Linear Scaling Video VLMs for Long Video Understanding
Pith reviewed 2026-06-28 22:58 UTC · model grok-4.3
The pith
StateKV replaces quadratic self-attention in video VLMs with a fixed-capacity recurrent state that keeps accuracy close to full attention while enabling linear scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
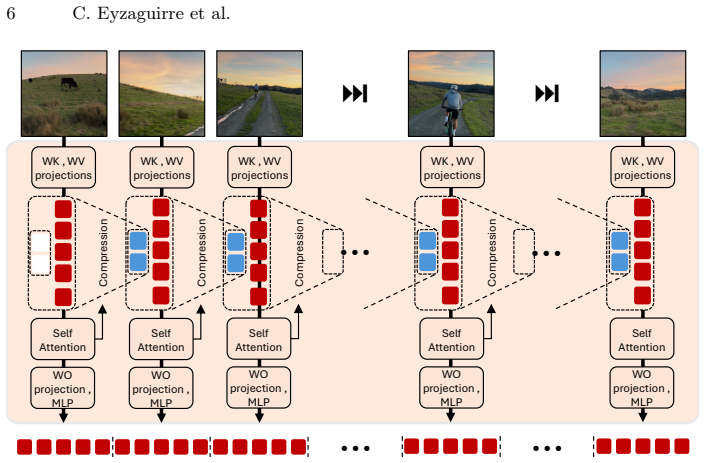
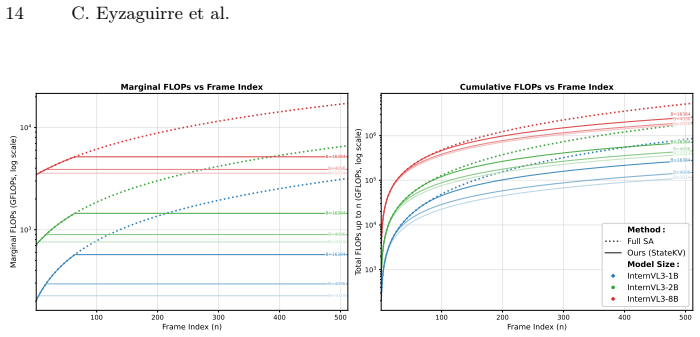
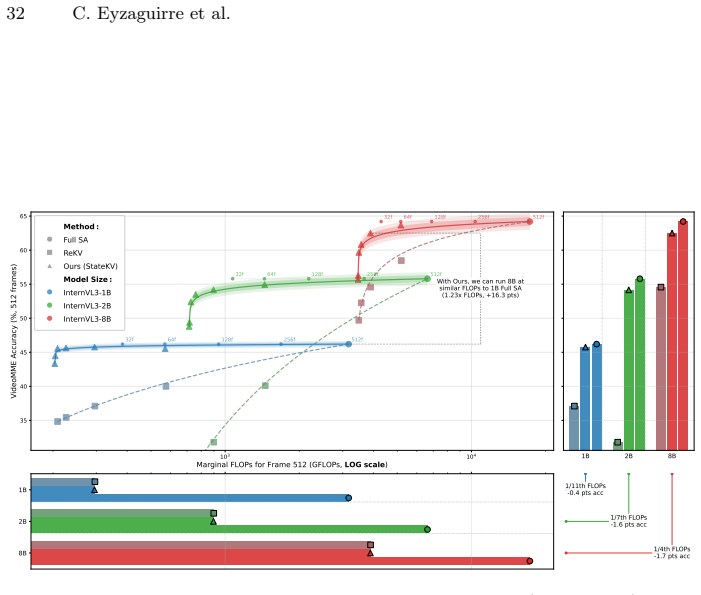
StateKV adapts pretrained video VLMs to linear-time video prefill by carrying cross-frame context in a fixed-capacity, importance-based recurrent state paired with a second full per-frame cache for decoding. Across three long-video benchmarks and seven models spanning three families and multiple scales, StateKV remains close to full self-attention and consistently outperforms dominant sliding-window and recency-based streaming approximations without fine-tuning or architectural changes. It also reduces video-prefill FLOPs, enabling stronger accuracy at a fixed compute budget by running larger models.
