Divergence Decoding: Inference-Time Unlearning via Auxiliary Models
Pith reviewed 2026-06-28 22:51 UTC · model grok-4.3
The pith
Divergence Decoding steers LLM logits with small auxiliary models to remove specific memorized data at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
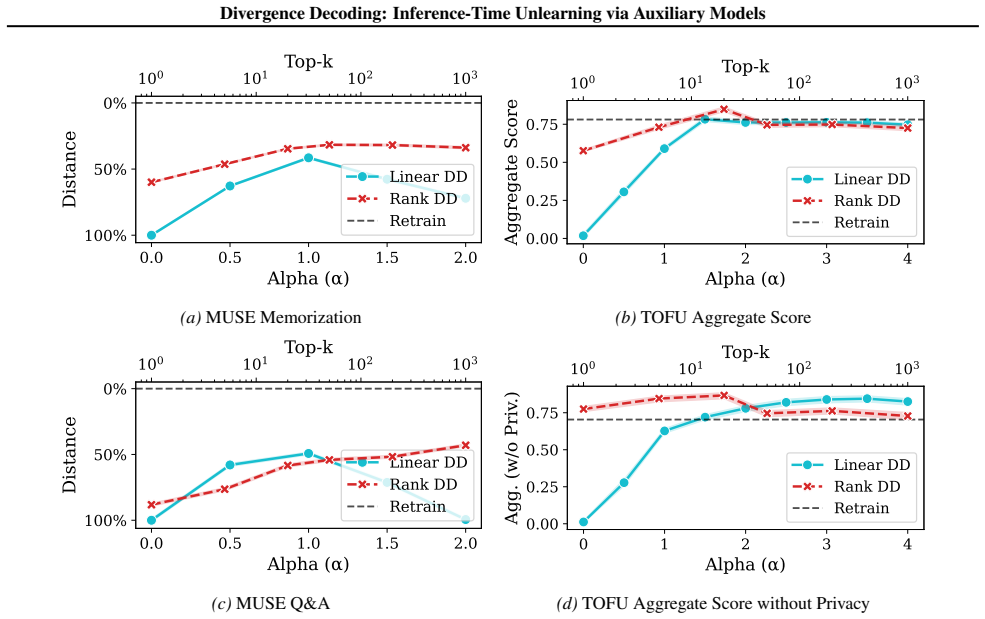
Divergence Decoding steers the logits of an LLM using small auxiliary models during inference to avoid generating specific memorized data. These auxiliary models are trained straightforwardly via pre-training and fine-tuning. The method outperforms state-of-the-art unlearning baselines across model and dataset scales, and the steered distribution can be distilled back into the original model. The approach generalizes to non-text domains like images.
What carries the argument
Divergence Decoding, a logit-steering mechanism that uses auxiliary models to adjust the probability distribution away from targeted data during inference.
If this is right
- The method outperforms state-of-the-art baselines on unlearning benchmarks across a variety of model and training dataset scales.
- The steered distribution produced by the auxiliary models can be distilled back into the base model.
- The technique applies to any probabilistic model and shows evidence of generalization to the domain of images.
- It provides an effective and inexpensive solution to unlearning that avoids the utility loss common in prior methods.
Where Pith is reading between the lines
- Because the auxiliary models are small, the overhead may remain low even when the base model grows much larger.
- Distilling the steered behavior back into the base model could turn the inference-time fix into a permanent change.
- The same auxiliary-model idea might combine with other unlearning approaches to handle harder or more complex queries.
- Further tests on real-world copyright or privacy datasets would clarify whether the image-domain result extends to other modalities.
Load-bearing premise
Small auxiliary models trained with standard pre-training and fine-tuning setups can reliably steer the main model's logits away from specific data during inference without causing catastrophic utility loss.
What would settle it
A benchmark run in which the auxiliary models are applied yet the LLM still assigns high probability to the target sensitive sequences while utility on unrelated tasks drops sharply.
Figures


















read the original abstract
Large Language Models (LLMs) frequently memorize sensitive training data thereby creating significant privacy and copyright risks. Addressing these risks, i.e., removing such knowledge from an existing model checkpoint, has proven challenging as many unlearning methods lead to catastrophic utility loss or are ineffective for complex queries. We introduce Divergence Decoding (DD), a mechanism that uses small auxiliary models to steer the logits of the LLM away from specific data during inference. Training these models is straight forward, i.e., we use standard pre-training and fine-tuning setups. We find the method decisively outperforms state-of-the-art (SOTA) baselines on unlearning benchmarks across a variety of model and training dataset scales consistent with DD being an effective and inexpensive solution to unlearning. We then demonstrate that this steered distribution can be trivially distilled back into the base model. Since the method is generally applicable to any probabilistic model, we explore its efficacy outside of text generation and find evidence of generalization to the domain of images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Divergence Decoding (DD), an inference-time unlearning method for LLMs that uses small auxiliary models trained with standard pre-training and fine-tuning to steer the main model's logits away from specific sensitive data. The authors claim that this method decisively outperforms SOTA baselines on unlearning benchmarks across various model and dataset scales, that the steered distribution can be distilled back into the base model, and that it generalizes to image generation tasks.
