Reliable Multilingual Orthopedic Decision Support from Clinical Narratives: Language-Aware Adaptation and Verification-Guided Deferral
Pith reviewed 2026-06-28 22:30 UTC · model grok-4.3
The pith
IndicBERT-HPA with a selective-verification layer reaches 84.4% accuracy on 72.3% of multilingual orthopedic notes while deferring the rest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
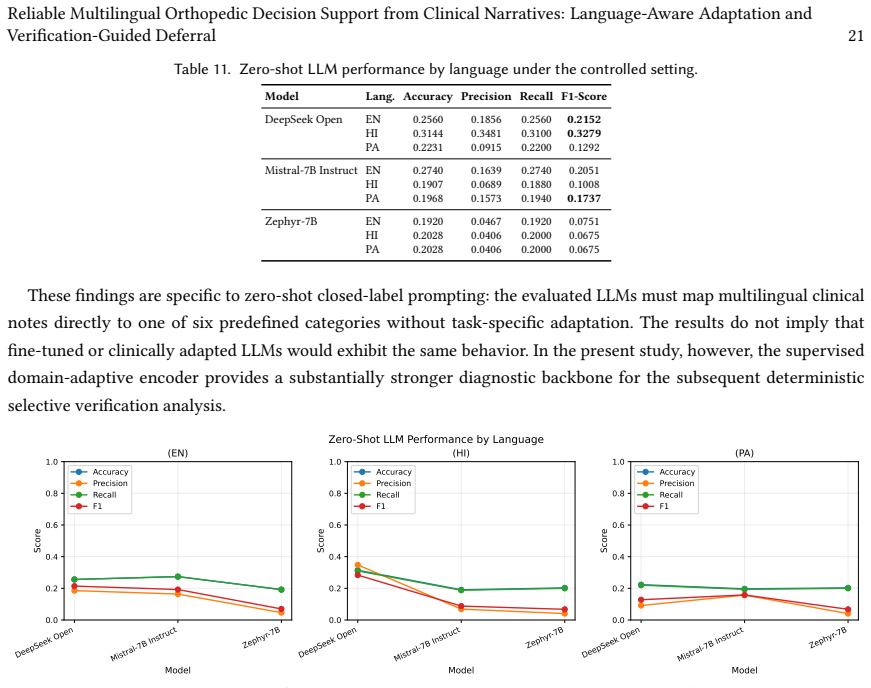
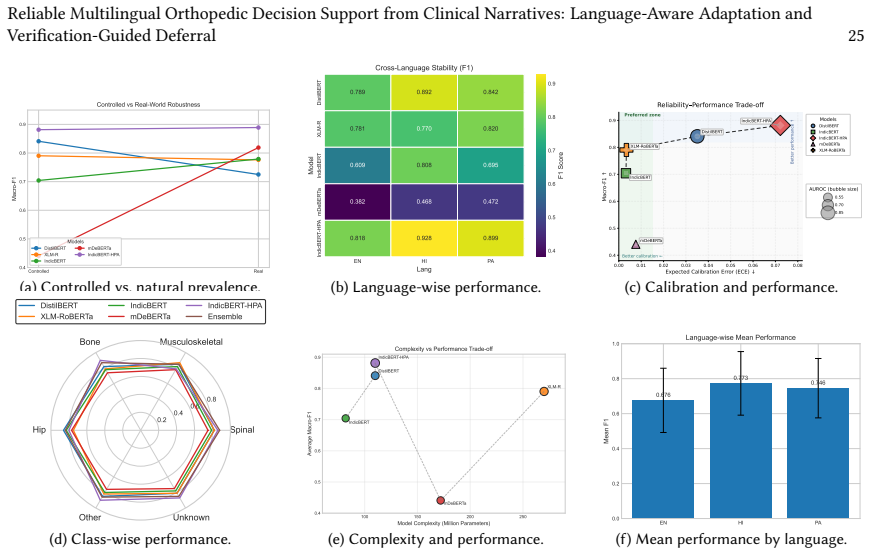
Under natural clinical prevalence, IndicBERT-HPA achieves the strongest overall performance, reaching an averaged Macro-F1 of 0.8792, Macro-AUROC of 0.894 and AUPRC of 0.902. The selective-verification layer achieves 84.4% selective accuracy and 0.76 selective Macro-F1 at 72.3% coverage, compared with 71.5% accuracy and 0.65 Macro-F1 for accept-all prediction. Zero-shot LLMs remain substantially less effective than task-adapted encoders for closed-set classification, with language-dependent instability.
