Memory by Design: Probabilistic Sequence Layers
Pith reviewed 2026-06-28 21:05 UTC · model grok-4.3
The pith
A design model using exact Bayesian filtering derives and unifies linear attention, GLA, Mamba-2, and DeltaNet while showing covariance tracking boosts retrieval robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
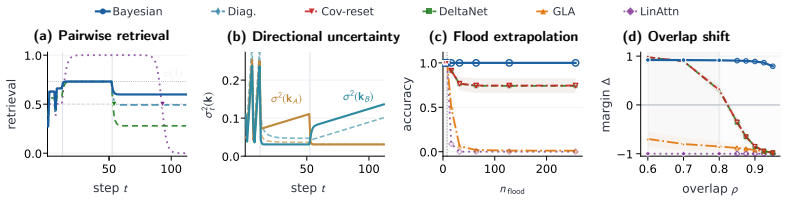
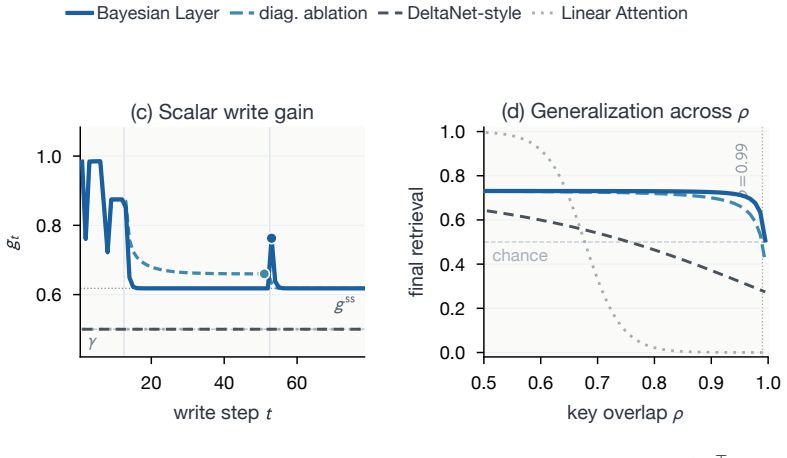
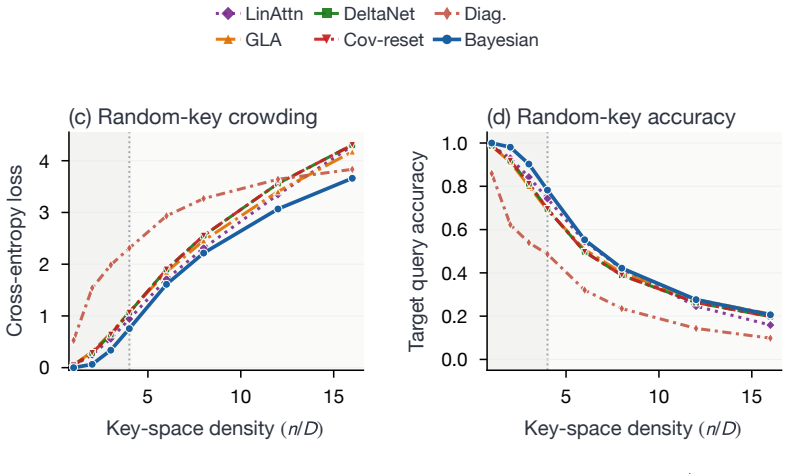
Several sub-quadratic recurrent architectures arise as instances of a design model in which memory writes are performed by exact Bayesian filtering; linear attention, GLA, and Mamba-2/SSD are exact filters under one such model, while DeltaNet and related Delta-rule models are covariance-reset reductions under another. Retaining the covariance yields closed-form predictions for retrieval dynamics that improve robustness beyond the training regime.
What carries the argument
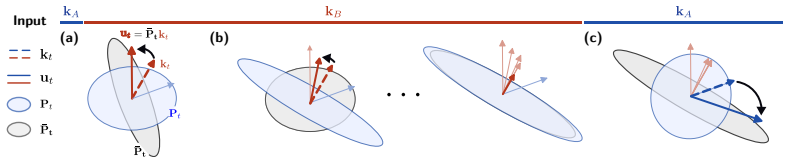
The design-model framework, which specifies memory writes via exact Bayesian filtering and query-dependent readout; its linear-Gaussian instantiation is the Bayesian Layer that maintains and propagates both mean and covariance.
If this is right
- Linear attention, GLA, and Mamba-2/SSD are recovered as exact Bayesian filters under one design model.
- DeltaNet and Delta-rule models emerge as covariance-reset reductions under a second design model.
