Unlocking Fine-Grained Translation Quality Estimation in LRMs through Synergistically Evolving Implicit and Explicit Reasoning
Pith reviewed 2026-06-28 22:33 UTC · model grok-4.3
The pith
A two-stage training method allows large reasoning models to improve implicit and explicit reasoning together for better fine-grained translation quality estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that by first decomposing the complex QE task into straightforward subtasks and then applying NonThinking-SFT to boost implicit reasoning followed by Thinking-RLVR to strengthen explicit reasoning, the two reasoning capabilities synergistically co-evolve, enabling LRMs to achieve superior performance on fine-grained translation quality estimation.
What carries the argument
The RIEQE two-stage training framework that applies task decomposition followed by NonThinking-SFT and then Thinking-RLVR to enable co-evolution of implicit and explicit reasoning.
If this is right
- On the WMT test sets, RIEQE based on Qwen3-4B-Thinking-2507 surpasses all baselines in explicit reasoning performance.
- Its implicit reasoning capability is comparable to the best current encoder-based models.
- Implicit and explicit reasoning synergistically co-evolve under the framework.
- The two reasoning types mutually benefit each other through synergistic collaboration.
Where Pith is reading between the lines
- This approach could be tested on other fine-grained NLP tasks to see if similar co-evolution occurs.
- Models might achieve better efficiency by relying more on the implicit reasoning developed in the first stage.
- Future work could explore whether the decomposition into subtasks is essential or if other methods can trigger the co-evolution.
Load-bearing premise
The core challenge in fine-grained quality estimation is the intrinsic difficulty of learning the task rather than insufficient multilingual capabilities in the base models.
What would settle it
An experiment where the model is trained only with the second-stage RLVR without the first-stage SFT or task decomposition, and it still achieves the same performance gains, would falsify the necessity of the synergistic co-evolution process.
Figures









read the original abstract
Large Reasoning Models (LRMs) still struggle with fine-grained translation quality estimation (QE), even with long reasoning chains. We argue that LRMs already possess strong multilingual capabilities, while the core challenge stems from the intrinsic difficulty of learning the fine-grained QE task. In this paper, we propose RIEQE (Reasoning both Implicitly and Explicitly for QE), a simple two-stage training framework that enables the co-evolution of implicit (layer-wise) and explicit (token-wise) reasoning capabilities. To make implicit reasoning feasible, we first decompose the complex QE task into straightforward subtasks. Based on this, our two-stage approach applies: (1) NonThinking-SFT, Supervised Fine-Tuning (SFT) without reasoning chains to directly boost the model's implicit reasoning tendency and capability; and (2) Thinking-RLVR, standard Reinforcement Learning with Verifiable Reward (RLVR) to subsequently strengthen explicit reasoning. Results demonstrate that implicit and explicit reasoning synergistically co-evolve under our framework. On the WMT test sets, RIEQE based on Qwen3-4B-Thinking-2507 surpasses all baselines in explicit reasoning performance, while its implicit reasoning capability is also comparable to the best current encoder-based models. We further provide evidence for the synergistic collaboration between implicit and explicit reasoning, showing how they mutually benefit each other.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RIEQE, a two-stage training framework for large reasoning models (LRMs) on fine-grained translation quality estimation (QE). It decomposes the QE task into subtasks, applies NonThinking-SFT to enhance implicit (layer-wise) reasoning, then Thinking-RLVR to strengthen explicit (token-wise) reasoning, claiming that implicit and explicit reasoning synergistically co-evolve. On WMT test sets, the resulting model based on Qwen3-4B-Thinking-2507 outperforms baselines in explicit reasoning and matches top encoder-based models in implicit reasoning.
Significance. If the reported gains prove robust under statistical testing and ablations, the work would offer a practical recipe for unlocking task-specific reasoning in LRMs for QE without assuming multilingual deficits, and the evidence of mutual benefit between implicit and explicit modes could inform broader LRM training strategies. The two-stage decomposition itself is a concrete, implementable contribution.
major comments (3)
- [Abstract, §4] Abstract and §4 (results): performance claims on WMT are stated without error bars, dataset sizes, number of runs, or statistical significance tests, so the assertion that RIEQE 'surpasses all baselines' and that implicit/explicit reasoning 'synergistically co-evolve' cannot be evaluated for reliability.
