Learning Cardiac Latent Representations in Vectorcardiogram Space
Pith reviewed 2026-06-28 23:35 UTC · model grok-4.3
The pith
Learning representations in vectorcardiogram space reduces redundancy and improves generalization over twelve-lead ECG methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
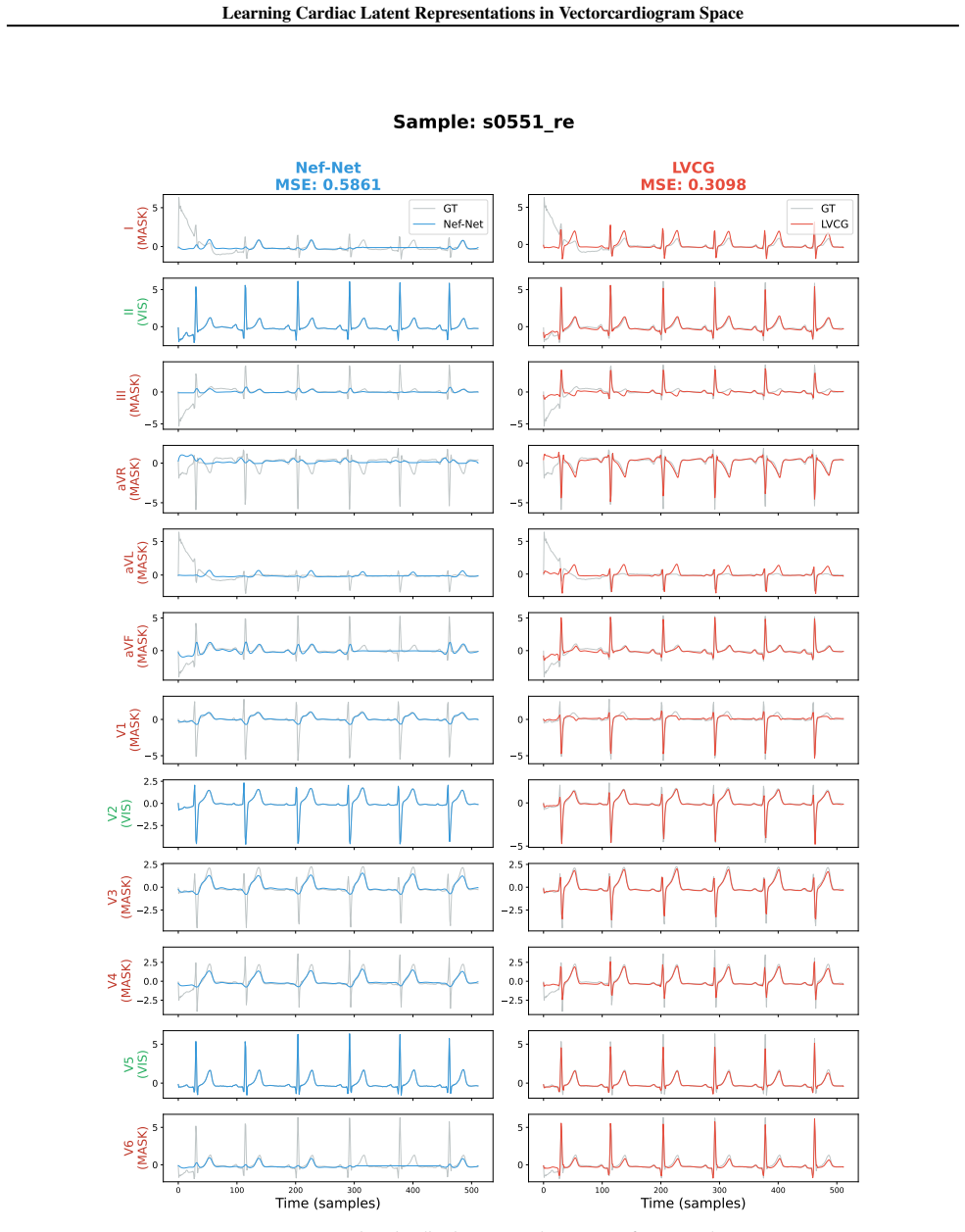
