BOUTEF: A Multilingual Corpus for FakeNews in North Africa -- Language as a Weapon
Pith reviewed 2026-06-28 22:32 UTC · model grok-4.3
The pith
A multilingual corpus shows that fake news in North Africa spreads through emotional and hybrid linguistic practices unlike factual debunking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By building the BOUTEF corpus that includes fake and genuine narratives along with comments and verified debunking across standard Arabic, local dialects, Arabizi, French, English, and mixed forms, the authors show through quantitative and qualitative study that fake news depends on emotionally charged narratives, sensational framing, and hybrid linguistic practices to enhance virality and audience engagement, while debunking content uses a factual and verification-oriented style, with significant associations between thematic categories and veracity as well as correlations between engagement and fake visibility, and differences between Algeria and Tunisia shaped by sociopolitical contexts.
What carries the argument
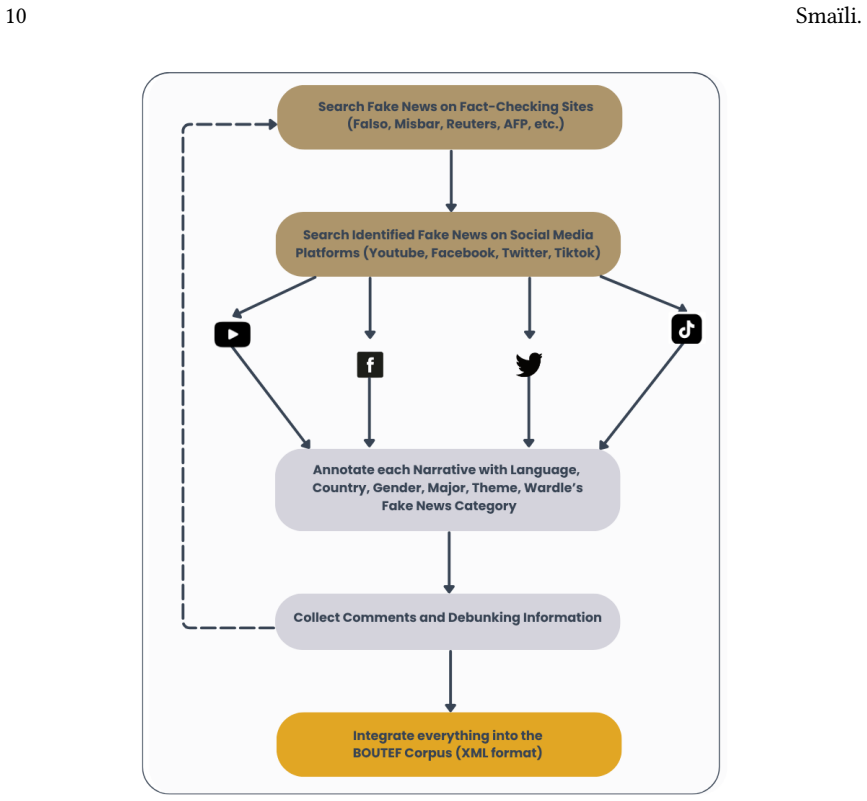
The BOUTEF corpus integrating fake narratives, genuine narratives, user comments, and debunking information across multiple languages and linguistic varieties.
Load-bearing premise
The collected narratives and annotations accurately represent the broader fake news landscape in Algeria and Tunisia without systematic selection bias or labeling errors.
What would settle it
Finding no significant statistical association between thematic categories and message veracity in an independently gathered dataset from Algeria and Tunisia would challenge the reported empirical results.
