LVSA: Training-Free Sparse Attention for Long Video Diffusion
Pith reviewed 2026-06-28 22:33 UTC · model grok-4.3
The pith
LVSA sparse attention reduces long video diffusion compute by up to 3.33 times without any retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
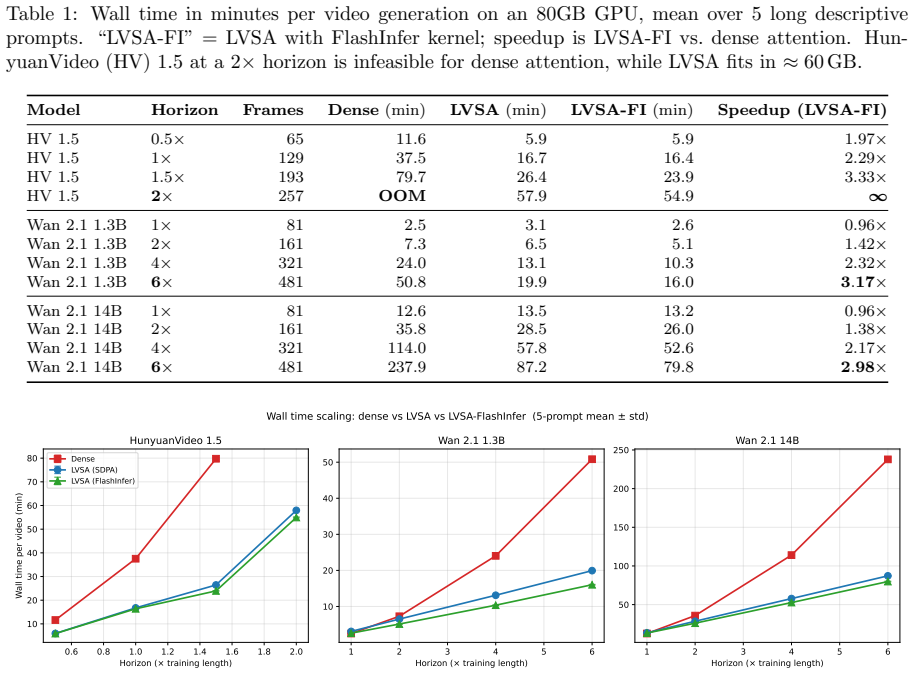
LVSA is a training-free model-agnostic block-sparse attention for video diffusion transformers. It combines a structured window pattern with rotating global anchors to remove the fixed-grid bias which causes long-range temporal artifacts. When used with a FlashInfer kernel, LVSA reduces compute up to 3.17 times on Wan 2.1 1.3B at a 6 times horizon, 2.98 times on Wan 2.1 14B at a 6 times horizon, and 3.33 times on HunyuanVideo 1.5 at a 1.5 times horizon compared with dense attention. It remains quality-neutral at training horizon length and quality-positive at extended lengths, enables 2 times horizon generation on HunyuanVideo 1.5 that is otherwise out of memory, and provides speedups up to
What carries the argument
Structured window pattern combined with rotating global anchors in block-sparse attention
If this is right
- Compute reduced up to 3.17 times on Wan 2.1 1.3B at 6 times horizon
- Compute reduced up to 2.98 times on Wan 2.1 14B at 6 times horizon
- Compute reduced up to 3.33 times on HunyuanVideo 1.5 at 1.5 times horizon
- 2 times horizon generation enabled on HunyuanVideo 1.5 which exceeds single-GPU memory for dense attention
- Speedups up to 2.41 times versus RIFLEx and 3.27 times versus UltraViCo on Wan 2.1 1.3B
Where Pith is reading between the lines
- The rotation schedule could be tested on other transformer-based generative tasks that suffer from similar fixed-pattern attention biases.
- VQeval could be applied to re-score existing long-video methods that currently receive inflated scores from metrics that reward looping output.
- Because LVSA requires no retraining, the same pattern can be dropped into additional video diffusion models beyond the three evaluated here.
- The method may combine with other inference optimizations such as quantization to produce further efficiency gains.
Load-bearing premise
The specific window sizes and rotation schedule remove fixed-grid bias and long-range artifacts without introducing new failure modes.
What would settle it
Generating videos at six times training horizon length with LVSA and measuring the same rate of repetitive looping as dense attention would show the quality claim does not hold.