What carries the argument
StateKV's importance-based recurrent state of fixed capacity, which selects and retains key tokens to carry cross-frame context linearly across frames while a separate per-frame cache handles decoding.
If this is right
- Video prefill cost measured in FLOPs drops enough to run larger models inside the same compute limit.
- The method applies to existing models across families and scales with no retraining required.
- Accuracy holds on long-horizon and streaming benchmarks where sliding-window approximations degrade.
- Linear scaling supports longer video sequences without quadratic memory growth.
Where Pith is reading between the lines
- The same fixed-capacity state compression could be tested on non-video sequence tasks such as long-document language modeling.
- If the importance selection proves stable, it might allow real-time long-video inference on devices with tight memory budgets.
- Separating the recurrent state from the per-frame cache suggests a template for hybrid attention designs in other multimodal models.
Load-bearing premise
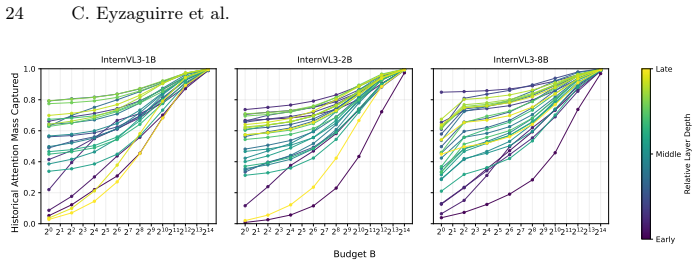
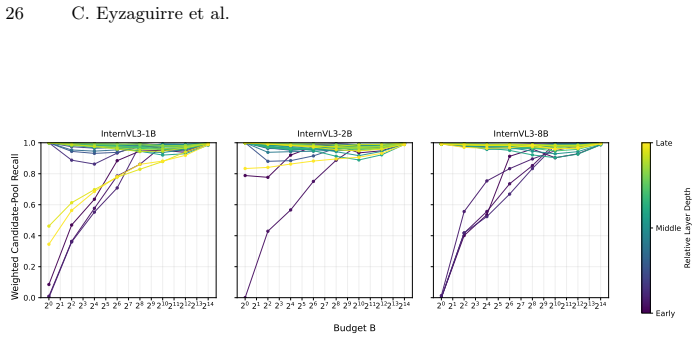
That selecting tokens by importance into a fixed-size recurrent state preserves enough cross-frame information for downstream accuracy without task-specific tuning.
What would settle it
A benchmark result where StateKV accuracy falls substantially below full self-attention on any of the three long-video tasks would falsify the claim that the recurrent state suffices.
Figures








read the original abstract
Video vision-language models (VLMs) are increasingly used in long-horizon and streaming settings, yet most video encoders still rely on spatiotemporal self-attention, causing compute and latency to grow quadratically with the number of frames. Existing efficiency methods improve scalability but often lose accuracy relative to full self-attention, for example through aggressive frame/token dropping or coarse attention approximations. We introduce StateKV, an inference-time method that adapts pretrained long-video VLMs to linear-time video prefill by carrying cross-frame context in a fixed-capacity, importance-based recurrent state, paired with a second full per-frame cache used for decoding. Across three long-video benchmarks and seven models spanning three families and multiple scales, StateKV remains close to full self-attention and consistently outperforms dominant sliding-window / recency-based streaming approximations, without fine-tuning or architectural changes. StateKV also reduces video-prefill cost measured FLOPs, enabling stronger accuracy at a fixed compute budget by running larger models. These results suggest a practical step toward scalable long-video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StateKV, an inference-time procedure that enables linear-time video prefill for pretrained video VLMs. It maintains cross-frame context in a fixed-capacity importance-based recurrent state during prefill while using a separate full per-frame cache for decoding. Empirical evaluation across three long-video benchmarks and seven models from three families shows StateKV performance remains close to full self-attention and outperforms sliding-window and recency-based baselines, without fine-tuning or architectural changes; it also reports reduced prefill FLOPs.