- Restoring covariance produces closed-form predictions for retrieval dynamics.
- Covariance-aware layers improve robustness on collision studies, associative recall, and MQAR beyond the training regime.
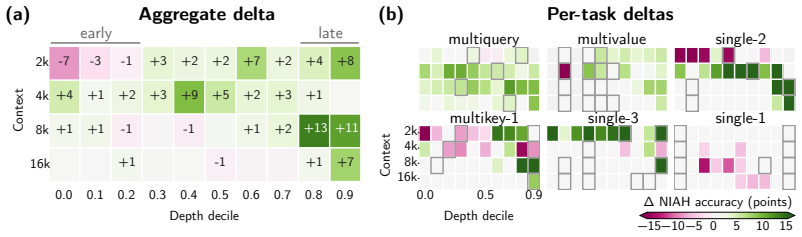
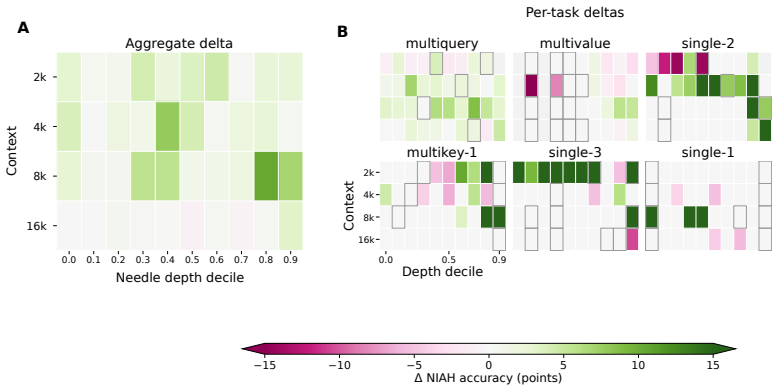
- Distilling Bayesian Layers into a pretrained Gated DeltaNet raises RULER long-context retrieval at matched compute.
Where Pith is reading between the lines
- The unification may allow systematic derivation of new hybrid layers that combine exact filtering steps with selective resets.
- Covariance tracking could serve as a diagnostic for when sequence models will generalize on out-of-distribution retrieval tasks.
- The design-model approach might extend naturally to non-Gaussian or non-linear memory dynamics for more structured sequence problems.
Load-bearing premise
The linear-Gaussian instantiation accurately captures the memory dynamics of the target sequence layers and the design-model assumptions hold for the unified models without additional unstated constraints.
What would settle it
An experiment in which restoring covariance propagation fails to improve robustness on controlled collision studies, learned associative recall, or the Zoology MQAR benchmark, or in which the listed architectures deviate from the exact Bayesian filtering predictions of the design model.
Figures


read the original abstract
We introduce the design-model framework: a way to derive efficient recurrent sequence maps from explicit assumptions about memory. A design model writes evidence into memory by exact Bayesian filtering; a query-dependent readout produces a predictive distribution whose mean is the layer output. In our linear-Gaussian instantiation, the \emph{Bayesian Layer} propagates both a mean and a covariance: the covariance tracks uncertainty over stored associations, steering writes toward uncertain directions, attenuating gains as evidence accumulates, and preserving confident memories. The same framework unifies several sub-quadratic recurrences. Linear attention, GLA, and Mamba-2/SSD are exact filters under one design model, whereas DeltaNet and related Delta-rule models arise as covariance-reset reductions under another. Restoring the covariance yields closed-form predictions for retrieval dynamics, verified empirically, and improves robustness beyond the training regime across controlled collision studies, learned associative recall, and the Zoology MQAR benchmark; distilling Bayesian Layers into a pretrained 340M Gated DeltaNet improves RULER long-context retrieval at matched compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the design-model framework for deriving recurrent sequence layers from explicit Bayesian filtering assumptions on memory writes, with a query-dependent readout. In the linear-Gaussian instantiation, the Bayesian Layer propagates both mean and covariance to track uncertainty over associations. It claims that Linear attention, GLA, and Mamba-2/SSD are exact filters under one design model while DeltaNet and related models arise as covariance-reset reductions under another; restoring the covariance yields closed-form retrieval predictions that are empirically verified and improve robustness on collision studies, associative recall, the Zoology MQAR benchmark, and via distillation into a 340M Gated DeltaNet on RULER.
