VisionPulse: Dynamic Visual Sparsity for Efficient Multimodal Reasoning
Pith reviewed 2026-06-28 23:11 UTC · model grok-4.3
The pith
VisionPulse prunes visual tokens to 5 percent per decoding step and shortens reasoning traces by 11.2 percent while holding accuracy steady.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
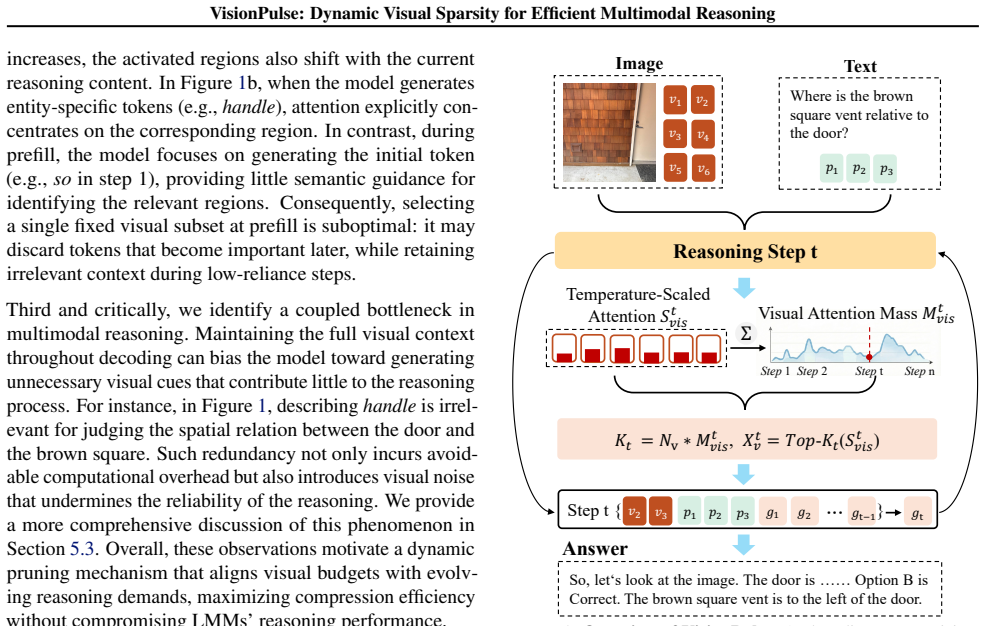
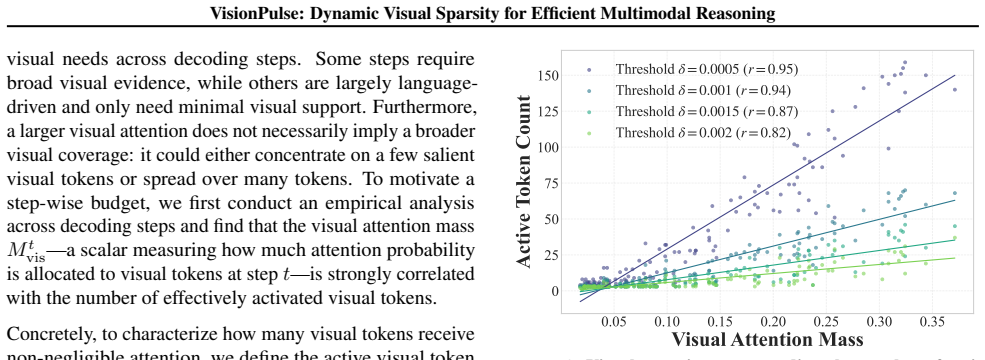
VisionPulse performs step-wise visual token pruning by first computing a visual attention mass that correlates strongly with the number of tokens the model actually uses at that decoding step, then retaining only the most critical tokens inside the resulting budget. Because visual evidence is step-dependent, this removes context that would otherwise steer reasoning off-track, naturally shortening traces while the retained tokens preserve the information needed for correct answers.
What carries the argument
Step-wise retention budget derived from visual attention mass, used to select the top critical tokens at each decoding step.
If this is right
- Only 5 percent of visual tokens need to be kept at each step to reach the same final answer.
- Reasoning traces become 11.2 percent shorter on average because redundant visual context is removed.
- Accuracy remains essentially unchanged across the tested multimodal benchmarks.
- The pruning operates without any model retraining or change to the underlying architecture.
Where Pith is reading between the lines
- The same attention-mass signal could be used to decide when to stop generating altogether rather than only how many tokens to keep.
- Extending the method to video or multi-image inputs would require checking whether the step-dependent pattern still holds across time or across multiple frames.
