Learning Global Motion with Compact Gaussians for Feed-Forward 4D Reconstruction
Pith reviewed 2026-06-28 23:06 UTC · model grok-4.3
The pith
Timestamp-conditioned Gaussian query tokens aggregate temporal features to decode coherent 4D motion from monocular video in a feed-forward manner.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
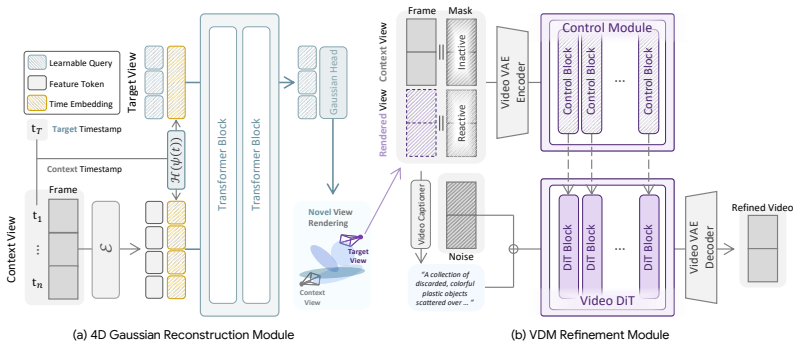
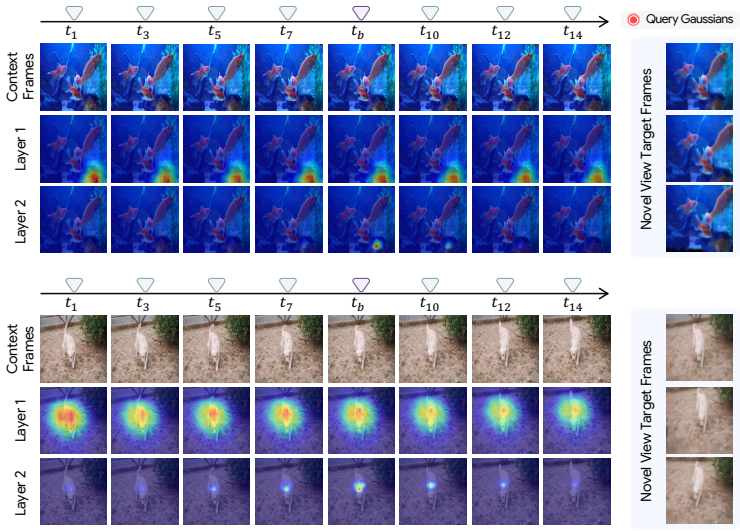
C4G uses a compact collection of timestamp-conditioned learnable Gaussian query tokens; each token aggregates matching features across the entire temporal context and decodes one 3D Gaussian whose 3D position is modulated by the query timestamp, producing globally coherent motion without per-scene optimization or duplicated primitives.
What carries the argument
timestamp-conditioned learnable Gaussian query tokens that aggregate full-sequence features and decode timestamp-modulated 3D Gaussians
If this is right
- Novel-view synthesis is achieved with far fewer Gaussians than per-frame methods.
- Reconstruction proceeds without any camera-pose input or per-scene optimization.
- Motion remains coherent even across large temporal separations.
- The same token aggregation produces a 4D feature field usable for point tracking.
- A separate diffusion renderer can be attached to restore high-frequency detail after the core field is built.
Where Pith is reading between the lines
- The token design could be tested on longer sequences to check whether global coherence scales without additional regularization.
- Replacing the diffusion enhancement with a lighter decoder might reveal how much of the quality gain comes from the Gaussian field alone.
- The 4D feature field might support downstream tasks such as action recognition or future-frame prediction if the tokens are kept frozen after training.
Load-bearing premise
The tokens can reliably collect corresponding features from every frame in the video to produce motion that stays consistent across large time gaps without duplication or viewpoint bias.
What would settle it
Apply the method to a monocular video containing sudden large object displacements or long occlusions and measure whether novel-view renderings at distant timestamps show duplicated surfaces or broken trajectories.