Figures














read the original abstract
The rapid spread of fake news on social media has become a major challenge, particularly in multilingual and under-resourced contexts such as North Africa. In this paper, we introduce BOUTEF, a large-scale multilingual corpus designed to study the propagation, characteristics, and impact of fake news in Algeria and Tunisia. The corpus integrates three complementary components: fake narratives, genuine narratives, and associated user-generated comments, along with verified debunking information. It covers a wide range of languages and linguistic varieties, including MSA, Algerian and Tunisian dialects, Arabizi, French, English, and code-switched language. Building on this resource, we conduct a comprehensive empirical analysis combining quantitative and qualitative approaches. We examine thematic distributions, linguistic and rhetorical strategies, sentiment patterns, and social engagement dynamics. Statistical analyses reveal significant associations between thematic categories and message veracity, as well as strong correlations between user engagement and the visibility of fake content. Our findings show that fake news relies heavily on emotionally charged narratives, sensational framing, and hybrid linguistic practices that enhance virality and audience engagement. In contrast, debunking content adopts a more factual and verification-oriented style. Furthermore, a comparative analysis between Algeria and Tunisia highlights both shared dynamics and country-specific characteristics shaped by sociopolitical contexts. The results emphasize the role of informal language practices in the diffusion and reception of misinformation. By providing a rich, annotated, and publicly available dataset, this work contributes to advancing research on fake news detection, low-resource language processing, and the understanding of information disorders in complex linguistic environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BOUTEF, a large-scale multilingual corpus for fake news in Algeria and Tunisia comprising fake narratives, genuine narratives, user-generated comments, and verified debunking information across MSA, Algerian/Tunisian dialects, Arabizi, French, English, and code-switching. It performs quantitative and qualitative analyses of thematic distributions, linguistic/rhetorical strategies, sentiment patterns, and engagement dynamics, reporting significant associations between thematic categories and message veracity, strong correlations between user engagement and fake content visibility, emotionally charged/sensational framing in fake news versus factual styles in debunking content, and both shared and country-specific patterns between Algeria and Tunisia.
Significance. If the corpus construction, sampling, and annotation procedures prove rigorous and the statistical claims hold after proper validation, the resource would be valuable for studying misinformation propagation in under-resourced multilingual North African contexts. The inclusion of dialects, code-switching, genuine/debunking pairs, and comments enables analyses of virality, reception, and sociolinguistic factors that are currently scarce in the literature, potentially supporting improved detection models and cross-lingual studies.
major comments (3)
- [Corpus construction / data collection section] The manuscript provides no description of corpus construction, including social media platforms selected, sampling strategy (e.g., keyword, time-based, or random), time period covered, or criteria used to classify narratives as fake versus genuine beyond a passing reference to 'verified debunking'. This is load-bearing because the central claims of 'significant associations between thematic categories and message veracity' and 'strong correlations between user engagement and visibility of fake content' cannot be evaluated without knowing whether the data represent the target population or are artifacts of collection bias.
- [Annotation and labeling procedures] No details are supplied on the annotation protocol: annotator qualifications, number of annotators, how veracity labels were assigned or validated, inter-annotator agreement metrics (e.g., Cohen's kappa or Fleiss' kappa), or disagreement resolution. Without these, the reliability of the veracity labels underlying all reported statistical associations remains unassessable.
- [Empirical analysis / statistical results section] The statistical analyses section reports 'significant associations' and 'strong correlations' but specifies neither the tests used (chi-square, regression, etc.), sample sizes per analysis, p-values or effect sizes, nor any controls for confounders such as topic popularity, collection method, or language variety. This prevents verification that the findings are not driven by sampling artifacts, directly undermining the empirical claims.
minor comments (2)
- [Abstract] The abstract and introduction use several long compound sentences that could be split for readability; for example, the sentence beginning 'Statistical analyses reveal significant associations...' combines multiple distinct findings.
- [Introduction / title] The acronym 'BOUTEF' is introduced without expansion or etymological note, which may reduce accessibility for readers unfamiliar with the project.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for identifying critical gaps in methodological transparency. We agree that these details are essential for evaluating the claims and will substantially revise the manuscript to include them. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Corpus construction / data collection section] The manuscript provides no description of corpus construction, including social media platforms selected, sampling strategy (e.g., keyword, time-based, or random), time period covered, or criteria used to classify narratives as fake versus genuine beyond a passing reference to 'verified debunking'. This is load-bearing because the central claims of 'significant associations between thematic categories and message veracity' and 'strong correlations between user engagement and visibility of fake content' cannot be evaluated without knowing whether the data represent the target population or are artifacts of collection bias.
