ConsisGuard: Aligning Safety Deliberation with Policy Enforcement in LLM Guardrails
Pith reviewed 2026-06-28 23:01 UTC · model grok-4.3
The pith
ConsisGuard closes the deliberation-to-enforcement gap by aligning reasoning and decisions in LLM guardrails.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
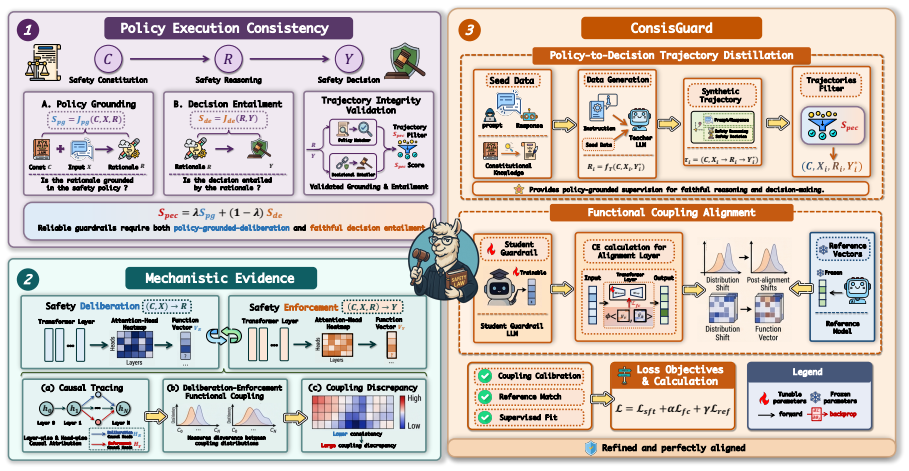
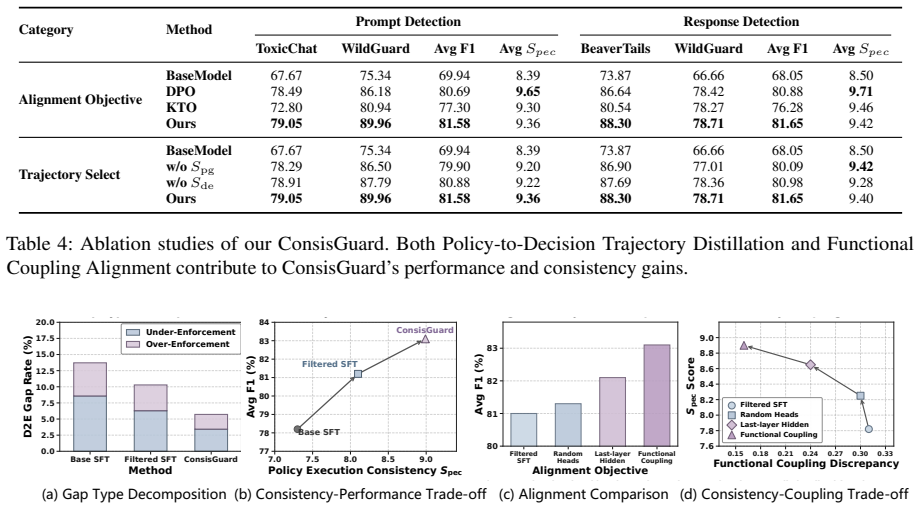
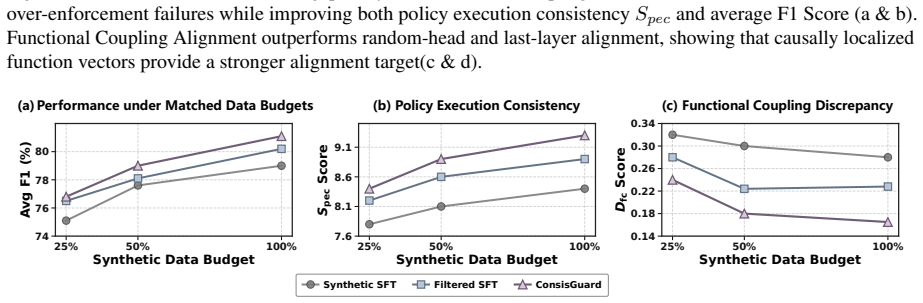
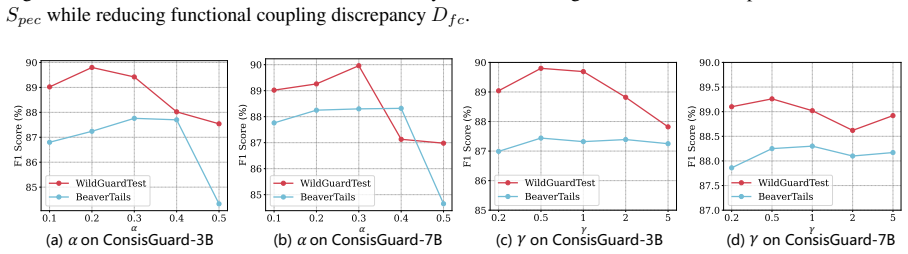
Reasoning-based LLM guardrails improve safety by generating rationales before decisions, but suffer from a deliberation-to-enforcement gap where rationales do not always lead to faithful enforcement. ConsisGuard performs Policy-to-Decision Trajectory Distillation and Functional Coupling Alignment to align the internal coupling between safety deliberation and decision enforcement, leading to improved detection performance while reducing policy execution failures on prompt and response harmfulness detection benchmarks.
