Learning to Construct Practical Agentic Systems
Pith reviewed 2026-06-28 23:02 UTC · model grok-4.3
The pith
A framework using pseudo-tools for modularity makes fixed workflows in LLM agents cheaper and more accurate than dynamic planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By defining pseudo-tools that call LLMs recursively on a restricted context, the framework enables designers to enforce modularity in agentic LLM systems. Hand-constructed fixed workflows built in this framework are generally cheaper and more accurate than dynamically-planned workflows across diverse tasks. Learning methods for the required pseudo-tools and workflows outperform the hand-engineered agents, and the modularity permits multi-objective optimization to balance cost against quality.
What carries the argument
The pseudo-tool mechanism, which enforces modularity by restricting the context passed to recursive LLM calls.
If this is right
- Hand-constructed fixed workflows outperform dynamically-planned workflows on both cost and accuracy for the tested tasks.
- Learning methods for pseudo-tools and workflows produce agents that beat hand-engineered baselines.
- Multi-objective optimization can be applied directly to the modular components to trade off inference cost against response quality.
- Production agentic systems can prioritize simplicity and predictability by favoring fixed workflows over dynamic planning.
Where Pith is reading between the lines
- The modularity could make it easier to update or debug individual agent components without retraining the whole system.
- If context restriction works reliably, similar designs might reduce variance in real-world deployment costs.
- The approach suggests that learning fixed structures may be more sample-efficient than learning full dynamic planners.
Load-bearing premise
The pseudo-tool mechanism successfully enforces useful modularity and restricted context without losing necessary information or introducing new failure modes that offset the gains in cost and accuracy.
What would settle it
A direct comparison on the paper's task set where fixed workflows show higher total cost or lower accuracy than dynamic planning once context restriction is applied.
Figures

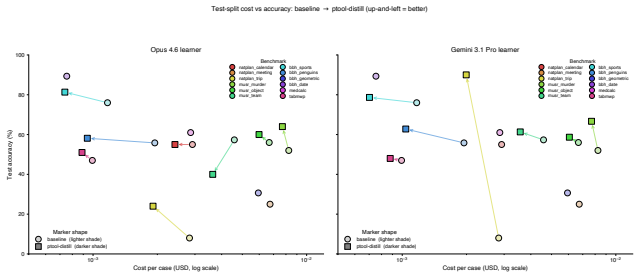
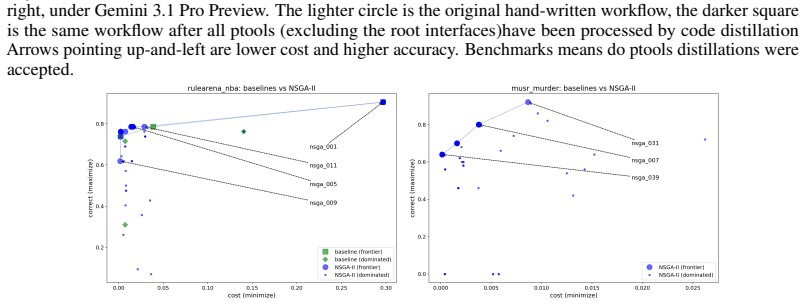


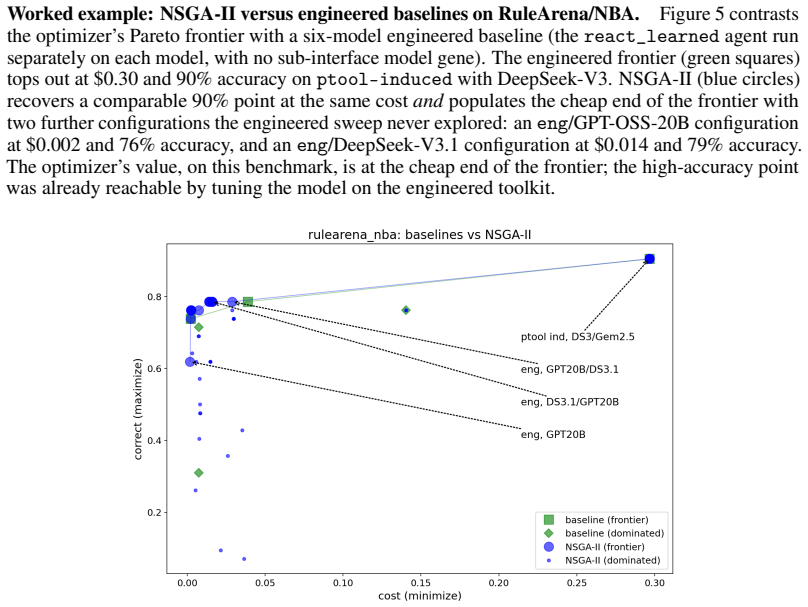
read the original abstract
Automated design and optimization of agentic LLM-based systems leads to sophisticated systems that substantially improve result quality over off-the-shelf agentic patterns. However, studies of fielded agentic systems show that production systems focus much more on issues such as simplicity, controllability, and predictability of inference costs. In this paper we propose principled approaches to designing and optimizing practical agentic systems. We describe an agent framework that enables designers to enforce modularity in agentic systems, by defining "pseudo-tools" that call LLMs recursively on a restricted context. Using this framework we hand-engineer agents for a diverse set of tasks, and show that relative to dynamically-planned workflows, hand-constructed fixed workflows are generally cheaper and more accurate. We then propose novel learning methods for the agentic components