Significance. If the empirical results hold with proper controls, DD would provide a practical inference-time unlearning approach that is inexpensive and avoids catastrophic utility loss, with potential extension to other probabilistic generative models.
major comments (2)
- [Abstract] Abstract: the claim of 'decisive outperformance' and 'generalization' is asserted without any quantitative metrics, error bars, dataset details, or failure cases, which is load-bearing for the central empirical claim of effectiveness across scales.
- [Method] Method (Divergence Decoding mechanism): the precise logit-combination rule (e.g., subtraction or re-weighting) between auxiliary and base models is not specified, leaving open whether correlations on non-target data cause unintended suppression and thus undermining the no-utility-loss premise.
minor comments (1)
- [Abstract] Abstract: the phrasing 'consistent with DD being an effective and inexpensive solution' is conclusory and should be supported by specific evidence or rephrased.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and support for the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'decisive outperformance' and 'generalization' is asserted without any quantitative metrics, error bars, dataset details, or failure cases, which is load-bearing for the central empirical claim of effectiveness across scales.
Authors: We agree that the abstract would benefit from quantitative support. The main text reports specific metrics, error bars, and dataset details across scales, along with some discussion of limitations. In revision we will update the abstract to include representative quantitative results, error bars, dataset scales, and a brief reference to observed failure cases. revision: yes
-
Referee: [Method] Method (Divergence Decoding mechanism): the precise logit-combination rule (e.g., subtraction or re-weighting) between auxiliary and base models is not specified, leaving open whether correlations on non-target data cause unintended suppression and thus undermining the no-utility-loss premise.
Authors: We accept that the exact logit-combination rule is insufficiently specified. The manuscript will be revised to state the precise combination formula (including any subtraction or re-weighting) and to analyze its effect on non-target tokens, thereby clarifying the utility-preservation argument. revision: yes
Circularity Check
No significant circularity; empirical method stands on independent benchmarks
full rationale
The paper describes an inference-time steering technique using separately trained auxiliary models. No equations, derivations, or parameter-fitting steps are shown that would reduce the claimed outperformance to a self-definition, a fitted input renamed as prediction, or a self-citation chain. The central result (decisive benchmark gains across scales) is presented as an empirical observation rather than a mathematical consequence of the method's own construction. The auxiliary models are trained with standard pre-training/fine-tuning, and the steering operation is described at a high level without any load-bearing uniqueness theorem or ansatz imported from prior self-work. This is the normal case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard pre-training and fine-tuning setups suffice to train effective auxiliary models for logit steering.
invented entities (1)
-
Divergence Decoding mechanism
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Forecasting With LLMs: Improved Generalization Through Feature Steering
Amplifying time-awareness features in LLMs via sparse autoencoders reduces look-ahead bias in forecasting while preserving general performance.
Reference graph
Works this paper leans on
-
[1]
URL https://aclanthology.org/D07-1090/
Association for Computational Linguistics. URL https://aclanthology.org/D07-1090/. Carlini, N., Tram `er, F., Wallace, E., Jagielski, M., Herbert-V oss, A., Lee, K., Roberts, A., Brown, T. B., Song, D. X., Erlingsson, ´U., Oprea, A., and Raf- fel, C. Extracting training data from large lan- guage models. InUSENIX Security Symposium,
-
[2]
URL https://api.semanticscholar. org/CorpusID:229156229. Chen, D., Chen, R., Zhang, S., Wang, Y ., Liu, Y ., Zhou, H., Zhang, Q., Wan, Y ., Zhou, P., and Sun, L. Mllm- as-a-judge: assessing multimodal llm-as-a-judge with vision-language benchmark. InProceedings of the 41st In- ternational Conference on Machine Learning, ICML’24. JMLR.org, 2024. DeepSeek-A...
Pith/arXiv arXiv 2024
-
[3]
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/2025.naacl-long
-
[4]
URL https://aclanthology.org/2025. naacl-long.444/. Dorna, V ., Mekala, A., Zhao, W., McCallum, A., Kolter, Z., Lipton, Z., and Maini, P. Openunlearning: Accelerating llm unlearning via unified benchmarking of methods and metrics. In Belgrave, D., Zhang, C., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., and Chen, N. (eds.),Advances in Neural Informatio...
