RAFT: Data Refinement and Adaptive Distillation for Domain Fine-Tuning with Alleviated Forgetting
Pith reviewed 2026-06-29 00:00 UTC · model grok-4.3
The pith
RAFT refines domain data and applies answer-conditioned on-policy distillation to raise specialized accuracy while limiting loss of general capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RAFT is a two-stage method that first builds supervision through self-conditioned rewriting, semantic filtering, and answer fusion, then trains with Answer-Conditioned On-Policy Distillation in which the original model supplies soft targets on the student's own rollouts while conditioned on the fused answer; top-K temperature distillation and EMA loss balancing keep the domain-general trade-off stable. On three backbones and five domains this yields a 23.2 percent average gain in domain accuracy over plain SFT and recovers 18.2 percent and 10.2 percent of the degradation on MS-Bench and IFEval respectively.
What carries the argument
Answer-Conditioned On-Policy Distillation, in which the teacher supplies soft targets on student-generated trajectories while the fused answer serves as conditioning context.
If this is right
- Domain accuracy rises 23.2 percent on average relative to standard supervised fine-tuning.
- Degradation on MS-Bench is reduced by a relative 18.2 percent.
- Degradation on IFEval is reduced by a relative 10.2 percent.
- The same recipe works across three different instruction-tuned base models and five distinct domains.
Where Pith is reading between the lines
- The same two-stage pattern could be tested on tasks that require long-horizon reasoning where prefix behavior matters even more than in short instruction following.
- If the fused answer is replaced by a weaker context signal the preservation effect should shrink, offering a direct test of the conditioning step.
- The method may generalize to continual learning settings where successive domain updates must not erase earlier capabilities.
Load-bearing premise
The rewritten and filtered data plus the soft targets from the original model remain free of new biases or distribution shifts that would cancel the claimed accuracy gains or destabilize the distillation.
What would settle it
Running the identical three backbones and five domains with the same evaluation suite but replacing RAFT's data refinement and on-policy distillation steps with ordinary SFT produces no measurable lift in domain accuracy or recovery on the general benchmarks.
Figures

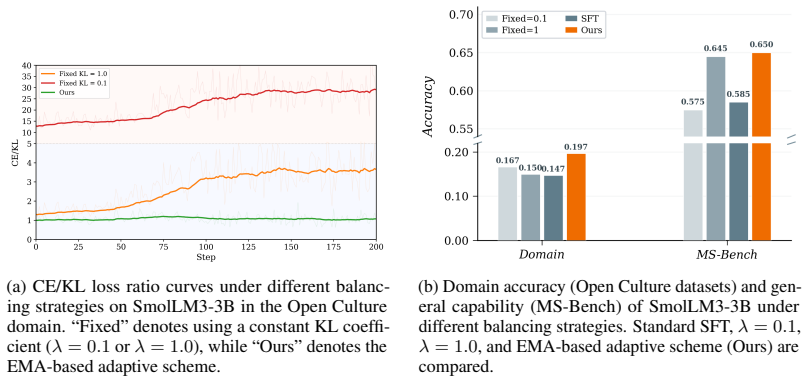
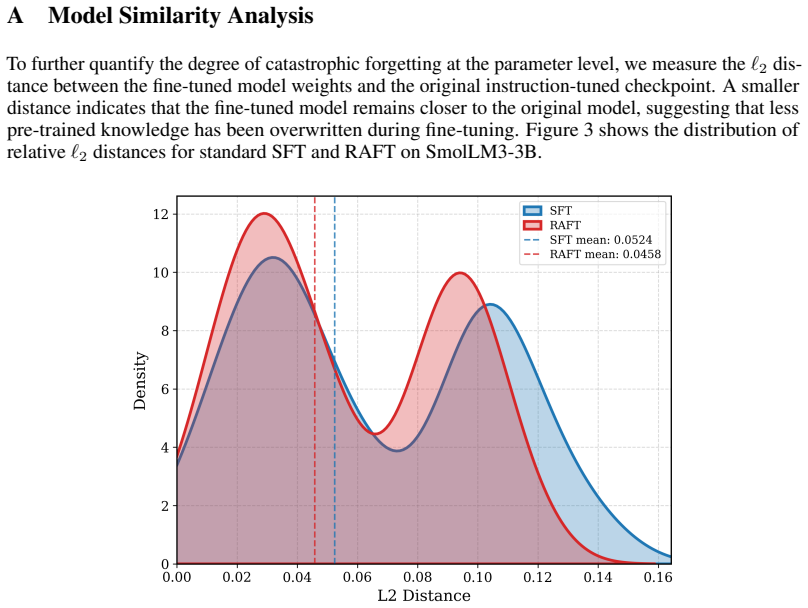
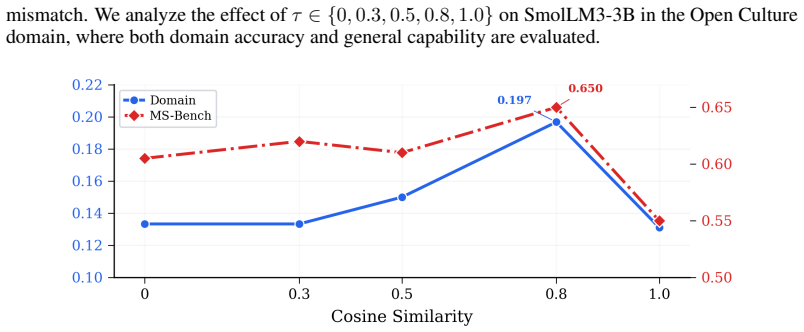