Figures




read the original abstract
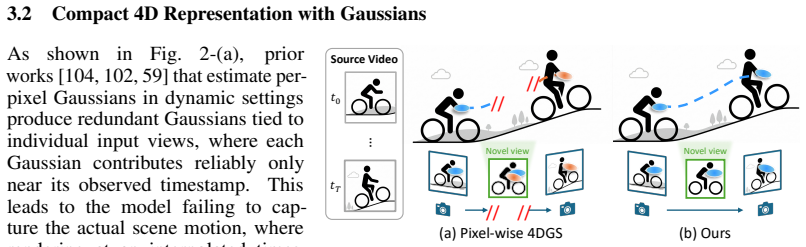
Dynamic scene reconstruction from monocular video remains a fundamental challenge in computer vision. Existing feed-forward methods predict 3D Gaussians pixel-wise for each frame, suffering from duplicated Gaussians and view-dependent biases that hinder effective learning of scene motion. We present C4G, a feed-forward 4D reconstruction framework built upon a compact set of timestamp-conditioned learnable Gaussian query tokens. Each token aggregates corresponding features across the full temporal context and decodes a 3D Gaussian whose position is modulated by the target timestamp, enabling globally coherent motion modeling without per-scene optimization. To capture fine-grained details, we further introduce a video diffusion model-based rendering enhancement module. Since our framework effectively aggregates features into Gaussians, we extend this capability to feature lifting, producing a 4D feature field that supports point tracking and dynamic scene understanding. C4G achieves strong novel-view synthesis performance using significantly fewer Gaussians and without requiring camera poses, while exhibiting stronger motion modeling and robustness to large temporal gaps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces C4G, a feed-forward 4D reconstruction method for dynamic scenes from monocular video. It replaces per-frame pixel-wise Gaussian prediction with a compact set of timestamp-conditioned learnable Gaussian query tokens. Each token aggregates features across the full temporal context and decodes a 3D Gaussian whose position is modulated by the target timestamp. A video diffusion model is added for rendering enhancement, and the same aggregation is extended to produce a 4D feature field supporting point tracking. The central claims are that this yields strong novel-view synthesis with far fewer Gaussians, requires no camera poses or per-scene optimization, improves motion modeling, and is robust to large temporal gaps.
Significance. If the architecture and empirical claims hold, the work would be significant for enabling efficient, pose-free feed-forward 4D reconstruction. The use of learnable query tokens to enforce global temporal coherence without duplication or view-dependent bias, together with the extension to a 4D feature field, addresses a recognized limitation of current Gaussian-based dynamic methods. The absence of per-scene optimization and the reported robustness to large time gaps would be practically valuable if substantiated.
major comments (2)
- [Abstract] Abstract (framework paragraph): the claim that timestamp-conditioned learnable Gaussian query tokens 'aggregate corresponding features across the full temporal context' and thereby avoid duplicated Gaussians and view-dependent biases is presented without any equation, architecture diagram, loss term, or correspondence mechanism. This is the load-bearing assumption for the entire method; without it the performance claims cannot be evaluated.
- [Abstract] Abstract: no training procedure, loss formulation, or evaluation protocol is supplied. The reported gains in novel-view synthesis, motion modeling, and robustness to temporal gaps therefore rest on unspecified implementation details, making it impossible to determine whether the architecture itself produces the stated improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for clearer presentation of key claims in the abstract. The detailed mechanisms, training, and evaluation are fully specified in the manuscript body (Sections 3–5), but we agree the abstract can be revised for better self-containment. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (framework paragraph): the claim that timestamp-conditioned learnable Gaussian query tokens 'aggregate corresponding features across the full temporal context' and thereby avoid duplicated Gaussians and view-dependent biases is presented without any equation, architecture diagram, loss term, or correspondence mechanism. This is the load-bearing assumption for the entire method; without it the performance claims cannot be evaluated.
