The Latin Substrate: How Language Models Represent and Mediate Script Choice
Pith reviewed 2026-06-28 22:36 UTC · model grok-4.3
The pith
Language models organize script variation around shared latent representations but treat Latin as a privileged substrate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
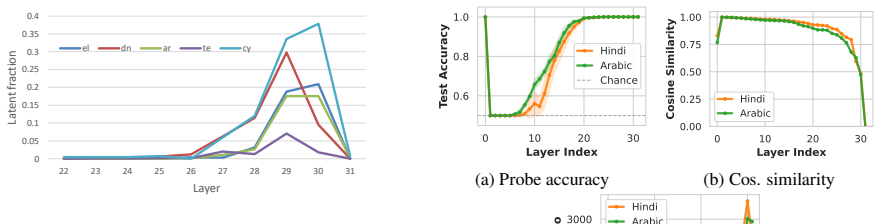
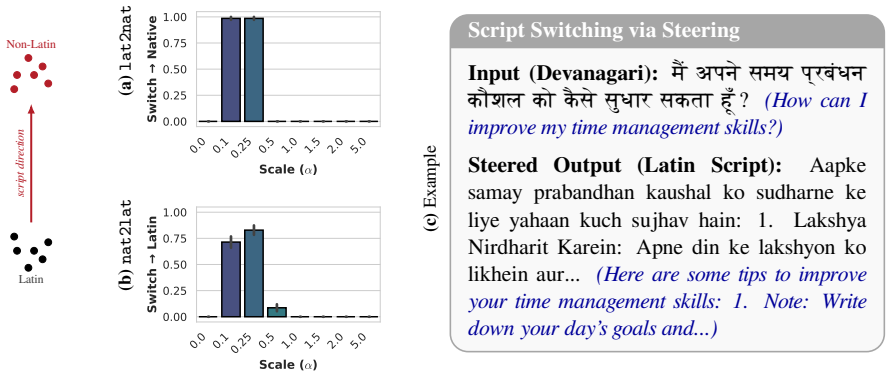
