Model-Native Computing Architecture: Envisioning Future System Architecture Through the Lens of Computer Architecture
Pith reviewed 2026-06-28 22:10 UTC · model grok-4.3
The pith
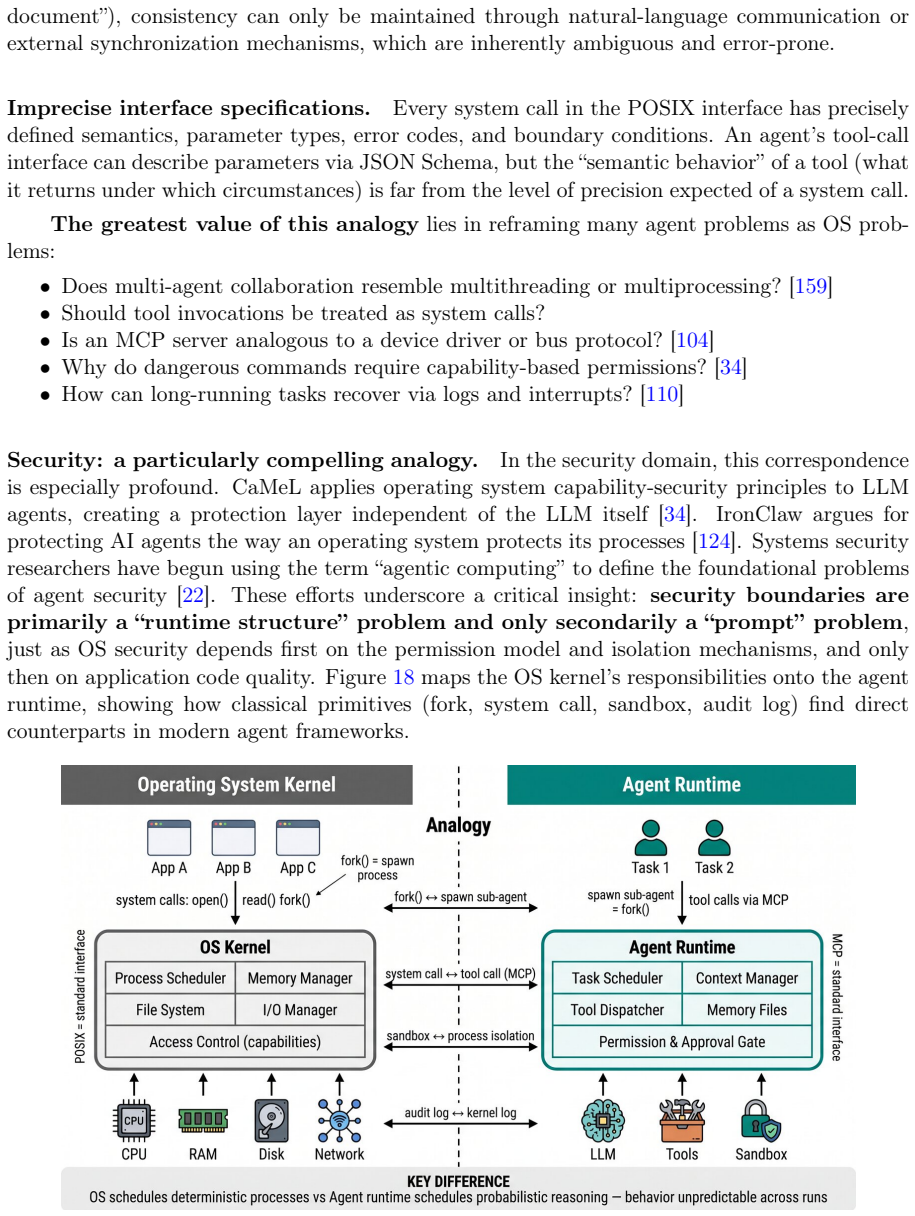
LLM systems gain a six-layer architecture by mapping them to CPUs, caches, memory, and operating systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
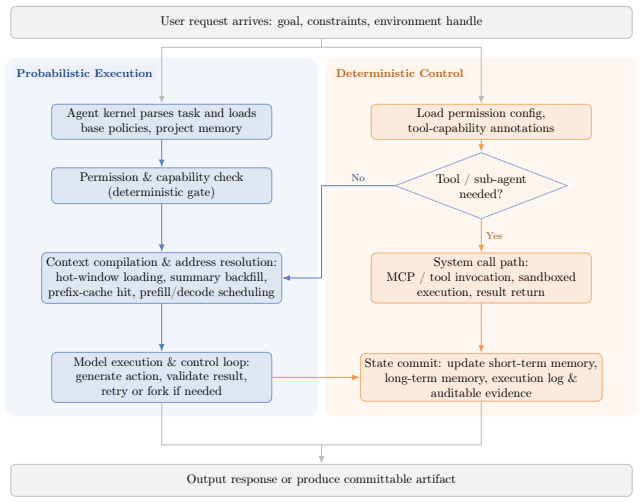
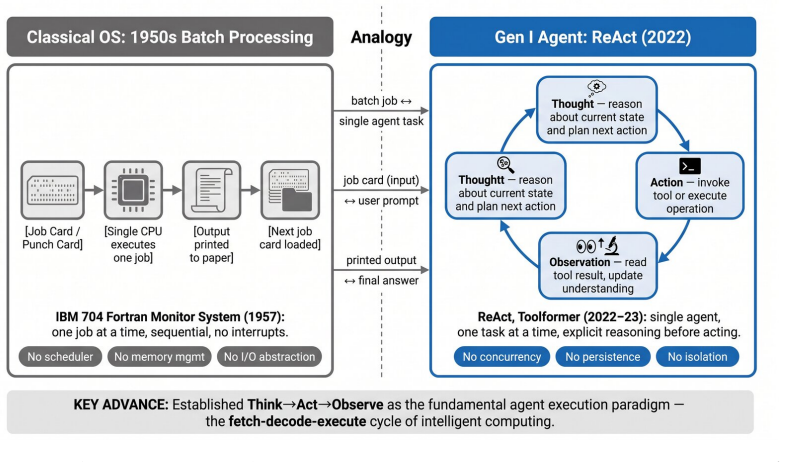
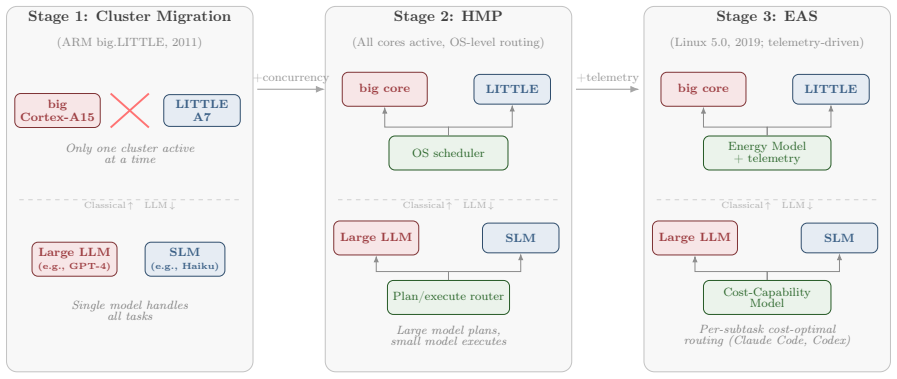
The central claim is that decades of computer-architecture experience can be transferred to model-native stacks through explicit mappings, producing the Intelligent Computing Architecture: six layers with defined interfaces and axioms, unified by a dual-plane architecture in which a probabilistic execution plane handles what can be computed and a deterministic control plane handles what should be computed, each layer graded across the crossover.
What carries the argument
The dual-plane architecture that routes every layer through both a probabilistic execution plane (what can be computed) and a deterministic control plane (what should be computed) with graded crossovers.
If this is right
- The three heuristics Semantic Locality, Context Budget, and Agent Speedup supply back-of-the-envelope models whose parameter ranges can be checked against published data.
- Surveyed literature on memory management, tool protocols, multi-agent coordination, and safety governance maps onto distinct layers of the ICA.