What carries the argument
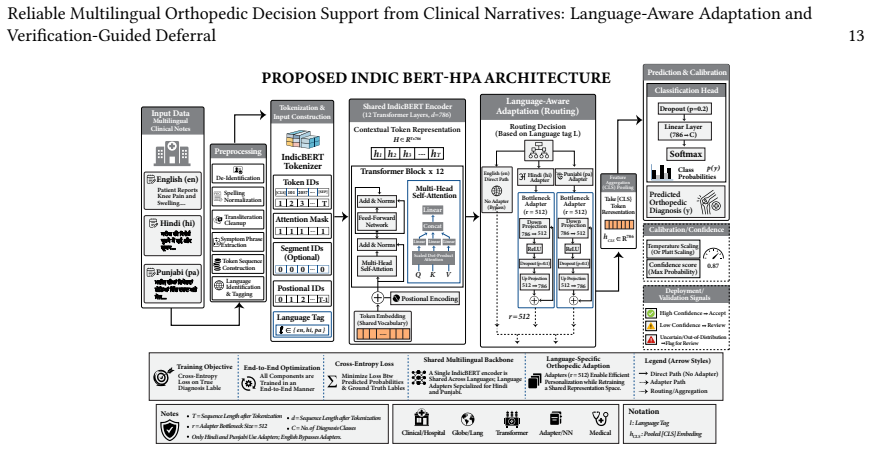
IndicBERT-HPA, IndicBERT augmented with language-aware orthopedic adapter heads, paired with a deterministic selective-verification layer that combines confidence gating, evidence-consistency checking and language-risk screening.
If this is right
- Task-adapted encoders outperform zero-shot LLMs on closed-set multilingual classification with reduced language-dependent instability.
- The verification layer produces higher accuracy and Macro-F1 by deferring uncertain cases rather than forcing every prediction.
- Strong per-class, ROC-AUC, AUPRC and calibration results hold under both balanced and natural-prevalence distributions.
- Cross-language stability is maintained across English, Hindi and Punjabi notes.
Where Pith is reading between the lines
- The 27.7% deferral rate implies a need for human review capacity in any deployed workflow.
- The same adapter-plus-verification pattern could be tested on clinical notes from other specialties that use mixed-language documentation.
- Language-risk screening may need recalibration if applied to additional low-resource languages not present in the current training data.
- Integration with electronic health record systems would require measuring end-to-end latency and clinician acceptance of the deferred cases.
Load-bearing premise
The randomly selected held-out 5,000-record subset accurately reflects natural clinical prevalence distributions, and the deterministic components of the selective-verification layer reliably identify unreliable predictions without introducing new systematic biases.
What would settle it
A prospective test on a larger, independently collected clinical-note set in which selective accuracy falls below the 71.5% accept-all baseline or the verification layer systematically defers one language more than the others.
Figures




read the original abstract
Multilingual orthopedic decision support remains challenging in low-resource healthcare settings, where clinical narratives contain specialized terminology, mixed scripts, incomplete evidence, label imbalance and language-dependent documentation patterns. This article presents a reliability-oriented framework for classifying free-text orthopedic notes in English, Hindi and Punjabi. We compare task-aligned multilingual transformer encoders, a task-fine-tuned DistilBERT baseline, zero-shot instruction-tuned large language models (LLMs) and a domain-adaptive encoder, IndicBERT-HPA. IndicBERT-HPA augments IndicBERT with language-aware orthopedic adapter heads to support clinically relevant multilingual representation learning. Evaluation extends beyond aggregate accuracy to per-class performance, ROC-AUC, AUPRC, expected calibration error, cross-language stability and robustness under controlled balanced and natural-prevalence distributions. The evaluated zero-shot LLMs remain substantially less effective than task-adapted encoders for closed-set classification, with language-dependent instability. Under natural clinical prevalence, IndicBERT-HPA achieves the strongest overall performance, reaching an averaged Macro-F1 of 0.8792, Macro-AUROC of 0.894 and AUPRC of 0.902. We further implement a deterministic selective-verification layer combining confidence gating, evidence-consistency checking and language-risk screening. On a randomly selected held-out 5,000-record subset, it achieves 84.4% selective accuracy and 0.76 selective Macro-F1 at 72.3% coverage, compared with 71.5% accuracy and 0.65 Macro-F1 for accept-all prediction. These results support reliability-oriented multilingual clinical decision support with explicit deferral.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a reliability-oriented framework for multilingual classification of orthopedic clinical narratives in English, Hindi, and Punjabi. It evaluates task-adapted encoders including IndicBERT-HPA (with language-aware adapters), a DistilBERT baseline, and zero-shot LLMs, reporting that IndicBERT-HPA achieves the strongest results under natural prevalence (Macro-F1 0.8792, Macro-AUROC 0.894, AUPRC 0.902). A deterministic selective-verification layer (confidence gating, evidence-consistency checking, language-risk screening) is shown to raise selective accuracy to 84.4% and selective Macro-F1 to 0.76 at 72.3% coverage on a 5,000-record held-out subset, versus 71.5% accuracy and 0.65 Macro-F1 for accept-all.