What carries the argument
ConsisGuard framework that performs Policy-to-Decision Trajectory Distillation and Functional Coupling Alignment to ensure policy execution consistency in reasoning-based guardrails.
If this is right
- Improved performance on prompt and response harmfulness detection benchmarks.
- Reduced policy execution failures.
- Generated reasoning is grounded in the safety policy.
- The final decision is entailed by the reasoning.
Where Pith is reading between the lines
- Similar consistency alignment could apply to other LLM reasoning tasks like math or code generation to ensure steps match the answer.
- Deployed guardrails might benefit from this to avoid both over-refusal and under-protection.
- Future work could test if this reduces the need for ensemble methods or human oversight in safety systems.
Load-bearing premise
The deliberation-to-enforcement gap is the primary failure mode in guardrails and the distillation and alignment steps will close it without introducing new problems.
What would settle it
Running the same benchmarks and finding that ConsisGuard shows no improvement in detection or no reduction in failures would disprove the central claim.
Figures




read the original abstract
Reasoning-based LLM guardrails improve safety moderation by generating explicit rationales before issuing final decisions. However, their rationales do not always lead to faithful enforcement: a model may recognize a harmful intent in its reasoning but still predict a safe label, or issue an unsafe decision without policy-grounded justification. We identify this safety-critical failure mode as the deliberation-to-enforcement gap. Unlike general chain-of-thought faithfulness, guardrail reliability requires policy execution consistency: the generated reasoning should be grounded in the safety policy, and the final decision should be entailed by that reasoning. We propose ConsisGuard, a consistency-aware framework for reasoning-based LLM guardrails. ConsisGuard performs Policy-to-Decision Trajectory Distillation and Functional Coupling Alignment, aligning the internal coupling between safety deliberation and decision enforcement. Experiments on prompt and response harmfulness detection benchmarks show that ConsisGuard improves detection performance while reducing policy execution failures. These results suggest that reliable reasoning-based guardrails require accurate faithful execution of safety policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'deliberation-to-enforcement gap' in reasoning-based LLM guardrails, where generated rationales may not faithfully lead to policy-consistent decisions. It introduces ConsisGuard, which applies Policy-to-Decision Trajectory Distillation and Functional Coupling Alignment to enforce consistency between safety deliberation and enforcement. The abstract states that experiments on prompt and response harmfulness detection benchmarks demonstrate improved detection performance alongside reduced policy execution failures, suggesting that reliable guardrails require faithful policy execution.
Significance. If the proposed distillation and alignment steps demonstrably close the gap by producing reasoning that is verifiably grounded in an explicit safety policy with decisions entailed by that reasoning, the work would address a practically important failure mode in LLM safety systems. The identification of policy execution consistency as distinct from general CoT faithfulness is a useful conceptual contribution. However, the significance is limited by the absence of evidence that the evaluation directly measures policy grounding rather than label correlation.
major comments (2)
- [Abstract] Abstract: The central empirical claim states that 'Experiments on prompt and response harmfulness detection benchmarks show that ConsisGuard improves detection performance while reducing policy execution failures.' Standard harmfulness benchmarks supply only safe/unsafe labels and do not include the explicit policy text. Consequently, any measured reduction in 'policy execution failures' cannot be distinguished from improved correlation with the label distribution; the evaluation does not test whether reasoning is grounded in the policy or whether decisions are entailed by policy-grounded reasoning.