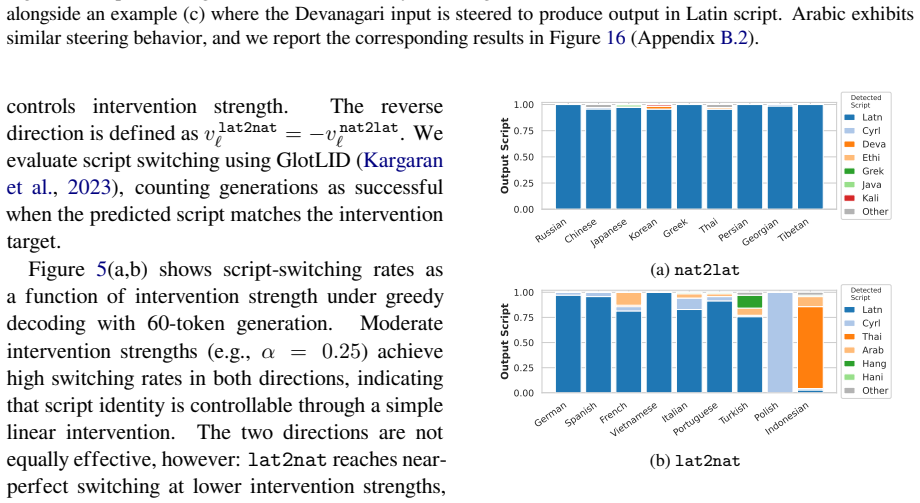
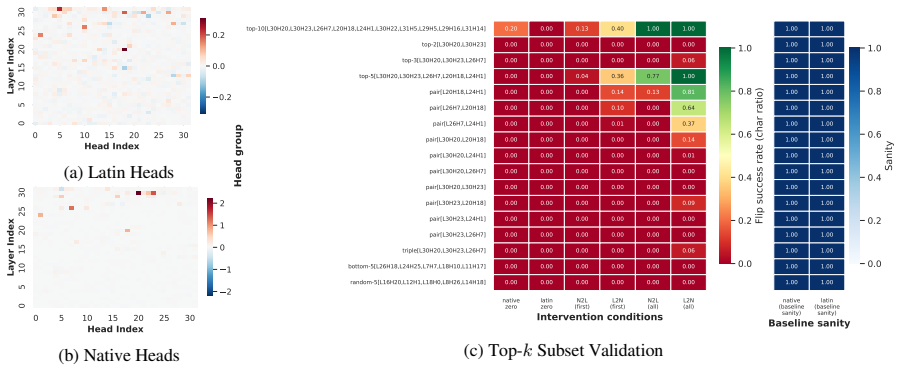
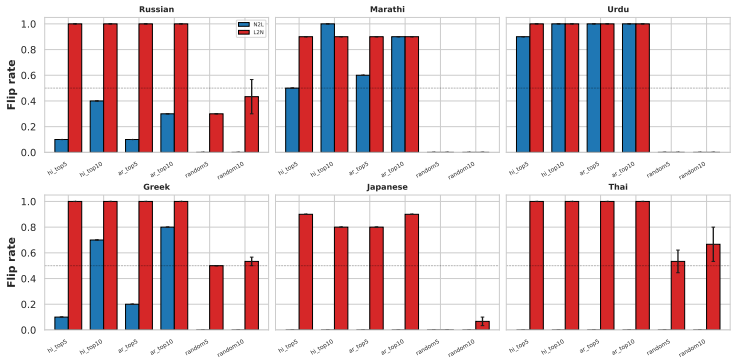
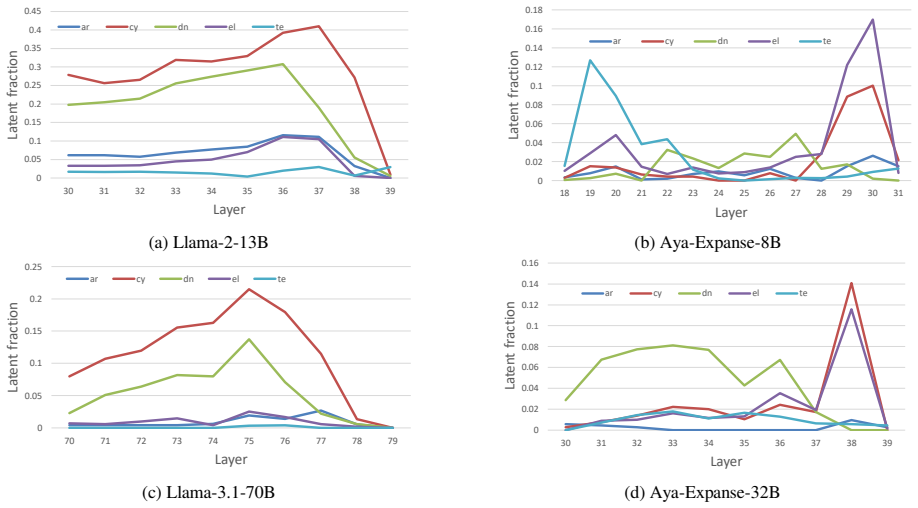
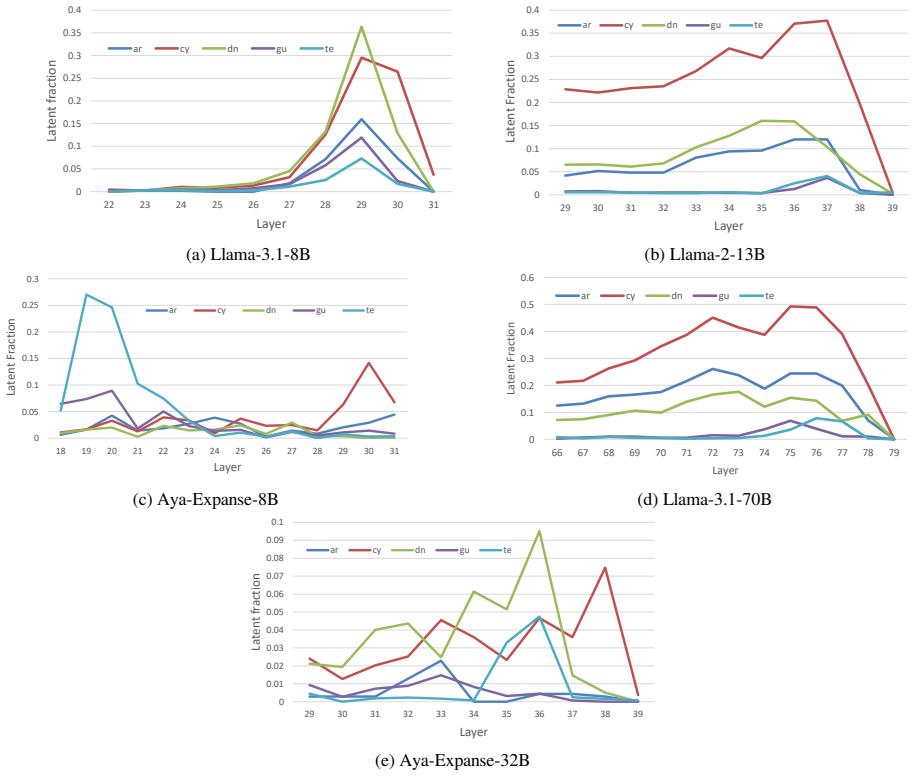
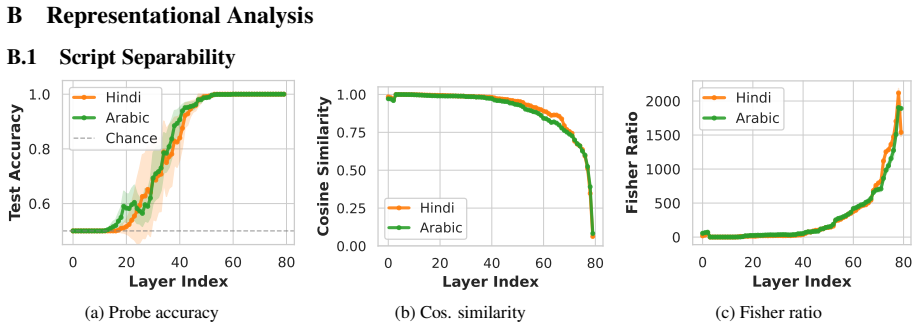
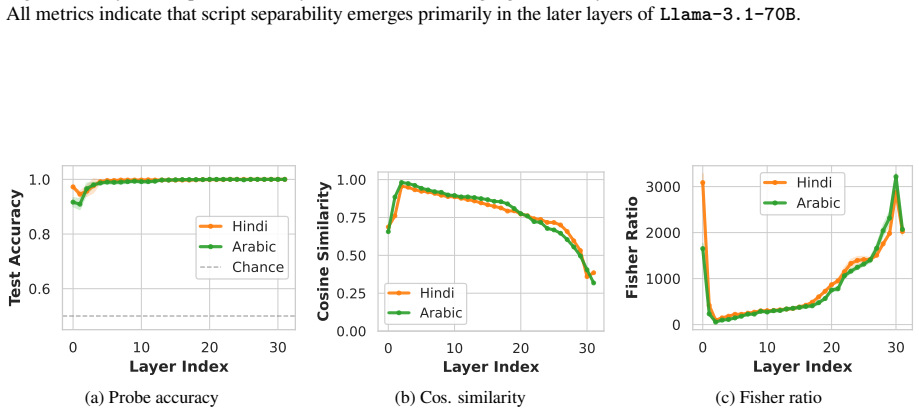
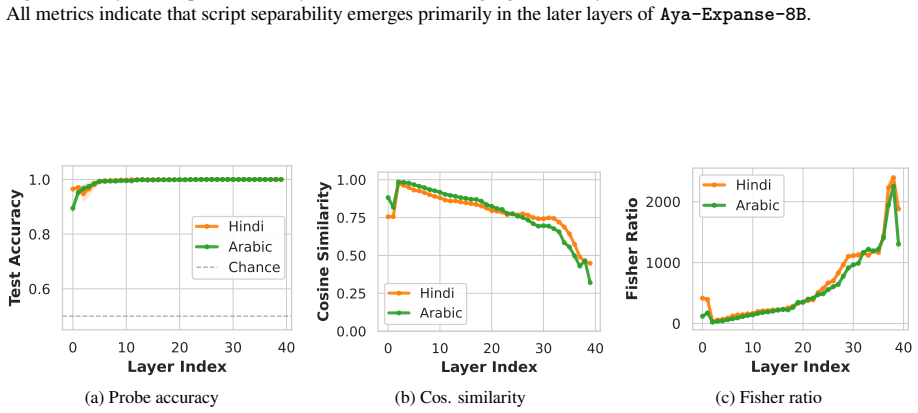
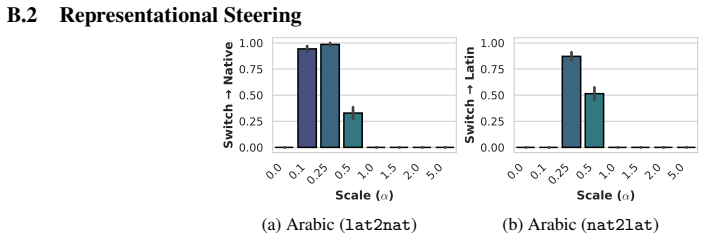