Authors: The aggregation is realized via cross-attention between the compact learnable query tokens and multi-frame image features, with timestamp embeddings modulating both the queries and the decoded Gaussian positions; this is detailed with equations and a diagram in Section 3.2. No explicit correspondence loss is used—the temporal coherence emerges from end-to-end training on the reconstruction objective. We will revise the abstract to include a concise clause referencing the attention-based temporal aggregation. revision: yes
-
Referee: [Abstract] Abstract: no training procedure, loss formulation, or evaluation protocol is supplied. The reported gains in novel-view synthesis, motion modeling, and robustness to temporal gaps therefore rest on unspecified implementation details, making it impossible to determine whether the architecture itself produces the stated improvements.
Authors: Training uses an end-to-end objective combining L1, SSIM, and perceptual losses on rendered images plus a diffusion rendering loss (Section 4.2); evaluation follows standard novel-view metrics plus point-tracking accuracy on held-out frames (Section 5). The abstract omits these for brevity. We will add one sentence summarizing the training and evaluation protocol if space permits. revision: partial
Circularity Check
No circularity: derivation self-contained with no reductions visible
full rationale
The provided abstract and text describe a feed-forward framework using timestamp-conditioned learnable Gaussian query tokens for feature aggregation and Gaussian decoding, but contain no equations, no fitted parameters presented as predictions, and no self-citations invoked to justify core claims. The central description of aggregation enabling coherent motion is presented as an architectural choice without any self-definitional loop, fitted-input renaming, or load-bearing self-citation chain that would reduce the result to its inputs by construction. This is the normal case of an independent method proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C3G: Learning Compact 3D Representations with 2K Gaussians
An, H., Jung, J., Kim, M., Hong, S., Kim, C., Fukuda, K., Jeon, M., Han, J., Narihira, T., Ko, H., et al.: C3g: Learning compact 3d representations with 2k gaussians. arXiv preprint arXiv:2512.04021 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
An, H., Kim, J.H., Park, S., Jung, J., Han, J., Hong, S., Kim, S.: Cross-view completion models are zero-shot correspondence estimators. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1103–1115 (2025)
2025
-
[3]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y ., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y ., Tan...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Balasingam, A., Chandler, J., Li, C., Zhang, Z., Balakrishnan, H.: Drivetrack: A benchmark for long-range point tracking in real-world videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22488–22497 (2024)
2024
-
[5]
ACM Trans
Bartle, A., Sheffer, A., Kim, V .G., Kaufman, D.M., Vining, N., Berthouzoz, F.: Physics-driven pattern adjustment for direct 3d garment editing. ACM Trans. Graph.35(4), 50–1 (2016)
2016
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bozic, A., Zollhofer, M., Theobalt, C., Nießner, M.: Deepdeform: Learning non-rigid rgb-d reconstruction with semi-supervised data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7002–7012 (2020)
2020
-
[7]
In: Proceedings IEEE Conference on Computer Vision and Pattern Recognition
Bregler, C., Hertzmann, A., Biermann, H.: Recovering non-rigid 3d shape from image streams. In: Proceedings IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No. PR00662). vol. 2, pp. 690–696. IEEE (2000)
2000
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cao, A., Johnson, J.: Hexplane: A fast representation for dynamic scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 130–141 (2023)
2023
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Charatan, D., Li, S.L., Tagliasacchi, A., Sitzmann, V .: pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19457–19467 (2024)
2024
-
[10]
In: European conference on computer vision