Authors: We agree the description is insufficient. The revised manuscript will add a dedicated 'Data Collection' subsection specifying the platforms (Facebook and Twitter/X as primary sources), sampling approach (keyword-driven collection targeting misinformation-related terms combined with time-bounded scraping from 2020–2023), exact time window, and veracity criteria (narratives classified as fake only when matched to debunkings from at least two independent fact-checking outlets; genuine narratives drawn from verified official or journalistic sources). This addition will allow readers to assess sampling representativeness and potential biases. revision: yes
-
Referee: [Annotation and labeling procedures] No details are supplied on the annotation protocol: annotator qualifications, number of annotators, how veracity labels were assigned or validated, inter-annotator agreement metrics (e.g., Cohen's kappa or Fleiss' kappa), or disagreement resolution. Without these, the reliability of the veracity labels underlying all reported statistical associations remains unassessable.
Authors: We acknowledge this omission. The revision will insert an 'Annotation Protocol' section stating that three native-speaker annotators (with training in Arabic dialectology) performed labeling, veracity labels were validated against external debunking sources, Fleiss' kappa reached 0.82 on veracity, and disagreements were resolved by majority vote after discussion. These details will be added to demonstrate label reliability. revision: yes
-
Referee: [Empirical analysis / statistical results section] The statistical analyses section reports 'significant associations' and 'strong correlations' but specifies neither the tests used (chi-square, regression, etc.), sample sizes per analysis, p-values or effect sizes, nor any controls for confounders such as topic popularity, collection method, or language variety. This prevents verification that the findings are not driven by sampling artifacts, directly undermining the empirical claims.
Authors: We agree the statistical reporting must be expanded. The revised analysis section will explicitly name the tests (chi-square for thematic-veracity associations; Pearson correlation for engagement-visibility), report per-analysis sample sizes, exact p-values, effect sizes, and describe any stratification or controls applied for language variety and topic. Limitations regarding unmeasured confounders will also be discussed. revision: yes
Circularity Check
No circularity: descriptive corpus with empirical summaries only
full rationale
The paper introduces the BOUTEF corpus and reports thematic distributions, sentiment patterns, and statistical associations between categories and veracity/engagement. No equations, fitted parameters, predictions, or derivation chains exist. No self-citations are invoked to justify uniqueness theorems or ansatzes. The central claims rest on data collection and annotation procedures (whose validity is a separate concern) rather than any self-referential reduction of outputs to inputs. This is a standard resource paper whose empirical findings are not forced by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert or verified sources can reliably distinguish fake from genuine narratives in the collected data
Reference graph
Works this paper leans on
-
[1]
Esma Aïmeur, Sabrine Amri, and Gilles Brassard. 2023. Fake news, disinformation and misinformation in social media: a review.Social Network Analysis and Mining13, 1 (2023), 30
2023
-
[2]
Faisal Hammad Alatawi, Lu Cheng, Anique Tahir, Mansooreh Karami, Bohan Jiang, Tyler Black, and Huan Liu. 2021. A Survey on Echo Chambers on Social Media: Description, Detection and Mitigation. ArXivabs/2112.05084 (2021). https://api.semanticscholar.org/CorpusID:245006012
arXiv 2021
-
[3]
