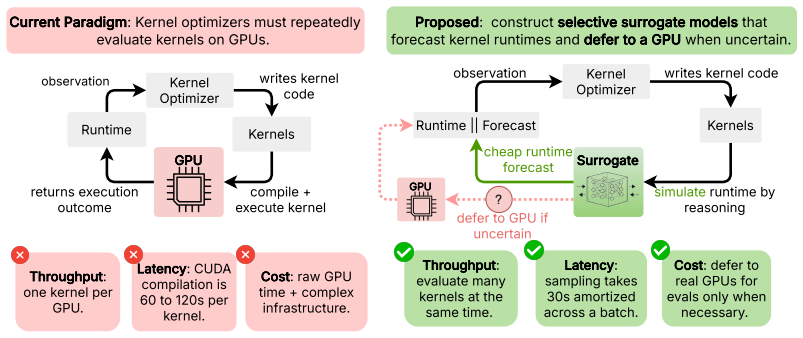
GPU Forecasters: Language Models as Selective Surrogates for Kernel Runtime Optimization
Pith reviewed 2026-06-28 23:08 UTC · model grok-4.3
The pith
Language models forecast GPU kernel performance and selectively defer to hardware to let searches evaluate more candidates under fixed budgets, yielding faster kernels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
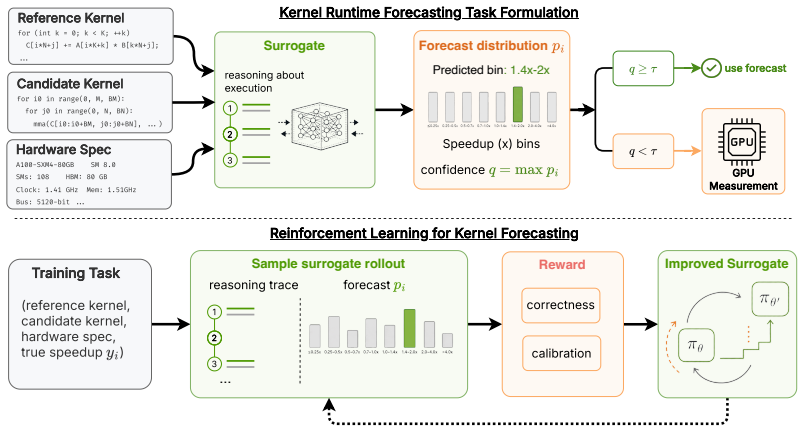
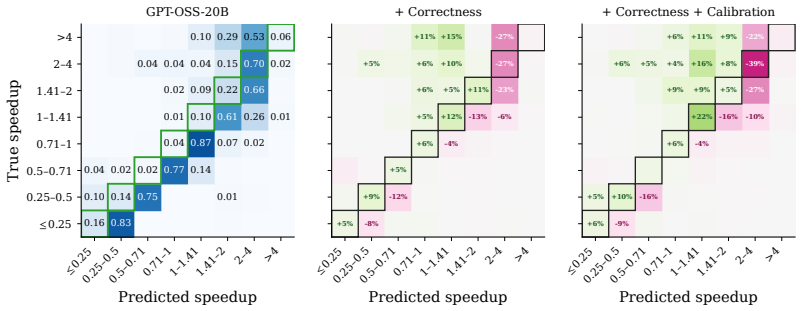
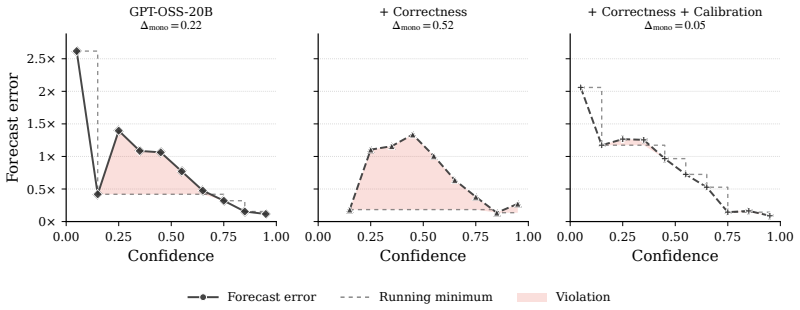
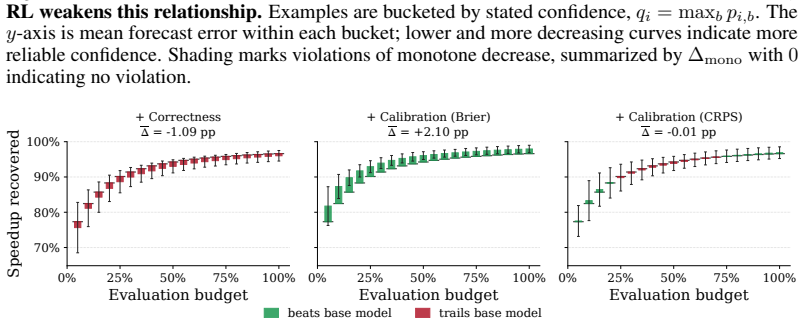
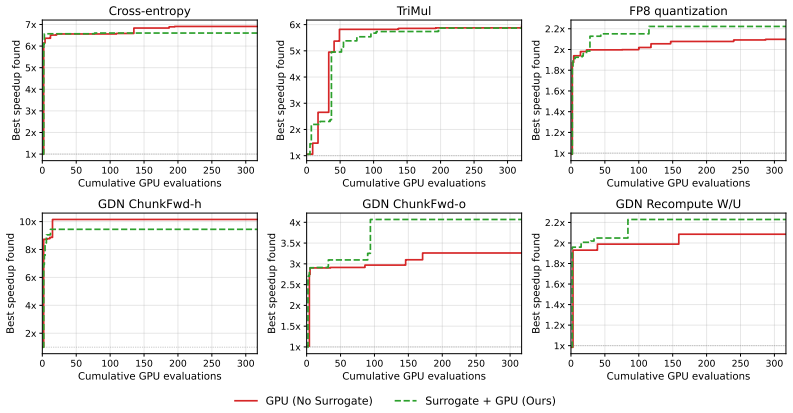
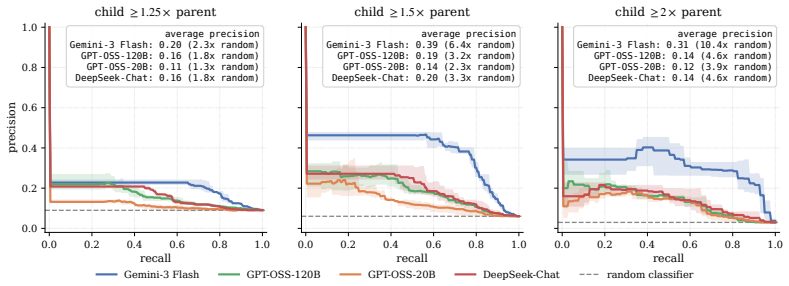
LLMs can accurately forecast relative kernel performance; when tuned via reinforcement learning for better calibration they function as selective surrogates that defer to GPU measurements on uncertain cases, so that a kernel search can consider several times as many candidates under the same GPU evaluation budget and recover faster kernels than an equal-budget baseline that always measures on hardware.
What carries the argument
The selective surrogate: an LLM that outputs both a relative performance forecast and a signal for deferral to the GPU when its prediction is likely unreliable.
If this is right
- Kernel searches can scale candidate volume without raising GPU measurement cost.
- Faster final kernels are obtained for the same on-device evaluation budget.
- Reinforcement learning can be used to raise both forecast accuracy and deferral calibration.
- LLMs can serve as virtual models of GPU behavior in addition to code generators.
Where Pith is reading between the lines
- The same selective-forecast pattern could be tested on other accelerators or non-kernel optimization tasks.
- Combining the surrogate with coding-agent generators might further enlarge the effective search space.
- If calibration holds across domains, the approach reduces reliance on repeated hardware runs in early design stages.
Load-bearing premise
LLM forecasts and uncertainty estimates stay sufficiently accurate across the kernels proposed during search so that selective deferral improves final kernel quality rather than introducing bias.
What would settle it
A kernel search using the surrogate that returns a slower best kernel than a pure-GPU-measurement baseline under identical GPU budget would show the surrogate is not useful.