required by this framework, namely pseudo-tools and fixed workflows. These learning methods generally outperform hand-engineered agents. We also exploit the modularity of the framework to apply multi-objective optimization methods to jointly optimize cost and response quality and blend the results of multiple learning systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an agent framework using 'pseudo-tools' for enforcing modularity in LLM-based agentic systems through recursive calls on restricted contexts. It shows that hand-constructed fixed workflows are generally cheaper and more accurate than dynamically-planned workflows, introduces learning methods for pseudo-tools and fixed workflows that outperform hand-engineered agents, and applies multi-objective optimization to jointly optimize cost and response quality.
Significance. If the empirical findings hold, this work addresses important practical issues in agentic systems such as controllability, predictability of costs, and simplicity, which are prioritized in production over sophisticated but complex designs. The combination of hand-engineering, learning, and multi-objective optimization provides a principled approach that could influence how agentic systems are built and optimized in practice.
major comments (2)
- [Abstract] The abstract asserts empirical superiority of fixed workflows and learned components but provides no quantitative results, baselines, task definitions, or statistical details, making it impossible to assess the validity of the central claims without the full experimental section.
- [Pseudo-tool mechanism] The framework's promise hinges on pseudo-tools delivering modularity and lower cost without losing critical information. No ablation on context restriction, information retention metrics, or comparison with unrestricted context is mentioned to confirm that the restriction does not introduce offsetting failure modes.
minor comments (1)
- The abstract could benefit from a brief mention of the specific tasks or domains used in the experiments to provide context for the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive review. We address each major comment below, agreeing where the manuscript can be strengthened through revision.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts empirical superiority of fixed workflows and learned components but provides no quantitative results, baselines, task definitions, or statistical details, making it impossible to assess the validity of the central claims without the full experimental section.
Authors: We agree that the abstract would be more informative with quantitative highlights. The body of the paper contains the requested details on tasks, baselines, metrics, and statistics. In revision we will expand the abstract to include key results such as the observed accuracy gains and cost reductions for fixed workflows versus dynamic planning. revision: yes
-
Referee: [Pseudo-tool mechanism] The framework's promise hinges on pseudo-tools delivering modularity and lower cost without losing critical information. No ablation on context restriction, information retention metrics, or comparison with unrestricted context is mentioned to confirm that the restriction does not introduce offsetting failure modes.