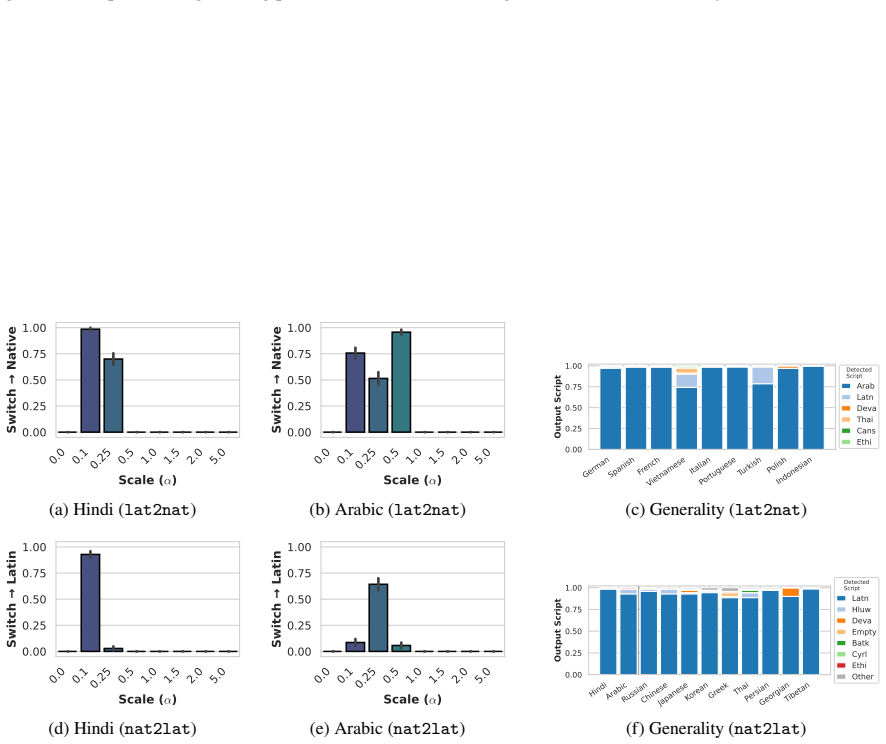
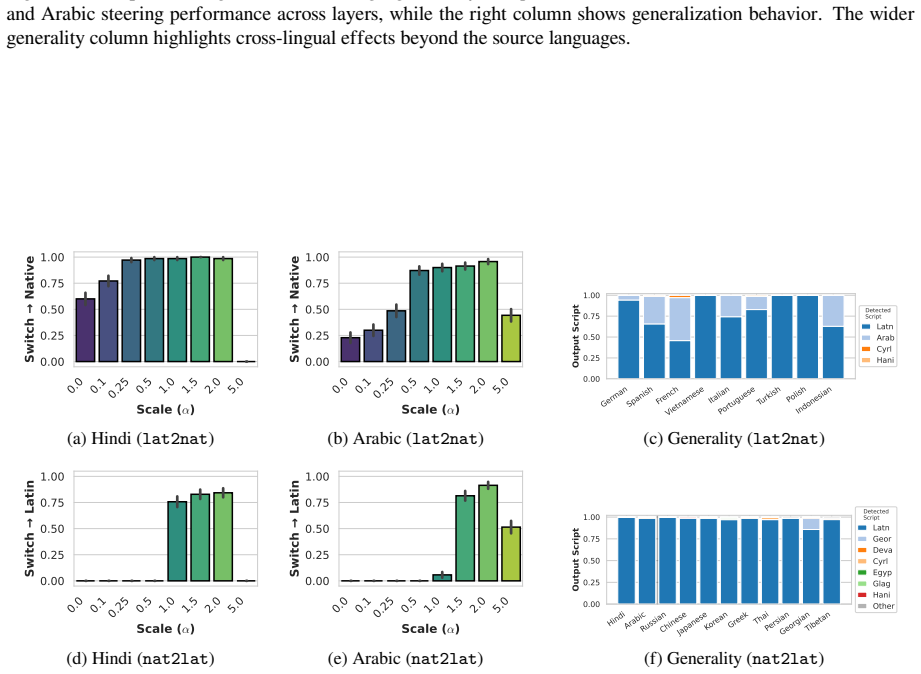
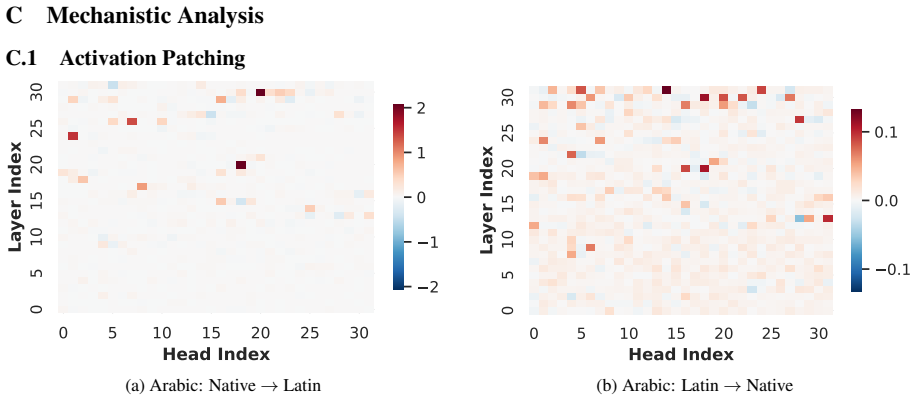
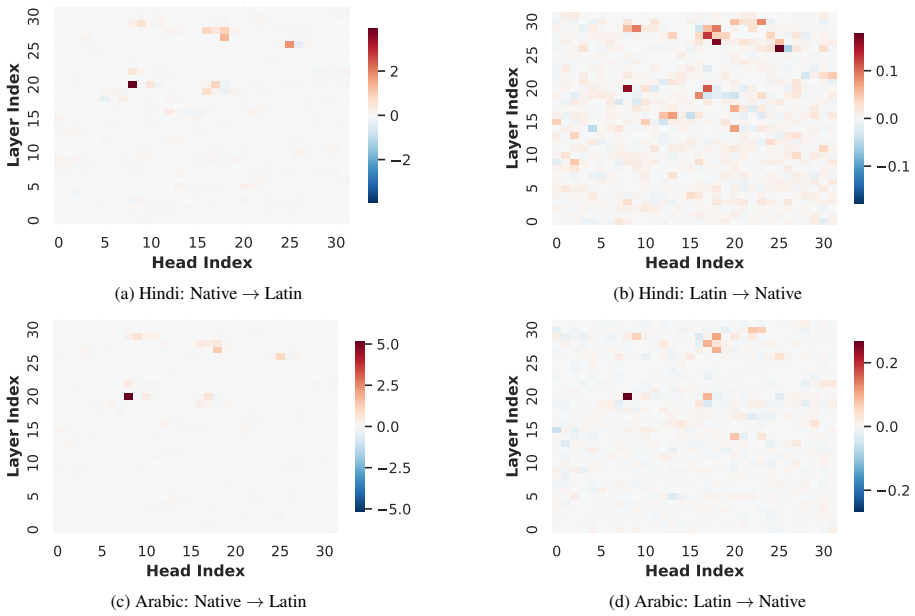
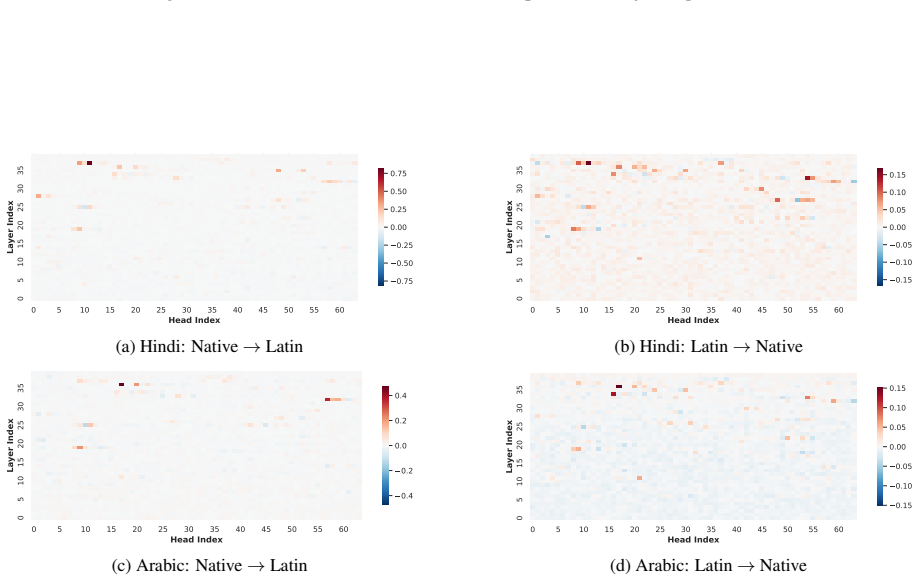
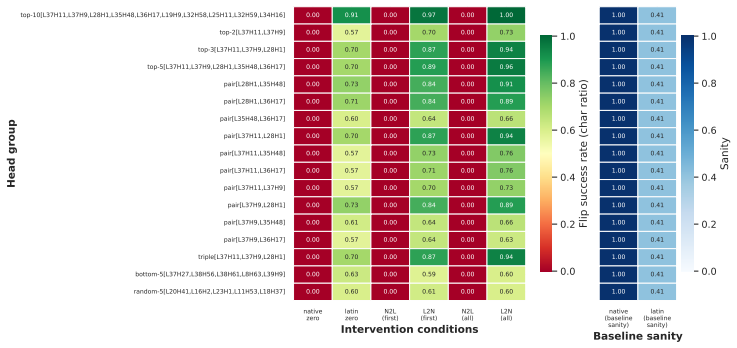
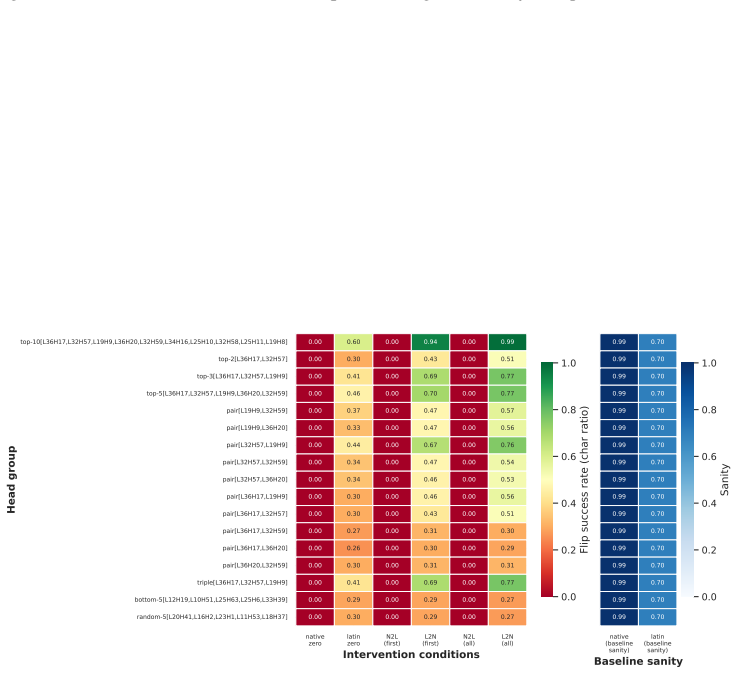
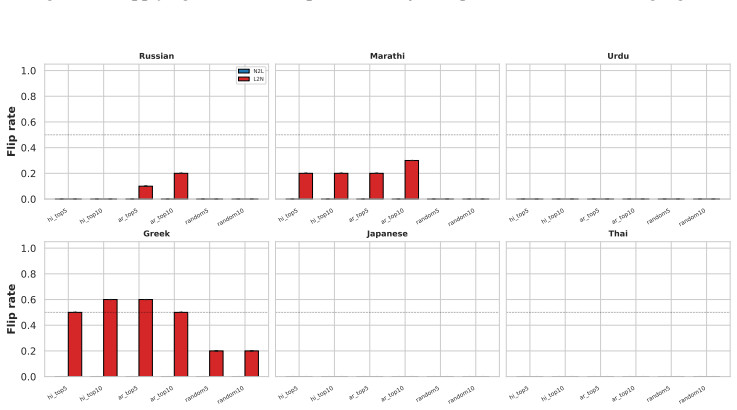
The authors argue that LLMs maintain shared latent representations for equivalent content across scripts, as shown by consistent romanization in intermediate layers. They demonstrate that script separability increases with depth, that a single linear direction can flip scripts asymmetrically, and that script choice is causally mediated by a small number of late-layer attention heads that generalize across languages. This leads to the conclusion that non-Latin scripts are produced via a compact identifiable gate while Latin script arises from diffuse contributions, indicating a privileged Latin substrate.
What carries the argument
Linear steering vectors that flip script output while preserving semantics, together with late-layer attention heads that causally mediate script choice across languages.