- [§3.1, §5] §3.1 and §5 (premise and experiments): the core premise that 'LRMs already possess strong multilingual capabilities' and that QE difficulty is purely task-intrinsic is load-bearing for the two-stage method, yet all results use only Qwen3-4B-Thinking-2507; no ablation applies RIEQE to a weaker multilingual base model or degrades cross-lingual alignment while holding the decomposition fixed.
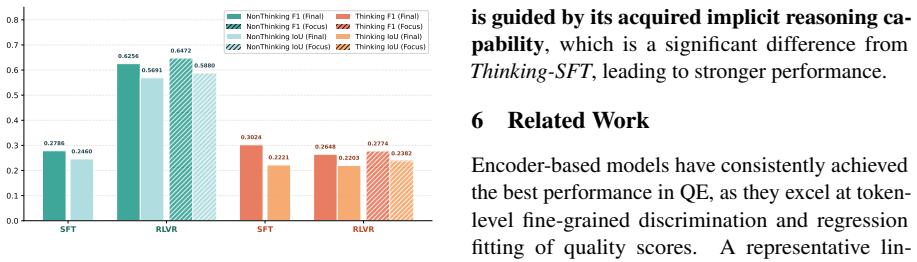
- [§4.2] §4.2 (ablation table): the synergistic co-evolution claim rests on comparisons between NonThinking-SFT and Thinking-RLVR stages, but the manuscript provides no quantitative measure (e.g., mutual information or staged performance deltas) showing that the second stage improves the implicit capability acquired in the first stage beyond what either stage achieves alone.
minor comments (2)
- [§2] Notation for implicit vs. explicit reasoning is introduced in §2 but used inconsistently in later sections; a single glossary or equation defining the two quantities would improve clarity.
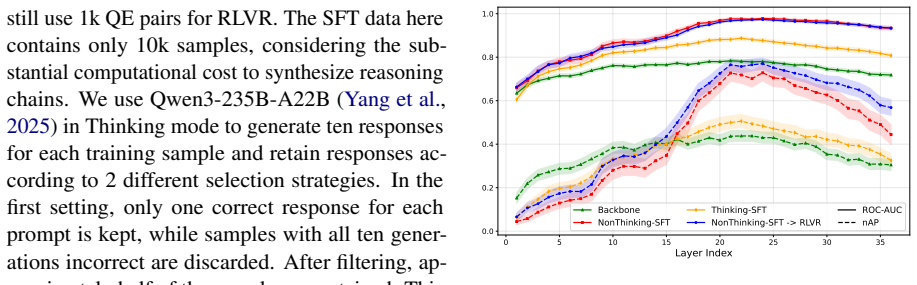
- [Figure 3] Figure 3 (co-evolution curves) lacks axis labels for the implicit-reasoning metric and does not indicate whether shaded regions represent standard deviation or min/max across seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical rigor, generalizability of the premise, and evidence for synergy. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (results): performance claims on WMT are stated without error bars, dataset sizes, number of runs, or statistical significance tests, so the assertion that RIEQE 'surpasses all baselines' and that implicit/explicit reasoning 'synergistically co-evolve' cannot be evaluated for reliability.
Authors: We agree that the current presentation lacks sufficient statistical detail. In the revised manuscript we will report results averaged over multiple random seeds (with error bars), explicitly state the sizes of all training and test splits, and include statistical significance tests (e.g., paired t-tests against baselines) to support both the performance claims and the synergistic co-evolution statement. revision: yes
-
Referee: [§3.1, §5] §3.1 and §5 (premise and experiments): the core premise that 'LRMs already possess strong multilingual capabilities' and that QE difficulty is purely task-intrinsic is load-bearing for the two-stage method, yet all results use only Qwen3-4B-Thinking-2507; no ablation applies RIEQE to a weaker multilingual base model or degrades cross-lingual alignment while holding the decomposition fixed.