Chen, Y ., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.J., Cai, J.: Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. In: European conference on computer vision. pp. 370–386. Springer (2024)
2024
-
[11]
Advances in Neural Information Processing Systems34, 9011–9023 (2021)
Cho, S., Hong, S., Jeon, S., Lee, Y ., Sohn, K., Kim, S.: Cats: Cost aggregation transformers for visual correspondence. Advances in Neural Information Processing Systems34, 9011–9023 (2021)
2021
-
[12]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(6), 7174– 7194 (2022)
Cho, S., Hong, S., Kim, S.: Cats++: Boosting cost aggregation with convolutions and transformers. IEEE Transactions on Pattern Analysis and Machine Intelligence45(6), 7174– 7194 (2022)
2022
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cho, S., Shin, H., Hong, S., Arnab, A., Seo, P.H., Kim, S.: Cat-seg: Cost aggregation for open-vocabulary semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4113–4123 (2024)
2024
-
[14]
International Journal of Computer Vision107(2), 101–122 (2014)
Dai, Y ., Li, H., He, M.: A simple prior-free method for non-rigid structure-from-motion factorization. International Journal of Computer Vision107(2), 101–122 (2014)
2014
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deng, K., Liu, A., Zhu, J.Y ., Ramanan, D.: Depth-supervised nerf: Fewer views and faster training for free. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12882–12891 (2022) 10
2022
-
[16]
Advances in Neural Information Processing Systems35, 13610–13626 (2022)
Doersch, C., Gupta, A., Markeeva, L., Recasens, A., Smaira, L., Aytar, Y ., Carreira, J., Zisserman, A., Yang, Y .: Tap-vid: A benchmark for tracking any point in a video. Advances in Neural Information Processing Systems35, 13610–13626 (2022)
2022
-
[17]
In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV)
Du, Y ., Zhang, Y ., Yu, H.X., Tenenbaum, J.B., Wu, J.: Neural radiance flow for 4d view synthesis and video processing. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 14304–14314. IEEE Computer Society (2021)
2021
-
[18]
Advances in neural information processing systems37, 40212–40229 (2024)
Fan, Z., Zhang, J., Cong, W., Wang, P., Li, R., Wen, K., Zhou, S., Kadambi, A., Wang, Z., Xu, D., et al.: Large spatial model: End-to-end unposed images to semantic 3d. Advances in neural information processing systems37, 40212–40229 (2024)
2024
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fridovich-Keil, S., Meanti, G., Warburg, F.R., Recht, B., Kanazawa, A.: K-planes: Explicit radiance fields in space, time, and appearance. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12479–12488 (2023)
2023
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fridovich-Keil, S., Yu, A., Tancik, M., Chen, Q., Recht, B., Kanazawa, A.: Plenoxels: Radiance fields without neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5501–5510 (2022)
2022
-
[21]
Advances in Neural Information Processing Systems35, 33768–33780 (2022)
Gao, H., Li, R., Tulsiani, S., Russell, B., Kanazawa, A.: Monocular dynamic view synthesis: A reality check. Advances in Neural Information Processing Systems35, 33768–33780 (2022)
2022
-
[22]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Greff, K., Belletti, F., Beyer, L., Doersch, C., Du, Y ., Duckworth, D., Fleet, D.J., Gnanapra- gasam, D., Golemo, F., Herrmann, C., et al.: Kubric: A scalable dataset generator. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3749–3761 (2022)
2022
-
[23]
arXiv e-prints pp
Han, J., An, H., Jung, J., Narihira, T., Seo, J., Fukuda, K., Kim, C., Hong, S., Mitsufuji, Y ., Kim, S.: Dˆ 2ust3r: Enhancing 3d reconstruction with 4d pointmaps for dynamic scenes. arXiv e-prints pp. arXiv–2504 (2025)
2025
-
[24]
Han, J., Hong, S., Jung, J., Jang, W., An, H., Wang, Q., Kim, S., Feng, C.: Emergent outlier view rejection in visual geometry grounded transformers. arXiv preprint arXiv:2512.04012 (2025)
-
[25]
arXiv preprint arXiv:2209.08742 (2022)
Hong, S., Cho, S., Kim, S., Lin, S.: Integrative feature and cost aggregation with transformers for dense correspondence. arXiv preprint arXiv:2209.08742 (2022)
-
[26]
arXiv preprint arXiv:2410.22128 (2024)
Hong, S., Jung, J., Shin, H., Han, J., Yang, J., Luo, C., Kim, S.: Pf3plat: Pose-free feed-forward 3d gaussian splatting. arXiv preprint arXiv:2410.22128 (2024)
