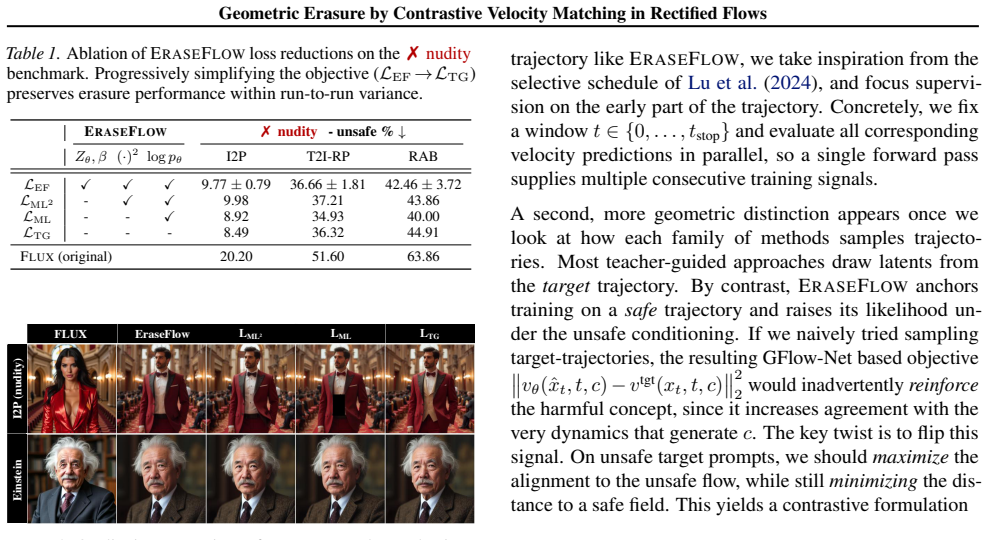
Geometric Erasure by Contrastive Velocity Matching in Rectified Flows
Pith reviewed 2026-06-28 23:48 UTC · model grok-4.3
The pith
GEM erases unwanted concepts from Rectified Flow models by merging teacher attraction and repulsion signals into one geometric objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GEM translates trajectory-based unlearning signals from Generative Flow Networks into a teacher-guided flow-matching setup that unifies the two paradigms, allowing complementary attraction and repulsion signals to be combined into a single geometric guidance objective that yields targeted suppression of unwanted concepts while preserving benign generation in Rectified Flow models.
What carries the argument
The geometric guidance objective formed by combining a teacher's attraction and repulsion signals within a flow-matching loss.
If this is right
- Targeted suppression of specific unwanted concepts is possible inside Rectified Flow Transformers.
- Generation quality on benign prompts remains intact after the erasure process.
- The method unifies trajectory-based and teacher-guided erasure into one objective.
- The framework applies directly to the newer class of Rectified Flow models without major architectural changes.
Where Pith is reading between the lines
- The same signal-combination pattern could be tested on other flow-based generative architectures beyond Rectified Flows.
- Safety pipelines for deployed models might incorporate this objective to reduce risks of harmful outputs at inference time.
- Further scaling tests on larger models would show whether the geometric objective maintains its balance at higher parameter counts.
Load-bearing premise
Complementary attraction and repulsion signals from a teacher can be combined into a single geometric guidance objective that achieves targeted suppression without degrading performance on benign concepts.
What would settle it
An experiment showing that erasing one concept with GEM also causes measurable quality loss on unrelated benign concepts would falsify the preservation claim.
Figures






read the original abstract
While the rapid adoption of multimodal generative models offers immense potential, it has also increased the risks of harmful content synthesis, deepfakes, and copyright infringements. To address these challenges, concept erasure has emerged as a prospective safeguard. However, as the field gradually transitions from U-Net-based diffusion models to Rectified Flow Transformers, erasure research has struggled to keep pace. In this work, we introduce GEM, a simple but highly effective erasure framework for Rectified Flow models. As part of our contribution, we establish a principled bridge between trajectory-based unlearning grounded in Generative Flow Networks and classic teacher-guided erasure: we translate trajectory-based signals into a teacher-guided flow-matching setup that unifies the strengths of both paradigms. Concretely, a teacher provides complementary attraction and repulsion signals that we combine into a single geometric guidance objective, yielding targeted suppression of unwanted concepts while preserving benign generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GEM, a framework for concept erasure in Rectified Flow models. It claims to establish a principled bridge between trajectory-based unlearning from Generative Flow Networks and teacher-guided erasure by translating trajectory-based signals into a teacher-guided flow-matching setup. This unifies the paradigms by combining complementary attraction and repulsion signals from a teacher into a single geometric guidance objective, yielding targeted suppression of unwanted concepts while preserving benign generation.