- Every layer of the architecture must pass through both the probabilistic and deterministic planes.
- Analogy boundaries include differences such as non-deterministic execution in models versus fixed silicon behavior.
- The principal open task is predictive validation of the heuristics against real deployments.
Where Pith is reading between the lines
- The ICA could serve as a common reference for comparing how different agent frameworks implement the same layer functions.
- The dual-plane separation might apply to hybrid codebases that combine model calls with conventional deterministic modules.
- Validation experiments would need to track whether the heuristics correctly forecast performance or failure modes in production LLM workloads.
- Strong deviations from statistical patterns in model outputs could mark the practical edge of the proposed mappings.
Load-bearing premise
The assumption that the probabilistic and non-deterministic character of model execution permits the same interface contracts and axioms used in deterministic silicon systems to be applied without fundamental revision.
What would settle it
A side-by-side implementation of two equivalent agent systems, one built according to the six-layer ICA with the three heuristics and one built without, that shows no measurable difference in scalability, error handling, or development effort.
Figures



































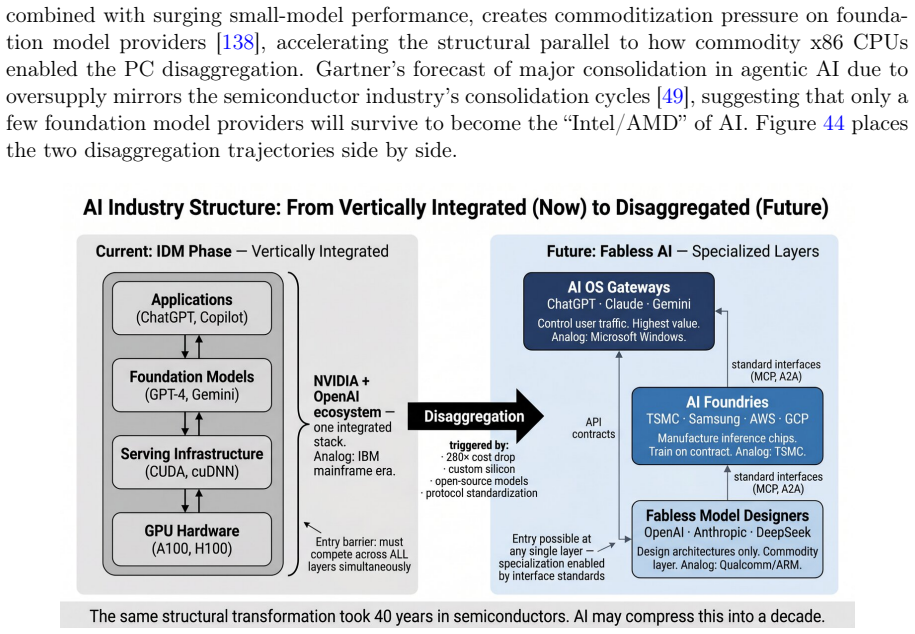









read the original abstract
Large language models are undergoing a transition from model technology to system technology. Engineering challenges like cache reuse, context capacity, agent scheduling, and permission control resemble classical computer systems problems. This raises a question: if we treat the LLM as a CPU, KV cache as processor cache, context window as main memory, and agent framework as an operating system, can decades of computer architecture wisdom guide next generation model native systems? This paper pursues this analogy as a visionary survey. We map computer architecture concepts onto the emerging model native stack, survey literature across LLM as OS, memory management, agent frameworks, tool protocols, multi agent coordination, cognitive architectures, and safety governance, finding that each addresses a different layer without a unifying model. We propose the Intelligent Computing Architecture (ICA): six functional layers with interface contracts and design axioms. We resolve the tension over whether the LLM resembles a CPU or OS via a dual plane architecture a probabilistic execution plane (what can be computed) and a deterministic control plane (what should be computed), with every layer passing through as a graded crossover. We propose three Amdahl style design heuristics Semantic Locality, Context Budget, and Agent Speedup as organizing back of envelope models, illustrate their parameter ranges with published data, and identify predictive validation as the principal open task. We articulate analogy boundaries, note differences between silicon and model era architectures, and propose a research roadmap. This is a conceptual and survey contribution with no new experimental results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a conceptual survey and proposal arguing that classical computer architecture principles can be transferred to model-native systems by treating LLMs as CPUs, KV caches as processor caches, context windows as main memory, and agent frameworks as operating systems. It surveys literature on LLM-as-OS, memory management, agent frameworks, tool protocols, multi-agent coordination, cognitive architectures, and safety, identifies the lack of a unifying model, and proposes the Intelligent Computing Architecture (ICA) as six functional layers with interface contracts and design axioms. The central contribution is a dual-plane architecture (probabilistic execution plane for what can be computed and deterministic control plane for what should be computed) with graded crossovers at every layer, plus three Amdahl-style heuristics (Semantic Locality, Context Budget, Agent Speedup) illustrated with published data ranges; predictive validation is explicitly identified as the principal open task, along with articulation of analogy boundaries.