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hong, S., Jung, J., Shin, H., Yang, J., Kim, S., Luo, C.: Unifying correspondence pose and nerf for generalized pose-free novel view synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20196–20206 (2024)
2024
-
[28]
In: Proceedings of the IEEE/CVF international conference on computer vision
Hong, S., Kim, S.: Deep matching prior: Test-time optimization for dense correspondence. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9907–9917 (2021)
2021
-
[29]
Advances in Neural Information Processing Systems35, 13512–13526 (2022)
Hong, S., Nam, J., Cho, S., Hong, S., Jeon, S., Min, D., Kim, S.: Neural matching fields: Implicit representation of matching fields for visual correspondence. Advances in Neural Information Processing Systems35, 13512–13526 (2022)
2022
-
[30]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[31]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Huang, R., Mikolajczyk, K.: No pose at all: Self-supervised pose-free 3d gaussian splatting from sparse views. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27947–27957 (2025)
2025
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y ., Yu, J., Zhang, F., Si, C., Jiang, Y ., Zhang, Y ., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024) 11
2024
-
[33]
In: The Fourteenth International Conference on Learning Representations
Hur, J., Herrmann, C., Peng, S., Henzler, P., Ma, Z., Zickler, T., Sun, D.: Ufo-4d: Unposed feedforward 4d reconstruction from two images. In: The Fourteenth International Conference on Learning Representations
-
[34]
In: European conference on computer vision
Innmann, M., Zollhöfer, M., Nießner, M., Theobalt, C., Stamminger, M.: V olumedeform: Real-time volumetric non-rigid reconstruction. In: European conference on computer vision. pp. 362–379. Springer (2016)
2016
-
[35]
arXiv preprint arXiv:2407.04504 (2024)
Ji, S., Wu, G., Fang, J., Cen, J., Yi, T., Liu, W., Tian, Q., Wang, X.: Segment any 4d gaussians. arXiv preprint arXiv:2407.04504 (2024)
-
[36]
ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
Jiang, L., Mao, Y ., Xu, L., Lu, T., Ren, K., Jin, Y ., Xu, X., Yu, M., Pang, J., Zhao, F., et al.: Anysplat: Feed-forward 3d gaussian splatting from unconstrained views. ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
2025
-
[37]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y ., Liu, Y .: Vace: All-in-one video creation and editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17191–17202 (2025)
2025
-
[38]
In: ICCV 2025 Workshop on Wild 3D: 3D Modeling, Reconstruction, and Generation in the Wild (2023)
Jung, J., Han, J., Kang, J., Kim, S., Kwak, M.S., Kim, S.: Self-evolving neural radiance fields. In: ICCV 2025 Workshop on Wild 3D: 3D Modeling, Reconstruction, and Generation in the Wild (2023)
2025
-
[39]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[40]
Advances in Neural Information Processing Systems38, 71685–71724 (2026)
Kim, C., Shin, H., Hong, E., Yoon, H., Arnab, A., Seo, P.H., Hong, S., Kim, S.: Seg4diff: Unveiling open-vocabulary semantic segmentation in text-to-image diffusion transformers. Advances in Neural Information Processing Systems38, 71685–71724 (2026)
2026
-
[41]
Advances in Neural Information Processing Systems37, 129209–129226 (2024)
Kim, M., Lim, J., Han, B.: 4d gaussian splatting in the wild with uncertainty-aware regulariza- tion. Advances in Neural Information Processing Systems37, 129209–129226 (2024)
2024
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, M., Seo, S., Han, B.: Infonerf: Ray entropy minimization for few-shot neural volume rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12912–12921 (2022)
2022
-
[43]
arXiv preprint arXiv:2512.02006 (2025)
Koo, J., Kim, I.H., Kim, M., Park, J., Park, S., Kim, J., Yi, J., Cho, S., Kim, S.: Mv-tap: Tracking any point in multi-view videos. arXiv preprint arXiv:2512.02006 (2025)
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kopf, J., Rong, X., Huang, J.B.: Robust consistent video depth estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1611–1621 (2021)
2021
-
[45]
In: Proceedings of the IEEE international conference on computer vision
