Per-Group Error, Not Total MSE: Fine-Tuning Vision-Language-Action Models for 11-DoF Mobile Manipulation
Pith reviewed 2026-06-28 21:59 UTC · model grok-4.3
The pith
For 11-DoF mobile manipulators, the lowest total MSE checkpoint often fails to perform best on the real robot because easy joints mask problems in harder ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
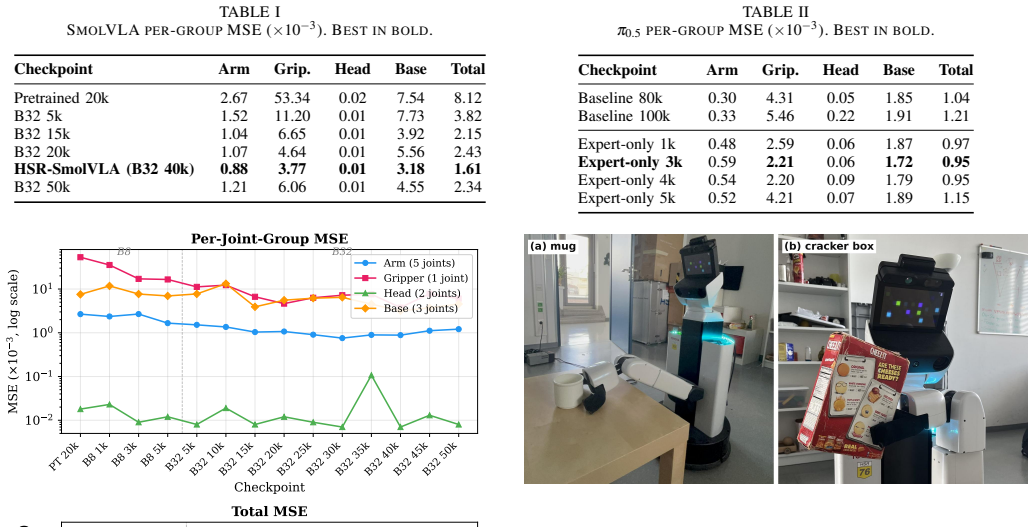
Fine-tuning VLA models for 11-DoF mobile manipulation produces the result that the checkpoint with lowest aggregate MSE is not the one that performs best on the robot. This follows from the fact that heterogeneous joint groups are collapsed into a single metric, allowing easy-to-predict joints to mask joints that continue to fail. Per-group analysis reveals that the mobile base converges slowest in SmolVLA while expert-only fine-tuning of the larger baseline lowers total MSE yet degrades arm accuracy. Across sixty real-robot trials the model whose per-group errors best match the offline arm signal outperforms the others, establishing per-group error as the more reliable signal for checkpoint
What carries the argument
Per-group error that decomposes the 11-DoF action vector into separate calculations for the arm, gripper, head and wheeled-base groups instead of a single aggregate MSE.
If this is right
- The checkpoint with lowest total MSE need not be optimal for real-robot performance when action spaces contain heterogeneous joint groups.
- Arm-group error shows stronger correlation with real-world success than either total MSE or base-group error in the tested cases.
- Expert-only fine-tuning can reduce aggregate MSE while harming accuracy on specific groups such as the arm.
- Checkpoint selection on heterogeneous robots should track per-group errors separately rather than relying on aggregate metrics alone.
Where Pith is reading between the lines
- The per-group approach could be applied to other robots whose actuation mixes different joint types.
- Training pipelines might incorporate per-group monitoring to trigger checkpoint saves automatically.
Load-bearing premise
The sixty real-robot trials and their statistical tests reflect performance differences caused by per-group error patterns rather than other unmeasured factors in execution or data collection.
What would settle it
Additional real-robot trials that produce a different ranking of the same models under total MSE versus per-group error, then check whether the per-group ranking still matches observed task success rates.