Figures



read the original abstract
Dense self-attention is the compute and quality bottleneck of long-video diffusion inference: cost grows quadratically with the sequence length, and beyond the training horizon the model converges to near-static output, that is, "frozen" repetitive video. State of the art approaches are either too costly, e.g., they require retraining, or fail to satisfy both performance and quality objectives in a scalable manner. To this end, we introduce Long Video Sparse Attention (LVSA), a training-free model-agnostic block-sparse attention for video diffusion transformers that combines a structured window pattern with rotating global anchors, thus removing the fixed-grid bias which causes long-range temporal artifacts. LVSA, combined with a FlashInfer kernel, reduces compute up to 3.17x on Wan 2.1 1.3B at a 6x horizon, 2.98x on Wan 2.1 14B at a 6x horizon, and 3.33x on HunyuanVideo 1.5 at a 1.5x horizon, compared to dense attention. Beyond reducing compute, LVSA enables HunyuanVideo 1.5 generation at a 2x horizon, which is otherwise out-of-memory on a single GPU. Moreover, LVSA provides speedups up to 2.41x compared to RIFLEx and 3.27x compared to UltraViCo on Wan 2.1 1.3B. To demonstrate applicability across diverse platforms, we apply LVSA on NPUs and achieve speedups up to 2.71x on Wan 2.2 A14B and 3.24x on Wan 2.1 1.3B compared to dense attention. To evaluate quality in a fair way, we introduce VQeval, a tool properly scoring loopy video failures, which instead are rewarded in state of the art evaluators like VBench-Long. LVSA is quality-neutral for generation at training horizon length and quality-positive at extended lengths.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LVSA, a training-free block-sparse attention pattern for video diffusion transformers that combines structured local windows with rotating global anchors to mitigate fixed-grid bias and long-range temporal artifacts. It reports concrete inference speedups (up to 3.17× on Wan 2.1 1.3B at 6× horizon, 2.98× on Wan 2.1 14B, 3.33× on HunyuanVideo) versus dense attention, additional gains versus RIFLEx/UltraViCo, out-of-memory relief for longer sequences, cross-hardware results on NPUs, and introduces VQeval as a metric that penalizes repetitive “frozen” outputs better than VBench-Long; quality is claimed neutral at training length and positive at extended lengths.
Significance. If the empirical claims hold under scrutiny, LVSA would constitute a practical, model-agnostic engineering contribution that materially extends the usable context length of existing video diffusion models at inference time without retraining, directly addressing the quadratic cost and temporal degradation problems that currently limit long-video generation.
major comments (3)
- [Abstract / Method] Abstract and method description: the central claim that the specific combination of structured windows plus rotating global anchors removes fixed-grid bias and long-range artifacts (while remaining quality-neutral/positive) is load-bearing for all reported speedups and quality statements, yet the manuscript supplies no quantitative ablation comparing rotating versus fixed anchors, no sensitivity sweeps on window size or rotation period, and no comparison against alternative sparse patterns; without these controls the reported 3.17×/2.98×/3.33× speedups and VQeval gains could be artifacts of hyper-parameter choices rather than a general property of the method.
- [Evaluation / VQeval] Evaluation section: the abstract states concrete speedups and quality improvements but reports neither error bars nor the number of random seeds used; likewise, no validation data (correlation coefficients, human-study results) are provided showing that VQeval scores align with human judgments on loopy-video failures, undermining the assertion that LVSA is “quality-positive at extended lengths.”
- [Results / Comparisons] Results tables (implied by abstract numbers): the speedups versus RIFLEx and UltraViCo (2.41× and 3.27×) are presented without accompanying implementation details, hyper-parameter matching protocol, or confirmation that the baseline kernels were run under identical memory and batch settings, making it impossible to assess whether the gains are attributable to LVSA or to unstated engineering differences.
minor comments (2)
- [Implementation details] The abstract mentions FlashInfer and NPU results but does not specify the exact kernel configuration or memory layout changes that enable the reported speedups; a short paragraph or table entry would improve reproducibility.
- [Method] Notation for the rotation schedule and anchor placement is introduced without an accompanying diagram or pseudocode; a single figure would clarify the pattern for readers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and evidence.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the central claim that the specific combination of structured windows plus rotating global anchors removes fixed-grid bias and long-range artifacts (while remaining quality-neutral/positive) is load-bearing for all reported speedups and quality statements, yet the manuscript supplies no quantitative ablation comparing rotating versus fixed anchors, no sensitivity sweeps on window size or rotation period, and no comparison against alternative sparse patterns; without these controls the reported 3.17×/2.98×/3.33× speedups and VQeval gains could be artifacts of hyper-parameter choices rather than a general property of the method.
Authors: We agree that direct quantitative ablations would provide stronger support for the design choices. The motivation for rotating anchors (to break fixed-grid bias) is explained in the method, but we will add an explicit ablation of rotating versus fixed anchors, sensitivity sweeps over window size and rotation period, and comparisons against additional sparse patterns (e.g., random and strided) in a new experimental subsection. revision: yes
-
Referee: [Evaluation / VQeval] Evaluation section: the abstract states concrete speedups and quality improvements but reports neither error bars nor the number of random seeds used; likewise, no validation data (correlation coefficients, human-study results) are provided showing that VQeval scores align with human judgments on loopy-video failures, undermining the assertion that LVSA is “quality-positive at extended lengths.”