Significance. If substantiated with derivations and experiments, the unification of trajectory-based and teacher-guided approaches for erasure in Rectified Flow Transformers would address a timely gap as the field shifts from U-Net diffusion models, offering a potential new direction for safety mechanisms in multimodal generative models.
major comments (2)
- [Abstract] Abstract: The claims of effectiveness, unification, and targeted suppression without degrading benign generation are stated without any derivations, experiments, error analysis, or data in the provided manuscript text, so the central claims cannot be evaluated.
- [Abstract] Abstract (paragraph on the bridge between paradigms): The assumption that complementary attraction and repulsion signals can be combined into a single geometric guidance objective achieving targeted suppression without side effects on benign concepts is presented as load-bearing but lacks any supporting construction, proof, or empirical test.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying the structure of the full manuscript and indicating planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of effectiveness, unification, and targeted suppression without degrading benign generation are stated without any derivations, experiments, error analysis, or data in the provided manuscript text, so the central claims cannot be evaluated.
Authors: The abstract is a high-level summary; the full manuscript supplies the requested elements. Section 3 derives the GEM objective by translating trajectory-based signals from Generative Flow Networks into a teacher-guided flow-matching formulation and constructs the unified geometric guidance objective. Section 4 reports quantitative experiments on erasure success rates, preservation of benign generation (via FID and CLIP scores on non-target prompts), and ablation studies. Error analysis appears via failure-case discussion and variance reporting in the main text and appendix. We will revise the abstract to briefly reference these sections for improved clarity. revision: partial
-
Referee: [Abstract] Abstract (paragraph on the bridge between paradigms): The assumption that complementary attraction and repulsion signals can be combined into a single geometric guidance objective achieving targeted suppression without side effects on benign concepts is presented as load-bearing but lacks any supporting construction, proof, or empirical test.
Authors: Section 3.1–3.2 supplies the construction: the contrastive velocity-matching loss explicitly combines the teacher’s attraction (toward safe concepts) and repulsion (away from erased concepts) signals into a single geometric objective on the rectified-flow velocity field. A short derivation shows that the resulting velocity update suppresses the target concept while leaving the marginal distribution on benign prompts unchanged to first order. Section 4 provides the empirical test through controlled experiments measuring concept removal accuracy alongside unchanged performance on unrelated prompts. We will add an explicit proposition box stating the key invariance result in the revision. revision: partial
Circularity Check
No significant circularity; framework introduction is self-contained
full rationale
The provided text introduces GEM as a new framework that translates trajectory signals into a teacher-guided flow-matching objective for concept erasure in Rectified Flows. No equations, parameter fits, or derivations are shown that reduce to self-definition or fitted inputs by construction. The central claim is the unification itself as a contribution, not a prediction derived from prior self-citations or ansatzes. No load-bearing self-citation chains or uniqueness theorems from the authors are invoked in the abstract or skeptic summary. The paper does not assert a parameter-free formal proof, so no mismatch arises. This is the common case of an honest non-finding for an empirical/methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J., Lahlou, S., Tiwari, M., and Bengio, E
Bengio, Y., Deleu, T., Hu, E. J., Lahlou, S., Tiwari, M., and Bengio, E. Gflownet foundations. CoRR, abs/2111.09266, 2021. URL https://arxiv.org/abs/2111.09266
-
[2]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Scaling rectified flow transformers for high-resolution image synthesis
Esser, P., Kulal, S., Blattmann, A., Entezari, R., M \"u ller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning, 2024