If this is right
- Scripts of the same language become increasingly separable across successive layers.
- A single linear direction in activation space can change output script while largely retaining semantic content.
- The steering vector generalizes asymmetrically, converting non-Latin reliably to Latin but Latin to varied non-Latin scripts.
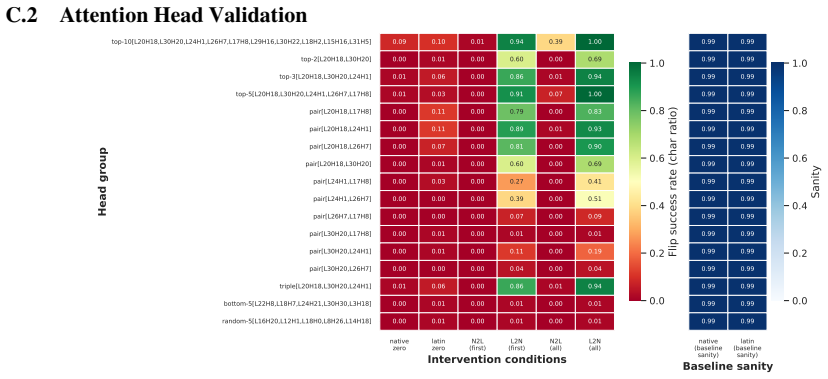
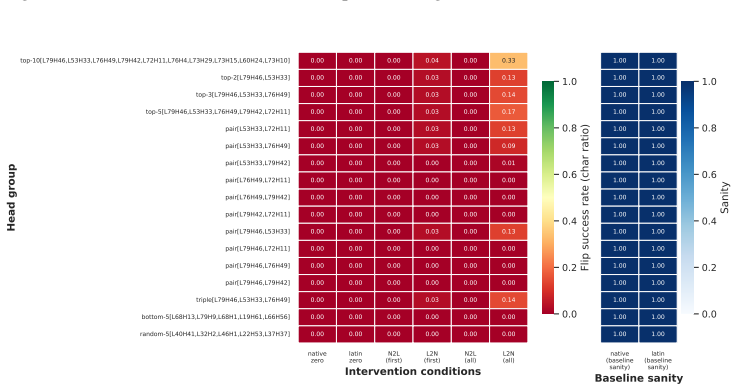
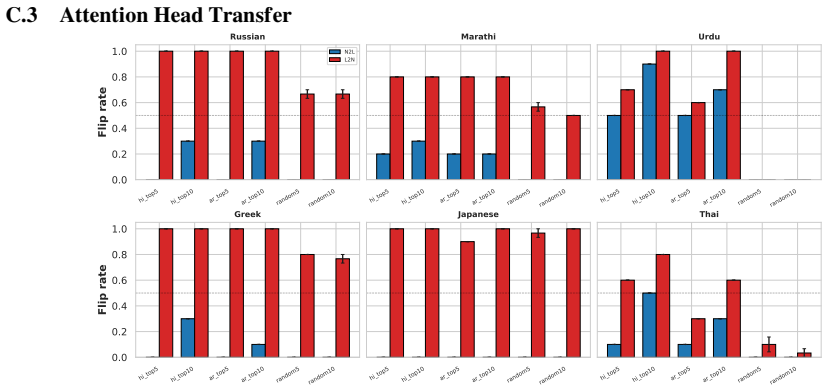
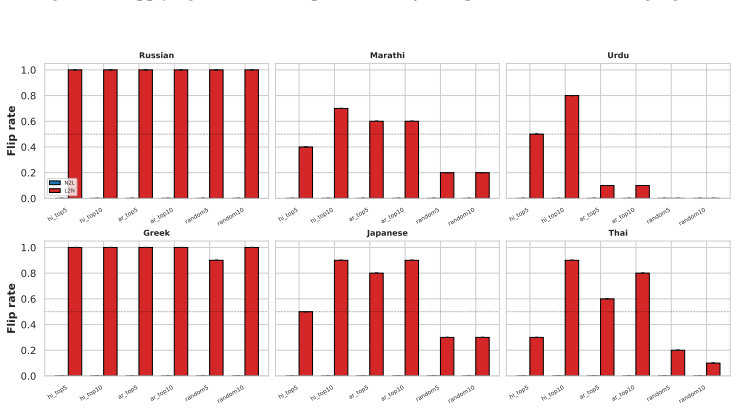
- A small set of late-layer attention heads implement script routing and transfer across unrelated languages.
- Non-Latin output depends on a compact gate while Latin output draws from diffuse contributions across the network.
Where Pith is reading between the lines
- The directional asymmetry may reflect training data distributions that make Latin the default internal pathway.
- Targeting the identified attention heads could provide a route to improve generation quality for non-Latin scripts.
- Similar compact versus diffuse routing patterns may appear in other output variations such as formality level or dialect.
- The results imply that script choice is one instance of a broader class of language-agnostic routing mechanisms in these models.
Load-bearing premise
The logit lens, linear steering vectors, and attention head interventions reveal causal mechanisms for script choice rather than correlational artifacts.
What would settle it
If deactivating the localized late-layer attention heads fails to block non-Latin script generation on held-out languages and writing systems, the claim of causal mediation would not hold.