Marwan Albahar. 2021. A hybrid model for fake news detection: Leveraging news content and user comments in fake news.IET Information Security15, 2 (2021), 169–177
2021
-
[4]
Maysoon Alkhair, Abdelouahab Hocini, and Kamel Smaïli. 2023. Spotting fake news in Arabic with Machine and Deep Learning Techniques.INTERNATIONAL JOURNAL OF SCIENTIFIC DEVELOPMENT AND RESEARCH8, 2 (Feb. 2023), 605–611
2023
-
[5]
Maysoon Alkhair, Karima Meftouh, Nouha Othman, and Kamel Smaïli. 2019. An Arabic Corpus of Fake News: Collection, Analysis and Classification. InArabic Language Processing: From Theory to Practice 7th International Conference, ICALP 2019, Nancy, Proceedings. Vol. Communications in Computer and Information Science book series (CCIS, volume 1108). 292–302
2019
-
[6]
Ester Almenar, Sue Aran-Ramspott, Jaume Suau, and Pere Masip. 2021. Gender differences in tackling fake news: Different degrees of concern, but same problems.Media and Communication9, 1 (2021), 229–238
2021
-
[7]
Shatha Alyoubi, Manal Kalkatawi, and Felwa Abukhodair. 2023. The Detection of Fake News in Arabic Tweets Using Deep Learning.Applied Sciences13, 14 (2023). doi:10.3390/app13148209
-
[8]
Bend the truth
Maaz Amjad, Grigori Sidorov, Alisa Zhila, Helena Gómez-Adorno, Ilia Voronkov, and Alexander Gelbukh. 2020. “Bend the truth”: Benchmark dataset for fake news detection in Urdu language and its evaluation.Journal of Intelligent & Fuzzy Systems39, 2 (2020), 2457–2469
2020
-
[9]
Rasha Assaf and Mahmoud Saheb. 2021. Dataset for Arabic Fake News. In2021 IEEE 15th International Conference on Application of Information and Communication Technologies (AICT). 1–4. doi:10.1109/ AICT52784.2021.9620228
arXiv 2021
-
[10]
Juan Cao, Peng Qi, Qiang Sheng, Tianyun Yang, Junbo Guo, and Jintao Li. 2020. Exploring the role of visual content in fake news detection.Disinformation, Misinformation, and Fake News in Social Media: Emerging Research Challenges and Opportunities(2020), 141–161
2020
-
[11]
Manolis Chalkiadakis, Alexandros Kornilakis, Panagiotis Papadopoulos, Evangelos Markatos, and Nicolas Kourtellis. 2021. The Rise and Fall of Fake News sites: A Traffic Analysis. InProceedings of the 13th ACM Web Science Conference 2021(Virtual Event, United Kingdom)(WebSci ’21). Association for Computing Machinery, New York, NY, USA, 168–177. doi:10.1145/...
-
[12]
Anderson Cordeiro Charles, Livia Ruback, and Jonice Oliveira. 2022. Fakepedia corpus: A flexible fake news corpus in portuguese. InComputational Processing of the Portuguese Language: 15th International Conference, PROPOR 2022, Fortaleza, Brazil, March 21–23, 2022, Proceedings. Springer, 37–45. 48 Smaïli
2022
-
[13]
Mingxi Cheng, Songli Wang, Xiaofeng Yan, Tianqi Yang, Wenshuo Wang, Zehao Huang, Xiongye Xiao, Shahin Nazarian, and Paul Bogdan. 2021. A COVID-19 Rumor Dataset.Frontiers in PsychologyVolume 12 - 2021 (2021). doi:10.3389/fpsyg.2021.644801
-
[14]
Matteo Cinelli, Gianmarco De Francisci Morales, Alessandro Galeazzi, Walter Quattrociocchi, and Michele Starnini. 2021. The echo chamber effect on social media.Proceedings of the National Academy of Sciences118, 9 (2021), e2023301118. doi:10.1073/pnas.2023301118 arXiv:https://www.pnas.org/doi/pdf/10.1073/pnas.2023301118
-
[15]
Ferreira, Romualdo Pastor-Satorras, and Michele Starnini
Wesley Cota, Silvio C. Ferreira, Romualdo Pastor-Satorras, and Michele Starnini. 2019. Quantifying echo chamber effects in information spreading over political communication networks.EPJ Data Science8 (2019). https://api.semanticscholar.org/CorpusID:256236204
2019
-
[16]
Jiangshu Du, Yingtong Dou, Congying Xia, Limeng Cui, Jing Ma, and S Yu Philip. 2021. Cross-lingual covid-19 fake news detection. In2021 International Conference on Data Mining Workshops (ICDMW). IEEE, 859–862
2021
-
[17]
Henrique Ferraz de Arruda, Kleber Andrade Oliveira, and Yamir Moreno. 2024. Echo chamber formation sharpened by priority users.iScience27, 11 (2024), 111098. doi:10.1016/j.isci.2024.111098