Significance. If the proposed ICA framework and dual-plane organization prove to be a productive organizing lens, the work could help structure the emerging field of model-native systems by providing a common vocabulary and set of interface contracts that connect disparate research threads. The manuscript's explicit acknowledgment that it contains no new experimental results, its framing of the three heuristics as back-of-the-envelope models whose predictive power remains to be tested, and its discussion of analogy boundaries constitute appropriate scholarly restraint and strengthen the contribution as a survey rather than an overclaimed derivation.
minor comments (3)
- [Abstract] Abstract: the sentence 'We resolve the tension over whether the LLM resembles a CPU or OS via a dual plane architecture a probabilistic execution plane...' is missing punctuation and a connecting phrase, reducing readability of the central architectural claim.
- [Abstract] Abstract: 'back of envelope models' should be hyphenated as 'back-of-the-envelope models' for standard usage.
- The manuscript would benefit from an explicit table or diagram summarizing the six ICA layers, their interface contracts, and how the probabilistic/deterministic planes cross each layer, to make the proposal more immediately usable by readers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive summary of our manuscript. The positive assessment of the ICA framework, dual-plane architecture, and the explicit acknowledgment of its conceptual nature and lack of new experiments aligns with our intent. The recommendation for minor revision is noted. No specific major comments were provided in the report, so we have no point-by-point revisions to address.
Circularity Check
No significant circularity
full rationale
The manuscript is a conceptual survey and architectural proposal that maps existing literature onto a six-layer ICA model with dual probabilistic/deterministic planes and three Amdahl-style heuristics. No equations, fitted parameters, or closed-form derivations appear; the contribution consists of organizing analogies and interface contracts rather than any result that reduces to its own inputs by construction. Self-citations, if present, are not load-bearing for any central claim, and the paper explicitly flags predictive validation as future work rather than asserting transfer guarantees. The derivation chain is therefore self-contained as a framing exercise.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Computer-architecture principles transfer usefully to LLM-based systems via the stated component mappings
invented entities (3)
-
Intelligent Computing Architecture (ICA) with six functional layers
no independent evidence
-
Dual probabilistic execution plane and deterministic control plane
no independent evidence
-
Semantic Locality, Context Budget, and Agent Speedup heuristics
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint, 2024
Marah Abdin et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint, 2024
2024
-
[2]
Steven Abreu, Sumit Bam Shrestha, Rui-Jie Zhu, and Jason Eshraghian. Neuromor- phic principles for efficient large language models on intel loihi 2.arXiv preprint arXiv:2503.18002, 2025
arXiv 2025
-
[3]
Taming throughput-latency tradeoff in llm inference with sarathi-serve
Anshuman Agrawal, Vivek Kedia, Jayashree Panwar, Aayush Mohanty, Aviral Malviya, Nikhil Mangal, Apurv Arya, et al. Taming throughput-latency tradeoff in llm inference with sarathi-serve. InUSENIX Symposium on Operating Systems Design and Implemen- tation, 2024
2024
-
[4]
Gene M. Amdahl. Validity of the single processor approach to achieving large scale com- puting capabilities. InProceedings of the April 18–20, 1967, Spring Joint Computer Con- ference (AFIPS), pages 483–485, 1967