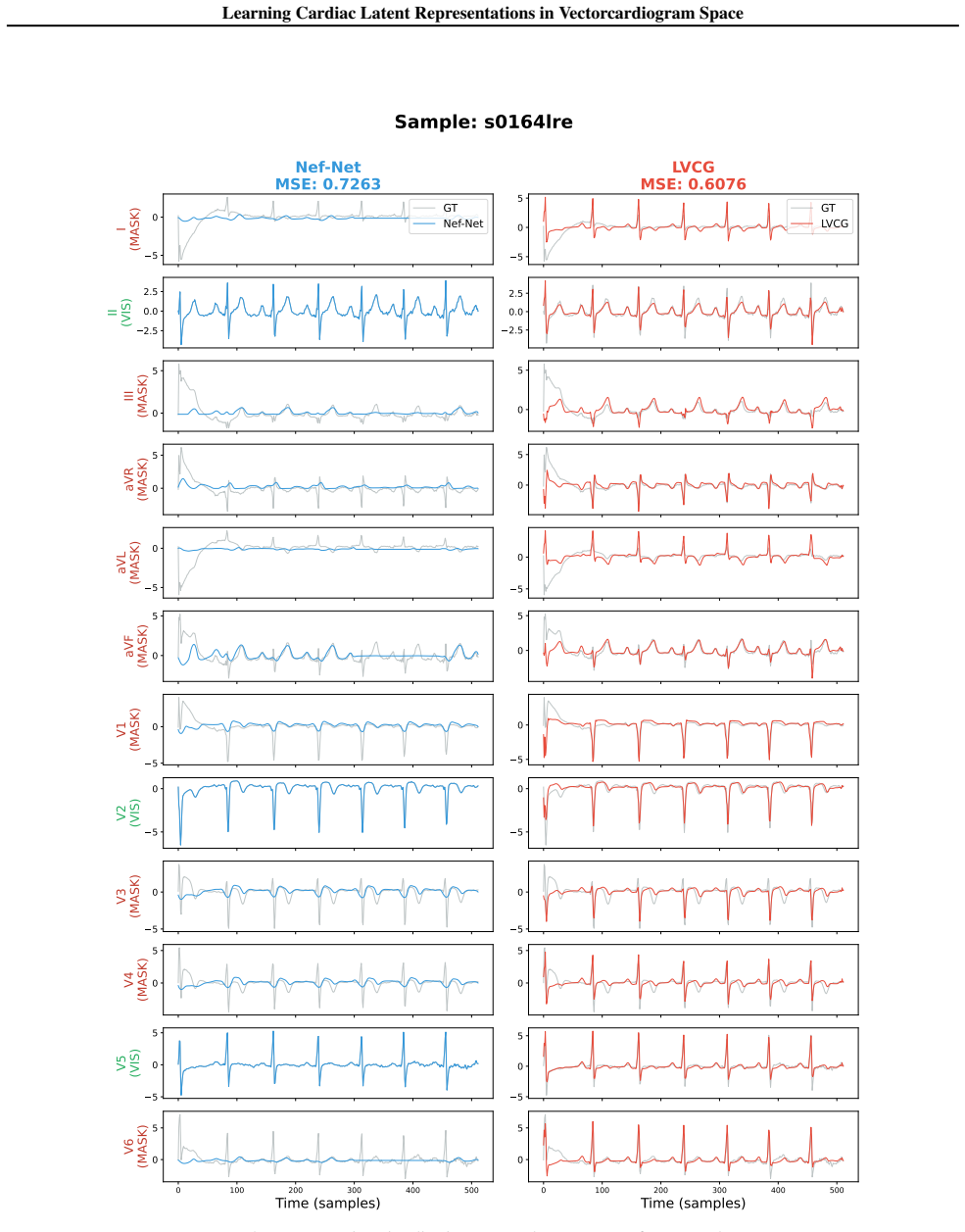
By learning view-invariant latent VCG representations rather than lead-specific artifacts, LVCG minimizes redundancy and improves generalization. LVCG generally outperforms ECG-space baselines across tasks, demonstrating enhanced robustness and generalization, especially in domain shift settings.