- If attention mass also correlates with token importance in text-only models, an analogous pruning rule might shorten long chain-of-thought traces.
Load-bearing premise
The amount of visual evidence actually needed changes strongly from one reasoning step to the next and attention mass reliably signals how many tokens matter at each step.
What would settle it
Run the same multimodal benchmark with and without VisionPulse on a task whose visual requirements shift rapidly across steps; a large accuracy drop or no shortening of traces would falsify the claim.
Figures







read the original abstract
With the rapid advancement of large multimodal models (LMMs), inference-time overhead has become a key bottleneck for real-world deployment. Existing methods typically prune visual tokens at prefill, assuming the required visual evidence remains static during reasoning. However, we empirically show that visual evidence is strongly step-dependent: only a sparse subset of visual tokens is critical at each decoding step, and the critical set evolves across reasoning. Furthermore, we identify a coupled bottleneck where redundant visual context can steer the model toward query-irrelevant regions, lengthening the reasoning trace. Guided by these insights, we propose VisionPulse, a step-wise visual token pruning framework during reasoning. VisionPulse computes a lightweight visual attention mass to estimate the step-wise retention budget by exploiting its strong positive correlation with LMMs' effective visual token usage and retain only the most critical tokens under this budget. By enforcing visual sparsity during reasoning, VisionPulse filters redundant visual context while preserving relevant visual evidence, shortening reasoning traces naturally. Extensive experiments show that VisionPulse only retains 5% of visual tokens per step with reasoning traces shortened by 11.2%, while keeping accuracy almost unchanged.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VisionPulse, a dynamic visual token pruning framework for large multimodal models (LMMs) during the reasoning phase. It claims that visual evidence is strongly step-dependent rather than static, identifies a coupled bottleneck where redundant visual context lengthens reasoning traces, and introduces a lightweight visual attention mass signal that exhibits a strong positive correlation with effective visual token usage. This signal is used to set a per-step retention budget, retaining only 5% of visual tokens while shortening reasoning traces by 11.2% with accuracy nearly unchanged.
Significance. If the empirical correlation and experimental outcomes hold under detailed scrutiny, VisionPulse offers a practical route to reduce inference-time visual token overhead in multimodal reasoning without retraining. The step-dependent pruning and use of attention mass to enforce sparsity during decoding represent a targeted advance over static prefill pruning methods, with potential impact on deployment efficiency for LMMs.
major comments (2)
- [Abstract] Abstract: The central claim that visual attention mass has a 'strong positive correlation' with LMMs' effective visual token usage is asserted without any reported correlation coefficient, R² value, per-step variance, or robustness metrics across models or datasets. This correlation directly determines the 5% retention budget and is load-bearing for the 'almost unchanged' accuracy result; without quantification or failure-case analysis, the fixed-percentage pruning mechanism cannot be verified to preserve the minimal necessary token set at each step.
- [Abstract] Abstract: Quantitative outcomes (5% token retention, 11.2% trace shortening, accuracy 'almost unchanged') are presented with no experimental details on datasets, baselines, number of runs, error bars, or statistical significance tests. This absence prevents evaluation of whether the reported gains are reliable or whether the step-dependent evidence assumption holds beyond the specific cases tested.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript to incorporate the requested quantifications and details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that visual attention mass has a 'strong positive correlation' with LMMs' effective visual token usage is asserted without any reported correlation coefficient, R² value, per-step variance, or robustness metrics across models or datasets. This correlation directly determines the 5% retention budget and is load-bearing for the 'almost unchanged' accuracy result; without quantification or failure-case analysis, the fixed-percentage pruning mechanism cannot be verified to preserve the minimal necessary token set at each step.
Authors: We agree that the abstract would be strengthened by explicit quantification. The full manuscript contains the supporting analysis of the attention mass signal; we will revise the abstract to report the Pearson correlation coefficient, R² value, per-step variance, and robustness metrics across models and datasets, along with a brief note on how these support the 5% retention budget. revision: yes
-
Referee: [Abstract] Abstract: Quantitative outcomes (5% token retention, 11.2% trace shortening, accuracy 'almost unchanged') are presented with no experimental details on datasets, baselines, number of runs, error bars, or statistical significance tests. This absence prevents evaluation of whether the reported gains are reliable or whether the step-dependent evidence assumption holds beyond the specific cases tested.