- [Abstract] Abstract, paragraph 3: The definition of policy execution consistency requires that 'the generated reasoning should be grounded in the safety policy, and the final decision should be entailed by that reasoning.' Because the benchmarks lack policy text, the experimental setup does not provide a direct test of this entailment relation, leaving the load-bearing claim that ConsisGuard achieves 'accurate faithful execution of safety policies' unsupported by the reported evaluation design.
minor comments (1)
- [Abstract] The abstract supplies no quantitative results, baselines, dataset sizes, or ablation details, which hinders immediate assessment of effect sizes even if the benchmark concern is addressed.
Simulated Author's Rebuttal
We thank the referee for highlighting the distinction between label correlation and direct policy-grounded entailment in our evaluation. We address each point below and propose targeted revisions to the abstract and evaluation discussion to clarify the scope of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim states that 'Experiments on prompt and response harmfulness detection benchmarks show that ConsisGuard improves detection performance while reducing policy execution failures.' Standard harmfulness benchmarks supply only safe/unsafe labels and do not include the explicit policy text. Consequently, any measured reduction in 'policy execution failures' cannot be distinguished from improved correlation with the label distribution; the evaluation does not test whether reasoning is grounded in the policy or whether decisions are entailed by policy-grounded reasoning.
Authors: We agree that standard benchmarks provide only binary labels without accompanying policy text, so our reported reduction in policy execution failures is measured via internal consistency between generated rationales and final decisions rather than direct entailment from an explicit policy document. This proxy captures the deliberation-to-enforcement gap as defined in the paper but does not constitute a direct test of policy grounding. We will revise the abstract to replace the phrase 'reducing policy execution failures' with 'reducing rationale-decision inconsistencies' and add a sentence noting that evaluation uses label-based benchmarks as a proxy for policy consistency. revision: yes
-
Referee: [Abstract] Abstract, paragraph 3: The definition of policy execution consistency requires that 'the generated reasoning should be grounded in the safety policy, and the final decision should be entailed by that reasoning.' Because the benchmarks lack policy text, the experimental setup does not provide a direct test of this entailment relation, leaving the load-bearing claim that ConsisGuard achieves 'accurate faithful execution of safety policies' unsupported by the reported evaluation design.
Authors: The definition in the manuscript assumes policies are supplied at inference time within the guardrail framework, yet the reported experiments rely on label-only benchmarks. This means the entailment claim is supported only indirectly through improved detection accuracy and reduced inconsistencies. We will revise the abstract to qualify the final sentence as 'These results suggest that reliable reasoning-based guardrails benefit from improved consistency between deliberation and enforcement on standard benchmarks' and will expand the evaluation section to discuss this limitation explicitly. revision: yes
Circularity Check
No circularity; empirical claims rest on experiments, not self-referential derivations
full rationale
The paper introduces ConsisGuard via two procedural steps (Policy-to-Decision Trajectory Distillation and Functional Coupling Alignment) to address an identified gap, then reports measured improvements on standard harmfulness detection benchmarks. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method. The performance gains are presented as experimental outcomes rather than quantities forced by definition or prior author results, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (3)
-
ConsisGuard
no independent evidence
-
Policy-to-Decision Trajectory Distillation
no independent evidence
-
Functional Coupling Alignment
no independent evidence
Forward citations
Cited by 1 Pith paper
-
ZooClaw-FashionSigLIP2: Distilled Fine-tuning for Robust Fashion Retrieval
ZooClaw-FashionSigLIP2 applies distilled full fine-tuning plus WiseFT interpolation to SigLIP2-base and reports outperforming LoRA, larger backbones, and external data on fashion retrieval benchmarks while releasing a...