Significance. If the exact equivalences hold without unstated constraints, the framework supplies a principled route to unify and extend sub-quadratic sequence models while generating falsifiable closed-form predictions for retrieval dynamics. The reported empirical gains on controlled robustness tests and the distillation result on long-context retrieval constitute concrete strengths that could be leveraged for model design.
major comments (2)
- [Abstract and unification section] Abstract and unification section: the claim that Linear attention, GLA, and Mamba-2/SSD are 'exact filters' under the stated linear-Gaussian design model (and DeltaNet a covariance-reset reduction) is load-bearing for the unification and closed-form prediction results. The mean/covariance propagation must be shown to recover the original recurrences exactly, including any normalization, scaling, or noise-model details, without additional approximations or hidden constraints.
- [Empirical evaluation sections] Empirical evaluation sections: the robustness improvements 'beyond the training regime' across collision studies, learned associative recall, and MQAR must be supported by ablations that isolate the contribution of the restored covariance from other implementation choices, to substantiate that the design-model restoration is the operative factor.
minor comments (1)
- Notation for the Bayesian Layer mean and covariance updates should be defined once with explicit variable lists to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the centrality of the exact equivalences and the need for isolating ablations. We address each major comment below and will revise the manuscript to strengthen clarity and evidence where indicated.
read point-by-point responses
-
Referee: [Abstract and unification section] Abstract and unification section: the claim that Linear attention, GLA, and Mamba-2/SSD are 'exact filters' under the stated linear-Gaussian design model (and DeltaNet a covariance-reset reduction) is load-bearing for the unification and closed-form prediction results. The mean/covariance propagation must be shown to recover the original recurrences exactly, including any normalization, scaling, or noise-model details, without additional approximations or hidden constraints.
Authors: We agree that explicit verification of exact recovery is essential for the unification claims. Section 3 of the manuscript derives the Bayesian filter updates and shows that they recover the recurrences of Linear Attention, GLA, and Mamba-2/SSD exactly under the linear-Gaussian design model, with the specific scaling, normalization, and noise terms matching those in the original formulations; DeltaNet is obtained precisely by the covariance-reset reduction. To make this fully transparent, we will add a dedicated appendix containing the complete algebraic steps that recover each original recurrence from the mean/covariance propagation equations, confirming the absence of approximations or hidden constraints. revision: yes
-
Referee: [Empirical evaluation sections] Empirical evaluation sections: the robustness improvements 'beyond the training regime' across collision studies, learned associative recall, and MQAR must be supported by ablations that isolate the contribution of the restored covariance from other implementation choices, to substantiate that the design-model restoration is the operative factor.
Authors: We agree that isolating the covariance contribution is necessary to substantiate the claims. The manuscript already compares the full Bayesian Layer against its covariance-reset counterpart (the DeltaNet reduction) across the collision, associative recall, and MQAR experiments; these comparisons directly attribute gains to the covariance term. We will revise the empirical sections to present these as explicit ablations, add controls for other implementation factors (e.g., initialization and normalization variants), and move relevant supplementary results into the main text to strengthen the isolation of the design-model effect. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives recurrent sequence layers from explicit design-model assumptions (exact Bayesian filtering for writes, query-dependent readout) in a linear-Gaussian instantiation. Claims that Linear attention, GLA, Mamba-2/SSD are exact filters and DeltaNet is a covariance-reset reduction are presented as mathematical equivalences obtained by specializing the framework, not as fitted parameters renamed as predictions or self-definitions. No load-bearing self-citations, ansatz smuggling, or renaming of known results are exhibited in the provided text; the unification and closed-form predictions rest on the stated assumptions rather than reducing to inputs by construction. Empirical tests on retrieval benchmarks are independent of the unification step.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Memory writes follow exact Bayesian filtering