What carries the argument
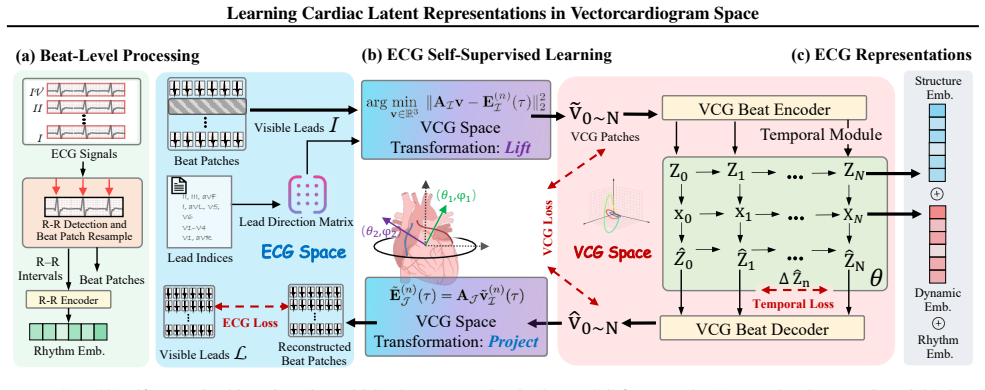
LVCG, the self-supervised framework that learns unified latent representations directly in the physically grounded Frank VCG space instead of the projected twelve-lead ECG space.
If this is right
- LVCG produces higher accuracy than ECG-space methods on standard cardiac tasks.
- The method shows particular gains in robustness when the data distribution changes across recording sites or patient groups.
- View-invariant features learned in VCG space avoid spurious correlations tied to individual lead placements.
- The reduction in redundancy lowers the risk that models overfit to artifacts rather than true cardiac signals.
Where Pith is reading between the lines
- The same principle of moving from multiple surface projections to an underlying physical latent space could apply to other multi-sensor biomedical signals.
- If VCG reconstruction from standard ECG leads proves stable, LVCG could be inserted into existing clinical pipelines without new hardware.
- Domain-shift gains suggest the method may help when models trained on hospital data are deployed in wearable or ambulatory settings.
Load-bearing premise
The Frank VCG model supplies a latent space that already contains less redundancy than the twelve-lead ECG projections.
What would settle it
A controlled experiment in which LVCG is trained and tested on the same tasks and domain-shift scenarios yet fails to match or exceed ECG-space baseline performance would falsify the central claim.
Figures

read the original abstract
Electrocardiography (ECG) is a cornerstone of cardiac assessment, making the learning of informative ECG representations fundamental to tasks ranging from disease diagnosis to clinical report generation. However, existing methods operate almost exclusively in the observable ECG signal space. In practice, the standard twelve-lead ECG represents multiple projections of the same underlying cardiac electrical activity from different spatial orientations. Therefore, representation learning in the ECG space inevitably introduces substantial redundancy, which may lead to spurious correlations and increased risk of overfitting. To address this and motivated by the Frank vectorcardiogram (VCG) model, we propose learning a unified latent representation of cardiac electrical activity directly in the VCG space. We introduce LVCG, the first general self-supervised representation learning framework designed to operate in this physically grounded latent space. By learning view-invariant latent VCG representations rather than lead-specific artifacts, VCG minimizes redundancy and improves generalization. LVCG generally outperforms ECG-space baselines across tasks, demonstrating enhanced robustness and generalization, especially in domain shift settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LVCG, the first self-supervised representation learning framework operating directly in Frank vectorcardiogram (VCG) space rather than twelve-lead ECG space. It claims that the physically grounded VCG model yields view-invariant latent representations with lower redundancy than lead-specific ECG projections, thereby reducing spurious correlations and improving generalization and robustness, with LVCG outperforming ECG-space baselines across tasks especially under domain shift.
Significance. If the empirical gains are shown to arise specifically from reduced redundancy in the VCG space (rather than architecture or training differences) and the Frank model is sufficiently complete for the evaluated populations, the approach could supply a principled, physically motivated alternative to standard ECG representation learning with better out-of-distribution behavior.
major comments (2)
- [Abstract, Introduction] Abstract and Introduction: The central claim that 'VCG minimizes redundancy' and thereby improves generalization rests on the untested modeling assumption that the Frank dipole model provides a lower-redundancy space than 12-lead projections without information loss for task-relevant signals. No direct measurement (mutual information, effective dimensionality, or reconstruction error) comparing learned VCG latents to ECG inputs is supplied to support this attribution.