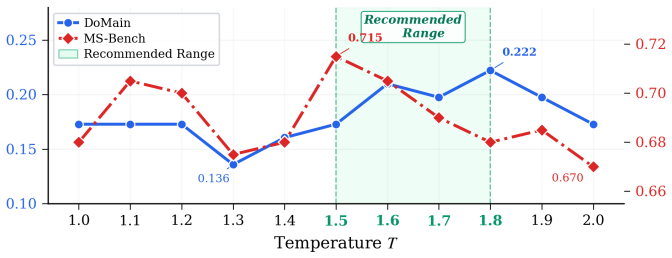
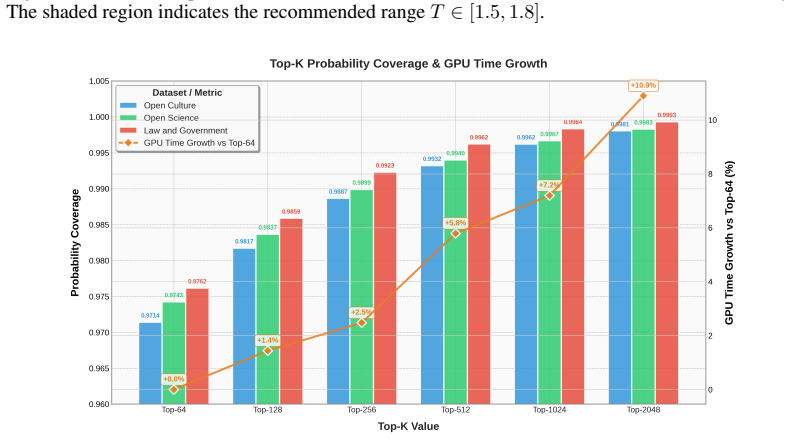
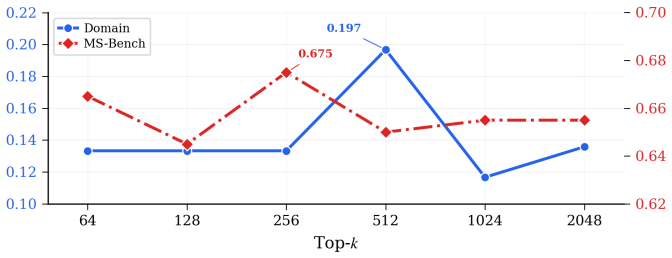

read the original abstract
Domain-specific supervised fine-tuning (SFT) often improves in-domain performance at the cost of degrading a model's general capabilities. We view this degradation through two practical gaps in domain SFT: a supervision-compatibility gap, where domain targets differ in style and reasoning format from the original model's natural responses, and a trajectory-preservation gap, where teacher-forced SFT optimizes fixed target tokens without constraining the model's behavior on its own generated prefixes. This process fails to preserve the model's original behavior. We propose RAFT (Data Refinement and Adaptive Distillation for Domain Fine-Tuning with Alleviated Forgetting), a two-stage framework that addresses both factors. First, RAFT constructs model-compatible supervision through self-conditioned rewriting, semantic filtering, and answer fusion. Second, RAFT performs Answer-Conditioned On-Policy Distillation, where the original instruction-tuned model provides soft targets on student-generated trajectories while being conditioned on the fused answer as helpful context. We further introduce top-K temperature distillation and EMA-based adaptive loss balancing to stabilize the domain-general trade-off. Across three instruction-tuned backbones and five domains, RAFT improves average domain accuracy by 23.2% over standard SFT, while recovering part of the SFT-induced degradation on MS-Bench and IFEval, with relative improvements of 18.2% and 10.2%, respectively. These results show that coupling data refinement with trajectory-level preservation provides an effective recipe for domain fine-tuning with alleviated forgetting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RAFT, a two-stage framework for domain-specific fine-tuning of instruction-tuned models. Stage 1 constructs model-compatible supervision via self-conditioned rewriting, semantic filtering, and answer fusion to close the supervision-compatibility gap. Stage 2 performs Answer-Conditioned On-Policy Distillation, in which the original untuned checkpoint supplies soft targets on student-generated trajectories (conditioned on the fused answer), augmented by top-K temperature distillation and EMA-based adaptive loss balancing to close the trajectory-preservation gap. Across three backbones and five domains the method reports a 23.2% average domain-accuracy lift over standard SFT together with partial recovery of SFT-induced degradation on MS-Bench (18.2% relative) and IFEval (10.2% relative).
