Diagnosing Failure Modes of Shared-State Collaboration in Resource-Constrained Visual Agents
Pith reviewed 2026-06-28 22:18 UTC · model grok-4.3
The pith
Naive shared workspaces amplify hallucinations in resource-constrained visual agents rather than resolving them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
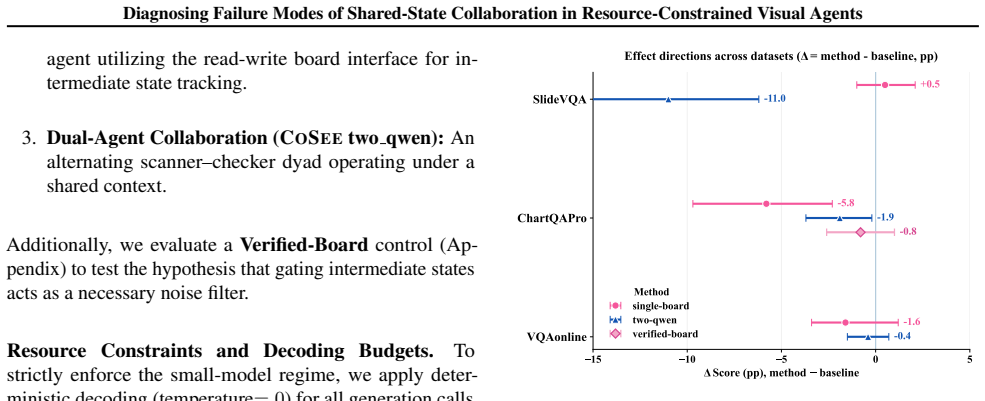
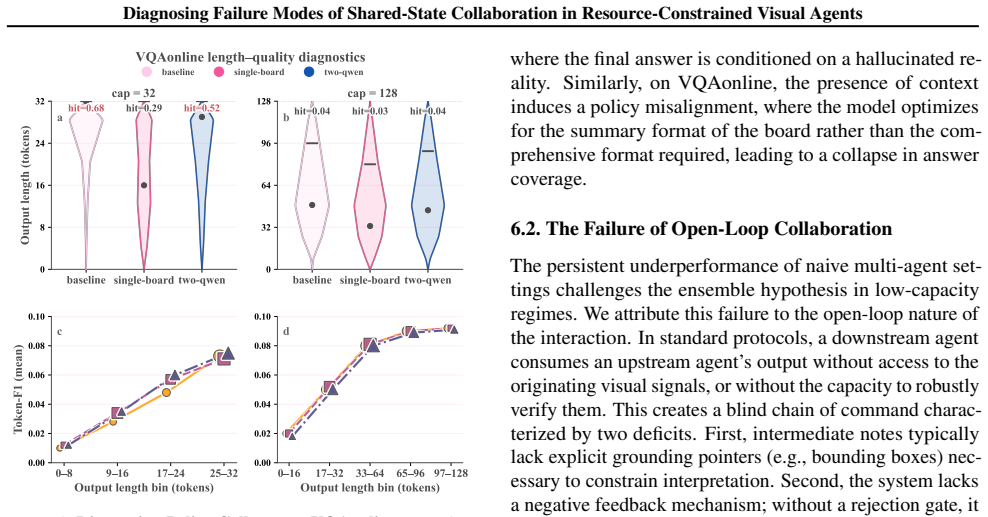
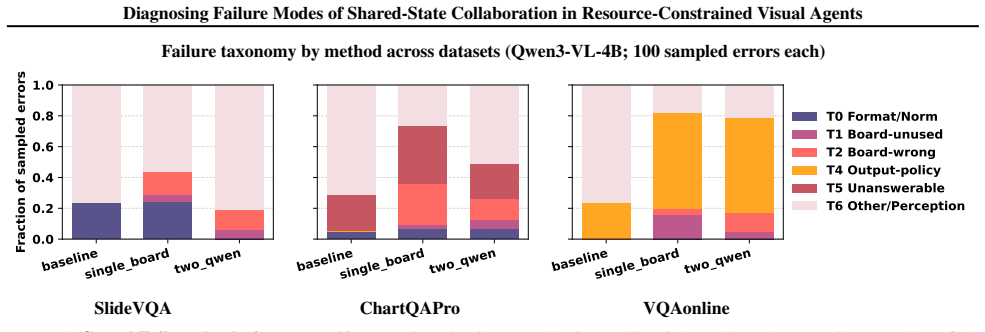
Modular visual reasoning systems with weak learners rely on shared working memory, but this leads to noise accumulation where ungrounded notes reinforce hallucinations and added context causes policy collapse to short-form answers. The CoSee framework audits the read-write-verify loop to trace failures across benchmarks, showing that increased compute without verification can degrade performance and that the bottleneck is communication fidelity.