Authors: We acknowledge that the abstract lacks these experimental specifics. We will revise the abstract to include key details on the datasets, baselines, number of evaluation runs, and reference to error bars and significance testing as reported in the main body of the paper. revision: yes
Circularity Check
No significant circularity in VisionPulse derivation
full rationale
The paper grounds its method in empirical observations (step-dependent visual evidence and positive correlation between attention mass and effective token usage) presented as external facts guiding the design, rather than deriving them from the pruning mechanism itself. The retention budget is computed dynamically from model attention mass as a proxy, with the 5% retention and 11.2% trace shortening reported as experimental outcomes. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness claims appear in the provided text to create a self-referential loop. The derivation chain remains independent and externally validated by experiments.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Visual evidence is strongly step-dependent: only a sparse subset of visual tokens is critical at each decoding step, and the critical set evolves across reasoning.
- domain assumption Visual attention mass has a strong positive correlation with LMMs' effective visual token usage.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., et al. Qwen3-VL technical report. arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y ., Chen, Z., Duan, H., Wang, J., Qiao, Y ., Lin, D., et al. Are we on the right way for evaluating Large Vision-Language Models? Advances in Neural Information Processing Systems, 37: 27056–27087, 2024a. Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., and Chang, B. An image is worth 1/2 tokens after ...
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-R1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Car- ney, A., et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y ., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y ., Liu, Z., et al. Llava- onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2202.07800 (2022) 4
Liang, Y ., Ge, C., Tong, Z., Song, Y ., Wang, J., and Xie, P. Not all patches are what you need: Expediting vision transformers via token reorganizations.arXiv preprint arXiv:2202.07800,
-
[7]
HiPrune: Hierarchical Attention for Efficient Token Pruning in Vision-Language Models
Liu, J., Du, F., Zhu, G., Lian, N., Li, J., and Chen, B. HiPrune: Training-free visual token pruning via hierarchi- cal attention in Vision-Language Models.arXiv preprint arXiv:2508.00553,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
L., Tan, J
Masry, A., Do, X. L., Tan, J. Q., Joty, S., and Hoque, E. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. InFindings of ACL 2022, pp. 2263–2279,
2022
-
[9]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Snell, C., Lee, J., Xu, K., and Kumar, A. Scaling LLM test- time compute optimally can be more effective than scal- ing model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Team, K., Du, A., Yin, B., Xing, B., Qu, B., Wang, B., Chen, C., Zhang, C., Du, C., Wei, C., et al. Kimi-VL technical report.arXiv preprint arXiv:2504.07491,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Look-M: Look-once optimization in KV cache for efficient multimodal long-context inference
Wan, Z., Wu, Z., Liu, C., Huang, J., Zhu, Z., Jin, P., Wang, L., and Yuan, L. Look-M: Look-once optimization in KV cache for efficient multimodal long-context inference. arXiv preprint arXiv:2406.18139,
-
[12]
Q., Stepputtis, S., Morency, L.-P., Ramanan, D., Sycara, K., and Xie, Y
Wan, Z., Zhang, C., Yong, S., Ma, M. Q., Stepputtis, S., Morency, L.-P., Ramanan, D., Sycara, K., and Xie, Y . Only: One-layer intervention sufficiently mitigates hallu- cinations in large vision-language models.arXiv preprint arXiv:2507.00898,
-
[13]
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Wang, H., Qu, C., Huang, Z., Chu, W., Lin, F., and Chen, W. VL-Rethinker: Incentivizing self-reflection of Vision- Language Models with reinforcement learning.arXiv preprint arXiv:2504.08837, 2025a. Wang, W., Ding, L., Zeng, M., Zhou, X., Shen, L., Luo, Y ., Yu, W., and Tao, D. Divide, conquer and combine: A training-free framework for high-resolution ima...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey
Wang, Y ., Wu, S., Zhang, Y ., Yan, S., Liu, Z., Luo, J., and Fei, H. Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025d. Wang, Z., Xia, M., He, L., Chen, H., Liu, Y ., Zhu, R., Liang, K., Wu, X., Liu, H., Malladi, S., et al. CharXiv: Charting gaps in realistic chart understanding in Multimodal LLMs. Advan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URL https://arxiv.org/ abs/2407.15754. xAI. RealworldQA,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URL https: //huggingface.co/datasets/xai-org/ RealworldQA. Xia, H., Leong, C. T., Wang, W., Li, Y ., and Li, W. To- kenSkip: Controllable chain-of-thought compression in LLMs.arXiv preprint arXiv:2502.12067,
-
[17]
Fast-slow thinking for Large Vision-Language Model reasoning
Xiao, W., Gan, L., Dai, W., He, W., Huang, Z., Li, H., Shu, F., Yu, Z., Zhang, P., Jiang, H., et al. Fast-slow thinking for Large Vision-Language Model reasoning. arXiv preprint arXiv:2504.18458,
-
[18]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Xing, L., Huang, Q., Dong, X., Lu, J., Zhang, P., Zang, Y ., Cao, Y ., He, C., Wang, J., Wu, F., et al. PyramidDrop: Accelerating your Large Vision-Language Models via pyramid visual redundancy reduction.arXiv preprint arXiv:2410.17247,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
VisionZip: Longer is better but not necessary in Vision Language Models
Yang, S., Chen, Y ., Tian, Z., Wang, C., Li, J., Yu, B., and Jia, J. VisionZip: Longer is better but not necessary in Vision Language Models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 19792–19802, 2025a. 10 VisionPulse: Dynamic Visual Sparsity for Efficient Multimodal Reasoning Yang, S., Niu, Y ., Liu, Y ., Ye, Y ., Lin,...