-
[18]
W. W. Greg. 1944.The Modern Language Review39, 3 (1944), 291–293. http://www.jstor.org/stable/ 3717870
1944
-
[19]
Nahyun Gwon, Wonjeong Jeong, Jee Hyun Kim, Kyoung Hee Oh, and Jae Kwan Jun. 2024. Effects of Intervention Timing on Health-Related Fake News: Simulation Study.JMIR Form Res8 (7 Aug 2024). doi:10.2196/48284
-
[20]
Jochen Hartmann, Mark Heitmann, Christian Siebert, and Christina Schamp. 2023. More than a Feeling: Accuracy and Application of Sentiment Analysis.International Journal of Research in Marketing40, 1 (2023), 75–87. doi:10.1016/j.ijresmar.2022.05.005
-
[21]
Hanen Himdi, Nuha Zamzami, Fatma Najar, Mada Alrehaili, and Nizar Bouguila. 2025. Arabic fake news dataset development: humans and AI generated contributions.IEEE Access(2025)
2025
-
[22]
Hirschman
Albert O. Hirschman. 1964. The Paternity of an Index.The American Economic Review54, 5 (1964), 761
1964
-
[23]
Md Zobaer Hossain, Md Ashraful Rahman, Md Saiful Islam, and Sudipta Kar. 2020. BanFakeNews: A Dataset for Detecting Fake News in Bangla. InProceedings of the Twelfth Language Resources and Evaluation Conference, Nicoletta Calzolari, Frédéric Béchet, Philippe Blache, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Hitoshi Isahara, Bente Ma...
2020
-
[24]
Agus Ari Iswara and Kadek Agus Bisena. 2020. Manipulation And persuasion through language features in fake news.RETORIKA: Jurnal Ilmu Bahasa6, 1 (2020), 26–32
2020
-
[25]
Ashwaq Khalil, Moath Jarrah, Monther Aldwairi, and Manar Jaradat. 2022. AFND: Arabic fake news dataset for the detection and classification of articles credibility.Data in Brief42 (2022), 108141. BOUTEF: A Multilingual Corpus for Fake News in North Africa — Language as a Weapon49
2022
-
[26]
Ashwaq Khalil, Moath Jarrah, Monther Aldwairi, and Yaser Jararweh. 2021. Detecting arabic fake news using machine learning. In2021 Second International Conference on Intelligent Data Science Technologies and Applications (IDSTA). IEEE, 171–177
2021
-
[27]
Junaed Younus Khan, Md Khondaker, Tawkat Islam, Anindya Iqbal, and Sadia Afroz. 2019. A benchmark study on machine learning methods for fake news detection.arXiv preprint arXiv:1905.047492 (2019)
arXiv 2019
-
[28]
Sophie Lecheler and Jana Laura Egelhofer. 2022. Disinformation, misinformation, and fake news: Understanding the supply side.Knowledge resistance in high-choice information environments(2022), 69–87
2022
-
[29]
Yichuan Li, Bohan Jiang, Kai Shu, and Huan Liu. 2020. MM-COVID: A Multilingual and Multimodal Data Repository for Combating COVID-19 Disinformation. arXiv:2011.04088 [cs.SI] https://arxiv.org/ abs/2011.04088
arXiv 2020
-
[30]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692 [cs.CL] https://arxiv.org/abs/1907.11692
Pith/arXiv arXiv 2019
-
[31]
Ahmed Redha Mahlous and Ali Al-Laith. 2021. Fake news detection in Arabic tweets during the COVID-19 pandemic.International Journal of Advanced Computer Science and Applications12, 6 (2021), 778–788
2021
-
[32]
Tanushree Mitra and Eric Gilbert. 2021. CREDBANK: A Large-Scale Social Media Corpus With Associated Credibility Annotations.Proceedings of the International AAAI Conference on Web and Social Media9, 1 (Aug. 2021), 258–267. doi:10.1609/icwsm.v9i1.14625
-
[33]
Ebtsam Mohamed, Walaa N Ismail, and Eman O Eldawy. 2026. Enhancing Arabic healthcare fake news detection with data augmentation and multi-metric analysis using large language models.Scientific Reports16, 1 (2026), 5364
2026
-
[34]
Rafael A Monteiro, Roney LS Santos, Thiago AS Pardo, Tiago A De Almeida, Evandro ES Ruiz, and Oto A Vale. 2018. Contributions to the study of fake news in portuguese: New corpus and automatic detection results. InComputational Processing of the Portuguese Language: 13th International Conference, PROPOR 2018, Canela, Brazil, September 24–26, 2018, Proceedi...