- [Experiments] Experiments/Results: The reported outperformance over ECG-space baselines is presented as evidence of enhanced robustness due to the VCG space, yet the manuscript provides no ablation that isolates the contribution of the VCG representation from differences in the self-supervised objective, network architecture, or training procedure. This leaves open the possibility that gains are not load-bearing on the claimed redundancy reduction.
minor comments (1)
- [Methods] Notation: The distinction between the learned latent VCG representation and the input VCG reconstruction could be clarified with consistent symbols across equations and figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional evidence would strengthen our claims. We address each major comment below and agree that revisions are warranted to provide direct measurements and ablations. These will be incorporated in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract, Introduction] Abstract and Introduction: The central claim that 'VCG minimizes redundancy' and thereby improves generalization rests on the untested modeling assumption that the Frank dipole model provides a lower-redundancy space than 12-lead projections without information loss for task-relevant signals. No direct measurement (mutual information, effective dimensionality, or reconstruction error) comparing learned VCG latents to ECG inputs is supplied to support this attribution.
Authors: We agree that direct quantitative support for the redundancy reduction claim would strengthen attribution of gains to the VCG space. The Frank model is a well-established physical representation of cardiac electrical activity as a dipole, which by construction uses three orthogonal components rather than the redundant projections in 12-lead ECG. While our empirical results (particularly under domain shift) are consistent with this motivation, we will add in revision explicit comparisons: mutual information between learned latents and inputs, effective dimensionality via participation ratio or PCA, and reconstruction error from VCG vs. ECG representations. This will provide the requested measurements. revision: yes
-
Referee: [Experiments] Experiments/Results: The reported outperformance over ECG-space baselines is presented as evidence of enhanced robustness due to the VCG space, yet the manuscript provides no ablation that isolates the contribution of the VCG representation from differences in the self-supervised objective, network architecture, or training procedure. This leaves open the possibility that gains are not load-bearing on the claimed redundancy reduction.
Authors: We acknowledge that the current experiments compare against published ECG-space baselines without fully matched architectures and objectives, leaving room for confounding factors. To isolate the effect of operating in VCG space, the revised manuscript will include controlled ablations: (1) applying the identical self-supervised objective and network architecture to both VCG and ECG inputs, and (2) additional controls varying only the input representation while holding all other factors fixed. These will directly test whether performance differences arise from the representation space itself. revision: yes
Circularity Check
No circularity; empirical claims rest on external comparisons without self-referential reductions.
full rationale
The provided manuscript text contains no equations, derivations, or parameter-fitting steps that reduce any claimed result to its own inputs by construction. The central motivation (Frank VCG model yields lower-redundancy space than 12-lead projections) is presented as a modeling assumption rather than a derived theorem, and performance claims are supported by task comparisons to baselines. No self-citation chains, ansatz smuggling, or renaming of known results appear. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Frank vectorcardiogram model accurately captures the underlying cardiac electrical activity as a low-redundancy 3D representation superior to twelve-lead ECG projections.
invented entities (1)
-
LVCG framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chen, J., Zheng, X., Yu, H., Chen, D. Z., and Wu, J. Electro- cardio panorama: synthesizing new ecg views with self- supervision.arXiv preprint arXiv:2105.06293, 2021a. Chen, J., Liao, K., Wei, K., Ying, H., Chen, D. Z., and Wu, J. Me-gan: Learning panoptic electrocardio repre- sentations for multi-view ecg synthesis conditioned on heart diseases. InInter...