Significance. If the results hold, the work offers a practical route to scaling video VLMs to longer sequences at inference time. The multi-model, multi-scale evaluation without retraining is a strength, as is the explicit comparison to dominant streaming approximations. The FLOPs reduction claim, if quantified, could support the secondary point about running larger models at fixed compute.
major comments (2)
- [Abstract and §3] Abstract and §3 (method description): the importance heuristic used to populate and update the fixed-capacity recurrent state is described only at a high level with no explicit equation, pseudocode, or definition of the scoring function (e.g., attention proxy, norm, or recency). This is load-bearing for the central claim that the state suffices to match full attention on long-horizon tasks.
- [§4 and Tables 1–3] §4 and Tables 1–3: the abstract and results claim consistent outperformance and closeness to full self-attention, yet no quantitative deltas, standard deviations, or error bars across runs or seeds are reported. Without these, the strength of the empirical support for the weakest assumption (that the importance heuristic preserves task-critical cross-frame context) cannot be assessed.
minor comments (1)
- The FLOPs measurement protocol for prefill cost should be stated explicitly (e.g., which operations are counted and on what hardware) to allow direct comparison with baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): the importance heuristic used to populate and update the fixed-capacity recurrent state is described only at a high level with no explicit equation, pseudocode, or definition of the scoring function (e.g., attention proxy, norm, or recency). This is load-bearing for the central claim that the state suffices to match full attention on long-horizon tasks.
Authors: We agree that the current description of the importance heuristic is high-level. In the revision we will add an explicit equation for the scoring function (based on an attention proxy), a definition of the importance metric, and pseudocode for the recurrent state population and update steps in §3. This will make the procedure fully reproducible from the text. revision: yes
-
Referee: [§4 and Tables 1–3] §4 and Tables 1–3: the abstract and results claim consistent outperformance and closeness to full self-attention, yet no quantitative deltas, standard deviations, or error bars across runs or seeds are reported. Without these, the strength of the empirical support for the weakest assumption (that the importance heuristic preserves task-critical cross-frame context) cannot be assessed.
Authors: We acknowledge that explicit per-table deltas and any variability measures are absent. Because StateKV is a deterministic inference procedure with no random seeds or stochastic components, standard deviations across runs are not applicable; however, we will add explicit accuracy deltas (StateKV minus full attention, StateKV minus baselines) to Tables 1–3 and the text in §4. We will also report results on an additional held-out seed for the largest model if space allows. revision: partial
Circularity Check
No circularity: empirical method with external benchmarks
full rationale
The paper presents StateKV as a new inference-time procedure for linear-time video prefill using an importance-based recurrent state, evaluated empirically across seven models and three benchmarks against full self-attention and baselines. No equations, fitted parameters, or derivations are described that reduce the reported performance to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing support. The central claims rest on direct comparisons to external benchmarks and are therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Advances in neural information processing systems35, 23716– 23736 (2022) 3
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022) 3
2022
-
[3]
com/m/12f214efcc2f457a/original/Claude-Sonnet-4-5-System-Card.pdf4
Anthropic: Claude sonnet 4.5 system card (2025),https://assets.anthropic. com/m/12f214efcc2f457a/original/Claude-Sonnet-4-5-System-Card.pdf4
2025
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025) 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
In: Forty-second International Conference on Machine Learning (2025),https: //openreview.net/forum?id=RyOpooIxDF5
Behnam, P., Fu, Y., Zhao, R., Tsai, P.A., Yu, Z., Tumanov, A.: RocketKV: Accelerating long-context LLM inference via two-stage KV cache compression. In: Forty-second International Conference on Machine Learning (2025),https: //openreview.net/forum?id=RyOpooIxDF5
2025
-
[8]
Buch, S., Eyzaguirre, C., Gaidon, A., Wu, J., Fei-Fei, L., Niebles, J.C.: Re- visiting the “Video” in Video-Language Understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022), arXiv:2206.01720 4
-
[9]
In: CVPR (2025) 4
Buch, S., Nagrani, A., Arnab, A., Schmid, C.: Flexible frame selection for efficient video reasoning. In: CVPR (2025) 4
2025
-