2018
-
[35]
Kai Nakamura, Sharon Levy, and William Yang Wang. 2020. Fakeddit: A New Multimodal Benchmark Dataset for Fine-grained Fake News Detection. InProceedings of the Twelfth Language Resources and Evaluation Conference, Nicoletta Calzolari, Frédéric Béchet, Philippe Blache, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Hitoshi Isahara, Bente ...
2020
-
[36]
Dan Saattrup Nielsen and Ryan McConville. 2022. MuMiN: A Large-Scale Multilingual Multimodal Fact-Checked Misinformation Social Network Dataset. arXiv:2202.11684 [cs.LG] https://arxiv.org/abs/ 2202.11684 50 Smaïli
arXiv 2022
-
[37]
Brendan Nyhan and Jason Reifler. 2010. When Corrections Fail: The Persistence of Political Mispercep- tions.Political Behavior32 (06 2010), 303–330. doi:10.1007/s11109-010-9112-2
-
[38]
Ossama Obeid, Nasser Zalmout, Salam Khalifa, Dima Taji, Mai Oudah, Bashar Alhafni, Go Inoue, Fadhl Eryani, Alexander Erdmann, and Nizar Habash. 2020. CAMeL Tools: An Open Source Python Toolkit for Arabic Natural Language Processing. InProceedings of the Twelfth Language Resources and Evaluation Conference, Nicoletta Calzolari, Frédéric Béchet, Philippe Bl...
2020
-
[39]
OpenAI. 2023.GPT-4 Technical Report. Technical Report. OpenAI. https://arxiv.org/abs/2303.08774
Pith/arXiv arXiv 2023
-
[40]
Archita Pathak and Rohini K Srihari. 2019. BREAKING! presenting fake news corpus for automated fact checking. InProceedings of the 57th annual meeting of the association for computational linguistics: student research workshop. 357–362
2019
-
[41]
Pennycook and David G
Gordon. Pennycook and David G. Ran. May 2021. The Psychology of Fake News.Trends in Cognitive sciences25 (May 2021), 388–402
2021
-
[42]
Juan-Pablo Posadas-Durán, Helena Gómez-Adorno, Grigori Sidorov, and Jesús Jaime Moreno Escobar
-
[43]
Detection of fake news in a new corpus for the Spanish language.Journal of Intelligent & Fuzzy Systems36, 5 (2019), 4869–4876
2019
-
[44]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT- Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3982–3992. doi:10.18653/v1/D19-1410
-
[45]
Stephen A. Rhoades. 1993.The Herfindahl-Hirschman Index. Technical Report. Federal Reserve Bulletin
1993
-
[46]
Hadeel Saadany, Emad Mohamed, and Constantin Orasan. 2020. Fake or real? A study of Arabic satirical fake news.arXiv preprint arXiv:2011.00452(2020)
arXiv 2020
-
[47]
Kai Shu, Deepak Mahudeswaran, Suhang Wang, Dongwon Lee, and Huan Liu. 2020. Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media.Big data8, 3 (2020), 171–188
2020
-
[48]
Kamel Smaïli, Anissa Hamza-Jamann, Langlois David, and Amazouz Djegdjiga. 2024. BOUTEF: Bolster- ing Our Understanding Through an Elaborated Fake News Corpus. InThe 8th International Conference on Arabic Language Processing. RABAT, Morocco. https://hal.science/hal-04578297
2024
-
[49]
Cass R Sunstein and Adrian Vermeule. 2009. Conspiracy theories: causes and cures.Journal of political philosophy17, 2 (2009)
2009
-
[50]
Edson C. Tandoc and Seth Kai Seet and. 2024. War of the Words: How Individuals Respond to “Fake News, ” “Misinformation, ” “Disinformation, ” and “Online Falsehoods”.Journalism Practice18, 6 (2024), 1503–1519. doi:10.1080/17512786.2022.2110929 arXiv:https://doi.org/10.1080/17512786.2022.2110929 BOUTEF: A Multilingual Corpus for Fake News in North Africa —...