Figures
read the original abstract
GPU kernels are the workhorse of modern deep learning, and optimizing them (via evolutionary search or coding agents) usually requires repeated measurement on target hardware. While these measurements provide the ground-truth signal necessary for kernel search, they are costly, because each evaluation of a kernel requires compilation and repeated execution on a GPU. As improvements in LLM inference reduce the cost of writing novel kernels and LLM-driven searches scale to large search budgets, on-device evaluation becomes a bottleneck. To address this, we study how LLMs can serve as selective GPU surrogates for kernel evaluation, by forecasting the performance of proposed kernels. A useful surrogate should be accurate, and it should be selective, by knowing when it could be wrong, and deferring to the GPU. To evaluate surrogates, we measure whether their forecasts are accurate, calibrated, and practically useful for recovering fast kernels under limited GPU-measurement budgets. Next, we study whether reinforcement learning can improve forecast accuracy and confidence calibration. Our experiments demonstrate that LLMs can accurately forecast relative kernel performance, that their utility can be improved through reinforcement learning. Used inside a kernel search, the surrogate lets the search consider several times as many candidates under the same GPU evaluation budget, and that leads to finding faster kernels than an equal-budget baseline. These results suggest that LLMs can play a broader role in kernel optimization, by acting as virtual models of a GPU rather than solely as kernel generators for search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes using LLMs as selective surrogates to forecast relative runtime performance of GPU kernels, thereby reducing the number of expensive on-device evaluations needed during evolutionary or agent-driven kernel searches. It reports that LLMs produce accurate relative forecasts, that RL fine-tuning improves both accuracy and confidence calibration, and that deploying the surrogate inside a search loop permits evaluating several times more candidates under a fixed GPU budget, ultimately yielding faster kernels than an equal-budget baseline that relies solely on GPU measurements.
Significance. If the empirical results hold under the reported conditions, the work demonstrates a practical way to scale kernel optimization by treating LLMs as cheap, selective virtual models of GPU behavior rather than only as code generators. The combination of relative-accuracy evaluation, RL-driven calibration, and end-to-end search improvement supplies concrete evidence that selective deferral can increase search throughput without degrading final kernel quality. This approach could meaningfully lower the hardware cost of automated kernel tuning in deep-learning systems.
minor comments (3)
- [§4.2] §4.2 and Table 2: the description of the RL reward function does not explicitly state how the calibration term is normalized relative to the accuracy term; adding the exact weighting formula would remove ambiguity when reproducing the reported calibration gains.
- [Figure 3] Figure 3 caption: the x-axis label 'search budget (GPU evals)' should clarify whether the plotted points include or exclude the surrogate-only evaluations; this affects interpretation of the 'several times more candidates' claim.
- [§5.3] §5.3: the baseline search is described as 'equal-budget' but the text does not state whether the baseline also uses the same evolutionary operators and population size; a one-sentence clarification would strengthen the comparison.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The referee's description of the work is accurate. No specific major comments were provided in the report, so we have no point-by-point responses. We will incorporate any minor revisions requested by the editor.
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical workflow: LLMs are fine-tuned via reinforcement learning on kernel performance data, then evaluated for forecast accuracy, calibration, and end-to-end utility inside a search loop whose final kernels are measured on actual GPU hardware. All load-bearing claims (relative ranking accuracy, selective deferral benefit, and search improvement under fixed measurement budget) are validated by direct comparison to hardware baselines rather than by any equation that reduces a forecast to a quantity already fitted inside the same paper. No self-citation chain, uniqueness theorem, or ansatz is invoked to justify the surrogate; the derivation chain therefore remains self-contained against external hardware measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Abramson, Jonas Adler, Jack Dunger, Richard Evans, Tim Green, Alexander Pritzel, Olaf Ronneberger, Lindsay Willmore, Andrew J. Ballard, Joshua Bambrick, et al. Accurate structure prediction of biomolecular interactions with AlphaFold 3.Nature, 630:493–500, 2024. doi: 10.1038/s41586-024-07487-w
-
[2]
Gregory Bolet, Giorgis Georgakoudis, Konstantinos Parasyris, Harshitha Menon, Niranjan Hasabnis, Kirk W. Cameron, and Gal Oren. Counting without running: Evaluating LLMs’ reasoning about code complexity.arXiv preprint arXiv:2512.04355, 2025
-
[3]
Shiyi Cao, Ziming Mao, Joseph E. Gonzalez, and Ion Stoica. K-search: Llm kernel generation via co-evolving intrinsic world model.arXiv preprint arXiv:2602.19128, 2026
-
[4]
Scaling open-ended reasoning to predict the future.arXiv preprint arXiv:2512.25070, 2025
Nikhil Chandak, Shashwat Goel, Ameya Prabhu, Moritz Hardt, and Jonas Geiping. Scaling open-ended reasoning to predict the future.arXiv preprint arXiv:2512.25070, 2025
-
[5]
Avo: Agentic variation operators for autonomous evolutionary search, 2026
Terry Chen, Zhifan Ye, Bing Xu, Zihao Ye, Timmy Liu, Ali Hassani, Tianqi Chen, Andrew Kerr, Haicheng Wu, Yang Xu, Yu-Jung Chen, Hanfeng Chen, Aditya Kane, Ronny Krashinsky, Ming-Yu Liu, Vinod Grover, Luis Ceze, Roger Bringmann, John Tran, Wei Liu, Fung Xie, Michael Lightstone, and Humphrey Shi. Avo: Agentic variation operators for autonomous evolutionary ...