Authors: We will add the number of random seeds used and error bars to all reported metrics. While VQeval is motivated by directly penalizing low temporal variance (unlike VBench-Long), we acknowledge the absence of explicit validation data. We will include a small human preference study with correlation coefficients in an appendix of the revision. revision: yes
-
Referee: [Results / Comparisons] Results tables (implied by abstract numbers): the speedups versus RIFLEx and UltraViCo (2.41× and 3.27×) are presented without accompanying implementation details, hyper-parameter matching protocol, or confirmation that the baseline kernels were run under identical memory and batch settings, making it impossible to assess whether the gains are attributable to LVSA or to unstated engineering differences.
Authors: All baselines were evaluated using their official implementations under identical hardware, batch size, and memory settings as the dense and LVSA runs. We will add an appendix with full hyper-parameter tables, kernel versions, and explicit confirmation of matched experimental conditions. revision: yes
Circularity Check
No circularity: empirical engineering pattern with no derivation chain or self-referential steps
full rationale
The paper presents LVSA as a training-free, model-agnostic block-sparse attention design that combines a structured window pattern with rotating global anchors. No equations, fitted parameters, predictions derived from subsets of data, or load-bearing self-citations appear in the abstract or described method. The central claims rest on empirical speedups and quality evaluations across three models rather than any mathematical derivation that reduces to its own inputs by construction. Design choices are stated directly as an engineering solution without invoking uniqueness theorems, ansatzes from prior self-work, or renaming of known results. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[2]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Ra- jbhandari, and Yuxiong He. Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[4]
Xingyang Li*, Muyang Li*, Tianle Cai, Haocheng Xi, Shuo Yang, Yujun Lin, Lvmin Zhang, Songlin Yang, Jinbo Hu, Kelly Peng, Maneesh Agrawala, Ion Stoica, Kurt Keutzer, and Song Han. Radial attention: O(nlogn) sparse attention with energy decay for long video generation.arXiv preprint arXiv:2506.19852, 2025
arXiv 2025
-
[5]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
Pith/arXiv arXiv 2025
-
[6]
Video is worth a thousand images: Exploring the latest trends in long video generation.ACM Comput
Faraz Waseem and Muhammad Shahzad. Video is worth a thousand images: Exploring the latest trends in long video generation.ACM Comput. Surv., 58(6), December 2025
2025
-
[7]
arXiv preprint arXiv:2502.01776 (2025)
Haocheng Xi, Shuo Yang, Yilong Zhao, Chenfeng Xu, Muyang Li, Xiuyu Li, Yujun Lin, Han Cai, Jintao Zhang, Dacheng Li, et al. Sparse videogen: Accelerating video diffusion transformers with spatial-temporal sparsity.arXiv preprint arXiv:2502.01776, 2025
-
[8]
Training-free and adaptive sparse attention for efficient long video generation
Yifei Xia, Suhan Ling, Fangcheng Fu, Yujie Wang, Huixia Li, Xuefeng Xiao, and Bin Cui. Training-free and adaptive sparse attention for efficient long video generation. InICCV, 2025
2025
-
[9]
Sparse VideoGen2: Accelerate Video Generation with Sparse Attention via Semantic-Aware Permutation
Shuo Yang, Haocheng Xi, Yilong Zhao, Muyang Li, Jintao Zhang, Han Cai, Yujun Lin, Xiuyu Li, Chenfeng Xu, Kelly Peng, et al. Sparse videogen2: Accelerate video generation with sparse attention via semantic- aware permutation.arXiv preprint arXiv:2505.18875, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
vllm-omni: Fully disaggregated serving for any-to-any multimodal models,
Peiqi Yin, Jiangyun Zhu, Han Gao, Chenguang Zheng, Yongxiang Huang, Taichang Zhou, Ruirui Yang, Weizhi Liu, Weiqing Chen, Canlin Guo, et al. vllm-omni: Fully disaggregated serving for any-to-any multi- modal models.arXiv preprint arXiv:2602.02204, 2026
-
[11]
Sageattention: Accurate 8-bit attention for plug-and-play inference acceleration, 2025
Jintao Zhang, Jia Wei, Haofeng Huang, Pengle Zhang, Jun Zhu, and Jianfei Chen. Sageattention: Accurate 8-bit attention for plug-and-play inference acceleration, 2025
2025
-
[12]
arXiv preprint arXiv:2502.04507 (2025)
Peiyuan Zhang, Yongqi Chen, Runlong Su, Hangliang Ding, Ion Stoica, Zhengzhong Liu, and Hao Zhang. Fast video generation with sliding tile attention.arXiv preprint arXiv:2502.04507, 2025
-
[13]
Min Zhao, Guande He, Yixiao Chen, Hongzhou Zhu, Chongxuan Li, and Jun Zhu. Riflex: A free lunch for length extrapolation in video diffusion transformers.arXiv preprint arXiv:2502.15894, 2025
-
[14]
Min Zhao, Hongzhou Zhu, Yingze Wang, Bokai Yan, Jintao Zhang, Guande He, Ling Yang, Chongxuan Li, and Jun Zhu. Ultravico: Breaking extrapolation limits in video diffusion transformers.arXiv preprint arXiv:2511.20123, 2025. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.