-
[20]
Demystifying Long Chain-of-Thought Reasoning in LLMs
Yeo, E., Tong, Y ., Niu, M., Neubig, G., and Yue, X. Demys- tifying long chain-of-thought reasoning in LLMs.arXiv preprint arXiv:2502.03373,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Unified visual transformer compression
Yu, S., Chen, T., Shen, J., Yuan, H., Tan, J., Yang, S., Liu, J., and Wang, Z. Unified visual transformer compression. arXiv preprint arXiv:2203.08243,
-
[22]
MLLMs know where to look: Training-free perception of small visual details with Multimodal LLMs
Zhang, J., Khayatkhoei, M., Chhikara, P., and Ilievski, F. MLLMs know where to look: Training-free perception of small visual details with Multimodal LLMs. InInterna- tional Conference on Learning Representations (ICLR), pp. 68194–68213, 2025a. Zhang, J., Lin, N., Hou, L., Feng, L., and Li, J. AdaptThink: Reasoning models can learn when to think.arXiv pre...
-
[23]
Additional Analysis A.1
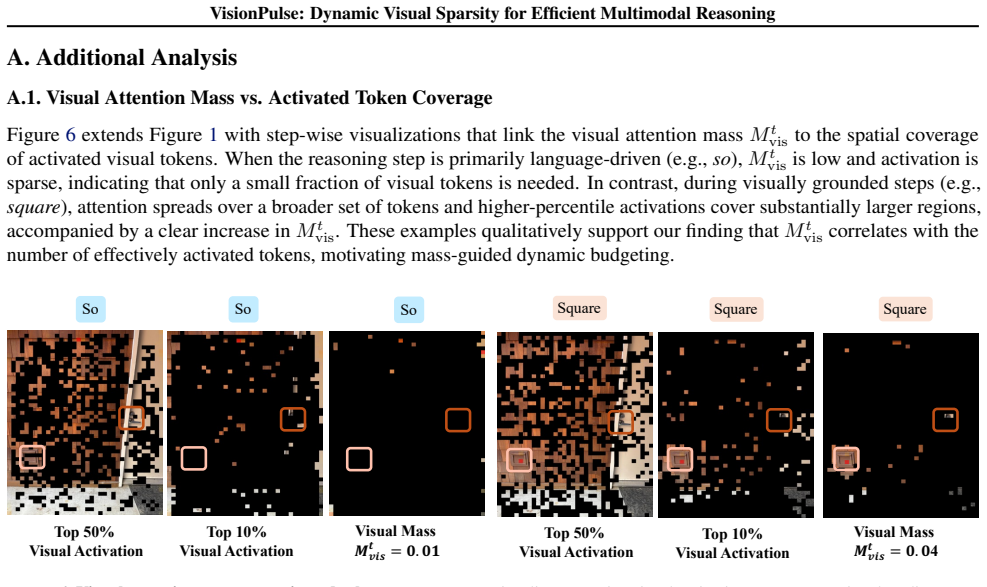
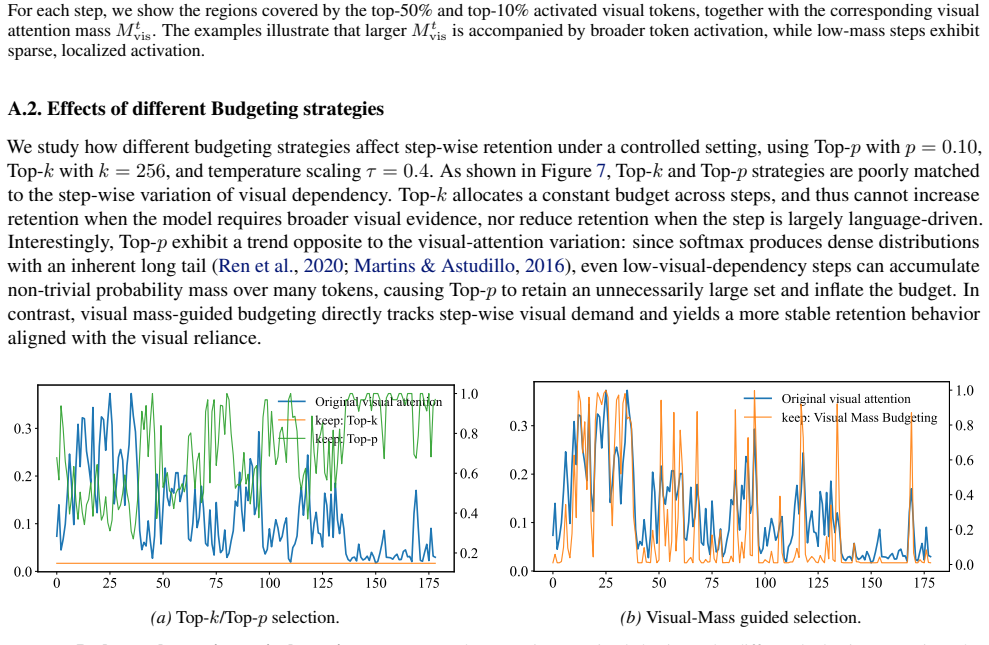