-
[6]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
Franc ¸ois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard. ARC- AGI-2: A new challenge for frontier AI reasoning systems, 2025. URL https://arxiv.org/ abs/2505.11831
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
An optimum character recognition system using decision functions.IRE Transactions on Electronic Computers, EC-6(4):247–254, 1957
Chi-Keung Chow. An optimum character recognition system using decision functions.IRE Transactions on Electronic Computers, EC-6(4):247–254, 1957
1957
-
[8]
Cuda agent: Large-scale agentic rl for high-performance cuda kernel generation.arXiv preprint, 2026
Weinan Dai, Hanlin Wu, Qiying Yu, Huan-ang Gao, Jiahao Li, Chengquan Jiang, Weiqiang Lou, Yufan Song, Hongli Yu, Jiaze Chen, Wei-Ying Ma, Ya-Qin Zhang, Jingjing Liu, Mingxuan Wang, Xin Liu, and Hao Zhou. Cuda agent: Large-scale agentic rl for high-performance cuda kernel generation.arXiv preprint, 2026
2026
-
[9]
Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Mehul Damani, Isha Puri, Stewart Slocum, Idan Shenfeld, Leshem Choshen, Yoon Kim, and Jacob Andreas. Beyond binary rewards: Training LMs to reason about their uncertainty.arXiv preprint arXiv:2507.16806, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
DeepSeek-V4: Towards highly efficient million-token context intelligence,
DeepSeek-AI. DeepSeek-V4: Towards highly efficient million-token context intelligence,
-
[11]
URL https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/ DeepSeek_V4.pdf
-
[12]
On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11:1605–1641, 2010
Ran El-Yaniv and Yair Wiener. On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11:1605–1641, 2010
2010
-
[13]
Cwm: An open-weights llm for research on code generation with world models, 2025
Meta FAIR CodeGen Team. Cwm: An open-weights llm for research on code generation with world models, 2025. URLhttps://ai.meta.com/research/publications/cwm/
2025
-
[14]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[15]
Mathematical exploration and discovery at scale
Bogdan Georgiev, Javier G´omez-Serrano, Terence Tao, and Adam Zsolt Wagner. Mathematical exploration and discovery at scale.arXiv preprint arXiv:2511.02864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Gemini 3 pro model card, 2025
Google DeepMind. Gemini 3 pro model card, 2025. URL https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf
2025
-
[17]
Alex Gu, Baptiste Rozi `ere, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I. Wang. CRUXEval: A benchmark for code reasoning, understanding and execution. arXiv preprint arXiv:2401.03065, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Recurrent world models facilitate policy evolution
David Ha and J ¨urgen Schmidhuber. Recurrent world models facilitate policy evolution. In Advances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[19]
Mastering diverse control tasks through world models,
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640:647–653, 2025. doi: 10.1038/s41586-025-08744-2
-
[20]
Siva Kumar Sastry Hari, Vignesh Balaji, Sana Damani, Qijing Huang, and Christos Kozyrakis. Improving efficiency of GPU kernel optimization agents using a domain-specific language and speed-of-light guidance.arXiv preprint arXiv:2603.29010, 2026
-
[21]
Jones, Matthias Schonlau, and William J
Donald R. Jones, Matthias Schonlau, and William J. Welch. Efficient global optimization of expensive black-box functions.Journal of Global Optimization, 13:455–492, 1998. doi: 10.1023/A:1008306431147
-
[22]
One life to learn: Inferring symbolic world models for stochastic environments from unguided exploration
Zaid Khan, Archiki Prasad, Elias Stengel-Eskin, Jaemin Cho, and Mohit Bansal. One life to learn: Inferring symbolic world models for stochastic environments from unguided exploration. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[23]
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. Shinkaevolve: Towards open-ended and sample-efficient program evolution.arXiv preprint arXiv:2509.19349, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Obtaining well calibrated probabilities using bayesian binning
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. InProceedings of the AAAI conference on artificial intelligence, volume 29, 2015
2015
-
[25]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov et al. AlphaEvolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025. URL https://arxiv.org/abs/ 2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
KernelBench: Can LLMs Write Efficient GPU Kernels?
