Preference-Aware Rubric Learning for Personalized Evaluation
Pith reviewed 2026-06-28 22:21 UTC · model grok-4.3
The pith
A learning approach extracts evaluation rubrics from user interaction histories to judge how well LLM outputs match individual preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
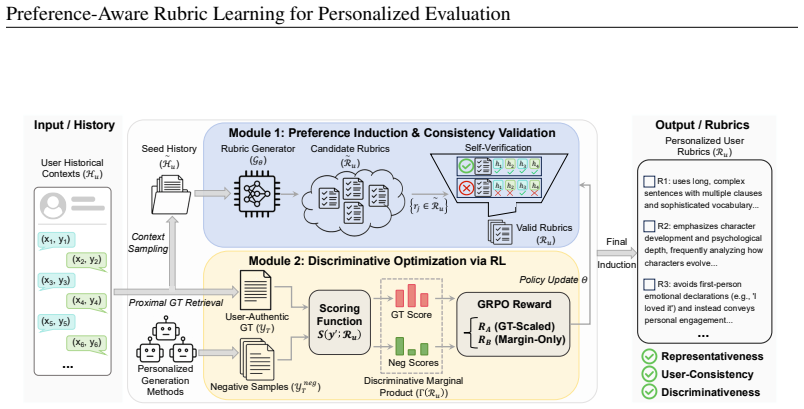
The paper establishes that preference-aware rubrics can be induced directly from raw user histories by combining rubric induction with a discriminative reinforcement learning objective that contrasts user-authored responses against competitive personalized model outputs, together with a self-validation mechanism that enforces consistency with the user's demonstrated preferences.
What carries the argument
Rubric induction paired with a discriminative reinforcement learning objective that learns user-specific decision boundaries from history data.
If this is right
- The induced rubrics identify user-aligned responses with high fidelity on real-world text generation tasks.
- Rubrics learned this way generalize across different users and across tasks.
- The rubrics capture stable stylistic preferences as well as fine-grained evaluative patterns.
- Self-validation during learning removes the need for external human judgment to confirm rubric quality.
Where Pith is reading between the lines
- Rubrics produced this way could serve as training signals to fine-tune models toward a specific user's demonstrated standards.
- The same induction process might apply to multi-turn dialogue or non-text outputs if histories of those forms are available.
- Internal validation could reduce reliance on crowdsourced preference data for building evaluation systems.
Load-bearing premise
User interaction histories contain stable, learnable preferences that rubrics can capture and validate through internal consistency alone.
What would settle it
An experiment in which rubrics induced on one set of user histories assign lower scores to the same user's new responses than to competing model outputs on held-out interactions.
Figures


read the original abstract
As Large Language Models (LLMs) evolve from general-purpose assistants to user-centric agents, personalization has become central to aligning model behavior with individual preferences, making the evaluation of personalized alignment a critical bottleneck. Existing evaluation methods-ranging from automatic metrics to LLM-as-a-judge approaches-fail to capture subjective, user-specific preferences embedded in long-term interaction histories. We identify three essential principles for reliable and effective personalized evaluation: Representativeness, User-Consistency, and Discriminativeness. To address these principles, we introduce Personalized Evaluation as Learning, a paradigm that formulates personalized evaluation as a learning problem rather than a static judgment. Under this paradigm, we propose PARL (Preference-Aware Rubric Learning for Personalized Evaluation), a framework that learns to induce preference-aware evaluation rubrics directly from raw user histories and performs a self-validation mechanism to ensure consistency with the user's preferences. PARL integrates rubric induction with a discriminative reinforcement learning objective that contrasts user-authored responses against competitive personalized model outputs, enabling the learned rubrics to capture precise, user-specific decision boundaries. Experiments on real-world personalized text generation tasks show that PARL consistently induces high-fidelity rubrics that reliably identify user-aligned responses and generalize across users and tasks, while capturing stable stylistic preferences and fine-grained evaluative patterns. To ensure reproducibility, our code is available at https://github.com/SnowCharmQ/PARL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PARL (Preference-Aware Rubric Learning), a framework under the 'Personalized Evaluation as Learning' paradigm. It learns evaluation rubrics directly from raw user interaction histories via rubric induction combined with a discriminative reinforcement learning objective that contrasts user-authored responses against competitive model outputs. A self-validation step is included to enforce consistency with user preferences. The central claim is that experiments on real-world personalized text generation tasks show PARL produces high-fidelity rubrics that reliably identify user-aligned responses, generalize across users and tasks, and capture stable stylistic and evaluative patterns. Code is released for reproducibility.