Significance. If the reported metrics are reproducible, the work contributes a practical, reliability-focused approach to multilingual clinical NLP in low-resource settings by combining domain-adaptive encoders with an explicit, training-free deferral mechanism. The emphasis on per-class metrics, calibration error, cross-language stability, and performance under both balanced and natural-prevalence distributions strengthens applicability; the selective layer's coverage-accuracy tradeoff is a concrete, falsifiable improvement over non-selective baselines.
major comments (3)
- [§4] §4 (Evaluation): The central performance claims rest on metrics from a 'randomly selected held-out 5,000-record subset' under natural prevalence, yet the manuscript provides no description of the full dataset size, collection protocol, labeling process, or statistical comparison of the subset's class and language distributions to the source data. This detail is load-bearing for validating the natural-prevalence evaluation.
- [§3 and §5] §3 (Methods) and §5 (Selective-verification layer): The deterministic components (confidence gating thresholds, evidence-consistency rules, language-risk screening criteria) are described at a high level but lack the exact implementation details, parameter values, or pseudocode needed to reproduce the layer or assess whether it introduces new systematic biases. This directly affects verification of the reported 84.4% selective accuracy and 0.76 selective Macro-F1.
- [§4] §4: No error analysis, confusion matrices, or per-language breakdown is provided for the zero-shot LLM comparisons or the IndicBERT-HPA model, despite the abstract noting 'language-dependent instability.' This omission limits assessment of where the claimed superiority holds and where it does not.
minor comments (1)
- [Abstract] The abstract is dense; consider moving some metric definitions or the selective-layer description to the main text for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for major revision. We address each major comment below with specific plans for revision where the manuscript is incomplete. All changes will be incorporated into the next version.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): The central performance claims rest on metrics from a 'randomly selected held-out 5,000-record subset' under natural prevalence, yet the manuscript provides no description of the full dataset size, collection protocol, labeling process, or statistical comparison of the subset's class and language distributions to the source data. This detail is load-bearing for validating the natural-prevalence evaluation.
Authors: We agree the current description is insufficient. The revised manuscript will add a dedicated subsection in §4 that reports the full dataset size, the collection protocol from participating orthopedic departments, the labeling process (including annotator qualifications and inter-annotator agreement), and statistical tests confirming that the 5,000-record subset preserves the original class and language distributions under natural prevalence. revision: yes
-
Referee: [§3 and §5] §3 (Methods) and §5 (Selective-verification layer): The deterministic components (confidence gating thresholds, evidence-consistency rules, language-risk screening criteria) are described at a high level but lack the exact implementation details, parameter values, or pseudocode needed to reproduce the layer or assess whether it introduces new systematic biases. This directly affects verification of the reported 84.4% selective accuracy and 0.76 selective Macro-F1.
Authors: We accept this point. The revision will expand §5 with (i) the precise numerical thresholds used for confidence gating, (ii) the exact rule definitions for evidence-consistency checking and language-risk screening, (iii) pseudocode for the full deferral procedure, and (iv) a short analysis of possible systematic biases introduced by each component. revision: yes
-
Referee: [§4] §4: No error analysis, confusion matrices, or per-language breakdown is provided for the zero-shot LLM comparisons or the IndicBERT-HPA model, despite the abstract noting 'language-dependent instability.' This omission limits assessment of where the claimed superiority holds and where it does not.