11 VisionPulse: Dynamic Visual Sparsity for Efficient Multimodal Reasoning A. Additional Analysis A.1. Visual Attention Mass vs. Activated Token Coverage Figure 6 extends Figure 1 with step-wise visualizations that link the visual attention mass M t vis to the spatial coverage of activated visual tokens. When the reasoning step is primarily language-drive...
2020
-
[24]
This suggests that VisionPulse is orthogonal to static visual token pruning methods such as FastV and can be combined with them for additional efficiency improvements
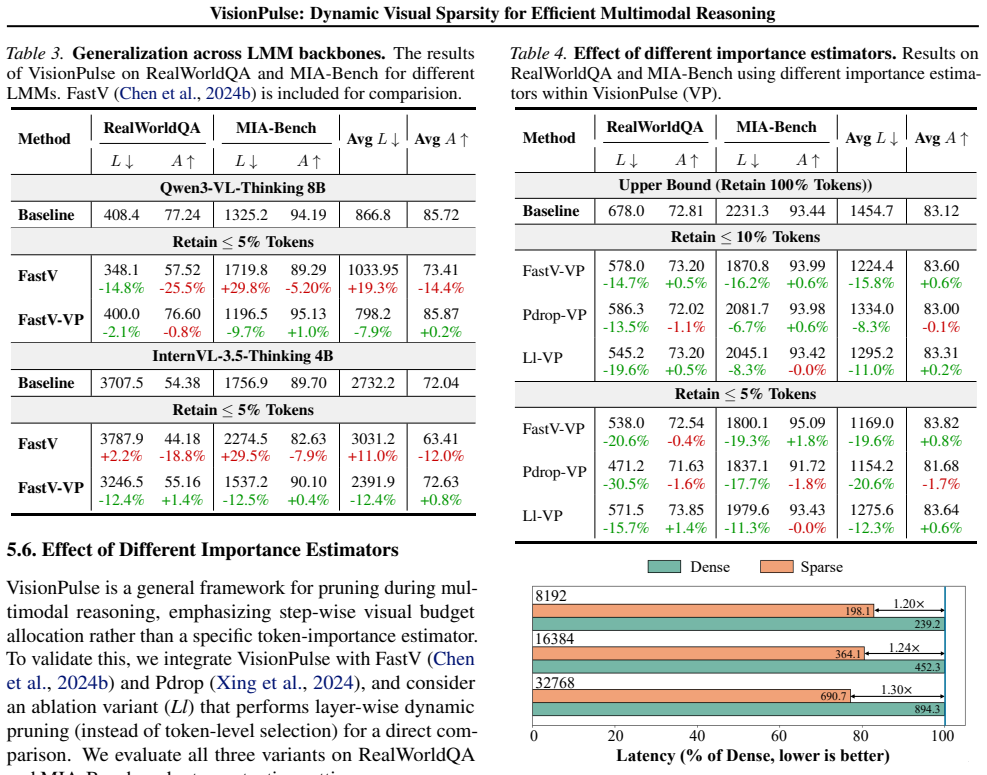
FastV+VisionPulse consistently outperforms FastV alone, indicating that VisionPulse complements prefill-stage token reduction. This suggests that VisionPulse is orthogonal to static visual token pruning methods such as FastV and can be combined with them for additional efficiency improvements. Persistent visual redundancy during reasoning.Beyond verifying...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.