1967
-
[5]
2026 agentic coding trends report: How coding agents are reshaping software development.https://resources.anthropic.com/hubfs/2026%20Agentic%20Coding% 20Trends%20Report.pdf, 2026
Anthropic. 2026 agentic coding trends report: How coding agents are reshaping software development.https://resources.anthropic.com/hubfs/2026%20Agentic%20Coding% 20Trends%20Report.pdf, 2026. Accessed: 2026-05-29
2026
-
[6]
Configure the sandboxed bash tool – claude code docs, 2026
Anthropic. Configure the sandboxed bash tool – claude code docs, 2026. Accessed: 2026- 05-29
2026
-
[7]
Connect claude code to tools via mcp – claude code docs, 2026
Anthropic. Connect claude code to tools via mcp – claude code docs, 2026. Accessed: 2026-05-29
2026
-
[8]
Create custom subagents – claude code docs, 2026
Anthropic. Create custom subagents – claude code docs, 2026. Accessed: 2026-05-29
2026
-
[9]
Extend claude with skills – claude code docs, 2026
Anthropic. Extend claude with skills – claude code docs, 2026. Accessed: 2026-05-29
2026
-
[10]
How claude remembers your project – claude code docs, 2026
Anthropic. How claude remembers your project – claude code docs, 2026. Accessed: 2026-05-29
2026
-
[11]
Overview – claude code docs, 2026
Anthropic. Overview – claude code docs, 2026. Accessed: 2026-05-29
2026
-
[12]
Security – claude code docs, 2026
Anthropic. Security – claude code docs, 2026. Accessed: 2026-05-29
2026
-
[13]
Apple M1 chip: An Apple silicon breakthrough, 2020
Apple. Apple M1 chip: An Apple silicon breakthrough, 2020. Announced November 2020. 109
2020
-
[14]
big.LITTLE processing with ARM cortex-a15 & cortex-a7
ARM. big.LITTLE processing with ARM cortex-a15 & cortex-a7. ARM Whitepaper, 2012
2012
-
[15]
Arpaci-Dusseau and Andrea C
Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau. Operating systems: Three easy pieces, 2023. Version 1.10; accessed 2026-05-29
2023
-
[16]
What is the autogpt platform?, 2026
AutoGPT. What is the autogpt platform?, 2026. Accessed: 2026-05-29
2026
-
[17]
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, et al. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3639–3664, 2025
2025
-
[18]
Hier- archical caching for agentic workflows: A multi-level architecture to reduce tool execution overhead.Machine Learning and Knowledge Extraction, 8(2):30, 2026
Farhana Begum, Craig Scott, Kofi Nyarko, Mansoureh Jeihani, and Fahmi Khalifa. Hier- archical caching for agentic workflows: A multi-level architecture to reduce tool execution overhead.Machine Learning and Knowledge Extraction, 8(2):30, 2026
2026
-
[19]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[20]
Internet of agents: Weaving a web of heterogeneous agents for collaborative intelligence
Weize Chen, Ziming You, Ran Li, Chen Qian, Chenyang Zhao, Cheng Yang, Ruobing Xie, Zhiyuan Liu, Maosong Sun, et al. Internet of agents: Weaving a web of heterogeneous agents for collaborative intelligence. InInternational Conference on Learning Representa- tions, volume 2025, pages 36374–36411, 2025
2025
-
[21]
AI industry landscape report 2025
China Europe International Business School (CEIBS). AI industry landscape report 2025. Industry Report, 2025. Analysis of AI industry structure, agent market competition and ecosystem dynamics
2025
-
[22]
Systems security foundations for agentic computing.arXiv preprint arXiv:2512.01295, 2025
MihaiChristodorescu, EarlenceFernandes, AshishHooda, SomeshJha, JohannRehberger, Kamalika Chaudhuri, Xiaohan Fu, Khawaja Shams, Guy Amir, Jihye Choi, et al. Systems security foundations for agentic computing.arXiv preprint arXiv:2512.01295, 2025
arXiv 2025
-
[23]
The right to be forgotten vs