Significance. If the results can be substantiated with non-circular validation, the work would meaningfully advance personalized LLM evaluation by shifting from static or generic judges to learned, user-specific rubrics grounded in interaction histories. The release of code at https://github.com/SnowCharmQ/PARL is a positive contribution to reproducibility.
major comments (2)
- [Abstract] Abstract: The claim that 'Experiments on real-world personalized text generation tasks show that PARL consistently induces high-fidelity rubrics that reliably identify user-aligned responses and generalize across users and tasks' is presented without any quantitative metrics, baselines, error analysis, or statistical tests. This absence makes it impossible to evaluate the strength or reliability of the reported experimental success.
- [Abstract] Abstract (self-validation mechanism): The self-validation is described as ensuring consistency with the user's preferences, yet both rubric induction and validation operate on the same raw user histories without reference to held-out interactions, external human judgments, or independent benchmarks. This setup risks circularity, where reported fidelity and generalization may reflect fitting to training patterns rather than capturing stable, transferable preferences (particularly given the discriminative RL objective contrasting user responses against model outputs).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'Experiments on real-world personalized text generation tasks show that PARL consistently induces high-fidelity rubrics that reliably identify user-aligned responses and generalize across users and tasks' is presented without any quantitative metrics, baselines, error analysis, or statistical tests. This absence makes it impossible to evaluate the strength or reliability of the reported experimental success.
Authors: We agree that the abstract is a high-level summary and does not include specific quantitative details. The body of the manuscript contains the full experimental results with metrics, baselines, error analyses, and statistical tests. We will revise the abstract to incorporate key quantitative highlights from the experiments. revision: yes
-
Referee: [Abstract] Abstract (self-validation mechanism): The self-validation is described as ensuring consistency with the user's preferences, yet both rubric induction and validation operate on the same raw user histories without reference to held-out interactions, external human judgments, or independent benchmarks. This setup risks circularity, where reported fidelity and generalization may reflect fitting to training patterns rather than capturing stable, transferable preferences (particularly given the discriminative RL objective contrasting user responses against model outputs).
Authors: We acknowledge the risk of circularity when both induction and validation draw from the same user histories. The design intentionally learns from raw interaction data, with the discriminative RL objective providing contrast against competitive model outputs to define user-specific boundaries rather than simple pattern fitting. Cross-user and cross-task generalization experiments provide evidence of stability. We will add an explicit discussion of this limitation and design rationale in the revised manuscript. revision: partial
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
-
[2]
Longformer: The long-document transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150,
Pith/arXiv arXiv 2004
-
[3]
PAL: sample-efficient personalized reward modeling for pluralistic alignment
Daiwei Chen, Yi Chen, Aniket Rege, Zhi Wang, and Ramya Korlakai Vinayak. PAL: sample-efficient personalized reward modeling for pluralistic alignment. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, 2025a. Jin Chen, Zheng Liu, Xu Huang, Chenwang Wu, Qi Liu, Gangwei Jiang, Yuanhao Pu, Yuxuan Lei, Xiaolong Chen, Xingmei Wan...
2025
-
[4]
PAD: personalized alignment of llms at decoding-time
Ruizhe Chen, Xiaotian Zhang, Meng Luo, Wenhao Chai, and Zuozhu Liu. PAD: personalized alignment of llms at decoding-time. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, 2025b. Yuxin Chen, Yu Wang, Yi Zhang, Ziang Ye, Zhengzhou Cai, Yaorui Shi, Qi Gu, Hui Su, Xunliang Cai, Xiang Wang, et al. Learning to self-verify makes ...
arXiv 2025
-
[5]
Xiao Fu, Hossein A Rahmani, Bin Wu, Jerome Ramos, Emine Yilmaz, and Aldo Lipani. Pref: Reference-free evaluation of personalised text generation in llms.arXiv preprint arXiv:2508.10028,
-
[6]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025a. 12 Preference-Aware Rubric Learning for Personalized Evaluation Zhiliang Guo, Teng Tu, Yunshan Ma, and Xun Y...