- domain assumption Linear-Gaussian model suffices for the sequence-layer instantiation
invented entities (1)
-
Bayesian Layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Brian D. O. Anderson and John B. Moore. Optimal Filtering. Prentice-Hall , Englewood Cliffs, N.J. , 1979. ISBN 978-0-13-638122-8
1979
-
[2]
Zoology: Measuring and improving recall in efficient language models
Simran Arora, Sabri Eyuboglu, Aman Timalsina, Isys Johnson, Michael Poli, James Zou, Atri Rudra, and Christopher R \'e . Zoology: Measuring and improving recall in efficient language models. arXiv preprint arXiv:2312.04927, 2024
arXiv 2024
-
[3]
xLSTM : Extended long short-term memory
Maximilian Beck, Korbinian P \"o ppel, Markus Spanring, Andreas Ber, Emanuele Hu, Maor Ivgi, Gregor Lennartz, Kevin Schlegel, and Hochreiter Sepp. xLSTM : Extended long short-term memory. arXiv preprint arXiv:2405.04517, 2024
arXiv 2024
-
[4]
Atlas: Learning to optimally memorize the context at test time
Ali Behrouz, Zeman Li, Praneeth Kacham, Majid Daliri, Yuan Deng, Peilin Zhong, Meisam Razaviyayn, and Vahab Mirrokni. Atlas: Learning to optimally memorize the context at test time. arXiv preprint arXiv:2505.23735, 2025
arXiv 2025
-
[5]
Learning to remember, learn, and forget in attention-based models
Djohan Bonnet, Jamie Lohoff, Jan Finkbeiner, Elidona Skhikerujah, and Emre Neftci. Learning to remember, learn, and forget in attention-based models. arXiv preprint arXiv:2602.09075, 2026
Pith/arXiv arXiv 2026
-
[6]
Transformers are SSM s: Generalized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are SSM s: Generalized models and efficient algorithms through structured state space duality. In International Conference on Machine Learning, 2024 a
2024
-
[7]
Mamba-2: The structured state space duality
Tri Dao and Albert Gu. Mamba-2: The structured state space duality. arXiv preprint arXiv:2405.21060, 2024 b
Pith/arXiv arXiv 2024
-
[8]
Soham De, Samuel L. Smith, Anushan Fernando, Aleksandar Botev, George Cristian-Muraru, Albert Gu, Russ Harber, Tayfun Hazan, et al. Griffin: Mixing gated linear recurrences with local attention for efficient language models. arXiv preprint arXiv:2402.19427, 2024
Pith/arXiv arXiv 2024
-
[9]
MoM : Linear sequence modeling with mixture-of-memories
Jusen Du, Weigao Sun, Disen Lan, Jiaxi Hu, and Yu Cheng. MoM : Linear sequence modeling with mixture-of-memories. arXiv preprint arXiv:2502.13685, 2025
arXiv 2025
-
[10]
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. arXiv [cs.NE], October 2014. URL http://arxiv.org/abs/1410.5401
Pith/arXiv arXiv 2014
-
[11]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[12]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. RULER : What's the real context size of your long-context language models? arXiv preprint arXiv:2404.06654, 2024
Pith/arXiv arXiv 2024
-
[13]
Linear estimation
Thomas Kailath, Ali H Sayed, and Babak Hassibi. Linear estimation. Prentice Hall, 2000
2000
-
[14]
Transformers are RNNs : Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are RNNs : Fast autoregressive transformers with linear attention. In International Conference on Machine Learning, pages 5156--5165, 2020. URL https://proceedings.mlr.press/v119/katharopoulos20a.html
2020
-
[15]
Kimi linear: An expressive, efficient attention architecture
Kimi Team . Kimi linear: An expressive, efficient attention architecture. arXiv preprint arXiv:2510.26692, 2025
Pith/arXiv arXiv 2025
-
[16]
Liger : Linearizing large language models to gated recurrent structures
Disen Lan, Weigao Sun, Jiaxi Hu, Jusen Du, and Yu Cheng. Liger : Linearizing large language models to gated recurrent structures. In International Conference on Machine Learning (ICML), 2025
2025
-
[17]
Gerber, Elad Dolev, Eran Krakovsky, Erez Safahi, Erez Schwartz, Gal Cohen, et al
Barak Lenz, Opher Lieber, Alan Arazi, Amir Bergman, Avshalom Manevich, Barak Peleg, Ben Aviram, Chen Almagor, Clara Fridman, Dan Padnos, Daniel Gissin, Daniel Jannai, Dor Muhlgay, Dor Zimberg, Edden M. Gerber, Elad Dolev, Eran Krakovsky, Erez Safahi, Erez Schwartz, Gal Cohen, et al. Jamba : Hybrid transformer- Mamba language models. In International Confe...