What carries the argument
The CoSee auditing framework, which formalizes the read-write-verify loop to trace information flow in collaborative visual reasoning.
If this is right
- Ungrounded notes in shared workspaces get reused as evidence, amplifying hallucinations.
- Added context from sharing shifts models toward under-specified, short-form answers.
- Increased compute can correlate negatively with performance without explicit verification.
- The primary bottleneck for resource-constrained agents is communication fidelity rather than reasoning depth.
- Trace-level diagnostics from the auditing method provide a baseline for reliable modular design.
Where Pith is reading between the lines
- Verification steps should be prioritized when designing shared memory for multi-agent visual systems.
- The identified failure modes may appear in other collaborative setups beyond visual agents.
- Adding explicit checks could reverse the negative correlation between compute and performance.
- Testing the framework on larger models would show if the issues persist or change.
Load-bearing premise
The introduced CoSee auditing framework and its read-write-verify loop faithfully capture the actual information flow and failure dynamics without introducing its own artifacts or selection effects in the multi-page, chart, and web benchmarks.
What would settle it
Applying the CoSee framework to a new set of multi-page and chart benchmarks and observing neither noise reinforcement nor policy collapse under naive sharing.
Figures


read the original abstract
Modular visual reasoning systems increasingly rely on shared working memory for multi-step collaboration, yet the failure dynamics of intermediate state evolution in low-capacity regimes remain underexplored. We study failure modes of collaborative reasoning with weak learners (4B--8B models) through the lens of noise accumulation. We introduce CoSee, an auditing framework that formalizes the read-write-verify loop to trace information flow in document visual question answering. Across multi-page, chart, and web-based benchmarks, we find a counter-intuitive degradation: naive shared workspaces often amplify hallucinations rather than resolve them. We identify two dominant failure modes: Noise Reinforcement, where ungrounded notes are reused as evidence, and Policy Collapse, where added context shifts the model toward under-specified, short-form answers. Using cost-accuracy Pareto frontiers, we show that increased compute can correlate negatively with performance without explicit verification. Our findings suggest that for resource-constrained agents, the bottleneck lies not in reasoning depth but in communication fidelity, providing trace-level diagnostics and a mechanistic baseline for reliable modular design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoSee, a read-write-verify auditing framework, to trace information flow and diagnose failure modes in shared-state collaboration among weak visual agents (4B-8B models) on multi-page, chart, and web VQA benchmarks. It claims that naive shared workspaces amplify hallucinations rather than mitigate them, identifying two dominant modes—Noise Reinforcement (ungrounded notes reused as evidence) and Policy Collapse (added context driving under-specified short-form answers)—and shows via cost-accuracy Pareto frontiers that increased compute can correlate negatively with performance absent explicit verification, concluding that the bottleneck is communication fidelity rather than reasoning depth.
Significance. If the empirical claims hold after controls for framework artifacts, the work supplies useful trace-level diagnostics and a mechanistic baseline for modular agent design in resource-constrained regimes, underscoring that collaboration can degrade rather than improve performance when state is shared naively. The provision of explicit failure-mode identification and Pareto analysis is a constructive contribution to the literature on reliable multi-agent visual reasoning.
major comments (2)
- [§3] §3 (CoSee framework definition): The read-write-verify loop adds an explicit verification step and auditing structure on top of the shared workspace. This machinery could alter context length, prompting style, or note retention relative to a purely naive shared state, creating the risk that Noise Reinforcement and Policy Collapse are partly framework-induced rather than intrinsic properties of naive collaboration. An ablation that isolates the verify component (or compares unmodified shared state against CoSee) is needed to support the central attribution.
- [§5] §5 (Pareto frontier results and benchmark comparisons): The claim that increased compute correlates negatively with performance without verification rests on how the frontiers are constructed and how "naive" baselines are implemented versus CoSee-augmented runs. Without reported controls for selection effects, context overhead, or data exclusion rules in the multi-page/chart/web suites, it is difficult to separate the reported degradation from artifacts of the auditing loop itself.
minor comments (2)
- [§3.1] Notation for the read/write/verify primitives is introduced without a compact summary table; a small table listing the exact prompt templates and state-update rules would improve reproducibility.
