Detect in Any Scene: An Agentic Framework for Object Detection with Experience-Aware Reasoning
Pith reviewed 2026-06-28 22:36 UTC · model grok-4.3
The pith
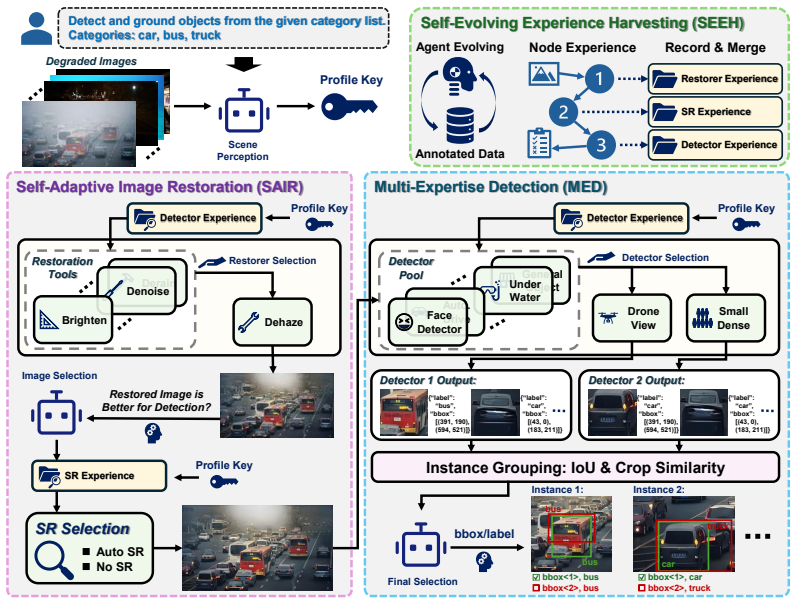
An MLLM agent adaptively selects restoration steps and specialized detectors to improve object detection across degraded scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an agentic framework using an MLLM to compose detection workflows from restoration modules and specialized detectors, augmented by experience harvesting from limited annotated data, produces higher detection accuracy than static or end-to-end alternatives on benchmarks featuring diverse image degradations.
What carries the argument
The MLLM as central agent that selects restoration and detector modules from a toolbox and incorporates harvested node-level decision experience for experience-aware reasoning.
If this is right
- Detection accuracy rises when restoration is applied conditionally rather than uniformly across all inputs.
- Instance-level reasoning can reconcile outputs from multiple domain-specialized detectors without requiring a single universal model.
- Decision policies improve over successive inferences as experience nodes accumulate from small annotated collections.
- The same agentic structure supports handling of heterogeneous object distributions by routing each image to appropriate expertise.
Where Pith is reading between the lines
- The experience-harvesting loop could be applied to other perception tasks such as instance segmentation where degradation and domain shifts also appear.
- If decision consistency holds, repeated deployment might allow the system to self-calibrate toward particular deployment environments without additional labels.
- Testing the framework with a larger and more diverse set of restoration and detector options would reveal whether performance scales with toolbox size.
Load-bearing premise
The MLLM can make reliable decisions about whether to restore an image and which detector to apply, and that experience collected from a small annotated set will transfer to new real-world conditions.
What would settle it
A new benchmark containing degradation types absent from the training experience where DetAS-X F1 scores fall below the strongest single fixed detector would falsify the adaptability claim.