Figures


read the original abstract
Fine-tuning Vision-Language-Action (VLA) models for mobile manipulators with heterogeneous joint spaces can produce a counterintuitive result: the checkpoint with the lowest aggregate MSE is not the one that performs best on the real robot. We argue this is a predictable consequence of collapsing heterogeneous joint groups (arm, gripper, head, wheeled base) into a single metric, where easy-to-predict joints can mask joints that still fail. We fine-tune SmolVLA (450M, action-expert only) on the 11-DoF Toyota HSR and compare it against $\pi_{0.5}$ (3.3B), a stronger pretrained baseline. Per-group analysis exposes two patterns: in SmolVLA, the mobile base converges slowest and limits overall performance. In expert-only fine-tuning of $\pi_{0.5}$ (training only the action head, backbone frozen), total MSE drops below the baseline but arm accuracy degrades. On 60 real-robot trials (20 per model), $\pi_{0.5}$ 80k (4.0/4) significantly outperforms both fine-tuned variants (expert-only 3k: 3.75/4; HSR-SmolVLA: 3.5/4; Mann-Whitney $p \leq 0.010$), despite expert-only 3k having the lowest total MSE. This separation is most consistent with the offline arm-group error, not total MSE or base-group error. We conclude that per-group error is a more reliable signal than total MSE for checkpoint selection on robots with heterogeneous action spaces. Code: https://github.com/paumontagut/per-group-mse-vla
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for fine-tuning VLAs on 11-DoF mobile manipulators with heterogeneous action spaces, the checkpoint with lowest total MSE is not necessarily best on the robot because easy-to-predict joints can mask failures in harder groups (arm, base, etc.). They fine-tune SmolVLA (action-expert only) on Toyota HSR, compare to π0.5 (3.3B), observe that expert-only fine-tuning lowers total MSE but degrades arm accuracy, and report that on 60 real-robot trials (20 per model) the π0.5 80k checkpoint (4.0/4) significantly outperforms the lowest-MSE expert-only 3k (3.75/4) and HSR-SmolVLA (3.5/4) with Mann-Whitney p≤0.010; the gap is attributed to offline arm-group error rather than total MSE or base error. They conclude per-group error is the more reliable checkpoint signal.
Significance. If the result holds, the work identifies a practical issue in VLA fine-tuning for heterogeneous robots and supplies real-robot evidence with statistical testing plus open code, which strengthens the empirical grounding. The finding could influence checkpoint selection practices when action spaces mix fast- and slow-converging groups.
major comments (2)
- [real-robot trials paragraph] Real-robot evaluation (60 trials, 20 per model, Mann-Whitney p≤0.010): the central attribution of the performance gap to arm-group error rather than total MSE assumes the trials isolate that factor, but with only discrete scores out of 4, n=20 per condition, and no reported controls for initial-state randomization, sensor noise, or task variations, the result does not yet rule out confounding execution factors.
- [evaluation and conclusion] No ablation is presented showing that, within a single training run, selecting the checkpoint by lowest per-group (arm) error would have produced a better real-robot outcome than selection by total MSE; without this, the claim that per-group error is the more reliable signal rests on cross-model comparison rather than a controlled within-run test.
minor comments (2)
- [methods] Provide full details on data splits, training hyperparameters, and exact checkpoint selection criteria (e.g., how the 3k and 80k steps were chosen) to support reproducibility.
- [per-group analysis] Clarify the precise computation of per-group MSE for each joint group (arm, gripper, head, base) and whether any normalization or weighting is applied.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our real-robot evaluation and the evidential basis for our claims regarding checkpoint selection. We address each major comment below.
read point-by-point responses
-
Referee: [real-robot trials paragraph] Real-robot evaluation (60 trials, 20 per model, Mann-Whitney p≤0.010): the central attribution of the performance gap to arm-group error rather than total MSE assumes the trials isolate that factor, but with only discrete scores out of 4, n=20 per condition, and no reported controls for initial-state randomization, sensor noise, or task variations, the result does not yet rule out confounding execution factors.