Figures








read the original abstract
Many languages are written in multiple scripts, requiring large language models (LLMs) to generate equivalent linguistic content in distinct orthographic forms. While prior work suggests that LLMs route information through shared latent representations, how they internally mediate script variation remains poorly understood. We study this question by first examining per-layer output distributions with the logit lens, which reveals consistent latent romanization during transliteration, and then through representational and mechanistic analyses of script generation. At the representational level, we show that scripts of the same language become increasingly separable across layers and that a simple linear steering direction can flip a model's output script while largely maintaining semantic content. The vector generalizes asymmetrically to writing systems unseen during construction, flipping non-Latin output to Latin reliably, but mapping Latin output into varied non-Latin scripts. At the mechanistic level, we localize a small set of late-layer attention heads that causally mediate script choice. These heads transfer across unrelated languages and writing systems, suggesting that script routing is implemented by language-agnostic components. Across both analyses, we observe a consistent directional asymmetry: non-Latin output is produced by a compact, identifiable gate, while Latin-script output emerges from diffuse contributions across the network. Collectively, our findings hint that LLMs organize script variation around shared latent representations while exhibiting a privileged substrate toward Latin script.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates how large language models internally represent and mediate script choice for languages written in multiple scripts. Logit lens analysis reveals consistent latent romanization during transliteration. Representational analyses show scripts of the same language becoming increasingly separable across layers, with a linear steering vector able to flip output script while preserving semantics; this vector generalizes asymmetrically, reliably mapping non-Latin to Latin but producing varied results in the reverse direction. Mechanistic interventions localize script choice to a small set of late-layer attention heads that transfer across unrelated languages and writing systems. The authors conclude that LLMs organize script variation around shared latent representations while exhibiting a privileged substrate toward Latin script.
Significance. If the empirical patterns hold under further scrutiny, the manuscript contributes to mechanistic interpretability of multilingual LLMs by combining logit lens, linear steering, and causal head interventions to identify shared representations and language-agnostic routing components. The asymmetric generalization and cross-lingual head transfer provide concrete, falsifiable observations that could guide future work on script bias and model editing. The multi-method approach is a strength when the tools are applied with appropriate controls.
major comments (2)
- [Abstract and Representational Analysis] Abstract and Representational Analysis section: The central claim of a 'privileged substrate toward Latin script' rests on the observed asymmetry in steering vector behavior (non-Latin to Latin reliable and compact; Latin to non-Latin diffuse and variable). This pattern is also consistent with well-documented Latin-script dominance in pretraining data. The manuscript does not report controls that apply the identical logit lens, difference-vector, and ablation methods to other high- vs. low-frequency token classes, which would be required to distinguish an architectural bias from a data-frequency effect. This distinction is load-bearing for the substrate interpretation.
- [Mechanistic Analysis] Mechanistic Analysis section: The claim that a small set of late-layer attention heads 'causally mediate script choice' and transfer across languages is used to support language-agnostic routing. The abstract provides no quantitative details on intervention effect sizes (e.g., change in script probability relative to random-head or layer-matched baselines), making it impossible to evaluate whether these heads specifically implement the reported substrate asymmetry or reflect more general generation mechanisms.
minor comments (2)
- [Abstract] Abstract: The final sentence uses appropriately cautious language ('hint that'), but the manuscript should explicitly list the limitations of logit lens and linear interventions when applied to script choice.
- [Figures and tables] Figures and tables: Ensure all quantitative claims about consistency across layers or languages include error bars, sample sizes, and statistical tests so readers can assess the reliability of the reported patterns.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. The comments highlight important considerations for interpreting our results on script representation and routing in LLMs. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and Representational Analysis] Abstract and Representational Analysis section: The central claim of a 'privileged substrate toward Latin script' rests on the observed asymmetry in steering vector behavior (non-Latin to Latin reliable and compact; Latin to non-Latin diffuse and variable). This pattern is also consistent with well-documented Latin-script dominance in pretraining data. The manuscript does not report controls that apply the identical logit lens, difference-vector, and ablation methods to other high- vs. low-frequency token classes, which would be required to distinguish an architectural bias from a data-frequency effect. This distinction is load-bearing for the substrate interpretation.
Authors: We agree that the distinction between data-frequency effects and potential architectural biases is important for the strength of the 'privileged substrate' interpretation. Our core experiments hold linguistic content fixed while varying only script, which provides a within-language control for many token-frequency confounds. Nevertheless, the manuscript does not include the broader cross-class controls suggested. In revision we will add an explicit limitations paragraph discussing this alternative explanation and its implications for the substrate claim, while preserving the original analyses as evidence specific to script variation. revision: partial
-
Referee: [Mechanistic Analysis] Mechanistic Analysis section: The claim that a small set of late-layer attention heads 'causally mediate script choice' and transfer across languages is used to support language-agnostic routing. The abstract provides no quantitative details on intervention effect sizes (e.g., change in script probability relative to random-head or layer-matched baselines), making it impossible to evaluate whether these heads specifically implement the reported substrate asymmetry or reflect more general generation mechanisms.