-
[7]
Llm2rec: Large language models are powerful embedding models for sequential recommendation
Yingzhi He, Xiaohao Liu, An Zhang, Yunshan Ma, and Tat-Seng Chua. Llm2rec: Large language models are powerful embedding models for sequential recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, V .2, KDD 2025, pp. 896–907. ACM,
2025
-
[8]
Yihan Hong, Huaiyuan Yao, Bolin Shen, Wanpeng Xu, Hua Wei, and Yushun Dong. Rulers: Locked rubrics and evidence-anchored scoring for robust llm evaluation.arXiv preprint arXiv:2601.08654,
-
[9]
Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952,
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952,
-
[10]
Joel Jang, Seungone Kim, Bill Yuchen Lin, Yizhong Wang, Jack Hessel, Luke Zettlemoyer, Hannaneh Hajishirzi, Yejin Choi, and Prithviraj Ammanabrolu. Personalized soups: Personalized large language model alignment via post-hoc parameter merging.arXiv preprint arXiv:2310.11564,
-
[11]
Tagging the thought: Unlocking personalization reasoning via reinforcement learning
Song Jin, Juntian Zhang, Yong Liu, Xun Zhang, Yufei Zhang, Fei Jiang, Guojun Yin, Wei Lin, and Rui Yan. Tagging the thought: Unlocking personalization reasoning via reinforcement learning. arXiv preprint arXiv:2509.23140,
-
[12]
Prometheus: Inducing fine- grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Choi, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: Inducing fine- grained evaluation capability in language models. InThe Twelfth International Conference on Learning Representations, ICLR 2024,
2024
-
[13]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun (eds.),3rd International Conference on Learning Representations, ICLR 2015, Conference Track Proceedings,
2015
-
[14]
Longlamp: A benchmark for personalized long-form text generation.arXiv preprint arXiv:2407.11016,
Ishita Kumar, Snigdha Viswanathan, Sushrita Yerra, Alireza Salemi, Ryan A Rossi, Franck Dernon- court, Hanieh Deilamsalehy, Xiang Chen, Ruiyi Zhang, Shubham Agarwal, et al. Longlamp: A benchmark for personalized long-form text generation.arXiv preprint arXiv:2407.11016,
-
[15]
Learning to rewrite prompts for personalized text generation
Cheng Li, Mingyang Zhang, Qiaozhu Mei, Weize Kong, and Michael Bendersky. Learning to rewrite prompts for personalized text generation. InProceedings of the ACM Web Conference 2024, pp. 3367–3378,
2024
-
[16]
Exploring personalization shifts in representation space of llms
Jiahong Liu, Wenhao Yu, Quanyu Dai, Zhongyang Li, Jieming Zhu, Menglin Yang, Tat-Seng Chua, and Irwin King. Exploring personalization shifts in representation space of llms. InKnowledgeable Foundation Models at ACL 2025, 2025a. 13 Preference-Aware Rubric Learning for Personalized Evaluation Tianci Liu, Ran Xu, Tony Yu, Ilgee Hong, Carl Yang, Tuo Zhao, and...
arXiv 2025
-
[17]
Sichun Luo, Guanzhi Deng, Jian Xu, Xiaojie Zhang, Hanxu Hou, and Linqi Song. Reasoning meets personalization: Unleashing the potential of large reasoning model for personalized generation. arXiv preprint arXiv:2505.17571,
-
[18]
News category dataset.arXiv preprint arXiv:2209.11429,
Rishabh Misra. News category dataset.arXiv preprint arXiv:2209.11429,
-
[19]
Rubric is all you need: Improving llm-based code evaluation with question-specific rubrics
Aditya Pathak, Rachit Gandhi, Vaibhav Uttam, Arnav Ramamoorthy, Pratyush Ghosh, Aaryan Raj Jindal, Shreyash Verma, Aditya Mittal, Aashna Ased, Chirag Khatri, et al. Rubric is all you need: Improving llm-based code evaluation with question-specific rubrics. InProceedings of the 2025 ACM Conference on International Computing Education Research V . 1, pp. 181–195,
2025
-
[20]
Personalizing reinforcement learning from human feedback with variational preference learning
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, and Natasha Jaques. Personalizing reinforcement learning from human feedback with variational preference learning. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024,
2024
-
[21]
Latent inter-user difference modeling for LLM personalization
Yilun Qiu, Tianhao Shi, Xiaoyan Zhao, Fengbin Zhu, Yang Zhang, and Fuli Feng. Latent inter-user difference modeling for LLM personalization. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 10610–10628, 2025a. Yilun Qiu, Xiaoyan Zhao, Yang Zhang, Yimeng Bai, Wenjie Wang, Hong Cheng, Fuli Feng, and Tat-Seng Chua...