Authors: We agree that the manuscript would benefit from greater transparency on the trial protocol. Initial states were randomized by varying robot and object positions within the workspace constraints of the physical setup; all trials occurred in the same controlled laboratory environment. We acknowledge that inherent real-world factors such as sensor noise and minor execution variations were not explicitly quantified or controlled beyond standard operating procedures. The discrete 4-point success metric and Mann-Whitney test capture distributional differences, which align with the observed offline arm-group error trends. We will revise the evaluation section to provide a fuller description of the protocol and to explicitly discuss these limitations. revision: partial
-
Referee: [evaluation and conclusion] No ablation is presented showing that, within a single training run, selecting the checkpoint by lowest per-group (arm) error would have produced a better real-robot outcome than selection by total MSE; without this, the claim that per-group error is the more reliable signal rests on cross-model comparison rather than a controlled within-run test.
Authors: This observation is correct. Our evidence derives from cross-model comparisons in which lower arm-group error correlates with superior real-robot performance even when total MSE is not the lowest. A controlled within-run ablation—evaluating multiple checkpoints from the identical training trajectory on the physical robot—was not conducted, primarily because of the substantial time and hardware costs of real-robot trials. While we maintain that the cross-model results provide indicative support for preferring per-group metrics, we recognize that a within-run test would constitute stronger evidence. In the revision we will add an explicit discussion of this limitation and identify it as an avenue for future work. revision: partial
Circularity Check
No circularity: empirical comparison of metrics on held-out robot trials
full rationale
The paper advances its central claim—that per-group error is a more reliable checkpoint signal than total MSE—solely through direct experimental evidence: offline per-group and total MSE values computed on held-out data are compared against real-robot success scores from 60 trials (20 per model) using Mann-Whitney tests. No derivation, equation, or ansatz is presented that reduces the result to its own inputs by construction; the separation between models (e.g., expert-only 3k having lowest total MSE yet lower real-robot score) is reported as an observed pattern, not derived. No self-citation load-bearing steps, uniqueness theorems, or fitted-input predictions appear in the provided text. The study is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mean squared error on predicted actions is a suitable proxy for downstream robot task performance.
Reference graph
Works this paper leans on
-
[1]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano,et al.(2025). SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics. arXiv:2506.01844
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
-
[3]
AIRoA (2026). AIRoA 10k Dataset: A Large-Scale Mobile Manipulation Dataset for VLA Pipelines.ICRA 2026 Workshop: From Data to Deci- sions – VLA Pipelines for Real Robots.https://icra2026vlapipeline.github. io/
2026
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess,et al.(2024).π 0: A Vision-Language- Action Flow Model for General Robot Control.arXiv:2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
K. Blacket al.(Physical Intelligence) (2025).π 0.5: A Vision-Language- Action Model with Open-World Generalization.arXiv:2504.16054
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
M. J. Kim, K. Pertsch, S. Karamcheti,et al.(2024). OpenVLA: An Open- Source Vision-Language-Action Model.arXiv:2406.09246(also CoRL 2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohanet al.(2023). RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control.CoRL 2023(arXiv:2307.15818)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
T. Z. Zhao, V . Kumar, S. Levine, C. Finn (2023). Learning Fine- Grained Bimanual Manipulation with Low-Cost Hardware.RSS 2023 (arXiv:2304.13705)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
C. Chi, Z. Xu, S. Feng,et al.(2023). Diffusion Policy: Visuomotor Policy Learning via Action Diffusion.RSS 2023(arXiv:2303.04137)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Kendall, Y
A. Kendall, Y . Gal, R. Cipolla (2018). Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics.CVPR 2018
2018
-
[11]
Z. Chen, V . Badrinarayanan, C.-Y . Lee, A. Rabinovich (2018). Grad- Norm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks.ICML 2018
2018
-
[12]
Z. Wuet al.(2025). MoManipVLA: Transferring VLAs for General Mobile Manipulation.CVPR 2025(arXiv:2503.13446)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.