[10]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Cai, Z., Zhang, Y., Gao, B., Liu, Y., Liu, T., Lu, K., Xiong, W., Dong, Y., Chang, B., Hu, J., Wen, X.: Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling. arXiv preprint arXiv:2406.02069 (2024) 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Advances in Neural Information Processing Systems38, 91077–91100 (2026) 3, 10 16 C
Chen, G., Li, Z., Wang, S., Jiang, J., Liu, Y., Lu, L., Huang, D.A., Byeon, W., Le, M., Ehrlich, M., et al.: Eagle 2.5: Boosting long-context post-training for frontier vision-language models. Advances in Neural Information Processing Systems38, 91077–91100 (2026) 3, 10 16 C. Eyzaguirre et al
2026
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, J., Lv, Z., Wu, S., Lin, K.Q., Song, C., Gao, D., Liu, J.W., Gao, Z., Mao, D., Shou, M.Z.: Videollm-online: Online video large language model for streaming video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18407–18418 (2024) 5
2024
-
[13]
In: European Conference on Computer Vision
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision- language models. In: European Conference on Computer Vision. pp. 19–35. Springer (2024) 4
2024
-
[14]
arXiv preprint arXiv:2411.18211 (2024) 3
Chen, S., Lan, X., Yuan, Y., Jie, Z., Ma, L.: Timemarker: A versatile video-llm for long and short video understanding with superior temporal localization ability. arXiv preprint arXiv:2411.18211 (2024) 3
-
[15]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Y., Bai, X., Wang, Z., Bai, C., Dai, Y., Lu, M.: Streamkv: Streaming video question-answering with segment-based kv cache retrieval and compression. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 3120–3128 (2026) 2, 5
2026
-
[16]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
In: International Conference on Learning Representations
Dao, T.: Flashattention-2: Faster attention with better parallelism and work parti- tioning. In: International Conference on Learning Representations. vol. 2024, pp. 35549–35562 (2024) 10, 28
2024
-
[19]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Deitke, M., Clark, C., Lee, S., Tripathi, R., Yang, Y., Park, J.S., Salehi, M., Muennighoff, N., Lo, K., Soldaini, L., et al.: Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 91–104 (2025) 3
2025
-
[20]
In: International Conference on Learning Representations
Di, S., Yu, Z., Zhang, G., Li, H., Cheng, H., Li, B., He, W., Shu, F., Jiang, H.: Streaming video question-answering with in-context video kv-cache retrieval. In: International Conference on Learning Representations. vol. 2025, pp. 42115–42127 (2025) 2, 5
2025
-
[21]
Advances in Neural Information Processing Systems 37, 100698–100733 (2024) 5
Eyzaguirre, C., Tang, E., Buch, S., Gaidon, A., Wu, J., Niebles, J.C.: Streaming detection of queried event start. Advances in Neural Information Processing Systems 37, 100698–100733 (2024) 5
2024
-
[22]
In: Forty-second International Conference on Machine Learning (2025), https://openreview.net/forum?id=6GFPnVHEKB4
Eyzaguirre, C., Vasiljevic, I., Dave, A., Wu, J., Ambrus, R.A., Kollar, T., Niebles, J.C., Tokmakov, P.: Understanding complexity in videoQA via visual program generation. In: Forty-second International Conference on Machine Learning (2025), https://openreview.net/forum?id=6GFPnVHEKB4
2025
-
[23]
In: CVPR (2025) 10
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: CVPR (2025) 10
2025
-
[24]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Fu, T., Liu, T., Han, Q., Dai, G., Yan, S., Yang, H., Ning, X., Wang, Y.: Framefusion: Combining similarity and importance for video token reduction on large vision language models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22654–22663 (2025) 4
2025
-
[25]
In: International Conference on Learning Representations
Gu, X., Pang, T., Du, C., Liu, Q., Zhang, F., Du, C., Wang, Y., Lin, M.: When attention sink emerges in language models: An empirical view. In: International Conference on Learning Representations. vol. 2025, pp. 97114–97144 (2025) 3 Linear Scaling Video VLMs for Long Video Understanding 17
2025
-
[26]
In: European Conference on Computer Vision
Huang, D.A., Liao, S., Radhakrishnan, S., Yin, H., Molchanov, P., Yu, Z., Kautz, J.: Lita: Language instructed temporal-localization assistant. In: European Conference on Computer Vision. pp. 202–218. Springer (2024) 4
2024
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jin, P., Takanobu, R., Zhang, W., Cao, X., Yuan, L.: Chat-univi: Unified visual representation empowers large language models with image and video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13700–13710 (2024) 4
2024
-
[28]
In: Belgrave, D., Zhang, C., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., Chen, N
Kim, M., Shim, K., Choi, J., Chang, S.: Infinipot-v: Memory-constrained kv cache compression for streaming video understanding. In: Belgrave, D., Zhang, C., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., Chen, N. (eds.) Advances in Neural Information Processing Systems. vol. 38, pp. 138983–139013. Curran Associates, Inc. (2025), https://proceedings.neur...