-
[5]
URL https://proceedings.mlr.press/ v235/ghosh24a.html. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., and the rest of the Llama 3 team. The llama 3 herd of models, 2024. URL https://arxiv. org/abs/2407.21783. Hammersley, J. and Handscomb, D.Monte Carlo Meth- ods. Methuen’s monographs on applied probabil- ity and statistics. ...
Pith/arXiv arXiv 2024
-
[6]
URL https://openreview.net/forum? id=rygGQyrFvH. Huang, J. Y ., Zhou, W., Wang, F., Morstatter, F., Zhang, S., Poon, H., and Chen, M. Offset unlearning for large language models.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https:// openreview.net/forum?id=A4RLpHPXCu. Ilharco, G., Ribeiro, M. T., Wortsman, M., Schmidt, L., Hajishirz...
-
[7]
Springer-Verlag. ISBN 978-3-031-72672-9. doi: 10.1007/978-3-031-72673-6 20. URLhttps://doi. org/10.1007/978-3-031-72673-6_20. Liu, A., Sap, M., Lu, X., Swayamdipta, S., Bhagavatula, C., Smith, N. A., and Choi, Y . DExperts: Decoding- time controlled text generation with experts and anti- experts. In Zong, C., Xia, F., Li, W., and Navigli, R. 11 Divergence...
-
[8]
cc/paper_files/paper/2022/file/ 6f1d43d5a82a37e89b0665b33bf3a182-Paper-Conference
URL https://proceedings.neurips. cc/paper_files/paper/2022/file/ 6f1d43d5a82a37e89b0665b33bf3a182-Paper-Conference. pdf. Merchant, H. and Levy, B. A fast and effective solu- tion to the problem of look-ahead bias in LLMs. In NeurIPS 2025 Workshop: Generative AI in Finance,
2022
-
[9]
Mirzadeh, S.-I., Farajtabar, M., Li, A., Levine, N., Mat- sukawa, A., and Ghasemzadeh, H
URL https://openreview.net/forum? id=zYsLIPgM28. Mirzadeh, S.-I., Farajtabar, M., Li, A., Levine, N., Mat- sukawa, A., and Ghasemzadeh, H. Improved knowledge distillation via teacher assistant, 2019. URL https: //arxiv.org/abs/1902.03393. Qi, X., Panda, A., Lyu, K., Ma, X., Roy, S., Beirami, A., Mittal, P., and Henderson, P. Safety alignment should be mad...
arXiv 2019
-
[10]
Reisizadeh, H., Ruan, J., Chen, Y ., Pal, S., Liu, S., and Hong, M
URL https://openreview.net/forum? id=6Mxhg9PtDE. Reisizadeh, H., Ruan, J., Chen, Y ., Pal, S., Liu, S., and Hong, M. Leak@k: Unlearning does not make llms forget under probabilistic decoding.CoRR, abs/2511.04934, Novem- ber 2025. URL https://doi.org/10.48550/ arXiv.2511.04934. Rybak, P., Batorski, P., Swoboda, P., and Spurek, P. Rebel: Hidden knowledge re...
Pith/arXiv arXiv 2025
-
[11]
Shi, W., Lee, J., Huang, Y ., Malladi, S., Zhao, J., Holtzman, A., Liu, D., Zettlemoyer, L., Smith, N
URL https://openreview.net/forum? id=zWqr3MQuNs. Shi, W., Lee, J., Huang, Y ., Malladi, S., Zhao, J., Holtzman, A., Liu, D., Zettlemoyer, L., Smith, N. A., and Zhang, C. MUSE: Machine unlearning six-way evaluation for language models. InThe Thirteenth International Confer- ence on Learning Representations, 2025. URL https: //openreview.net/forum?id=TArmA0...
2025
-
[12]
URL https://proceedings.mlr.press/ v267/springer25a.html. Suriyakumar, V . M., Sekhari, A., and Wilson, A. Ucd: Unlearning in llms via contrastive decoding, 2025. URL https://arxiv.org/abs/2506.12097. Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Fer...
arXiv 2025
-
[13]
Zhong, Y ., Yang, Z., and Zhu, Z
URL https://openreview.net/forum? id=MXLBXjQkmb. Zhong, Y ., Yang, Z., and Zhu, Z. DUET: Distilled LLM unlearning from an efficiently contextualized teacher. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=Xa6QRrXrKX. 13 Divergence Decoding: Inference-Time Unlearning via Auxiliary Models A...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.