Cloud Security Alliance. The right to be forgotten vs. AI’s infinite memory. https://www.dpo-india.com/Blogs/right-to-forgot/, 2025. Accessed: 2026-05-29
2025
-
[24]
Devin: The first autonomous AI software engineer, 2024
Cognition AI. Devin: The first autonomous AI software engineer, 2024. Announced March 2024; accessed 2026-05-29
2024
-
[25]
Intense competition across the AI stack
Computer & Communications Industry Association (CCIA). Intense competition across the AI stack. Policy Analysis, 2025. Analysis of competition dynamics across the AI technology stack
2025
-
[26]
An experimental time-sharing system
Fernando J Corbató, Marjorie Merwin-Daggett, and Robert C Daley. An experimental time-sharing system. InProceedings of the May 1-3, 1962, spring joint computer confer- ence, pages 335–344, 1962
1962
-
[27]
Introduction and overview of the multics sys- tem
Fernando J Corbató and Victor A Vyssotsky. Introduction and overview of the multics sys- tem. InProceedings of the November 30–December 1, 1965, fall joint computer conference, part I, pages 185–196, 1965
1965
-
[28]
Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, J
James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, J. J. Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, et al. Spanner: Google’s globally-distributed database. InUSENIX Symposium on Operating Systems Design and Implementation, 2012. 110
2012
-
[29]
CL1: The first biological computer, 2025
Cortical Labs. CL1: The first biological computer, 2025. Commercial biological computing system; accessed 2026-05-29
2025
-
[30]
xv6: a simple, unix-like teaching operating system, 2022
Russ Cox, Frans Kaashoek, and Robert Morris. xv6: a simple, unix-like teaching operating system, 2022
2022
-
[31]
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1280–1297, 2024
2024
-
[32]
Flashattention-2: Faster attention with better parallelism and work partition- ing
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partition- ing. InInternational Conference on Learning Representations, volume 2024, pages 35549– 35562, 2024
2024
-
[33]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashatten- tion: Fast and memory-efficient exact attention with io-awareness.Advances in Neural Information Processing Systems, 35:16344–16359, 2022
2022
-
[34]
Defeating prompt injections by design.arXiv preprint arXiv:2503.18813, 2025
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tramèr. Defeating prompt injections by design.arXiv preprint arXiv:2503.18813, 2025
Pith/arXiv arXiv 2025
-
[35]
Dennard, Fritz H
Robert H. Dennard, Fritz H. Gaensslen, Hwa-Nien Yu, V. Leo Rideout, Ernest Bassous, and Andre R. LeBlanc. Design of ion-implanted MOSFET’s with very small physical dimensions.IEEE Journal of Solid-State Circuits, 9(5):256–268, 1974
1974
-
[36]
Peter J. Denning. Thrashing: Its causes and prevention. InProceedings of the AFIPS Fall Joint Computer Conference, pages 915–922, 1968
1968
-
[37]
Working set analytics.ACM Computing Surveys (CSUR), 53(6):1–36, 2021
Peter J Denning. Working set analytics.ACM Computing Surveys (CSUR), 53(6):1–36, 2021
2021
-
[38]
Mcp adoption statistics 2026: Model context protocol, 2026
Digital Applied. Mcp adoption statistics 2026: Model context protocol, 2026. Accessed: 2026-05-29
2026
-
[39]
Longrope: Extending llm context window beyond 2 million tokens.International Conference on Machine Learning, 2024
Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, and Mao Yang. Longrope: Extending llm context window beyond 2 million tokens.International Conference on Machine Learning, 2024
2024
-
[40]
Thomas Dohmke, Marco Iansiti, and Greg Richards. Sea change in software development: Economic and productivity analysis of the AI-powered developer lifecycle.arXiv preprint arXiv:2306.15033, 2023
arXiv 2023
-
[41]