Authors: The current evaluation focuses on end-to-end task performance. We acknowledge that targeted ablations would better isolate the effect of context restriction. In the revised manuscript we will add an ablation comparing restricted versus unrestricted contexts together with information-retention metrics. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical framework using pseudo-tools for modularity in agentic LLM systems, hand-engineered agents, and learning methods for pseudo-tools and workflows. Claims rest on experimental comparisons of cost/accuracy vs. dynamic planning, with multi-objective optimization. No equations, derivations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described content. The derivation chain is self-contained against external benchmarks via empirical results rather than internal algebraic reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can usefully operate on deliberately restricted contexts without catastrophic loss of necessary information.
invented entities (1)
-
pseudo-tool
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Forty-first International Conference on Machine Learning , year=
Gptswarm: Language agents as optimizable graphs , author=. Forty-first International Conference on Machine Learning , year=
-
[2]
Recursive language models , author=. arXiv preprint arXiv:2512.24601 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Authorea Preprints , year=
Agentic AI for Emergency Response and Comparative Analysis of SmolAgents, LangGraph, AutoGen, Agno AGI and CrewAI for Crisis Solution , author=. Authorea Preprints , year=
-
[4]
Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks , author=. arXiv preprint arXiv:2211.12588 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
2025 , eprint=
A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems , author=. 2025 , eprint=
2025
-
[6]
2024 7th International Conference on Contemporary Computing and Informatics (IC3I) , volume=
A comparative study on using genetic algorithm with DEAP framework on different optimization problems , author=. 2024 7th International Conference on Contemporary Computing and Informatics (IC3I) , volume=. 2024 , organization=
2024
-
[7]
Designbench: A comprehensive benchmark for mllm-based front-end code generation , author=. arXiv preprint arXiv:2506.06251 , year=
-
[8]
2026 , eprint=
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents , author=. 2026 , eprint=
2026
-
[9]
2026 , eprint=
Measuring Agents in Production , author=. 2026 , eprint=
2026
-
[10]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , journal=
-
[11]
Executable Code Actions Elicit Better
Wang, Xingyao and Chen, Yangyi and Yuan, Lifan and Zhang, Yizhe and Li, Yunzhu and Peng, Hao and Ji, Heng , journal=. Executable Code Actions Elicit Better
-
[12]
and Burger, Doug and Wang, Chi , journal=
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Zhang, Shaokun and Liu, Jiale and Awadallah, Ahmed Hassan and White, Ryen W. and Burger, Doug and Wang, Chi , journal=
-
[13]
International Conference on Machine Learning (ICML) , year=
Zhuge, Mingchen and Wang, Wenyi and Kirsch, Louis and Faccio, Francesco and Khizbullin, Dmitrii and Schmidhuber, J. International Conference on Machine Learning (ICML) , year=
-
[14]
Zhang, Jinhao and Xiang, Dian and Yu, Ao and others , journal=
-
[15]
Automated Design of Agentic Systems
Automated Design of Agentic Systems , author=. arXiv preprint arXiv:2408.08435 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
and Mober, Hanna and Shah, Pawan Kumar and Edalati, Neel and Lee, Caleb and Shin, Richard and Potts, Christopher and Zaharia, Matei , journal=