Anne Ouyang, Simon Guo, Simran Arora, Alex L. Zhang, William Hu, Christopher R´e, and Azalia Mirhoseini. Kernelbench: Can llms write efficient gpu kernels?, 2025. URL https: //arxiv.org/abs/2502.10517
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
PoE-World: Compositional world modeling with products of programmatic experts
Wasu Top Piriyakulkij, Yichao Liang, Hao Tang, Adrian Weller, Marta Kryven, and Kevin Ellis. PoE-World: Compositional world modeling with products of programmatic experts. In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[29]
Learning to generate unit tests for automated debugging
Archiki Prasad, Elias Stengel-Eskin, Justin Chen, Zaid Khan, and Mohit Bansal. Learning to generate unit tests for automated debugging. InSecond Conference on Language Modeling, 2025. 13
2025
-
[30]
Luke Rivard, Sun Sun, Hongyu Guo, Wenhu Chen, and Yuntian Deng. NeuralOS: Towards simulating operating systems via neural generative models.arXiv preprint arXiv:2507.08800, 2025
-
[31]
Christopher D. Rosin. Multi-armed bandits with episode context.Annals of Mathematics and Artificial Intelligence, 61:203–230, 2011. doi: 10.1007/s10472-011-9258-6
-
[32]
Tara Saba, Anne Ouyang, Xujie Si, and Fan Long. CuTeGen: An LLM-based agentic framework for generation and optimization of high-performance GPU kernels using CuTe.arXiv preprint arXiv:2604.01489, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588:604–609, 2020. doi: 10.1038/s41586-020-03051-4
work page internal anchor Pith review doi:10.1038/s41586-020-03051-4 2020
-
[34]
Active learning literature survey
Burr Settles. Active learning literature survey. Technical Report 1648, University of Wisconsin- Madison Department of Computer Sciences, 2009
2009
-
[35]
Lacie: Listener-aware finetuning for calibration in large language models.Advances in Neural Information Processing Systems, 37: 43080–43106, 2024
Elias Stengel-Eskin, Peter Hase, and Mohit Bansal. Lacie: Listener-aware finetuning for calibration in large language models.Advances in Neural Information Processing Systems, 37: 43080–43106, 2024
2024
-
[36]
Richard S. Sutton. Dyna, an integrated architecture for learning, planning, and reacting.ACM SIGART Bulletin, 2(4):160–163, 1991
1991
-
[37]
ThetaEvolve: Test-time Learning on Open Problems
Yiping Wang, Shao-Rong Su, Zhiyuan Zeng, Eva Xu, Liliang Ren, Xinyu Yang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, Hao Cheng, Pengcheng He, Weizhu Chen, Shuohang Wang, Simon Shaolei Du, and Yelong Shen. Thetaevolve: Test-time learning on open problems. arXiv preprint 2511.23473, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Benchmarking World-Model Learning with Environment-Level Queries
Archana Warrier, Dat Nguyen, Michelangelo Naim, Moksh Jain, Yichao Liang, Karen Schroeder, Cambridge Yang, Joshua B. Tenenbaum, Sebastian V ollmer, Kevin Ellis, and Zenna Tavares. Benchmarking world-model learning, 2025. URLhttps://arxiv.org/abs/2510.19788
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Qingchuan Yang, Simon Mahns, Sida Li, Anri Gu, Jibang Wu, and Haifeng Xu. LLM- as-a-prophet: Understanding predictive intelligence with Prophet Arena.arXiv preprint arXiv:2510.17638, 2025
-
[40]
MIRAI: Evaluating LLM agents for event forecasting.arXiv preprint arXiv:2407.01231, 2024
Chenchen Ye, Ziniu Hu, Yihe Deng, Zijie Huang, Mingyu Derek Ma, Yanqiao Zhu, and Wei Wang. MIRAI: Evaluating LLM agents for event forecasting.arXiv preprint arXiv:2407.01231, 2024
-
[41]
Learning to discover at test time.arXiv preprint, 2026
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, and Yu Sun. Learning to discover at test time.arXiv preprint, 2026
2026
-
[42]
Mingchen Zhuge, Changsheng Zhao, Haozhe Liu, Zijian Zhou, Shuming Liu, Wenyi Wang, Ernie Chang, Gael Le Lan, Junjie Fei, Wenxuan Zhang, Yasheng Sun, Zhipeng Cai, Zechun Liu, Yunyang Xiong, Yining Yang, Yuandong Tian, Yangyang Shi, Vikas Chandra, and J¨urgen Schmidhuber. Neural computers.arXiv preprint arXiv:2604.06425, 2026. A Success Cases and Failure Ca...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
%.2f"|format(hardware.clock_rate_ghz) }} GHz | | Memory Clock | {{
**Data types and special hardware**: Does the candidate use lower precision (FP16, INT8) or tensor cores? These can provide large speedups for eligible operations. Think carefully about the RELATIVE performance. A candidate might be well-written but still slower than a PyTorch reference that dispatches to cuBLAS. Conversely, a simple-looking candidate mig...