Authors: Quantitative intervention results, including effect sizes relative to random-head and layer-matched baselines, are reported in the Mechanistic Analysis section of the full manuscript. To improve accessibility we will revise the abstract to include concise quantitative summaries of the head-intervention effect sizes and their comparison to baselines. revision: yes
Circularity Check
No circularity; empirical interventions are self-contained
full rationale
The paper reports empirical observations obtained via logit lens, linear steering vectors, and attention-head ablations. No equations, parameter fits, or self-citations are presented that reduce the reported asymmetry or latent-romanization findings to the inputs by construction. The central claim is framed as an observed pattern from intervention experiments rather than a definitional or fitted tautology, satisfying the criteria for a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Findings of the Association for Computational Linguistics: ACL 2026
Clas-bench: A cross-lingual alignment and steering benchmark. Findings of the Association for Computational Linguistics: ACL 2026 . J Jaavid, Raj Dabre, M Aswanth, Jay Gala, Thanmay Jayakumar, Ratish Puduppully, and Anoop Kunchukuttan. 2024. Romansetu: Efficiently unlocking multilingual capabilities of large language models via romanization. In Proceeding...
2026
-
[2]
Scripts Through Time: A Survey of the Evolving Role of Transliteration in NLP
Scripts through time: A survey of the evolving role of transliteration in nlp . Preprint, arXiv:2604.18722. Melvin Johnson, Mike Schuster, Quoc Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda Viégas, Martin Wattenberg, Greg Corrado, and 1 others. 2017. Google’s multilingual neural machine translation system: Enabling zero-shot transla...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
The Linear Representation Hypothesis and the Geometry of Large Language Models
The linear representation hypothesis and the geometry of large language models . Preprint, arXiv:2311.03658. Telmo Pires, Eva Schlinger, and Dan Garrette
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Sukannya Purkayastha, Sebastian Ruder, Jonas Pfeiffer, Iryna Gurevych, and Ivan Vuli ć
How multilingual is multilingual bert? In Proceedings of the 57th annual meeting of the association for computational linguistics , pages 4996–5001. Sukannya Purkayastha, Sebastian Ruder, Jonas Pfeiffer, Iryna Gurevych, and Ivan Vuli ć. 2023. Romanization-based large-scale adaptation of multilingual language models . In Findings of the Association for Co...
2023
-
[5]
Brain and language, 124(3):205–212
‘cost in transliteration’: The neurocognitive processing of romanized writing. Brain and language, 124(3):205–212. Kathleen Rastle and Marc Brysbaert. 2006. Masked phonological priming effects in english: Are they real? do they matter? Cognitive Psychology , 53(2):97–145. Alan Saji, Jaavid Aktar Husain, Thanmay Jayakumar, Raj Dabre, Anoop Kunchukuttan, an...
-
[6]
Qwen3 technical report. arXiv preprint arXiv:2505.09388. Jun Zhao, Zhihao Zhang, Luhui Gao, Qi Zhang, Tao Gui, and Xuanjing Huang. 2024. Llama beyond english: An empirical study on language capability transfer. arXiv preprint arXiv:2401.01055. Chengzhi Zhong, Fei Cheng, Qianying Liu, Junfeng Jiang, Zhen Wan, Chenhui Chu, Yugo Murawaki, and Sadao Kurohashi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Latent romanization condition: r(i) l,t = 1, if max r∈R P (xt = r | l, t) > 0.1 0, otherwise
-
[8]
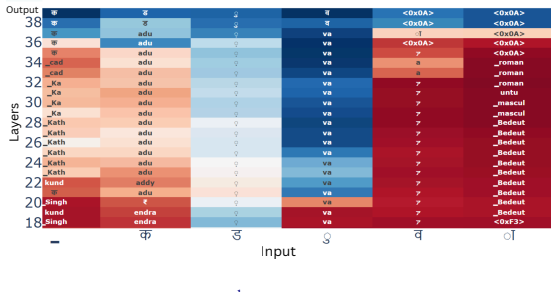
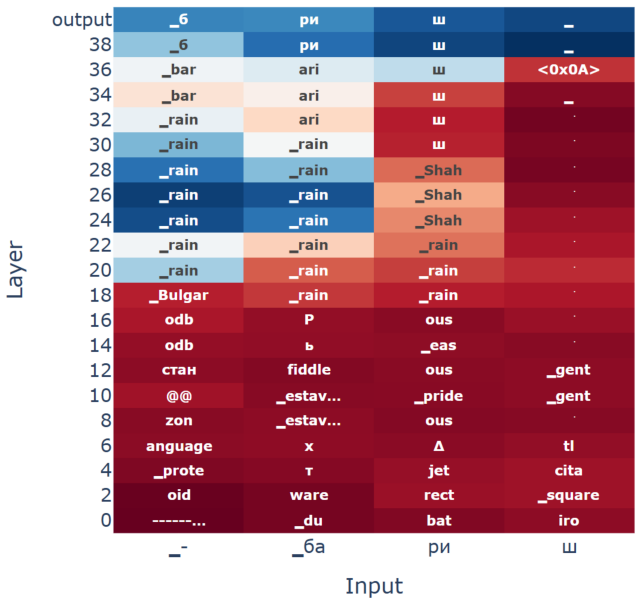
rain” from Devanagari to Cyrillic. The plot shows the next-token distribution at each position (x-axis) across layers (y-axis), with the final output (бариш, “barish
Latent fraction for a layer ℓ: L.F(l) = 1 N N∑ i=1 1 T T∑ t=1 r(i) l,t where N is the number of samples, T is the number of generation timesteps and P (xt = r|l, t) is the probability of generating token r at timestep t and layer ℓ. A.4 Additional Results Figure 12 depicts qualitative logit lens analysis for transliteration of the Hindi word for ‘rain" fr...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.