Reference graph
Works this paper leans on
-
[1]
URL: " 'urlintro :=
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Sriram Balasubramanian, Samyadeep Basu, and Soheil Feizi. 2025. A closer look at bias and chainof-thought faithfulness of large (vision) language models. arXiv preprint arXiv:2505.23945
arXiv 2025
-
[4]
Shiqi Chen, Jinghan Zhang, Tongyao Zhu, Wei Liu, Siyang Gao, Miao Xiong, Manling Li, and Junxian He. 2025. https://doi.org/10.48550/ARXIV.2505.05464 Bring reason to vision: Understanding perception and reasoning through model merging . CoRR, abs/2505.05464
-
[5]
Jiahao Cheng, Tiancheng Su, Jia Yuan, Guoxiu He, Jiawei Liu, Xinqi Tao, Jingwen Xie, and Huaxia Li. 2025. https://doi.org/10.48550/ARXIV.2506.17088 Chain-of-thought prompting obscures hallucination cues in large language models: An empirical evaluation . CoRR, abs/2506.17088
-
[6]
Zhixuan Chu, Yan Wang, Longfei Li, Zhibo Wang, Zhan Qin, and Kui Ren. 2024. https://doi.org/10.1145/3658644.3690217 A causal explainable guardrails for large language models . In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, CCS 2024, Salt Lake City, UT, USA, October 14-18, 2024 , pages 1136--1150. ACM
-
[7]
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. 2024. https://openreview.net/forum?id=TyFrPOKYXw Safe RLHF: safe reinforcement learning from human feedback . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[8]
Badhan Chandra Das, M. Hadi Amini, and Yanzhao Wu. 2025. https://doi.org/10.1145/3712001 Security and privacy challenges of large language models: A survey . ACM Comput. Surv. , 57(6):152:1--152:39
-
[9]
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. 2024. https://doi.org/10.18653/V1/2024.FINDINGS-ACL.212 Chain-of-verification reduces hallucination in large language models . In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11...
-
[10]
Yi Dong, Ronghui Mu, Yanghao Zhang, Siqi Sun, Tianle Zhang, Changshun Wu, Gaojie Jin, Yi Qi, Jinwei Hu, Jie Meng, Saddek Bensalem, and Xiaowei Huang. 2024. https://doi.org/10.48550/ARXIV.2406.02622 Safeguarding large language models: A survey . CoRR, abs/2406.02622
-
[11]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, and et al. 2024. https://doi.org/10.48550/ARXIV.2407.21783 The llama 3 herd of models . CoRR, abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[12]
Arduin Findeis, Timo Kaufmann, Eyke H \" u llermeier, Samuel Albanie, and Robert D. Mullins. 2025. https://openreview.net/forum?id=9FRwkPw3Cn Inverse constitutional AI: compressing preferences into principles . In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net
2025
-
[13]
Shaona Ghosh, Prasoon Varshney, Erick Galinkin, and Christopher Parisien. 2024. https://doi.org/10.48550/ARXIV.2404.05993 AEGIS: online adaptive AI content safety moderation with ensemble of LLM experts . CoRR, abs/2404.05993
-
[14]
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. 2024. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms. In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vanc...
2024
-
[15]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025. https://doi.org/10.1145/3703155 A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions . ACM Trans. Inf. Syst. , 43(2):42:1--42:55
-
[16]
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. 2023. Beavertails: Towards improved safety alignment of LLM via a human-preference dataset. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New O...
2023
-
[17]
Gangwei Jiang, Caigao Jiang, Zhaoyi Li, Siqiao Xue, Jun Zhou, Linqi Song, Defu Lian, and Ying Wei. 2025. Unlocking the power of function vectors for characterizing and mitigating catastrophic forgetting in continual instruction tuning. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net
2025
-
[18]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. https://doi.org/10.48550/ARXIV.2406.00515 A survey on large language models for code generation . CoRR, abs/2406.00515
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.00515 2024
-
[19]
Jiachun Li, Pengfei Cao, Yubo Chen, Jiexin Xu, Huaijun Li, Xiaojian Jiang, Kang Liu, and Jun Zhao. 2025. Towards better chain-of-thought: A reflection on effectiveness and faithfulness. In Findings of the Association for Computational Linguistics: ACL 2025, pages 10747--10765
2025
-
[20]
Lijun Li, Bowen Dong, Ruohui Wang, Xuhao Hu, Wangmeng Zuo, Dahua Lin, Yu Qiao, and Jing Shao. 2024. https://doi.org/10.18653/V1/2024.FINDINGS-ACL.235 Salad-bench: A hierarchical and comprehensive safety benchmark for large language models . In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, Augus...