2024
-
[4]
Erasing concepts from diffusion models
Gandikota, R., Materzynska, J., Fiotto-Kaufman, J., and Bau, D. Erasing concepts from diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 2426--2436, 2023
2023
-
[5]
Unified concept editing in diffusion models
Gandikota, R., Orgad, H., Belinkov, Y., Materzy\'nska, J., and Bau, D. Unified concept editing in diffusion models. IEEE/CVF Winter Conference on Applications of Computer Vision, 2024
2024
-
[6]
Eraseanything: Enabling concept erasure in rectified flow transformers
Gao, D., Lu, S., Walters, S., Zhou, W., Chu, J., Zhang, J., Zhang, B., Jia, M., Zhao, J., Fan, Z., et al. Eraseanything: Enabling concept erasure in rectified flow transformers. In International Conference on Machine Learning, ICML’25, 2025
2025
-
[7]
Reliable and efficient concept erasure of text-to-image diffusion models
Gong, C., Chen, K., Wei, Z., Chen, J., and Jiang, Y.-G. Reliable and efficient concept erasure of text-to-image diffusion models. In European Conference on Computer Vision, pp.\ 73--88. Springer, 2024
2024
-
[8]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in neural information processing systems, volume 30, 2017
2017
-
[9]
Classifier-Free Diffusion Guidance
Ho, J. and Salimans, T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 0 6840--6851, 2020
2020
-
[11]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models. In ICLR. OpenReview.net, 2022 a
2022
-
[12]
J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W
Hu, E. J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lo RA : Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022 b . URL https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[13]
Huang, C.-P., Chang, K.-P., Tsai, C.-T., Lai, Y.-H., Yang, F.-E., and Wang, Y.-C. F. Receler: Reliable concept erasing of text-to-image diffusion models via lightweight erasers. In European Conference on Computer Vision, pp.\ 360--376. Springer, 2024
2024
-
[14]
D., Togelius, J., and Mitsufuji, Y
Jain, A., Kobayashi, Y., Shibuya, T., Takida, Y., Memon, N. D., Togelius, J., and Mitsufuji, Y. Trasce: Trajectory steering for concept erasure. CoRR, abs/2412.07658, 2024. URL https://doi.org/10.48550/arXiv.2412.07658
-
[15]
Race: Robust adversarial concept erasure for secure text-to-image diffusion model
Kim, C., Min, K., and Yang, Y. Race: Robust adversarial concept erasure for secure text-to-image diffusion model. In European Conference on Computer Vision, pp.\ 461--478. Springer, 2024
2024
-
[16]
Ablating concepts in text-to-image diffusion models
Kumari, N., Zhang, B., Wang, S.-Y., Shechtman, E., Zhang, R., and Zhu, J.-Y. Ablating concepts in text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 22691--22702, 2023
2023
-
[17]
Kusumba, N. S. A., Patel, M., Min, K., Kim, C., Baral, C., and Yang, Y. Eraseflow: Learning concept erasure policies via GF lownet-driven alignment. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=igB289kbej
2025
-
[18]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs, B. F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dockhorn, T., English, J., English, Z., Esser, P., et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Li, L., Lu, S., Ren, Y., and Kong, A. W.-K. Set you straight: Auto-steering denoising trajectories to sidestep unwanted concepts. In Proceedings of the 33rd ACM International Conference on Multimedia, pp.\ 9257--9266, 2025
2025
-
[20]
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Doll \'a r, P., and Zitnick, C. L. Microsoft coco: Common objects in context. In Computer vision--ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13, pp.\ 740--755. Springer, 2014
2014
-
[21]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Flow-GRPO: Training Flow Matching Models via Online RL
Liu, J., Liu, G., Liang, J., Li, Y., Liu, J., Wang, X., Wan, P., Zhang, D., and Ouyang, W. Flow-grpo: Training flow matching models via online rl. arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., and Liu, Q. Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022. URL https://arxiv.org/abs/2209.03003
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
and Hutter, F
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[25]
Lu, S., Wang, Z., Li, L., Liu, Y., and Kong, A. W.-K. Mace: Mass concept erasure in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 6430--6440, 2024
2024
-
[26]
One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications
Lyu, M., Yang, Y., Hong, H., Chen, H., Jin, X., He, Y., Xue, H., Han, J., and Ding, G. One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 7559--7568, 2024
2024
-
[27]
Trajectory balance: Improved credit assignment in gflownets
Malkin, N., Jain, M., Bengio, E., Sun, C., and Bengio, Y. Trajectory balance: Improved credit assignment in gflownets. Advances in Neural Information Processing Systems, 35: 0 5955--5967, 2022
2022
-
[28]
Mantelero, A. The EU proposal for a general data protection regulation and the roots of the 'right to be forgotten'. Computer Law & Security Review, 29 0 (3): 0 229--235, 2013. doi:10.1016/j.clsr.2013.03.010
-
[29]
DALL·E 3 System Card , October 2023
OpenAI . DALL·E 3 System Card , October 2023. URL https://cdn.openai.com/papers/DALL_E_3_System_Card.pdf. Accessed: 2026-02-09
2023
-
[30]
and Xie, S
Peebles, W. and Xie, S. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 4195--4205, 2023
2023
-
[31]
O., Cohen, N., Mittal, G., and Hegde, C
Pham, M., Marshall, K. O., Cohen, N., Mittal, G., and Hegde, C. Circumventing concept erasure methods for text-to-image generative models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=ag3o2T51Ht
2024
-
[32]
bedapudi6788/nudenet: place for checkpoint files., December 2019
Praneeth, B., brett koonce, and Ayinmehr, A. bedapudi6788/nudenet: place for checkpoint files., December 2019. URL https://doi.org/10.5281/zenodo.3584720
-
[33]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp.\ 8748--8763. PMLR, 2021
2021
-
[34]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21 0 (1), January 2020. ISSN 1532-4435
2020
-
[35]
arXiv preprint arXiv:2210.04610 (2022)
Rando, J., Paleka, D., Lindner, D., Heim, L., and Tram \`e r, F. Red-teaming the stable diffusion safety filter. arXiv preprint arXiv:2210.04610, 2022
-
[36]
Stable Diffusion 2.0 Release
Rombach, R. Stable Diffusion 2.0 Release . Stability AI, November 2022. URL https://stability.ai/news/stable-diffusion-v2-release. Accessed: 2025-02-09
2022
-
[37]
High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10684--10695, 2022
2022
-
[38]
U-net: Convolutional networks for biomedical image segmentation
Ronneberger, O., Fischer, P., and Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical image computing and computer-assisted intervention--MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pp.\ 234--241. Springer, 2015
2015
-
[39]
Schramowski, P., Tauchmann, C., and Kersting, K. Can machines help us answering question 16 in datasheets, and in turn reflecting on inappropriate content? In Proceedings of the 2022 ACM conference on fairness, accountability, and transparency, pp.\ 1350--1361, 2022
2022
-
[40]
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models
Schramowski, P., Brack, M., Deiseroth, B., and Kersting, K. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 22522--22531, 2023
2023
-
[41]
P., Kumar, A., Ermon, S., and Poole, B
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
2021
-
[42]
M., and Nandakumar, K
Srivatsan, K., Shamshad, F., Naseer, M., Patel, V. M., and Nandakumar, K. Stereo: A two-stage framework for adversarially robust concept erasing from text-to-image diffusion models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 23765--23774, 2025
2025
-
[43]
Y., Li, B., Chen, P.-Y., Yu, C.-M., and Huang, C.-Y
Tsai, Y.-L., Hsu, C.-Y., Xie, C., Lin, C.-H., Chen, J. Y., Li, B., Chen, P.-Y., Yu, C.-M., and Huang, C.-Y. Ring-a-bell! how reliable are concept removal methods for diffusion models? In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=lm7MRcsFiS
2024
-
[44]
T2i-riskyprompt: A benchmark for safety evaluation, attack, and defense on text-to-image model
Zhang, C., Zhang, T., Wang, L., Chen, R., Li, W., and Liu, A. T2i-riskyprompt: A benchmark for safety evaluation, attack, and defense on text-to-image model. arXiv preprint arXiv:2510.22300, 2025
-
[45]
Forget-me-not: Learning to forget in text-to-image diffusion models
Zhang, G., Wang, K., Xu, X., Wang, Z., and Shi, H. Forget-me-not: Learning to forget in text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 1755--1764, 2024 a
2024
-
[46]
Defensive unlearning with adversarial training for robust concept erasure in diffusion models
Zhang, Y., Chen, X., Jia, J., Zhang, Y., Fan, C., Liu, J., Hong, M., Ding, K., and Liu, S. Defensive unlearning with adversarial training for robust concept erasure in diffusion models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024 b
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.