2025
-
[29]
Advances in Neural Information Processing Systems38, 9365–9397 (2026) 5
Łańcucki, A., Staniszewski, K., Nawrot, P., Ponti, E.M.: Inference-time hyper- scaling with kv cache compression. Advances in Neural Information Processing Systems38, 9365–9397 (2026) 5
2026
-
[30]
Transactions on Machine Learning Research (2024) 3
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. Transactions on Machine Learning Research (2024) 3
2024
-
[31]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023) 3
2023
-
[32]
Science China Information Sciences 68(10), 200102 (2025) 4
Li, K., He, Y., Wang, Y., Li, Y., Wang, W., Luo, P., Wang, Y., Wang, L., Qiao, Y.: Videochat: Chat-centric video understanding. Science China Information Sciences 68(10), 200102 (2025) 4
2025
-
[33]
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Li, X., Wang, Y., Yu, J., Zeng, X., Zhu, Y., Huang, H., Gao, J., Li, K., He, Y., Wang, C., Qiao, Y., Wang, Y., Wang, L.: Videochat-flash: Hierarchical compression for long-context video modeling. arXiv preprint arXiv:2501.00574 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Li, Y., Wang, C., Jia, J.: Llama-vid: An image is worth 2 tokens in large language models (2024) 4
2024
-
[35]
Advances in Neural Information Processing Systems37, 22947–22970 (2024) 5
Li, Y., Huang, Y., Yang, B., Venkitesh, B., Locatelli, A., Ye, H., Cai, T., Lewis, P., Chen, D.: Snapkv: Llm knows what you are looking for before generation. Advances in Neural Information Processing Systems37, 22947–22970 (2024) 5
2024
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024) 3
2024
-
[37]
io/blog/2024-01-30-llava-next/3
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge (January 2024),https://llava-vl.github. io/blog/2024-01-30-llava-next/3
2024
-
[38]
Advances in neural information processing systems36, 34892–34916 (2023) 3
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) 3
2023
-
[39]
Advances in Neural Information Processing Systems38, 102751–102777 (2026) 4
Lu, Y., Wang, T., Rao, F., Yang, Y., Zhu, L., et al.: Flexselect: Flexible token selection for efficient long video understanding. Advances in Neural Information Processing Systems38, 102751–102777 (2026) 4
2026
-
[40]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Maaz, M., Rasheed, H., Khan, S., Khan, F.: Video-chatgpt: Towards detailed video understanding via large vision and language models. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 12585–12602 (2024) 4
2024
-
[41]
In: Salakhutdinov, R., 18 C
Nawrot, P., Łańcucki, A., Chochowski, M., Tarjan, D., Ponti, E.: Dynamic memory compression: Retrofitting LLMs for accelerated inference. In: Salakhutdinov, R., 18 C. Eyzaguirre et al. Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F. (eds.) Proceedings of the 41st International Conference on Machine Learning. Proceedings of Mac...