Khattab, Omar and Singhvi, Arnav and Maheshwari, Paridhi and Zhang, Zhiyuan and Santhanam, Keshav and Vardhamanan, Sri and Haq, Saiful and Sharma, Ashutosh and Joshi, Thomas T. and Mober, Hanna and Shah, Pawan Kumar and Edalati, Neel and Lee, Caleb and Shin, Richard and Potts, Christopher and Zaharia, Matei , journal=
-
[17]
Yuksekgonul, Mert and Bianchi, Federico and Boen, Joseph and Liu, Sheng and Huang, Zhi and Guestrin, Carlos and Zou, James , journal=
-
[18]
Ye, Hongqiu and others , journal=
-
[19]
Challenging
Suzgun, Mirac and Scales, Nathan and Sch. Challenging. Findings of the Association for Computational Linguistics (ACL Findings) , year=
-
[20]
International Conference on Learning Representations (ICLR) , year=
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning , author=. International Conference on Learning Representations (ICLR) , year=
-
[21]
Chen, Zhiyu and Chen, Wenhu and Smiley, Charese and Shah, Sameena and Borova, Iana and Langdon, Dylan and Moussa, Reema and Beane, Matt and Huang, Ting-Hao and Routledge, Bryan and Wang, William Yang , journal=
-
[22]
Zhou, Ruiwen and Hua, Wenyue and Pan, Liangming and Cheng, Sitao and Wu, Xiaobao and Yu, En and Wang, William Yang , journal=
-
[23]
Sprague, Zayne and Ye, Xi and Bostrom, Kaj and Chaudhuri, Swarat and Durrett, Greg , journal=
-
[24]
and Chi, Ed H
Zheng, Huaixiu Steven and Mishra, Swaroop and Zhang, Hugh and Chen, Xinyun and Chen, Minmin and Nova, Azade and Hou, Le and Cheng, Heng-Tze and Le, Quoc V. and Chi, Ed H. and Zhou, Denny , journal=
-
[25]
and Anwar, Zain and Sarfo-Gyamfi, Maame and Safranek, Conrad W
Khandekar, Nikhil and Jin, Qiao and Xiong, Guangzhi and Dunn, Soren and Applebaum, Serina S. and Anwar, Zain and Sarfo-Gyamfi, Maame and Safranek, Conrad W. and Anwar, Abid A. and Zhang, Andrew and Gilson, Aidan and Singer, Maxwell B. and Dave, Amisha and Taylor, Andrew and Zhang, Aidong and Chen, Qingyu and Lu, Zhiyong , journal=
-
[26]
and Geng, Gloria and Park, Danny and Zou, James and Ng, Andrew Y
Jiang, Yixing and Black, Kameron C. and Geng, Gloria and Park, Danny and Zou, James and Ng, Andrew Y. and Chen, Jonathan H. , journal=. 2025 , note=
2025
-
[27]
Yao, Shunyu and Shinn, Noah and Razavi, Pedram and Narasimhan, Karthik , journal=
-
[28]
International Conference on Machine Learning (ICML) , year=
Agent Workflow Memory , author=. International Conference on Machine Learning (ICML) , year=
-
[29]
Conference on Language Modeling (COLM) , year=
Inducing Programmatic Skills for Agentic Tasks , author=. Conference on Language Modeling (COLM) , year=
-
[30]
Zhao, Andrew and Huang, Daniel and Xu, Quentin and Lin, Matthieu and Liu, Yong-Jin and Huang, Gao , journal=
-
[31]
Wang, Zhiruo and Fried, Daniel and Neubig, Graham , journal=
-
[32]
International Conference on Learning Representations (ICLR) , year=
Large Language Models as Tool Makers , author=. International Conference on Learning Representations (ICLR) , year=
-
[33]
Comanici, Gheorghe and Bieber, Eric and Schaekermann, Mike and Pasupat, Ice and others , year=. 2507.06261 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
2026 , howpublished=
2026
-
[35]
Journal of Machine Learning Research , year =
F. Journal of Machine Learning Research , year =
-
[36]
, title=
Deb, Kalyanmoy and Pratap, Amrit and Agarwal, Sameer and Meyarivan, T. , title=. IEEE Transactions on Evolutionary Computation , volume=
-
[37]
2023 , howpublished =
2023
-
[38]
2024 , howpublished =
2024
-
[39]
2025 , howpublished =
Roucher, Aymeric and Villanova del Moral, Albert and Wolf, Thomas and von Werra, Leandro and Kaunism. 2025 , howpublished =
2025
-
[40]
2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.