Authors: We agree that the absence of these diagnostics weakens the language-stability claims. The revised §4 will include per-language performance tables, confusion matrices for both IndicBERT-HPA and the strongest zero-shot LLM, and a focused error analysis highlighting the specific failure modes that underlie the noted language-dependent instability. revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports empirical performance metrics (Macro-F1, AUROC, AUPRC, selective accuracy) obtained by training task-adapted encoders on clinical narratives and evaluating on a held-out 5,000-record subset. No equations, derivation steps, or self-citations are described that would reduce these metrics to fitted parameters by construction or import uniqueness from prior author work. The selective-verification layer is presented as a deterministic combination of confidence gating, evidence-consistency checking and language-risk screening whose outputs are measured directly against ground truth; this constitutes standard external evaluation rather than a self-referential loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abirami, N
S. Abirami, N. Krishnammal, R. Suganya, and R. T. Suganya. 2026. NLP Powered Orthopaedics Expert System. InProceedings of the 2026 International Conference on Intelligent and Innovative Technologies in Computing, Electrical and Electronics (IITCEE). IEEE, 1–5
2026
-
[2]
Hayden P Baker, Sarthak Aggarwal, Senthooran Kalidoss, Matthew Hess, Rex Haydon, and Jason A Strelzow. 2025. Diagnostic accuracy of ChatGPT-4 in orthopedic oncology: a comparative study with residents.The Knee55 (2025), 153–160
2025
-
[3]
Agnese Bonfigli, Luca Bacco, Mario Merone, and Felice Dell’Orletta. 2024. From pre-training to fine-tuning: An in-depth analysis of Large Language Models in the biomedical domain.Artificial Intelligence in Medicine157 (2024), 103003
2024
-
[4]
Rochana Chaturvedi, Peyman Baghershahi, Sourav Medya, and Barbara Di Eugenio. 2025. Temporal Relation Extraction in Clinical Texts: A Span-based Graph Transformer Approach. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vienna, Austria, 25765–257...
-
[5]
Qiang Chen, Yu Hu, Xi Peng, Qian Xie, Qiang Jin, Aaron Gilson, and Hua Xu. 2025. Benchmarking Large Language Models for Biomedical Natural Language Processing Applications and Recommendations.Nature Communications16, 1 (2025), 3280
2025
-
[7]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised Cross-lingual Representation Learning at Scale. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational...
-
[8]
Jean-Philippe Corbeil, Amin Dada, Jean-Michel Attendu, Asma Ben Abacha, Alessandro Sordoni, Lucas Caccia, Francois Beaulieu, Thomas Lin, Jens Kleesiek, and Paul Vozila. 2025. A Modular Approach for Clinical SLMs Driven by Synthetic Data with Pre-Instruction Tuning, Model Merging, and Clinical-Tasks Alignment. InProceedings of the 63rd Annual Meeting of th...
-
[9]
Warren Del-Pinto, George Demetriou, Meghna Jani, Rikesh Patel, Leanne Gray, Alex Bulcock, Niels Peek, Andrew S Kanter, William G Dixon, and Goran Nenadic. 2025. Exploring the consistency, quality and challenges in manual and automated coding of free-text diagnoses from hospital outpatient letters.Plos one20, 8 (2025), e0328108
2025
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. InNAACL-HLT
2019
-
[11]
Niles, Ken Pathak, and Steven Sloan
Md Meftahul Ferdaus, Mahdi Abdelguerfi, Elias Loup, Kendall N. Niles, Ken Pathak, and Steven Sloan. 2026. Towards trustworthy AI: a review of ethical and robust large language models.Comput. Surveys58, 7 (2026), 1–43
2026
-
[12]
Gaber, M
F. Gaber, M. Shaik, F. Allega, A. J. Bilecz, F. Busch, K. Goon, and A. Akalin. 2025. Evaluating large language model workflows in clinical decision support for triage and referral and diagnosis.npj Digital Medicine8, 1 (2025), 263
2025
-
[13]
Yidong Gan, Maciej Rybinski, Ben Hachey, and Jonathan K. Kummerfeld. 2025. Aligning AI Research with the Needs of Clinical Coding Workflows: Eight Recommendations Based on US Data Analysis and Critical Review. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Li...