-
[21]
Lei Liu, Xiaoyan Yang, Junchi Lei, Xiaoyang Liu, Yue Shen, Zhiqiang Zhang, Peng Wei, Jinjie Gu, Zhixuan Chu, Zhan Qin, and Kui Ren. 2024. https://doi.org/10.48550/ARXIV.2406.03712 A survey on medical large language models: Technology, application, trustworthiness, and future directions . CoRR, abs/2406.03712
-
[22]
Yue Liu, Hongcheng Gao, Shengfang Zhai, Jun Xia, Tianyi Wu, Zhiwei Xue, Yulin Chen, Kenji Kawaguchi, Jiaheng Zhang, and Bryan Hooi. 2025. https://doi.org/10.48550/ARXIV.2501.18492 Guardreasoner: Towards reasoning-based LLM safeguards . CoRR, abs/2501.18492
-
[23]
Junyu Luo, Cao Xiao, and Fenglong Ma. 2024. https://doi.org/10.18653/V1/2024.FINDINGS-EMNLP.204 Zero-resource hallucination prevention for large language models . In Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16, 2024 , pages 3586--3602. Association for Computational Linguistics
-
[24]
Todor Markov, Chong Zhang, Sandhini Agarwal, Florentine Eloundou Nekoul, Theodore Lee, Steven Adler, Angela Jiang, and Lilian Weng. 2023. https://doi.org/10.1609/AAAI.V37I12.26752 A holistic approach to undesired content detection in the real world . In Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innova...
-
[25]
Forsyth, and Dan Hendrycks
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David A. Forsyth, and Dan Hendrycks. 2024. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-2...
2024
-
[26]
Paul R \" o ttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. 2024. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: L...
2024
-
[27]
Li, Arnab Sen Sharma, Aaron Mueller, Byron C
Eric Todd, Millicent L. Li, Arnab Sen Sharma, Aaron Mueller, Byron C. Wallace, and David Bau. 2024. https://openreview.net/forum?id=AwyxtyMwaG Function vectors in large language models . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[28]
Martin Tutek, Fateme Hashemi Chaleshtori, Ana Marasovi \'c , and Yonatan Belinkov. 2025. Measuring chain of thought faithfulness by unlearning reasoning steps. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9946--9971
2025
-
[29]
Yan Wang, Zhixuan Chu, Xin Ouyang, Simeng Wang, Hongyan Hao, Yue Shen, Jinjie Gu, Siqiao Xue, James Zhang, Qing Cui, Longfei Li, Jun Zhou, and Sheng Li. 2024. LLMRG: improving recommendations through large language model reasoning graphs. In Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applicat...
2024
-
[30]
Jiaxin Wen, Pei Ke, Hao Sun, Zhexin Zhang, Chengfei Li, Jinfeng Bai, and Minlie Huang. 2023. https://doi.org/10.18653/V1/2023.EMNLP-MAIN.84 Unveiling the implicit toxicity in large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023 , pages 1322--1338. Asso...
-
[31]
Xiaofei Wen, Wenxuan Zhou, Wenjie Jacky Mo, and Muhao Chen. 2025. https://aclanthology.org/2025.findings-acl.704/ Thinkguard: Deliberative slow thinking leads to cautious guardrails . In Findings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025 , pages 13698--13713. Association for Computational Linguistics
2025
-
[32]
Siqiao Xue, Xiaojing Li, Fan Zhou, Qingyang Dai, Zhixuan Chu, and Hongyuan Mei. 2024. Famma: A benchmark for financial domain multilingual multimodal question answering. arXiv preprint arXiv:2410.04526
arXiv 2024
-
[33]
Siqiao Xue, Zhaoyang Zhu, Wei Zhang, Rongyao Cai, Rui Wang, Yixiang Mu, Fan Zhou, Jianguo Li, Peng Di, and Hang Yu. 2026. https://arxiv.org/abs/2603.26017 Quitobench: A high-quality open time series forecasting benchmark . arXiv preprint arXiv:2603.26017
arXiv 2026
-
[34]
Zihao Xue, Zhen Bi, Long Ma, Zhenlin Hu, Yan Wang, Zhenfang Liu, Qing Sheng, Jie Xiao, and Jungang Lou. 2025. Thought purity: Defense paradigm for chain-of-thought attack. arXiv preprint arXiv:2507.12314
arXiv 2025
-
[35]
Zihao Yi, Jiarui Ouyang, Yuwen Liu, Tianhao Liao, Zhe Xu, and Ying Shen. 2024. https://doi.org/10.48550/ARXIV.2402.18013 A survey on recent advances in llm-based multi-turn dialogue systems . CoRR, abs/2402.18013
-
[36]
Wenjun Zeng, Yuchi Liu, Ryan Mullins, Ludovic Peran, Joe Fernandez, Hamza Harkous, Karthik Narasimhan, Drew Proud, Piyush Kumar, Bhaktipriya Radharapu, Olivia Sturman, and Oscar Wahltinez. 2024. https://doi.org/10.48550/ARXIV.2407.21772 Shieldgemma: Generative AI content moderation based on gemma . CoRR, abs/2407.21772
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21772 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.