- [§5.3] Figure captions for the Pareto plots should explicitly state whether error bars reflect multiple random seeds or only single-run variability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the attribution of the reported failure modes.
read point-by-point responses
-
Referee: [§3] §3 (CoSee framework definition): The read-write-verify loop adds an explicit verification step and auditing structure on top of the shared workspace. This machinery could alter context length, prompting style, or note retention relative to a purely naive shared state, creating the risk that Noise Reinforcement and Policy Collapse are partly framework-induced rather than intrinsic properties of naive collaboration. An ablation that isolates the verify component (or compares unmodified shared state against CoSee) is needed to support the central attribution.
Authors: We agree that isolating the verification step is important for attribution. Our naive baselines are already implemented without the read-write-verify loop. In the revision we will add an explicit ablation that runs the same shared-state protocol with and without the verify component, reporting any differences in note retention, context length, and observed failure rates. revision: yes
-
Referee: [§5] §5 (Pareto frontier results and benchmark comparisons): The claim that increased compute correlates negatively with performance without verification rests on how the frontiers are constructed and how "naive" baselines are implemented versus CoSee-augmented runs. Without reported controls for selection effects, context overhead, or data exclusion rules in the multi-page/chart/web suites, it is difficult to separate the reported degradation from artifacts of the auditing loop itself.
Authors: We acknowledge the need for explicit controls. The revised manuscript will include (i) measured context overhead for each condition, (ii) the precise selection and exclusion rules applied to the multi-page, chart, and web suites, and (iii) additional Pareto curves that hold context length and data subsets fixed across naive and CoSee conditions. revision: yes
Circularity Check
No significant circularity; empirical diagnostic framework with no derivations or self-referential fitting
full rationale
The paper introduces the CoSee auditing framework as a new contribution and reports empirical observations of failure modes (Noise Reinforcement, Policy Collapse) across benchmarks. No equations, parameter fitting, uniqueness theorems, or derivation chains appear in the abstract or described content. Claims rest on experimental traces rather than reducing to self-defined inputs or prior self-citations. The framework is presented as an external auditing tool, not derived from the results it measures, making the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https: //aclanthology.org/2025.acl-long.291/
doi: 10.18653/v1/2025.acl-long.291. URL https: //aclanthology.org/2025.acl-long.291/. Jain, C., Wu, Y ., Zeng, Y ., Liu, J., hengyu Dai, S., Shao, Z., Wu, Q., and Wang, H. Simpledoc: Multi- modal document understanding with dual-cue page re- trieval and iterative refinement.ArXiv, abs/2506.14035,
-
[2]
copy” case: P(Zu =Z v = 1) =p . Under the “independent
URL https://api.semanticscholar. org/CorpusID:279410653. Jiang, B., Zhuang, Z., Shivakumar, S. S., Roth, D., and Tay- lor, C. J. Multi-agent vqa: Exploring multi-agent founda- tion models in zero-shot visual question answering, 2024. URLhttps://arxiv.org/abs/2403.14783. Kim, G., Hong, T., Yim, M., Nam, J., Park, J., Yim, J., Hwang, W., Yun, S., Han, D., a...
-
[3]
SQuAD: 100, 000+ Questions for Machine Comprehension of Text , booktitle =
URL https://proceedings.mlr.press/ v260/nguyen25c.html. Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. SQuAD: 100,000+ questions for machine comprehension of text. In Su, J., Duh, K., and Carreras, X. (eds.),Proceed- ings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 2383–2392, Austin, Texas, November 2016. Associat...
-
[4]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
URL https://aclanthology.org/2025. emnlp-main.893/. Wang, D., Raman, N., Sibue, M., Ma, Z., Babkin, P., Kaur, S., Pei, Y ., Nourbakhsh, A., and Liu, X. DocLLM: A layout-aware generative language model for multimodal document understanding. In Ku, L.-W., Martins, A., and Srikumar, V . (eds.),Proceedings of the 62nd Annual Meet- ing of the Association for C...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.463 2025
-
[5]
URL https://api.semanticscholar. org/CorpusID:247595263. Wang, Z., Wan, W., Lao, Q., Chen, R., Lang, M., Wang, X., Wang, K., and Lin, L. Towards top-down reasoning: An explainable multi-agent approach for visual question answering, 2025. URL https://arxiv.org/abs/ 2311.17331. Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E. H., L...
-
[6]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
URL https://aclanthology.org/2021. acl-long.201/. Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y ., and Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models, 2023. URL https://arxiv.org/abs/2305.10601. Yi, Z., Liu, J., Xiao, T., and Albert, M. V . A multi-agent system for complex reasoning in radiology v...
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.