arXiv 2025
-
[22]
LaMP-QA: A benchmark for personalized long-form question answering
Alireza Salemi and Hamed Zamani. LaMP-QA: A benchmark for personalized long-form question answering. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 1139–1159,
2025
-
[23]
ExPerT: Effective and explainable evaluation of personalized long-form text generation
Alireza Salemi, Julian Killingback, and Hamed Zamani. ExPerT: Effective and explainable evaluation of personalized long-form text generation. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 17516–17532, 2025a. 14 Preference-Aware Rubric Learning for Personalized Evaluation Alireza Salemi, Cheng Li, Mingyang Zhang, Qiaozhu Mei, W...
arXiv 2025
-
[24]
MiCRo: Mixture modeling and context-aware routing for personalized preference learning
Jingyan Shen, Jiarui Yao, Rui Yang, Yifan Sun, Feng Luo, Rui Pan, Tong Zhang, and Han Zhao. MiCRo: Mixture modeling and context-aware routing for personalized preference learning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 17458–17474,
2025
-
[25]
Hybridflow: A flexible and efficient RLHF framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient RLHF framework. InProceedings of the Twentieth European Conference on Computer Systems, EuroSys 2025, pp. 1279–1297,
2025
-
[26]
Democratizing large language models via personalized parameter-efficient fine-tuning
Zhaoxuan Tan, Qingkai Zeng, Yijun Tian, Zheyuan Liu, Bing Yin, and Meng Jiang. Democratizing large language models via personalized parameter-efficient fine-tuning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 6476–6491,
2024
-
[27]
Chengbing Wang, Yang Zhang, Wenjie Wang, Xiaoyan Zhao, Fuli Feng, Xiangnan He, and Tat-Seng Chua. Think-while-generating: On-the-fly reasoning for personalized long-form generation.arXiv preprint arXiv:2512.06690,
-
[28]
Automated evaluation of personalized text generation using large language models
Yaqing Wang, Jiepu Jiang, Mingyang Zhang, Cheng Li, Yi Liang, Qiaozhu Mei, and Michael Bendersky. Automated evaluation of personalized text generation using large language models. arXiv preprint arXiv:2310.11593,
-
[29]
Zhouhang Xie, Junda Wu, Yiran Shen, Yu Xia, Xintong Li, Aaron Chang, Ryan Rossi, Sachin Kumar, Bodhisattwa Prasad Majumder, Jingbo Shang, et al. A survey on personalized and pluralistic preference alignment in large language models.arXiv preprint arXiv:2504.07070,
-
[30]
Per- sonalized image generation with large multimodal models
Yiyan Xu, Wenjie Wang, Yang Zhang, Biao Tang, Peng Yan, Fuli Feng, and Xiangnan He. Per- sonalized image generation with large multimodal models. InProceedings of the ACM on Web Conference 2025, pp. 264–274, 2025a. Yiyan Xu, Jinghao Zhang, Alireza Salemi, Xinting Hu, Wenjie Wang, Fuli Feng, Hamed Zamani, Xiangnan He, and Tat-Seng Chua. Personalized genera...