Kumar, S., Dai, Y ., Li, H.: Monocular dense 3d reconstruction of a complex dynamic scene from two perspective frames. In: Proceedings of the IEEE international conference on computer vision. pp. 4649–4657 (2017)
2017
-
[46]
arXiv preprint arXiv:2301.10941 (2023)
Kwak, M.S., Song, J., Kim, S.: Geconerf: Few-shot neural radiance fields via geometric consistency. arXiv preprint arXiv:2301.10941 (2023)
-
[47]
arXiv preprint arXiv:2602.04877 (2026)
Lai, Z., Insafutdinov, E., Sucar, E., Vedaldi, A.: Cowtracker: Tracking by warping instead of correlation. arXiv preprint arXiv:2602.04877 (2026)
-
[48]
In: 5th Annual Conference on Robot Learning (2021)
Lee, A.X., Devin, C.M., Zhou, Y ., Lampe, T., Bousmalis, K., Springenberg, J.T., Byravan, A., Abdolmaleki, A., Gileadi, N., Khosid, D., et al.: Beyond pick-and-place: Tackling robotic stacking of diverse shapes. In: 5th Annual Conference on Robot Learning (2021)
2021
-
[49]
arXiv preprint arXiv:2510.14945 (2025)
Lee, J., Jung, J., Han, J., Narihira, T., Fukuda, K., Seo, J., Hong, S., Mitsufuji, Y ., Kim, S.: 3d scene prompting for scene-consistent camera-controllable video generation. arXiv preprint arXiv:2510.14945 (2025)
-
[50]
TORA: Topological Representation Alignment for 3D Shape Assembly
Lee, N., Chen, Z., Pollefeys, M., Hong, S.: Tora: Topological representation alignment for 3d shape assembly. arXiv preprint arXiv:2604.04050 (2026) 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lei, J., Weng, Y ., Harley, A.W., Guibas, L., Daniilidis, K.: Mosca: Dynamic gaussian fusion from casual videos via 4d motion scaffolds. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6165–6177 (2025)
2025
-
[52]
In: European conference on computer vision
Leroy, V ., Cabon, Y ., Revaud, J.: Grounding image matching in 3d with mast3r. In: European conference on computer vision. pp. 71–91. Springer (2024)
2024
-
[53]
Language-driven Semantic Segmentation
Li, B., Weinberger, K.Q., Belongie, S., Koltun, V ., Ranftl, R.: Language-driven semantic segmentation. arXiv preprint arXiv:2201.03546 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[54]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, J., Zhang, J., Bai, X., Zheng, J., Ning, X., Zhou, J., Gu, L.: Dngaussian: Optimizing sparse-view 3d gaussian radiance fields with global-local depth normalization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20775–20785 (2024)
2024
-
[55]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, Z., Niklaus, S., Snavely, N., Wang, O.: Neural scene flow fields for space-time view synthesis of dynamic scenes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6498–6508 (2021)
2021
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Z., Tucker, R., Cole, F., Wang, Q., Jin, L., Ye, V ., Kanazawa, A., Holynski, A., Snavely, N.: Megasam: Accurate, fast and robust structure and motion from casual dynamic videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10486–10496 (2025)
2025
-
[57]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Z., Wang, Q., Cole, F., Tucker, R., Snavely, N.: Dynibar: Neural dynamic image-based rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4273–4284 (2023)
2023
-
[58]
arXiv preprint arXiv:2412.03526 (2024)
Liang, H., Ren, J., Mirzaei, A., Torralba, A., Liu, Z., Gilitschenski, I., Fidler, S., Oztireli, C., Ling, H., Gojcic, Z., et al.: Feed-forward bullet-time reconstruction of dynamic scenes from monocular videos. arXiv preprint arXiv:2412.03526 (2024)
-
[59]
arXiv preprint arXiv:2507.10065 (2025)
Lin, C., Lin, Y ., Pan, P., Yu, Y ., Yan, H., Fragkiadaki, K., Mu, Y .: Movies: Motion-aware 4d dynamic view synthesis in one second. arXiv preprint arXiv:2507.10065 (2025)
-
[60]
arXiv preprint arXiv:2506.09997 (2025)
Lin, C.H., Lv, Z., Wu, S., Xu, Z., Nguyen-Phuoc, T., Tseng, H.Y ., Straub, J., Khan, N., Xiao, L., Yang, M.H., et al.: Dgs-lrm: Real-time deformable 3d gaussian reconstruction from monocular videos. arXiv preprint arXiv:2506.09997 (2025)
-
[61]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[62]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[63]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lu, J., Huang, T., Li, P., Dou, Z., Lin, C., Cui, Z., Dong, Z., Yeung, S.K., Wang, W., Liu, Y .: Align3r: Aligned monocular depth estimation for dynamic videos. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22820–22830 (2025)