-
[2]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Chen, X., Xie, S., and He, K. An empirical study of training self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pp. 9640–9649, 2021b. Cho, K., Van Merri ¨enboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., and Bengio, Y . Learn- ing phrase representations using rnn encoder-decoder...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Eldele, E., Ragab, M., Chen, Z., Wu, M., Kwoh, C. K., Li, X., and Guan, C. Time-series representation learning via temporal and contextual contrasting.arXiv preprint arXiv:2106.14112,
-
[4]
Jin, J., Wang, H., Li, H., Li, J., Pan, J., and Hong, S. Reading your heart: Learning ecg words and sentences via pre-training ecg language model.arXiv preprint arXiv:2502.10707,
-
[5]
Yunfei Luo, Yuliang Chen, Asif Salekin, and Tauhidur Rahman
Li, J., Aguirre, A., Moura, J., Liu, C., Zhong, L., Sun, C., Clifford, G., Westover, B., and Hong, S. An electro- cardiogram foundation model built on over 10 million recordings with external evaluation across multiple do- mains.arXiv preprint arXiv:2410.04133,
-
[6]
Zero-shot ecg classification with multimodal learning and test-time clinical knowledge enhancement
Liu, C., Wan, Z., Ouyang, C., Shah, A., Bai, W., and Ar- cucci, R. Zero-shot ecg classification with multimodal learning and test-time clinical knowledge enhancement. arXiv preprint arXiv:2403.06659,
-
[7]
Na, Y ., Park, M., Tae, Y ., and Joo, S. Guiding masked repre- sentation learning to capture spatio-temporal relationship of electrocardiogram.arXiv preprint arXiv:2402.09450,
-
[8]
Pham, H. M., Saeed, A., and Ma, D. Boosting masked ecg-text auto-encoders as discriminative learners.arXiv preprint arXiv:2410.02131,
-
[9]
Wang, F., Xu, J., and Yu, L. From token to rhythm: A multi-scale approach for ecg-language pretraining.arXiv preprint arXiv:2506.21803,
-
[10]
Nef-net+: Adapting electrocardio panorama in the wild
Zhan, Z., Hu, Y ., Zhan, J., Lian, W., Wu, W., and Chen, J. Nef-net+: Adapting electrocardio panorama in the wild. arXiv preprint arXiv:2511.02880,