Pith/arXiv arXiv 2025
-
[31]
Bartscore: Evaluating generated text as text generation
Weizhe Yuan, Graham Neubig, and Pengfei Liu. Bartscore: Evaluating generated text as text generation. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan (eds.),Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, pp. 27263–27277,
2021
-
[32]
Prlm: Learning explicit reasoning for personalized rag via contrastive reward optimization
Kepu Zhang, Teng Shi, Weijie Yu, and Jun Xu. Prlm: Learning explicit reasoning for personalized rag via contrastive reward optimization. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pp. 5484–5488, 2025a. 15 Preference-Aware Rubric Learning for Personalized Evaluation Pinyi Zhang, Ting-En Lin, Yuchuan Wu, ...
arXiv 2020
-
[33]
Yang Zhang, Juntao You, Yimeng Bai, Jizhi Zhang, Keqin Bao, Wenjie Wang, and Tat-Seng Chua. Causality-enhanced behavior sequence modeling in llms for personalized recommendation.arXiv preprint arXiv:2410.22809, 2024a. Yang Zhang, Fuli Feng, Jizhi Zhang, Keqin Bao, Qifan Wang, and Xiangnan He. Collm: Integrating collaborative embeddings into large language...
arXiv 2025
-
[34]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, ...
2023
-
[35]
HYDRA: model factorization framework for black-box LLM personalization
Yuchen Zhuang, Haotian Sun, Yue Yu, Rushi Qiang, Qifan Wang, Chao Zhang, and Bo Dai. HYDRA: model factorization framework for black-box LLM personalization. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024,
2024
-
[36]
16 Preference-Aware Rubric Learning for Personalized Evaluation A LIMITATIONS The effectiveness of our rubric generator depends heavily on the quality and quantity of available user behavioral history. In cold-start scenarios, where historical signals are sparse, the model may struggle to induce sufficiently detailed and stable criteria, constraining its ...
2024
-
[37]
tagging the thought
D BASELINEDETAILS In this section, we provide more detailed descriptions of baselines benchmarked by PARL. To comprehensively evaluate the effectiveness and robustness of our framework, we extend our analysis beyond methods featured in Section 5.1 to include a broader suite of competitive baselines. These methods are categorized into four paradigms: ICL (...
2024
-
[38]
Training is conducted with a batch size of 8, a maximum prompt length of 10240 tokens, and a maximum response length of 2048 tokens
optimization objective. Training is conducted with a batch size of 8, a maximum prompt length of 10240 tokens, and a maximum response length of 2048 tokens. Optimization is carried out using Adam (Kingma & Ba,
2048
-
[39]
For rubric generation, we adopt the same vLLM-based deployment configuration
with nucleus sampling (p= 0.95 ), temperature 0.6, and top-k sampling (k= 20 ), producing 5 samples per prompt. For rubric generation, we adopt the same vLLM-based deployment configuration. The selected baselines for computingDiscriminative Margin Productinclude:Non,RAG,SFT,GRPO, SFT+GRPO. 19 Preference-Aware Rubric Learning for Personalized Evaluation Ta...
2025
-
[40]
Beyond absolute accuracy, PARL demonstrates robust discriminative power, effectively establishing a clear evaluative margin between GT and competitive baselines
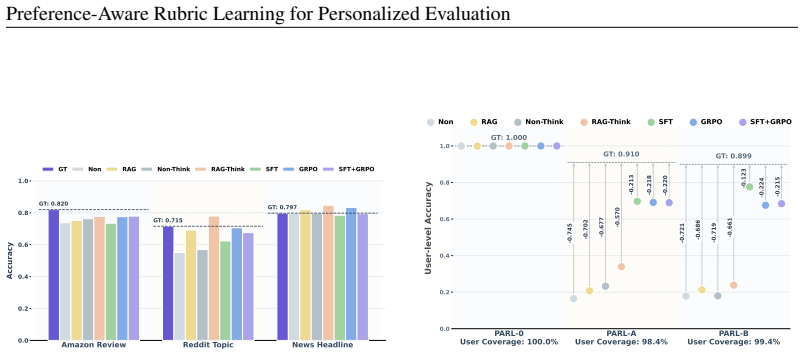
Our framework, PARL, consistently ensures that authentic user-authored GT responses achieve the highestrubric-level accuracyacross all three personalized text generation tasks. Beyond absolute accuracy, PARL demonstrates robust discriminative power, effectively establishing a clear evaluative margin between GT and competitive baselines. These results conf...
2004
-
[41]
As shown in Table 16, Table 17, and Table 18, we also provide prompts used in the comparison LLM-as-a-judge experiments in Section??for reference. 22 Preference-Aware Rubric Learning for Personalized Evaluation Table 7: Detailed evaluation results of induced rubrics across three personalized text generation tasks onuser-level accuracy. Amazon ReviewLM-8B ...
arXiv 1918
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.