Figures




read the original abstract
Object detection in real-world scenarios remains challenging due to diverse image degradations and heterogeneous object distributions, which significantly hinder the generalization of existing detectors. Conventional approaches, including scene-specific representation learning and end-to-end pipeline design, are inherently limited by their reliance on predefined conditions and lack adaptability to dynamic environments. In this paper, we propose DetAS, an agentic detection framework that formulates object detection as a dynamic decision process. Instead of relying on static pipelines, DetAS leverages a Multimodal Large Language Model (MLLM) as a central agent to adaptively compose detection workflows by selecting from a toolbox of restoration modules and specialized detectors. Specifically, DetAS consists of two key components: Self-Adaptive Image Restoration, which dynamically determines whether and how to enhance images for downstream detection, and Multi-Expertise Detection, which integrates multiple domain-specialized detectors and resolves their predictions through instance-level reasoning. To further improve decision quality under fine-grained conditions, we introduce Self-Evolving Experience Harvesting and extend the framework to DetAS-X, which accumulates node-level decision experience from a small set of annotated data and enables experience-aware reasoning during inference. This mechanism allows the system to progressively refine its decision policy and adapt to diverse real-world scenarios. Extensive experiments on six challenging benchmarks demonstrate that DetAS-X significantly outperforms existing MLLM-based detectors, achieving an average improvement of 28.36% in F1 score, with up to 37.01% gain on DarkFace. These results demonstrate the promise of agentic detection and establish a solid foundation for its application in complex and dynamic environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DetAS, an agentic object detection framework that uses an MLLM as a central agent to dynamically compose workflows by selecting restoration modules and domain-specialized detectors. Key components are Self-Adaptive Image Restoration (deciding whether/how to enhance images) and Multi-Expertise Detection (integrating multiple detectors with instance-level reasoning). DetAS-X extends this with Self-Evolving Experience Harvesting, accumulating node-level decisions from a small annotated set to enable experience-aware reasoning at inference. Experiments on six benchmarks are claimed to show DetAS-X outperforming existing MLLM-based detectors by 28.36% average F1 (up to 37.01% on DarkFace).
Significance. If the performance claims and attribution to the agentic components hold after proper validation, the work would demonstrate a promising direction for adaptive detection systems that handle diverse degradations without fixed pipelines, with the experience-harvesting mechanism offering a path to generalization from limited data.
major comments (2)
- [Abstract] Abstract: The reported F1 gains (28.36% average, 37.01% on DarkFace) are presented without any description of experimental setup, baselines, datasets details, error analysis, or statistical validation, making it impossible to determine whether the data support the central claim that gains derive from the agentic framework.
- [Framework description (Self-Evolving Experience Harvesting and MLLM decision process)] Framework description (Self-Evolving Experience Harvesting and MLLM decision process): No direct validation is provided for the MLLM's node-level decisions on restoration and detector selection (e.g., decision accuracy, confusion matrices on chosen actions, or ablations replacing the MLLM policy with random or fixed baselines), which is load-bearing for attributing improvements to the agent rather than the underlying toolbox.
minor comments (1)
- The abstract and framework overview introduce 'Self-Evolving Experience Harvesting' without specifying the representation of experience (e.g., how node-level decisions are stored or retrieved) or the exact mechanism for progressive refinement.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive suggestions. We address the major comments point-by-point below, providing clarifications from the manuscript and outlining revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported F1 gains (28.36% average, 37.01% on DarkFace) are presented without any description of experimental setup, baselines, datasets details, error analysis, or statistical validation, making it impossible to determine whether the data support the central claim that gains derive from the agentic framework.
Authors: The abstract is intentionally concise to highlight the core contributions and key results. Detailed experimental setup, including the six benchmarks, baselines (existing MLLM-based detectors), and protocols are provided in Section 4 (Experimental Setup) and Section 5 (Results and Analysis). Error analysis appears in Section 5.5 and statistical validation (multiple runs with standard deviations) is reported in the main results tables. To improve accessibility for readers, we will expand the abstract to briefly reference the experimental context, key baselines, and the source of the reported gains. revision: partial
-
Referee: [Framework description (Self-Evolving Experience Harvesting and MLLM decision process)] Framework description (Self-Evolving Experience Harvesting and MLLM decision process): No direct validation is provided for the MLLM's node-level decisions on restoration and detector selection (e.g., decision accuracy, confusion matrices on chosen actions, or ablations replacing the MLLM policy with random or fixed baselines), which is load-bearing for attributing improvements to the agent rather than the underlying toolbox.