2024
-
[42]
LiveVLM: Efficient Online Video Understanding via Streaming-Oriented KV Cache and Retrieval
Ning, Z., Liu, G., Jin, Q., Li, C., Ding, W., Guo, M., Zhao, J.: Livevlm: Efficient online video understanding via streaming-oriented kv cache and retrieval. arXiv preprint arXiv:2505.15269 (2025) 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Niu, J., Li, Y., Miao, Z., Ge, C., Zhou, Y., He, Q., Dong, X., Duan, H., Ding, S., Qian, R., et al.: Ovo-bench: How far is your video-llms from real-world online video understanding? In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18902–18913 (2025) 10
2025
-
[44]
OpenAI: Gpt-5 system card (2025),https://openai.com/index/gpt-5-system- card/4
2025
-
[45]
Advances in neural information processing systems32(2019) 10
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high- performance deep learning library. Advances in neural information processing systems32(2019) 10
2019
-
[46]
In: International Conference on Learning Representations
Peng, B., Quesnelle, J., Fan, H., Shippole, E.: Yarn: Efficient context window extension of large language models. In: International Conference on Learning Representations. vol. 2024, pp. 31932–31951 (2024) 9
2024
-
[47]
In: Forty-first International Conference on Machine Learning (2024), https://openreview.net/forum?id=e3geukCBw64
Qian, L., Li, J., Wu, Y., Ye, Y., Fei, H., Chua, T.S., Zhuang, Y., Tang, S.: Momentor: Advancing video large language model with fine-grained temporal reasoning. In: Forty-first International Conference on Machine Learning (2024), https://openreview.net/forum?id=e3geukCBw64
2024
-
[48]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Qian, R., Ding, S., Dong, X., Zhang, P., Zang, Y., Cao, Y., Lin, D., Wang, J.: Dispider: Enabling video llms with active real-time interaction via disentangled perception, decision, and reaction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24045–24055 (2025) 5
2025
-
[49]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 3
2021
-
[50]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ren, S., Yao, L., Li, S., Sun, X., Hou, L.: Timechat: A time-sensitive multi- modal large language model for long video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14313–14323 (2024) 4
2024
-
[51]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ren, W., Ma, W., Yang, H., Wei, C., Zhang, G., Chen, W.: Vamba: Understand- ing hour-long videos with hybrid mamba-transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21197–21208 (2025) 4
2025
- [52]
-
[53]
arXiv preprint arXiv:2507.20198 (2025) 2, 4
Shao, K., Tao, K., Zhang, K., Feng, S., Cai, M., Shang, Y., You, H., Qin, C., Sui, Y., Wang, H.: When tokens talk too much: A survey of multimodal long-context token compression across images, videos, and audios. arXiv preprint arXiv:2507.20198 (2025) 4
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Song, E., Chai, W., Wang, G., Zhang, Y., Zhou, H., Wu, F., Chi, H., Guo, X., Ye, T., Zhang, Y., et al.: Moviechat: From dense token to sparse memory for long video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18221–18232 (2024) 5 Linear Scaling Video VLMs for Long Video Understanding 19
2024
-
[55]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) 5
Song, E., Chai, W., Ye, T., Hwang, J.N., Li, X., Wang, G.: Moviechat+: Question- aware sparse memory for long video question answering. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) 5
2025
-
[56]
Neurocomputing568, 127063 (2024) 9
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced transformer with rotary position embedding. Neurocomputing568, 127063 (2024) 9
2024
-
[57]
arXiv preprint arXiv:2506.21862 (2025) 4
Sun, B., Zhao, J., Wei, X., Hou, Q.: Llava-scissor: Token compression with semantic connected components for video llms. arXiv preprint arXiv:2506.21862 (2025) 4
-
[58]
IEEE Transactions on Circuits and Systems for Video Technology (2025) 3
Tang, Y., Bi, J., Xu, S., Song, L., Liang, S., Wang, T., Zhang, D., An, J., Lin, J., Zhu, R., et al.: Video understanding with large language models: A survey. IEEE Transactions on Circuits and Systems for Video Technology (2025) 3
2025
-
[59]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tao, K., Qin, C., You, H., Sui, Y., Wang, H.: Dycoke: Dynamic compression of tokens for fast video large language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18992–19001 (2025) 4
2025
-
[60]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Team,G., Georgiev, P., Lei,V.I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vincent, D., Pan, Z., Wang, S., et al.: Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