-
[14]
Shang Gao, Mohammed Alawad, M Todd Young, John Gounley, Noah Schaefferkoetter, Hong Jun Yoon, Xiao-Cheng Wu, Eric B Durbin, Jennifer Doherty, Antoinette Stroup, et al. 2021. Limitations of transformers on clinical text classification.IEEE journal of biomedical and health informatics 25, 9 (2021), 3596–3607. Manuscript submitted to ACM 30 Ali et al
2021
-
[15]
Edgar Garcia-Lopez, Jamieson O’Marr, Rachel Gottlieb, Katherine Rebecca Miclau, and Nirav Pandya. 2025. Language Barriers in the Delivery of Musculoskeletal Care and Future Directions.Current Reviews in Musculoskeletal Medicine(2025), 1–9
2025
-
[16]
Maxime Griot, Coralie Hemptinne, Jean Vanderdonckt, and Demet Yuksel. 2025. Large Language Models lack essential metacognition for reliable medical reasoning.Nature Communications16, 1 (2025), 642. doi:10.1038/s41467-024-55628-6
-
[17]
Maxime Griot, Jean Vanderdonckt, Demet Yuksel, and Coralie Hemptinne. 2025. Pattern Recognition or Medical Knowledge? The Problem with Multiple-Choice Questions in Medicine. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher P...
-
[18]
Pengcheng He, Jianfeng Gao, Weizhu Chen, and Jason Wang. 2021. mDeBERTa: Efficient Multilingual Pre-trained Model for Low-Resource Languages. InFindings of EMNLP
2021
-
[19]
Hugging Face H4. 2023. Zephyr-7B-Beta: Model Card. https://huggingface.co/HuggingFaceH4/zephyr-7b-beta. Official model card; accessed 2026-05-26
2023
-
[20]
Dipika Jain. 2025. Multilingual and Cross-Linguistic Challenges in NLP. InTransformative Natural Language Processing: Bridging Ambiguity in Healthcare, Legal, and Financial Applications. Springer, 157–177
2025
-
[21]
Shaoxiong Ji, Xiaobo Li, Wei Sun, Hang Dong, Ara Taalas, Yijia Zhang, Honghan Wu, Esa Pitkänen, and Pekka Marttinen. 2024. A Unified Review of Deep Learning for Automated Medical Coding.Comput. Surveys56, 12 (2024), 1–41
2024
-
[22]
Divyanshu Kakwani, Anoop Kunchukuttan, Satish Golla, Gokul N.C., Avik Bhattacharyya, Mitesh M. Khapra, and Pratyush Kumar. 2020. IndicNLP- Suite: Monolingual Corpora, Evaluation Benchmarks and Pre-trained Multilingual Language Models for Indian Languages. InFindings of the Associ- ation for Computational Linguistics: EMNLP 2020. Association for Computatio...
-
[23]
Kyungjin Kim, Jinju Kim, Haeji Jung, David R Mortensen, and Jongmo Seo. 2025. Domain-Specific Multilingual Strategies for Medical NLP: A Cross-Lingual Analysis of Orthographic and Phonemic Representations. In2025 47th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 1–6
2025
-
[24]
Dongchen Li, Jitao Liang, Wei Li, Xiaoyu Wang, Longbing Cao, and Kun Yu. 2026. CliCARE: Grounding Large Language Models in Clinical Guidelines for Decision Support over Longitudinal Cancer Electronic Health Records. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 31554–31562. doi:10.1609/aaai.v40i37.40421
-
[25]
Chen Ling, Xujiang Zhao, Jiaying Lu, Chengyuan Deng, Can Zheng, Junxiang Wang, Tanmoy Chowdhury, Yun Li, Hejie Cui, Xuchao Zhang, et al
-
[26]
Surveys58, 3 (2025), 1–39
Domain specialization as the key to make large language models disruptive: A comprehensive survey.Comput. Surveys58, 3 (2025), 1–39
2025
-
[27]
Mistral AI. 2023. Mistral-7B-Instruct-v0.2. https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2. Official model card; accessed 2026-05-26
2023
-
[28]
Mark A Musen, Blackford Middleton, and Robert A Greenes. 2021. Clinical decision-support systems. InBiomedical informatics: computer applications in health care and biomedicine. Springer, 795–840
2021
-
[29]
Muhammad Kashif Nazir, CM Nadeem Faisal, Muhammad Asif Habib, and Haseeb Ahmad. 2025. Leveraging multilingual transformer for multiclass sentiment analysis in code-mixed data of low-resource languages.IEEE Access(2025)
2025
-
[30]