Neuronal wiring diagram of an adult brain.Nature, 634(8032):124–138, 2024
Sven Dorkenwald, Arie Matsliah, Amy R Sterling, Philipp Schlegel, Szi-Chieh Yu, Claire E McKellar, Albert Lin, Marta Costa, Katharina Eichler, Yijie Yin, et al. Neuronal wiring diagram of an adult brain.Nature, 634(8032):124–138, 2024
2024
-
[42]
What every programmer should know about memory.Red Hat, Inc., 2007
Ulrich Drepper. What every programmer should know about memory.Red Hat, Inc., 2007
2007
-
[43]
Pengfei Du. Memory for autonomous llm agents: Mechanisms, evaluation, and emerging frontiers.arXiv preprint arXiv:2603.07670, 2026. 111
arXiv 2026
-
[44]
Abul Ehtesham, Aditi Singh, Gaurav Kumar Gupta, and Saket Kumar. A survey of agent interoperability protocols: Model context protocol (mcp), agent communication protocol (acp), agent-to-agent protocol (a2a), and agent network protocol (anp).arXiv preprint arXiv:2505.02279, 2025
arXiv 2025
-
[45]
Amant, Karthikeyan Sankaralingam, and Doug Burger
Hadi Esmaeilzadeh, Emily Blem, Renee St. Amant, Karthikeyan Sankaralingam, and Doug Burger. Dark silicon and the end of multicore scaling. InProceedings of the 38th annual international symposium on Computer architecture, pages 365–376, 2011
2011
-
[46]
Euartificialintelligenceact: Officialdevelopmentsandcompliance,
EuropeanCommission. Euartificialintelligenceact: Officialdevelopmentsandcompliance,
-
[47]
Accessed: 2026-05-29
2026
-
[48]
Switch transformers: Scaling to tril- lion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to tril- lion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[49]
James Fodor. Line goes up? inherent limitations of benchmarks for evaluating large language models.arXiv preprint arXiv:2502.14318, 2025
arXiv 2025
-
[50]
Top strategic technology trends 2026: AI and beyond
Gartner. Top strategic technology trends 2026: AI and beyond. Gartner Research, 2026. Prediction on AI technology trends
2026
-
[51]
Yingqiang Ge, Yujie Ren, Wenyue Hua, Shuyuan Xu, Juntao Tan, and Yongfeng Zhang. Llm as os, agents as apps: Envisioning aios, agents and the aios-agent ecosystem.arXiv preprint arXiv:2312.03815, 2023
arXiv 2023
-
[52]
Ai and memory wall.IEEE Micro, 44(3):33–39, 2024
Amir Gholami, Zhewei Yao, Sehoon Kim, Coleman Hooper, Michael W Mahoney, and Kurt Keutzer. Ai and memory wall.IEEE Micro, 44(3):33–39, 2024
2024
-
[53]
Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services.SIGACT News, 33(2):51–59, 2002
Seth Gilbert and Nancy Lynch. Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services.SIGACT News, 33(2):51–59, 2002
2002
-
[54]
Prompt cache: Modular attention reuse for low-latency inference.Proceedings of Machine Learning and Systems, 6:325–338, 2024
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference.Proceedings of Machine Learning and Systems, 6:325–338, 2024
2024
-
[55]
Hector A Gonzalez, Jiaxin Huang, Florian Kelber, Khaleelulla Khan Nazeer, Tim Langer, Chen Liu, Matthias Lohrmann, Amirhossein Rostami, Mark Schöne, Bernhard Vogginger, et al. Spinnaker2: A large-scale neuromorphic system for event-based and asynchronous machine learning.arXiv preprint arXiv:2401.04491, 2024
arXiv 2024
-
[56]
A2A: Agent-to-agent protocol, 2025
Google. A2A: Agent-to-agent protocol, 2025. Accessed: 2026-05-29
2025
-
[57]
Google donates agent2agent (a2a) protocol to the linux foundation, 2025
Google Cloud. Google donates agent2agent (a2a) protocol to the linux foundation, 2025. Accessed: 2026-05-29
2025
-
[58]
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[59]
Hennessy and David A
John L. Hennessy and David A. Patterson.Computer Architecture: A Quantitative Ap- proach. Morgan Kaufmann, 6 edition, 2017
2017
-
[60]
Hennessy and David A
John L. Hennessy and David A. Patterson. A new golden age for computer architecture. Communications of the ACM, 62(2):48–60, 2019. Turing Lecture