-
[11]
The coordinate system is: x axis right→left, y axis superior→inferior, and z axis anterior→posterior
using fixed direction vectors from a standard 12-lead ECG geometry. The coordinate system is: x axis right→left, y axis superior→inferior, and z axis anterior→posterior. Limb leads lie in the frontal plane (z= 0 ) with Einthoven-style angles, while precordial leads use an approximate transverse- plane geometry with a small inferior tilt. We use the MIMIC ...
2000
-
[12]
Dataset Statistics In our study, we utilize a diverse set of ECG datasets for large-scale pre-training and comprehensive evaluation
B.2. Dataset Statistics In our study, we utilize a diverse set of ECG datasets for large-scale pre-training and comprehensive evaluation. Table 9 summarizes the core statistics of these datasets. Following the protocols in HeartLang (Jin et al., 2025), we utilize the full volume of MIMIC-IV-ECG for self-supervised pre-training and evaluate the learned rep...
2025
-
[13]
Evaluation 21,837 18,885 10s 500 12 5/21/44/12 Classification CPSC 2018 (Liu et al.,
2018
-
[14]
and CPSC 2018 (Liu et al.,
2018
-
[15]
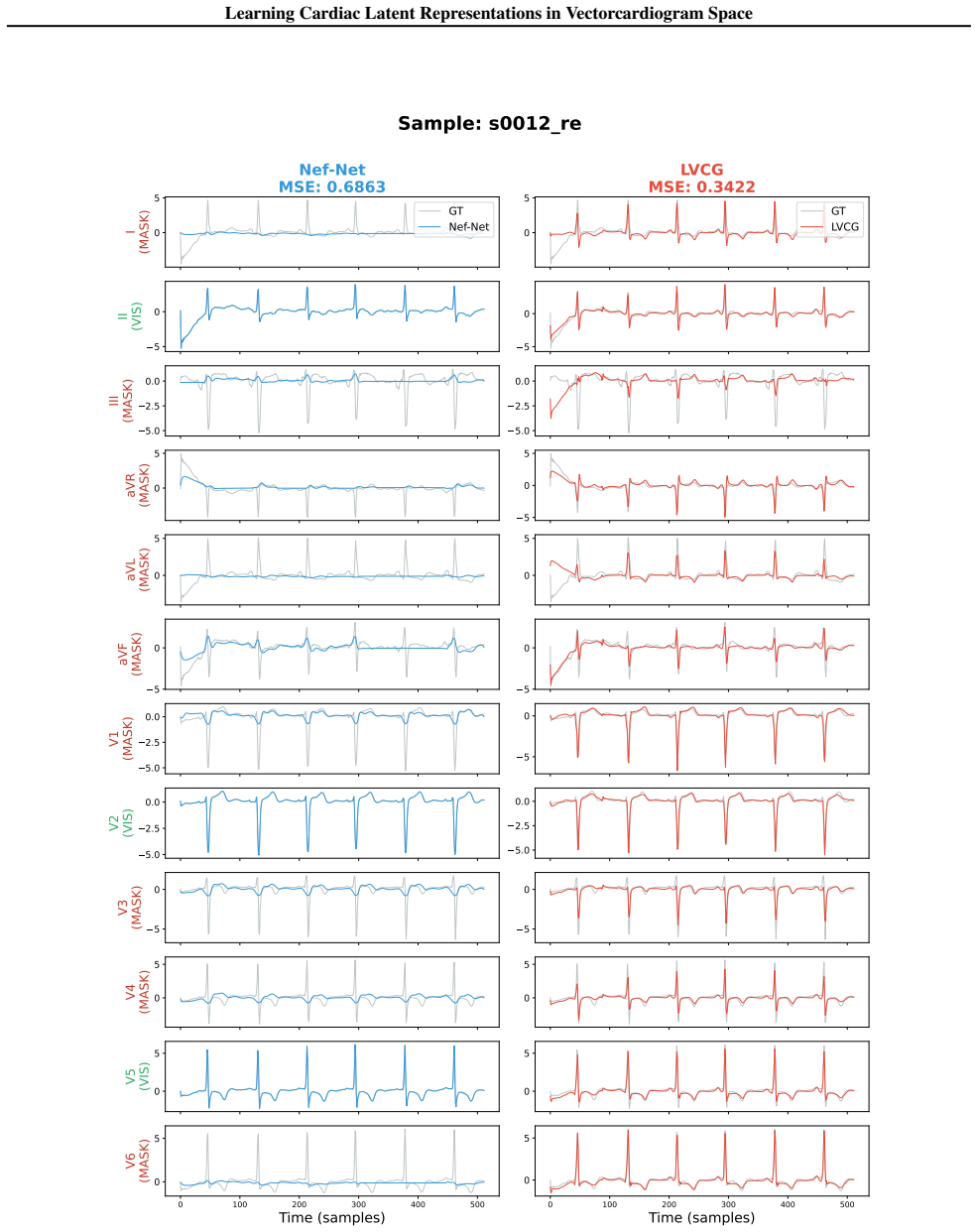
PTB provides high-resolution signals (1000 Hz) that are ideal for verifying fine-grained morphological recovery
datasets. PTB provides high-resolution signals (1000 Hz) that are ideal for verifying fine-grained morphological recovery. CPSC 2018 contains signals with diverse arrhythmias and varying durations, providing a robust test for view-synthesis generalization. For both datasets, we simulate a view-generation scenario where the model reconstructs the full 12-l...
2018
-
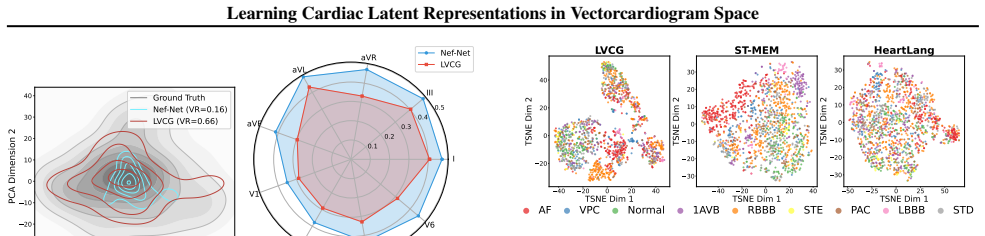
[16]
Nef-Net (Chen et al., 2021a) 782.84 24.6388.6325.22 0.23 LVCG 374.04 23.9491.0622.81 0.21 Table 11.Robustness under simulated electrode perturbation (linear probing). Setting AUC (%) F1 (%)∆AUC vs. baseline (pp) baseline 67.55 27.72 +0.00 noise: 0.01 67.55 27.79 +0.00 noise: 0.05 67.57 27.86 +0.02 noise: 0.1 67.59 27.87 +0.04 noise: 0.2 67.41 27.56−0.14 r...