Significance. If the central empirical claims hold after verification, RAFT supplies a practical, two-gap recipe for domain adaptation that couples data refinement with on-policy trajectory preservation. The multi-backbone, multi-domain evaluation is a positive feature. The work also ships an external reference point (the original instruction-tuned checkpoint) rather than a circular teacher, which strengthens the distillation design.
major comments (3)
- [Abstract and §4] Abstract and §4: the headline 23.2% domain-accuracy gain, 18.2% MS-Bench recovery, and 10.2% IFEval recovery are reported without error bars, standard deviations across random seeds, or statistical significance tests. This absence makes it impossible to assess whether the reported lifts are robust or could be explained by hyper-parameter variation or data-selection effects.
- [§3.1] §3.1 (data-refinement pipeline): the claim that self-conditioned rewriting + semantic filtering + answer fusion produce strictly higher-quality, unbiased targets rests on an untested assumption. No quantitative diagnostics (embedding divergence, n-gram overlap statistics, length/style distribution shifts, or human preference between raw and refined targets) are provided to rule out the possibility that observed gains arise from altered supervision rather than the subsequent distillation mechanism.
- [§4] §4 (experimental protocol): no ablation isolates the contribution of Answer-Conditioned On-Policy Distillation from the data-refinement stage, nor is sensitivity reported for the two free parameters (top-K temperature value and EMA decay rate). Without these controls the attribution of both domain gains and forgetting alleviation to the proposed components remains unverified.
minor comments (2)
- [§3.2] The description of the EMA-based adaptive loss balancing would benefit from an explicit equation showing how the balancing coefficient is updated.
- [§3] Implementation details for the semantic-filtering threshold and the exact conditioning format used in the distillation stage are missing and should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on empirical robustness and component attribution. We address each major comment below and commit to revisions that strengthen the statistical reporting, diagnostics, and ablations.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4: the headline 23.2% domain-accuracy gain, 18.2% MS-Bench recovery, and 10.2% IFEval recovery are reported without error bars, standard deviations across random seeds, or statistical significance tests. This absence makes it impossible to assess whether the reported lifts are robust or could be explained by hyper-parameter variation or data-selection effects.
Authors: We agree that the absence of error bars and significance tests limits assessment of robustness. In the revised manuscript we will rerun key experiments across multiple random seeds, report standard deviations, and include statistical significance tests for the headline metrics. revision: yes
-
Referee: [§3.1] §3.1 (data-refinement pipeline): the claim that self-conditioned rewriting + semantic filtering + answer fusion produce strictly higher-quality, unbiased targets rests on an untested assumption. No quantitative diagnostics (embedding divergence, n-gram overlap statistics, length/style distribution shifts, or human preference between raw and refined targets) are provided to rule out the possibility that observed gains arise from altered supervision rather than the subsequent distillation mechanism.
Authors: The referee is correct that direct quantitative diagnostics on the refined targets are missing. While the end-to-end gains support the pipeline, we will add embedding divergence, n-gram overlap statistics, and length/style distribution comparisons between raw and refined targets in the revision to better substantiate the supervision-compatibility claims. revision: yes
-
Referee: [§4] §4 (experimental protocol): no ablation isolates the contribution of Answer-Conditioned On-Policy Distillation from the data-refinement stage, nor is sensitivity reported for the two free parameters (top-K temperature value and EMA decay rate). Without these controls the attribution of both domain gains and forgetting alleviation to the proposed components remains unverified.
