning data composition. InACL. 177–198
2024
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. Transformer Feed-Forward Layers Are Key-Value Memories. InEMNLP. 5484–5495
2021
-
[14]
Neel Guha, Julian Nyarko, Daniel Ho, Christopher Ré, Adam Chilton, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel Rockmore, Diego Zam- brano, et al. 2023. Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models. InNeurIPS. 44123–44279
2023
-
[15]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al . 2025. DeepSeek-R1 in- centivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
-
[16]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Xiaodong Song, and Jacob Steinhardt. 2021. Measuring Mathematical Problem Solving With the MATH Dataset. InNeurIPS. 5325–5337
2021
-
[17]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.. InICLR
2022
-
[18]
Hanxu Hu, Simon Yu, Pinzhen Chen, and Edoardo Ponti. 2025. Fine-Tuning Large Language Models with Sequential Instructions. InNAACL. 5589–5610
2025
-
[19]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences11, 14 (2021), 6421
2021
-
[20]
Mark H Johnson. 2001. Functional brain development in humans.Nature Reviews Neuroscience2, 7 (2001), 475–483
2001
-
[21]
Zixuan Ke, Yijia Shao, Haowei Lin, Tatsuya Konishi, Gyuhak Kim, and Bing Liu
-
[22]
Continual pre-training of language models. InICLR
-
[23]
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey E. Hinton
-
[24]
Similarity of Neural Network Representations Revisited. InICML. 3519– 3529
-
[25]
Mengyu Li, Yonghao Liu, Fausto Giunchiglia, Ximing Li, Xiaoyue Feng, and Renchu Guan. 2026. Simple-sampling and hard-mixup with prototypes to rebal- ance contrastive learning for text classification. InWWW. 3698–3708
2026
-
[26]
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Diao, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, et al. 2024. Mitigating the alignment tax of rlhf. InEMNLP. 580–606
2024
-
[27]
Yonghao Liu, Renchu Guan, Fausto Giunchiglia, Yanchun Liang, and Xiaoyue Feng. 2021. Deep attention diffusion graph neural networks for text classification. InEMNLP. 8142–8152
2021
-
[28]
Yonghao Liu, Mengyu Li, Wei Pang, Fausto Giunchiglia, Lan Huang, Xiaoyue Feng, and Renchu Guan. 2025. Boosting short text classification with multi- source information exploration and dual-level contrastive learning. InAAAI. 24696–24704
2025
-
[29]
Yonghao Liu, Di Liang, Mengyu Li, Fausto Giunchiglia, Ximing Li, Sirui Wang, Wei Wu, Lan Huang, Xiaoyue Feng, and Renchu Guan. 2023. Local and Global: Temporal Question Answering via Information Fusion.. InIJCAI. 5141–5149
2023
-
[30]
Yonghao Liu, Chuyao Wang, Zhikang Wang, Liang Chen, Zhi Li, Jiangning Song, Qi Zou, Rui Gao, Binzhi Qian, Xiaoyue Feng, et al. 2026. High-Parameter Spatial Multi-Omics through Histology-Anchored Integration.Nature Methods23, 2 (2026), 373–386
2026
-
[31]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. InICLR
2019
-
[32]
Jinghui Lu, Dongsheng Zhu, Weidong Han, Rui Zhao, Brian Mac Namee, and Fei Tan. 2023. What Makes Pre-trained Language Models Better Zero-shot Learners?. InACL. 2288–2303
2023
-
[33]
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. 2025. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE TASLP33 (2025), 3776–3786
2025
-
[34]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt. InNeurIPS. 17359–17372
2022
-
[35]
Paul Michel, Omer Levy, and Graham Neubig. 2019. Are sixteen heads really better than one?. InNeurIPS. 14037–14047
2019
-
[36]
OpenAI. 2025. Introducing GPT-5. https://openai.com/index/introducing-gpt-5/
2025
-
[37]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. InNeurIPS. 27730–27744
2022
-
[38]
Abhishek Panigrahi, Nikunj Saunshi, Haoyu Zhao, and Sanjeev Arora. 2023. Task- specific skill localization in fine-tuned language models. InICML. 27011–27033
2023
-
[39]
Aldo Pareja, Nikhil Shivakumar Nayak, Hao Wang, Krishnateja Killamsetty, Shivchander Sudalairaj, Wenlong Zhao, Seungwook Han, Abhishek Bhandwaldar, Guangxuan Xu, Kai Xu, et al . 2025. Unveiling the secret recipe: A guide for supervised fine-tuning small llms. InICLR
2025
-
[40]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. ZeRO: memory optimizations toward training trillion parameter models. InSC. 1–16
2020
-
[41]
James Seale Smith, Yen-Chang Hsu, Lingyu Zhang, Ting Hua, Zsolt Kira, Yilin Shen, and Hongxia Jin. 2023. Continual diffusion: Continual customization of text-to-image diffusion with c-lora.TMLR(2023)
2023
-
[42]
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. 2024. A simple and effective pruning approach for large language models. InICLR
2024
-
[43]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [44]
-
[45]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. InNeurIPS. 24824–24837
2022
-
[46]
Mitchell Wortsman, Gabriel Ilharco, Jong Wook Kim, Mike Li, Simon Korn- blith, Rebecca Roelofs, Raphael Gontijo Lopes, Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, et al. 2022. Robust fine-tuning of zero-shot models. In CVPR. 7959–7971
2022
-
[47]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jianhong Tu, Jianwei Zhang, Jingren Zhou, et al. 2025. Qwen2. 5-1m technical report.arXiv preprint arXiv:2501.15383(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. 2023. Scaling Relationship on Learning Mathematical Reasoning with Large Language Models.arXiv preprint 2308.01825 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Zaifu Zhan and Rui Zhang. 2025. Towards better multi-task learning: A frame- work for optimizing dataset combinations in large language models. InNAACL. 5373–5386
2025
-
[51]
Yang Zhang, Yanfei Dong, and Kenji Kawaguchi. 2024. Investigating Layer Importance in Large Language Models. InProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 469–479
2024
-
[52]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.18223(2023). A Appendix A.1 Details of SFT Datasets GSM8K RFT[ 47] extends the original GSM8K benchmark [7] by incorporating multiple reasoning trajectori...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.