-
[53]
**Algorithmic complexity**: How many FLOPs does each kernel perform? Does the candidate reduce total work (e.g., fused operations, fewer passes over data)?
-
[54]
**Memory access patterns**: Are global memory accesses coalesced? Does the candidate use shared memory or registers to reduce global memory traffic? How many bytes are read/written per thread?
-
[55]
**Arithmetic intensity**: What is the ratio of compute to memory operations? Is the kernel compute-bound or memory-bandwidth- bound? This determines which optimizations matter
-
[56]
**Thread divergence**: Do conditionals cause warp divergence? Does the candidate reduce branch divergence compared to the reference?
-
[57]
**Occupancy and resource pressure**: How many registers per thread? How much shared memory per block? These limit the number of concurrent warps and can bottleneck throughput
-
[58]
**Parallelism and grid dimensions**: Does the candidate expose more parallelism? Are there enough threads to saturate the GPU? Is the work evenly distributed across blocks?
-
[59]
**Synchronization overhead**: Does the kernel use __syncthreads(), atomics, or other synchronization primitives? These can serialize execution
-
[60]
Multiple kernel launches vs
**Kernel launch overhead**: For very fast kernels, launch overhead can dominate. Multiple kernel launches vs. a single fused kernel matters
-
[61]
custom code**: Does the reference use highly optimized vendor libraries (cuBLAS, cuDNN)? Custom kernels rarely beat these for standard operations (GEMM, convolution)
**Library calls vs. custom code**: Does the reference use highly optimized vendor libraries (cuBLAS, cuDNN)? Custom kernels rarely beat these for standard operations (GEMM, convolution)
-
[62]
%.2f"|format(hardware.clock_rate_ghz) }} GHz | | Memory Clock | {{
**Data types and special hardware**: Does the candidate use lower precision (FP16, INT8) or tensor cores? These can provide large speedups for eligible operations. Think carefully about the RELATIVE performance. A candidate might be well-written but still slower than a PyTorch reference that dispatches to cuBLAS. Conversely, a simple-looking candidate mig...
2000
-
[63]
Translates the 2D tensor `(num_tokens, hidden_dim)` into a flat 1D grid of `total_groups`.,→
-
[64]
Dynamically adjusts `BLOCK_GROUPS` strictly to balance SM wave occupancy and register limit.,→ - Targeting >= 512 blocks ensures massive wave overlap on A100's 108 SMs to natively hide DRAM latency.,→ - Capping `BLOCK_GROUPS` at 128 guarantees <= 64 elements per thread, completely eliminating,→ register spilling which otherwise drastically hurts performan...
-
[65]
Groups are processed entirely within registers natively (intra-warp reduction), bypassing,→ shared memory round-trips
-
[66]
Drops PTX masking globally when the dispatch grid perfectly overlaps the tensor boundary.,→ """ 34 import torch import triton import triton.language as tl @triton.jit def fp8_quantize_kernel( x_ptr, x_q_ptr, x_s_ptr, total_groups, GROUP_SIZE: tl.constexpr, BLOCK_GROUPS: tl.constexpr, NEEDS_MASK: tl.constexpr, ): pid = tl.program_id(0) group_start = pid * ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.