-
[17]
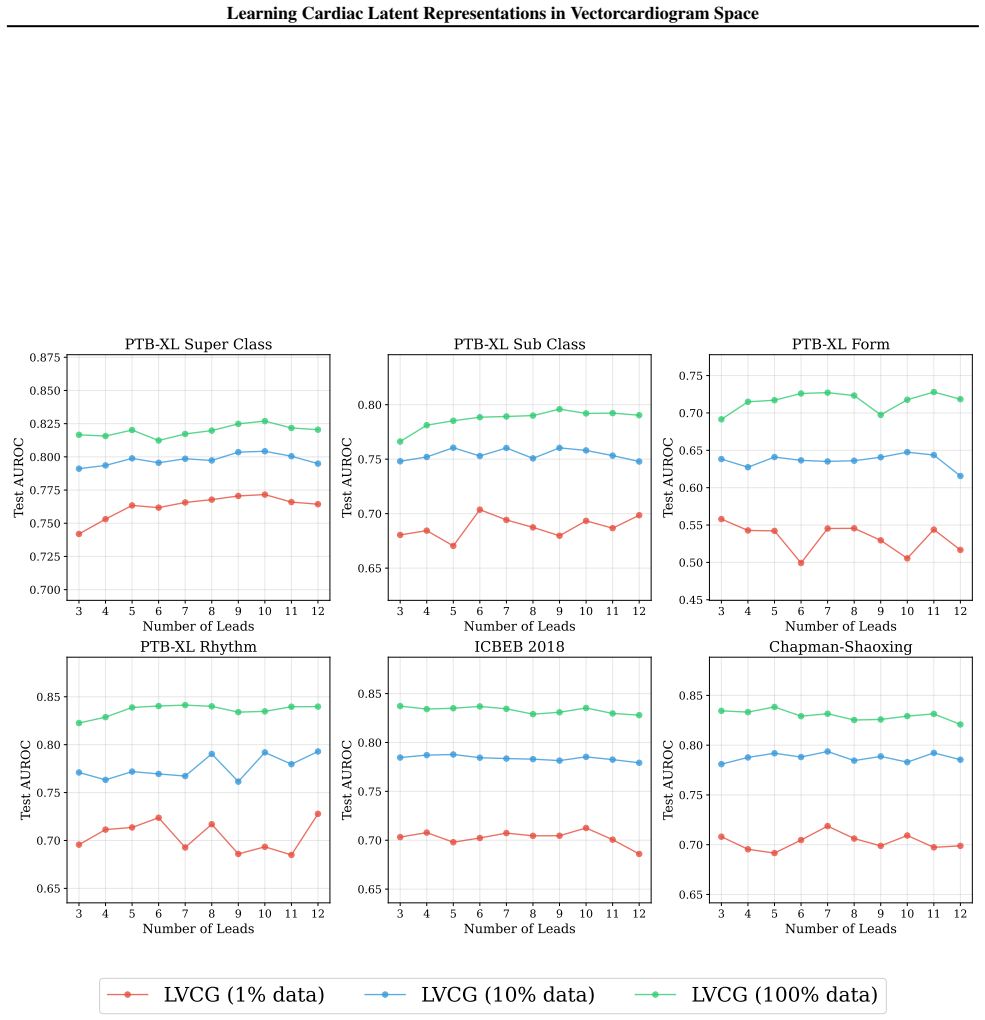
Furthermore, LVCG demonstrates highlabel efficiencyregardless of lead sparsity
This provides strong empirical validation for our latent VCG formulation: as long as the visible leads provide a sufficient spatial span to recover the underlying cardiac electrical field (i.e., at least 3 leads), LVCG can effectively map the signals into a consistent latent space for downstream classification. Furthermore, LVCG demonstrates highlabel eff...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.