In: Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages
Tillet, P., Kung, H.T., Cox, D.: Triton: an intermediate language and compiler for tiled neural network computations. In: Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages. pp. 10–19 (2019) 10, 28
2019
-
[62]
In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Wan, Z., Shen, H., Wang, X., Liu, C., Mai, Z., Zhang, M.: Meda: Dynamic kv cache allocation for efficient multimodal long-context inference. In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 2485–2497 (2025) 5
2025
-
[63]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Wan, Z., Wu, Z., Liu, C., Huang, J., Zhu, Z., Jin, P., Wang, L., Yuan, L.: Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 4065–4078 (2024) 5
2024
-
[64]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Machine Intelligence Research20(4), 447–482 (2023) 3
Wang, X., Chen, G., Qian, G., Gao, P., Wei, X.Y., Wang, Y., Tian, Y., Gao, W.: Large-scale multi-modal pre-trained models: A comprehensive survey. Machine Intelligence Research20(4), 447–482 (2023) 3
2023
-
[66]
In: Findings of the Association for Computational Linguistics: ACL 2025
Wang, X., Si, Q., Zhu, S., Wu, J., Cao, L., Nie, L.: Adaretake: Adaptive redundancy reduction to perceive longer for video-language understanding. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 5417–5432 (2025) 2, 5
2025
-
[67]
Wang, Y., Meng, X., Liang, J., Wang, Y., Liu, Q., Zhao, D.: Hawkeye: Training video-text llms for grounding text in videos (2024) 4
2024
-
[68]
In: Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., et al.: Transformers: State-of-the-art natural language processing. In: Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations. pp. 38–45 (2020) 10
2020
-
[69]
In: International Conference on Learning Representations
Xiao, G., Tian, Y., Chen, B., Han, S., Lewis, M.: Efficient streaming language models with attention sinks. In: International Conference on Learning Representations. vol. 2024, pp. 21875–21895 (2024) 3
2024
-
[70]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xing, L., Huang, Q., Dong, X., Lu, J., Zhang, P., Zang, Y., Cao, Y., He, C., Wang, J., Wu, F., Lin, D.: Conical visual concentration for efficient large vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14593–14603 (June 2025) 4 20 C. Eyzaguirre et al
2025
-
[71]
Xu, L., Zhao, Y., Zhou, D., Lin, Z., Ng, S.K., Feng, J.: Pllava : Parameter-free llava extension from images to videos for video dense captioning (2024) 4
2024
-
[72]
Xu, M., Gao, M., Gan, Z., Chen, H.Y., Lai, Z., Gang, H., Kang, K., Dehghan, A.: Slowfast-llava: A strong training-free baseline for video large language models. arXiv preprint arXiv:2407.15841 (2024) 4
-
[73]
Xu, R., Xiao, G., Chen, Y., He, L., Peng, K., Lu, Y., Han, S.: Streamingvlm: Real-time understanding for infinite video streams (2025),https://arxiv.org/ abs/2510.096084
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Yang, Y., Zhao, Z., Shukla, S.N., Singh, A., Mishra, S.K., Zhang, L., Ren, M.: Streammem: Query-agnostic kv cache memory for streaming video understanding. arXiv preprint arXiv:2508.15717 (2025) 5
-
[75]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ye, J., Wang, Z., Sun, H., Chandrasegaran, K., Durante, Z., Eyzaguirre, C., Bisk, Y., Niebles, J.C., Adeli, E., Fei-Fei, L., et al.: Re-thinking temporal search for long-form video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8579–8591 (2025), arXiv:2504.02259 4
-
[76]
In: NeurIPS (2023) 4
Yu, S., Cho, J., Yadav, P., Bansal, M.: Self-chained image-language model for video localization and question answering. In: NeurIPS (2023) 4
2023
-
[77]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., et al.: Videollama 3: Frontier multimodal foundation models for image and video understanding. arXiv preprint arXiv:2501.13106 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
In: Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations
Zhang, H., Li, X., Bing, L.: Video-llama: An instruction-tuned audio-visual language model for video understanding. In: Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations. pp. 543–553 (2023) 4
2023
- [79]
-
[80]
HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
Zhang, H., Yang, S., Fu, J., Ng, S.K., Qiu, X.: Hermes: Kv cache as hierarchical mem- ory for efficient streaming video understanding. arXiv preprint arXiv:2601.14724 (2026) 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.