Riccardo Nogaroli. 2025. Ethical and Legal Aspects of Artificial Intelligence (AI) in Medical Service Contracts. InMedical Liability and Artificial Intelligence. Springer
2025
- [31]
-
[32]
Yu Qiao, Phuong-Nam Tran, Ji Su Yoon, Loc X Nguyen, Eui-Nam Huh, Dusit Niyato, and Choong Seon Hong. 2025. Deepseek-inspired exploration of rl-based llms and synergy with wireless networks: A survey.Comput. Surveys58, 7 (2025), 1–37
2025
-
[33]
Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2024. Towards building multilingual language model for medicine.Nature Communications15, 1 (2024), 8384
2024
-
[34]
Lisa Raithel, Johann Frei, Philippe Thomas, Roland Roller, Pierre Zweigenbaum, Sebastian Möller, and Frank Kramer. 2025. Cross-& multi-lingual medication detection: a transformer-based analysis.BMC Medical Informatics and Decision Making25, 1 (2025), 359
2025
-
[35]
Tizabi, Michael Baumgartner, Maximilian Eisenmann, et al
Annika Reinke, Mohammad D. Tizabi, Michael Baumgartner, Maximilian Eisenmann, et al. 2024. Understanding metric-related pitfalls in image analysis validation.Nature(2024)
2024
-
[36]
Morley, and Luis Filipe Nakayama
David Restrepo, Chenwei Wu, Zhengxu Tang, Zitao Shuai, Thao Nguyen Minh Phan, Jun-En Ding, Cong-Tinh Dao, Jack Gallifant, Robyn Gayle Dychiao, Jose Carlo Artiaga, André Hiroshi Bando, Carolina Pelegrini Barbosa Gracitelli, Vincenz Ferrer, Leo Anthony Celi, Danielle Bitter- man, Michael G. Morley, and Luis Filipe Nakayama. 2025. Multi-OphthaLingua: A Multi...
-
[37]
Daniel Philip Rose, Chia-Chien Hung, Marco Lepri, Israa Alqassem, Kiril Gashteovski, and Carolin Lawrence. 2025. MEDDxAgent: A Unified Modular Agent Framework for Explainable Automatic Differential Diagnosis. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Lin...
-
[38]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[39]
Harman Singh, Nitish Gupta, Shikhar Bharadwaj, Dinesh Tewari, and Partha Talukdar. 2024. IndicGenBench: A Multilingual Benchmark to Evaluate Generation Capabilities of LLMs on Indic Languages. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Bangko...
-
[40]
Sauhard Soni and S Lalitha. 2025. Effective Multilingual and Mixed-lingual DSR System for Healthcare Application in Indian Languages.Procedia Computer Science258 (2025), 1219–1231
2025
-
[41]
Joshua Strong, Qianhui Men, and J. Alison Noble. 2025. Trustworthy and Practical AI for Healthcare: A Guided Deferral System with Large Language Models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 28413–28421. doi:10.1609/aaai.v39i27.35063
-
[42]
Jeffrey Thompson, Jinxiang Hu, Dinesh Pal Mudaranthakam, David Streeter, Lisa Neums, Michele Park, Devin C Koestler, Byron Gajewski, Roy Jensen, and Matthew S Mayo. 2019. Relevant word order vectorization for improved natural language processing in electronic health records. Scientific reports9, 1 (2019), 9253
2019
-
[43]
Fabián Villena, Felipe Bravo-Marquez, and Jocelyn Dunstan. 2025. NLP modeling recommendations for restricted data availability in clinical settings. BMC Medical Informatics and Decision Making25, 1 (2025), 116
2025
-
[44]
Xintong Wu, Yu Huang, and Qing He. 2025. A large language model improves clinicians’ diagnostic performance in complex critical illness cases. Critical Care29, 1 (2025), 230
2025
-
[45]
Xiechi Zhang, Zetian Ouyang, Linlin Wang, Gerard De Melo, Zhu Cao, Xiaoling Wang, Ya Zhang, Yanfeng Wang, and Liang He. 2025. AutoMedEval: Harnessing Language Models for Automatic Medical Capability Evaluation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational L...
-
[46]
Ke Zou, Yang Bai, Bo Liu, Yidi Chen, Zhihao Chen, Yang Zhou, Xuedong Yuan, Meng Wang, Xiaojing Shen, Xiaochun Cao, et al. 2025. Uncertainty- aware medical diagnostic phrase identification and grounding.IEEE Transactions on Pattern Analysis and Machine Intelligence(2025). Manuscript submitted to ACM
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.