2025
-
[18]
Longhorn: State space models are amortized online learners
Bo Liu, Rui Wang, Lemeng Wu, Yihao Feng, Peter Stone, and Qiang Liu. Longhorn: State space models are amortized online learners. arXiv preprint arXiv:2407.14207, 2024 a
arXiv 2024
-
[19]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12: 0 157--173, 2024 b
2024
-
[20]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016
Pith/arXiv arXiv 2016
-
[21]
RWKV : Reinventing RNN s for the transformer era
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, et al. RWKV : Reinventing RNN s for the transformer era. arXiv preprint arXiv:2305.13048, 2023
Pith/arXiv arXiv 2023
-
[22]
Eagle and finch: RWKV with matrix-valued states and dynamic recurrence
Bo Peng, Daniel Goldstein, Quentin Anthony, Alon Albalak, Eric Alcaide, Stella Biderman, et al. Eagle and finch: RWKV with matrix-valued states and dynamic recurrence. arXiv preprint arXiv:2404.05892, 2024
Pith/arXiv arXiv 2024
-
[23]
Hyena hierarchy: Towards larger convolutional language models
Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher R \'e . Hyena hierarchy: Towards larger convolutional language models. In International Conference on Machine Learning, pages 28043--28078. PMLR, 2023
2023
-
[24]
Mechanistic design and scaling of hybrid architectures
Michael Poli, Armin W Thomas, Eric Nguyen, Pragaash Ponnusamy, Bj \"o rn Deiseroth, Kristian Kersting, Taiji Suzuki, Brian Hie, Stefano Ermon, Christopher R \'e , et al. Mechanistic design and scaling of hybrid architectures. arXiv preprint arXiv:2403.17844, 2024
arXiv 2024
-
[25]
HGRN2 : Gated linear RNN s with state expansion
Zhen Qin, Songlin Li, Weixuan Sun, Xuyang Zhong, Dongxu Yang, Bowen Peng, Hao Zhong, et al. HGRN2 : Gated linear RNN s with state expansion. arXiv preprint arXiv:2404.07904, 2024
arXiv 2024
-
[26]
Rae, Anna Potapenko, Siddhant M
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Chloe Hillier, and Timothy P. Lillicrap. Compressive transformers for long-range sequence modelling. arXiv preprint arXiv:1911.05507, 2019
Pith/arXiv arXiv 1911
-
[27]
Bayesian filtering and smoothing
Simo S \"a rkk \"a . Bayesian filtering and smoothing. Cambridge University Press, 2013. ISBN 9781107619289. URL http://www.worldcat.org/isbn/9781107619289
arXiv 2013
-
[28]
Linear transformers are secretly fast weight programmers
Imanol Schlag, Kazuki Irie, and J \"u rgen Schmidhuber. Linear transformers are secretly fast weight programmers. arXiv preprint arXiv:2102.11174, 2021
arXiv 2021
-
[29]
Learning to control fast-weight memories: An alternative to dynamic recurrent networks
J \"u rgen Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks. Neural Computation, 4 0 (1): 0 131--139, 1992
1992
-
[30]
Vaisakh Shaj, Cameron Barker, Aidan Scannell, Andras Szecsenyi, Elliot J. Crowley, and Amos Storkey. Kalman linear attention: Parallel bayesian filtering for efficient language modelling and state tracking. arXiv preprint arXiv:2602.10743, 2026
Pith/arXiv arXiv 2026
-
[31]
Deltaproduct: Increasing the expressivity of deltanet through products of householders
Julien Siems, Timur Carstensen, Arber Zela, Frank Hutter, Massimiliano Pontil, and Riccardo Grazzi. Deltaproduct: Increasing the expressivity of deltanet through products of householders. arXiv preprint arXiv:2502.10297, 2025
arXiv 2025
-
[32]
Steeves, Joel Hestness, and Nolan Dey
Daria Soboleva, Faisal Al-Khateeb, Robert Myers, Jacob R. Steeves, Joel Hestness, and Nolan Dey. SlimPajama : A 627 B token cleaned and deduplicated version of RedPajama . https://www.cerebras.net/blog/slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama, 2023. Cerebras Systems blog
2023
-
[33]
Retentive network: A successor to transformer for large language models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models. arXiv preprint arXiv:2307.08621, 2023
Pith/arXiv arXiv 2023
-
[34]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[35]
Johannes von Oswald, Nino Scherrer, Seijin Kobayashi, Luca Versari, Songlin Yang, Maximilian Schlegel, Kaitlin Maile, Yanick Schimpf, Oliver Sieberling, Alexander Meulemans, Rif A. Saurous, Guillaume Lajoie, Charlotte Frenkel, Razvan Pascanu, Blaise Ag \"u era y Arcas, and Jo \ a o Sacramento. MesaNet : Sequence modeling by locally optimal test-time train...
Pith/arXiv arXiv 2025
-
[36]
Rush, and Tri Dao
Junxiong Wang, Daniele Paliotta, Avner May, Alexander M. Rush, and Tri Dao. The Mamba in the Llama : Distilling and accelerating hybrid models. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[37]
Gated linear attention transformers with hardware-efficient training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training. arXiv preprint arXiv:2312.06635, 2023
Pith/arXiv arXiv 2023
-
[38]
Gated delta networks: Improving mamba2 with delta rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. arXiv preprint arXiv:2412.06464, 2024 a
Pith/arXiv arXiv 2024
-
[39]
Parallelizing linear transformers with the delta rule over sequence length
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length. Advances in neural information processing systems, 37: 0 115491--115522, 2024 b
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.