2025
-
[64]
In: 2024 International Conference on 3D Vision (3DV)
Luiten, J., Kopanas, G., Leibe, B., Ramanan, D.: Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. In: 2024 International Conference on 3D Vision (3DV). pp. 800–809. IEEE (2024)
2024
-
[65]
arXiv preprint arXiv:2506.18890 (2025)
Ma, Z., Chen, X., Yu, S., Bi, S., Zhang, K., Ziwen, C., Xu, S., Yang, J., Xu, Z., Sunkavalli, K., et al.: 4d-lrm: Large space-time reconstruction model from and to any view at any time. arXiv preprint arXiv:2506.18890 (2025)
-
[66]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Mehl, L., Schmalfuss, J., Jahedi, A., Nalivayko, Y ., Bruhn, A.: Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4981–4991 (2023)
2023
-
[67]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Miao, S., Huang, J., Bai, D., Yan, X., Zhou, H., Wang, Y ., Liu, B., Geiger, A., Liao, Y .: Evolsplat: Efficient volume-based gaussian splatting for urban view synthesis. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 11286–11296 (2025) 13
2025
-
[68]
Communications of the ACM 65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM 65(1), 99–106 (2021)
2021
-
[69]
R3M: A Universal Visual Representation for Robot Manipulation
Nair, S., Rajeswaran, A., Kumar, V ., Finn, C., Gupta, A.: R3m: A universal visual representa- tion for robot manipulation. arXiv preprint arXiv:2203.12601 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[70]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Newcombe, R.A., Fox, D., Seitz, S.M.: Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 343–352 (2015)
2015
-
[71]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Niemeyer, M., Barron, J.T., Mildenhall, B., Sajjadi, M.S., Geiger, A., Radwan, N.: Regnerf: Regularizing neural radiance fields for view synthesis from sparse inputs. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5480–5490 (2022)
2022
-
[72]
In: Proceedings of the IEEE/CVF international conference on computer vision
Novotny, D., Ravi, N., Graham, B., Neverova, N., Vedaldi, A.: C3dpo: Canonical 3d pose networks for non-rigid structure from motion. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 7688–7697 (2019)
2019
-
[73]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Pan, X., Charron, N., Yang, Y ., Peters, S., Whelan, T., Kong, C., Parkhi, O., Newcombe, R., Ren, Y .C.: Aria digital twin: A new benchmark dataset for egocentric 3d machine perception. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20133– 20143 (2023)
2023
-
[74]
In: Proceedings of the IEEE/CVF international conference on computer vision
Park, K., Sinha, U., Barron, J.T., Bouaziz, S., Goldman, D.B., Seitz, S.M., Martin-Brualla, R.: Nerfies: Deformable neural radiance fields. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5865–5874 (2021)
2021
-
[75]
arXiv preprint arXiv:2106.13228 (2021)
Park, K., Sinha, U., Hedman, P., Barron, J.T., Bouaziz, S., Goldman, D.B., Martin-Brualla, R., Seitz, S.M.: Hypernerf: A higher-dimensional representation for topologically varying neural radiance fields. arXiv preprint arXiv:2106.13228 (2021)
-
[76]
The 2017 DAVIS Challenge on Video Object Segmentation
Pont-Tuset, J., Perazzi, F., Caelles, S., Arbeláez, P., Sorkine-Hornung, A., Van Gool, L.: The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[77]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Pumarola, A., Corona, E., Pons-Moll, G., Moreno-Noguer, F.: D-nerf: Neural radiance fields for dynamic scenes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10318–10327 (2021)
2021
-
[78]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[79]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Ranftl, R., Vineet, V ., Chen, Q., Koltun, V .: Dense monocular depth estimation in complex dynamic scenes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4058–4066 (2016)
2016
-
[80]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Roessle, B., Barron, J.T., Mildenhall, B., Srinivasan, P.P., Nießner, M.: Dense depth priors for neural radiance fields from sparse input views. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12892–12901 (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.