Authors: The manuscript deliberately selects Qwen3-4B-Thinking-2507 as a representative strong LRM to isolate the contribution of the two-stage framework on the QE task itself. While we acknowledge that additional experiments on weaker multilingual bases would strengthen the premise, such ablations are computationally prohibitive within the current study. We will revise §3.1 and §5 to cite prior literature supporting the multilingual capabilities of comparable LRMs and add an explicit limitations paragraph on generalizability. revision: partial
-
Referee: [§4.2] §4.2 (ablation table): the synergistic co-evolution claim rests on comparisons between NonThinking-SFT and Thinking-RLVR stages, but the manuscript provides no quantitative measure (e.g., mutual information or staged performance deltas) showing that the second stage improves the implicit capability acquired in the first stage beyond what either stage achieves alone.
Authors: We will augment §4.2 with explicit quantitative analyses, including per-stage performance deltas on both implicit and explicit metrics and correlation measures between the two reasoning modes across training stages. These additions will provide a clearer demonstration that the second stage further improves the implicit capability obtained after the first stage. revision: yes
Circularity Check
No circularity: empirical training procedure with independent results
full rationale
The paper presents RIEQE as a two-stage empirical training framework (NonThinking-SFT followed by Thinking-RLVR) applied to an existing LRM, with performance measured on WMT test sets. No mathematical derivation, equations, or first-principles claims reduce to fitted parameters or self-citations by construction. The central premise (multilingual capability already sufficient, task difficulty intrinsic) is stated as an argument rather than derived, and results are reported as direct experimental outcomes without renaming or self-referential forcing. The method is self-contained against external benchmarks and does not invoke load-bearing self-citations or uniqueness theorems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Implicit reasoning in transformers is reasoning through shortcuts. InFindings of the Association for Computational Linguistics: ACL 2025, pages 9470–9487, Vienna, Austria. Association for Compu- tational Linguistics. Jack Lindsey, Wes Gurnee, Emmanuel Ameisen, Brian Chen, Adam Pearce, Nicholas L. Turner, Craig Citro, David Abrahams, Shan Carter, Basil Hos...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Wenda Xu, Danqing Wang, Liangming Pan, Zhenqiao Song, Markus Freitag, William Wang, and Lei Li
Do language models plan ahead for future tokens? InFirst Conference on Language Modeling. Wenda Xu, Danqing Wang, Liangming Pan, Zhenqiao Song, Markus Freitag, William Wang, and Lei Li
-
[3]
INSTRUCTSCORE: Towards explainable text generation evaluation with automatic feedback. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5967–5994, Singapore. Association for Computa- tional Linguistics. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (V olume 3: System Demonstra- tions), Bangkok, Thailand
Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (V olume 3: System Demonstra- tions), Bangkok, Thailand. Association for Computa- tional Linguistics. Xiaolin Zhou, Zheng Luo, Yicheng Gao, Qixuan Chen, Xiyang Hu, Yue Zhao, and Ruishan Liu
-
[5]
Excl.” (self-exclusion, main protocol) and “Incl
Fairness or fluency? an investigation into language bias of pairwise llm-as-a-judge.Preprint, arXiv:2601.13649. 11 A Data Details We evaluate on the WMT 2023 test sets for zh- en, en-de, and en-mr, and the WMT 2022 test set for en-ru. We use the training data provided by WMT 2022 and 2023, ensuring no test data leakage. Table 5 summarizes the number of tr...
-
[8]
Unit1": [
**Language naturalness and style** — Is the expression idiomatic, fluent, and appropriate in register? For each semantic unit containing an error, identify the error span within its corresponding translation. - The ‘span‘ must be an **exact substring** from the target sentence. - The span should cover the **entire erroneous phrase** that conveys the incor...
-
[11]
errors": [
**Language naturalness and style** — Is the expression idiomatic, fluent, and appropriate in register? For each semantic unit containing an error, identify the error span within its corresponding translation. - The ‘span‘ must be an **exact substring** from the target sentence. - The span should cover the **entire erroneous phrase** that conveys the incor...
-
[12]
**Terminology consistency** — Are key terms translated consistently and correctly?
-
[13]
**Faithfulness / Accuracy** — Does the meaning match the source sentence precisely? - Detect any mistranslation, omission, or addition
-
[14]
errors": [ {
**Language naturalness and style** — Is the expression idiomatic, fluent, and appropriate in register? For each error, identify the error span within its corresponding translation. - The ‘span‘ must be an **exact substring** from the target sentence. - The span should cover the **entire erroneous phrase** that conveys the incorrect meaning, not just an in...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.