-
[51]
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER: a large-scale dataset for Fact Extraction and VERification.CoRRabs/1803.05355 (2018). arXiv:1803.05355 http://arxiv.org/abs/1803.05355
Pith/arXiv arXiv 2018
-
[52]
Petter Törnberg. 2018. Echo chambers and viral misinformation: Modeling fake news as complex contagion.PLoS ONE13 (2018)
2018
-
[53]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, et al. 2023. LLaMA: Open and Efficient Foundation Language Models.arXiv preprint arXiv:2302.13971(2023)
Pith/arXiv arXiv 2023
-
[54]
Adaku Uchendu, Thai Le, Kai Shu, and Dongwon Lee. 2021. TURINGBENCH: A Benchmark Environ- ment for Turing Test in the Age of Neural Text Generation. InFindings of EMNLP
2021
-
[55]
GermanFakeNC
Inna Vogel and Peter Jiang. 2019. Fake news detection with the new German dataset “GermanFakeNC”. InDigital Libraries for Open Knowledge: 23rd International Conference on Theory and Practice of Digital Libraries, TPDL 2019, Oslo, Norway, September 9-12, 2019, Proceedings 23. Springer, 288–295
2019
-
[56]
Soroush Vosoughi, Deb Roy, and Sinan Aral. 2018. The spread of true and false news online.Science 359 (03 2018), 1146–1151. doi:10.1126/science.aap9559
-
[57]
William Yang Wang. 2017. "liar, liar pants on fire": A new benchmark dataset for fake news detection. arXiv preprint arXiv:1705.00648(2017)
Pith/arXiv arXiv 2017
-
[58]
Xinyu Wang, Jiayi Li, and Sarah Rajtmajer. 2024. Inside the echo chamber: Linguistic underpinnings of misinformation on Twitter.Proceedings of the 16th ACM Web Science Conference(2024)
2024
-
[59]
Claire Wardle and Hossein Derakhshan. 2017. Information disorder: Toward an interdisciplinary framework for research and policymaking. InCouncil of Europe 27
2017
-
[60]
Jake Williams and Giovanni Santia. 2018. BuzzFace: A News Veracity Dataset withFacebook User Commentary and Egos
2018
-
[61]
Lina Zhou, Jie Tao, and Dongsong Zhang. 2023. Does fake news in different languages tell the same story? An analysis of multi-level thematic and emotional characteristics of news about COVID-19. Information Systems Frontiers25, 2 (2023), 493–512
2023
-
[62]
Arkaitz Zubiaga, Ahmet Aker, Kalina Bontcheva, Maria Liakata, and Rob Procter. 2018. Detection and resolution of rumours in social media: A survey.Acm Computing Surveys (Csur)51, 2 (2018), 1–36
2018
-
[63]
Arkaitz Zubiaga, Geraldine Wong Sak Hoi, Maria Liakata, and Rob Procter. 2016. PHEME dataset of rumours and non-rumours. (2016). 52 Smaïli. Appendix A: Fake News Topics in BOUTEF •ADMINISTRATION: Issues related to public administration, services,etc. •ARMY: Topics involving the military or armed forces. •CATASTROPHE: Stories about natural or man-made disa...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.