Authors: We agree that direct validation of the MLLM's node-level decisions would strengthen attribution of gains to the agentic components. To address this concern, we will add quantitative analyses in the revised manuscript, including confusion matrices for restoration and detector selection decisions on a held-out validation set, as well as ablations that replace the MLLM policy with random selection and fixed pipelines. These additions will be placed in Section 5.4 alongside the existing experience-harvesting results. revision: yes
Circularity Check
No circularity: experimental claims rest on benchmark results, not self-referential definitions or fits
full rationale
The paper describes an agentic MLLM framework (DetAS/DetAS-X) that selects restoration modules and detectors, harvests experience from annotated data, and reports F1 gains on six benchmarks. No equations, self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the abstract or described components. The central performance numbers are presented as outcomes of external experiments rather than quantities forced by the framework's own definitions or prior author results. The derivation chain is therefore self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A multimodal large language model can serve as a reliable central agent for composing detection workflows by selecting restoration modules and specialized detectors.
invented entities (1)
-
Self-Evolving Experience Harvesting
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. 9 arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Jiaxing Chen, Yuxuan Liu, Dehu Li, Xiang An, Weimo Deng, Ziyong Feng, Yongle Zhao, and Yin Xie. Plug-and-play grounding of reasoning in multimodal large language models.arXiv preprint arXiv:2403.19322,
-
[4]
Changfeng Feng, Zhenyuan Chen, Xiang Li, Chunping Wang, Jian Yang, Ming-Ming Cheng, Yimian Dai, and Qiang Fu. Hazydet: Open-source benchmark for drone-view object detection with depth-cues in hazy scenes.arXiv preprint arXiv:2409.19833,
-
[5]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Qing Jiang, Xingyu Chen, Zhaoyang Zeng, Junzhi Yu, and Lei Zhang. Rex-thinker: Grounded object referring via chain-of-thought reasoning.arXiv preprint arXiv:2506.04034, 2025a. Qing Jiang, Junan Huo, Xingyu Chen, Yuda Xiong, Zhaoyang Zeng, Yihao Chen, Tianhe Ren, Junzhi Yu, and Lei Zhang. Detect anything via next point prediction.arXiv preprint arXiv:2510....
-
[8]
Bingyu Li, Feiyu Wang, Da Zhang, Zhiyuan Zhao, Junyu Gao, and Xuelong Li. Maris: Marine open-vocabulary instance segmentation with geometric enhancement and semantic alignment. arXiv preprint arXiv:2510.15398,
-
[9]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InComputer Vision– ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer,
2014
-
[10]
Shiyin Lu, Yang Li, Yu Xia, Yuwei Hu, Shanshan Zhao, Yanqing Ma, Zhichao Wei, Yinglun Li, Lunhao Duan, Jianshan Zhao, et al. Ovis2. 5 technical report.arXiv preprint arXiv:2508.11737,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Liqin Luo, Guangyao Chen, Xiawu Zheng, Yongxing Dai, Yixiong Zou, and Yonghong Tian. Connecting the dots: Training-free visual grounding via agentic reasoning.arXiv preprint arXiv:2511.19516,
-
[12]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
VGR: Visual Grounded Reasoning
Jiacong Wang, Zijian Kang, Haochen Wang, Haiyong Jiang, Jiawen Li, Bohong Wu, Ya Wang, Jiao Ran, Xiao Liang, Chao Feng, et al. Vgr: Visual grounded reasoning.arXiv preprint arXiv:2506.11991, 2025a. Sen Wang, Shao Zeng, Tianjun Gu, Zhizhong Zhang, Ruixin Zhang, Shouhong Ding, Jingyun Zhang, Jun Wang, Xin Tan, Yuan Xie, et al. From enhancement to understand...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Multimodal large language models: A survey
Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, and Philip S Yu. Multimodal large language models: A survey. In2023 IEEE International Conference on Big Data (BigData), pages 2247–2256. IEEE, 2023a. Rui-Qi Wu, Zheng-Peng Duan, Chun-Le Guo, Zhi Chai, and Chongyi Li. Ridcp: Revitalizing real image dehazing via high-quality codebook priors. InProceeding...
-
[15]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, et al. Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe.arXiv preprint arXiv:2509.18154,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
4kagent: agentic any image to 4k super-resolution.arXiv preprint arXiv:2507.07105,
Yushen Zuo, Qi Zheng, Mingyang Wu, Xinrui Jiang, Renjie Li, Jian Wang, Yide Zhang, Gengchen Mai, Lihong V Wang, James Zou, et al. 4kagent: agentic any image to 4k super-resolution.arXiv preprint arXiv:2507.07105,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.