Authors: We agree that isolating the distillation stage and reporting parameter sensitivity would strengthen attribution. The revised manuscript will include an ablation that separates data refinement from Answer-Conditioned On-Policy Distillation and will report sensitivity results for top-K temperature and EMA decay rate. revision: yes
Circularity Check
No circularity in claimed derivation or predictions
full rationale
The paper describes an empirical two-stage procedure (data refinement via rewriting/filtering/fusion followed by answer-conditioned on-policy distillation with EMA balancing) whose performance claims rest on experimental comparisons against standard SFT across three backbones and five domains. No equations, fitted parameters, or uniqueness theorems are presented that reduce by construction to the method's own inputs; the teacher is explicitly the original untuned checkpoint, supplying an external reference. No self-citation chains or ansatzes are invoked to justify core design choices. The reported gains (23.2% domain accuracy, partial recovery on MS-Bench/IFEval) are therefore not forced by definition or statistical artifact within the paper's own framing, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- top-K value for temperature distillation
- EMA decay rate for adaptive loss balancing
axioms (2)
- domain assumption The base instruction-tuned model can generate coherent trajectories on which soft targets from the same model remain meaningful.
- ad hoc to paper Semantic filtering and answer fusion preserve task-relevant information without introducing label noise.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Experience replay for continual learning , author=. Advances in neural information processing systems , volume=
-
[2]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Mitigating catastrophic forgetting in large language models with self-synthesized rehearsal , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[3]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Recall and learn: Fine-tuning deep pretrained language models with less forgetting , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[4]
Proceedings of The Eleventh International Conference on Learning Representations (ICLR-2023) , year=
Continual pre-training of language models , author=. Proceedings of The Eleventh International Conference on Learning Representations (ICLR-2023) , year=
2023
-
[5]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[6]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Mitigating Catastrophic Forgetting in Large Language Models with Forgetting-aware Pruning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[7]
Even When Users Do Not Intend To , year=
Fine-tuning Aligned Language Models Compromises Safety , author=. Even When Users Do Not Intend To , year=
-
[8]
2026 , eprint=
Self-Distillation Enables Continual Learning , author=. 2026 , eprint=
2026
-
[9]
Reinforcement Learning via Self-Distillation
Reinforcement Learning via Self-Distillation , author=. arXiv preprint arXiv:2601.20802 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Thinking Machines Lab: Connectionism , year =
Kevin Lu and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
- [11]
-
[12]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
Modelscope-agent: Building your customizable agent system with open-source large language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2023
-
[13]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Bakouch, Elie and Ben Allal, Loubna and Lozhkov, Anton and Tazi, Nouamane and Tunstall, Lewis and Patiño, Carlos Miguel and Beeching, Edward and Roucher, Aymeric and Reedi, Aksel Joonas and Gallouédec, Quentin and Rasul, Kashif and Habib, Nathan and Fourrier, Clémentine and Kydlicek, Hynek and Penedo, Guilherme and Larcher, Hugo and Morlon, Mathieu and Sr...
-
[15]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras , author=. arXiv preprint arXiv:2503.01743 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training
Common corpus: The largest collection of ethical data for llm pre-training , author=. arXiv preprint arXiv:2506.01732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[18]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Aligning AI With Shared Human Values , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[19]
2023 , eprint=
Instruction-Following Evaluation for Large Language Models , author=. 2023 , eprint=
2023
-
[20]
2025 , eprint=
CCI4.0: A Bilingual Pretraining Dataset for Enhancing Reasoning in Large Language Models , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[22]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=
-
[23]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[24]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2408.16673 , year=
Preserving diversity in supervised fine-tuning of large language models , author=. arXiv preprint arXiv:2408.16673 , year=
-
[26]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Self-distillation bridges distribution gap in language model fine-tuning , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[27]
2018 second international conference on electronics, communication and aerospace technology (ICECA) , pages=
LoRa technology-an overview , author=. 2018 second international conference on electronics, communication and aerospace technology (ICECA) , pages=. 2018 , organization=
2018
-
[28]
ACM Computing Surveys , volume=
Instruction tuning for large language models: A survey , author=. ACM Computing Surveys , volume=. 2026 , publisher=
2026
-
[29]
IEEE Transactions on Audio, Speech and Language Processing , year=
An empirical study of catastrophic forgetting in large language models during continual fine-tuning , author=. IEEE Transactions on Audio, Speech and Language Processing , year=
-
[30]
arXiv preprint arXiv:2309.10105 , year=
Understanding catastrophic forgetting in language models via implicit inference , author=. arXiv preprint arXiv:2309.10105 , year=
-
[31]
arXiv preprint arXiv:2603.09892 , year=
MSSR: Memory-Aware Adaptive Replay for Continual LLM Fine-Tuning , author=. arXiv preprint arXiv:2603.09892 , year=
-
[32]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
2017
-
[33]
International conference on machine learning , pages=
Explicit inductive bias for transfer learning with convolutional networks , author=. International conference on machine learning , pages=. 2018 , organization=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.