2019
-
[61]
L2mac: Large language model automatic computer for extensive code generation
Samuel Holt, Max Ruiz Luyten, and Mihaela van der Schaar. L2mac: Large language model automatic computer for extensive code generation. InInternational Conference on Learning Representations, volume 2024, pages 36762–36822, 2024. 112
2024
-
[62]
Metagpt: Meta program- ming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Steven Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta program- ming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, volume 2024, pages 23247–23275, 2024
2024
-
[63]
Coleman Hooper, Sehoon Kim, others, and Michael W. Mahoney. KVQuant: Towards 10 million context length LLM inference with KV cache quantization. InAdvances in Neural Information Processing Systems, 2024
2024
-
[64]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024
Pith/arXiv arXiv 2024
-
[65]
Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 32779–32798, 2025
2025
-
[66]
Text generation inference documentation, 2026
Hugging Face. Text generation inference documentation, 2026. Accessed: 2026-05-29
2026
-
[67]
Intel thread director technology
Intel. Intel thread director technology. Intel Developer Documentation, 2022. Related to 12th Gen Alder Lake heterogeneous scheduling
2022
-
[68]
Intel builds world’s largest neuromorphic system to enable more sustainable ai
Intel. Intel builds world’s largest neuromorphic system to enable more sustainable ai. Intel Labs, 2024. Announced April 2024
2024
-
[69]
Intel 64 and ia-32 architectures software developer’s manual, 2026
Intel. Intel 64 and ia-32 architectures software developer’s manual, 2026. Accessed: 2026- 05-29
2026
-
[70]
Efficient context management for LLM coding agents, 2025
JetBrains Research. Efficient context management for LLM coding agents, 2025. Accessed: 2026-05-29
2025
-
[71]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
Pith/arXiv arXiv 2024
-
[72]
Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, volume 2024, pages 54107–54157, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, volume 2024, pages 54107–54157, 2024
2024
-
[73]
In vitro neurons learn and exhibit sentience when embodied in a simulated game-world.Neuron, 110(23):3952–3969, 2022
Brett J Kagan, Andy C Kitchen, Nhi T Tran, Forough Habibollahi, Moein Khajehne- jad, Bradyn J Parker, Anjali Bhat, Ben Rollo, Adeel Razi, and Karl J Friston. In vitro neurons learn and exhibit sentience when embodied in a simulated game-world.Neuron, 110(23):3952–3969, 2022
2022
-
[74]
Memory OS of AI agent
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory OS of AI agent. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
2025
-
[75]
LLM as OS
Andrej Karpathy. LLMs are the kernel process of a new operating system. Public remark, UC Berkeley BAIR colloquium and social media, October 2023, 2023. Widely circulated articulation of the “LLM as OS” analogy
2023
-
[76]
Quixer: A quantum transformer model.arXiv preprint arXiv:2406.04305, 2024
Nikhil Khatri, Gabriel Matos, Luuk Coopmans, and Stephen Clark. Quixer: A quantum transformer model.arXiv preprint arXiv:2406.04305, 2024. 113
arXiv 2024
-
[77]
Klemmer, Stefan Albert Horstmann, and Nikhil Patnaik
Jan H. Klemmer, Stefan Albert Horstmann, and Nikhil Patnaik. Using AI assistants in software development: A qualitative study on security practices and concerns.arXiv preprint arXiv:2405.06371, 2024
arXiv 2024
-
[78]
Single-isa heterogeneous multi-core architectures: The potential for pro- cessor power reduction
Rakesh Kumar, Keith I Farkas, Norman P Jouppi, Parthasarathy Ranganathan, and Dean M Tullsen. Single-isa heterogeneous multi-core architectures: The potential for pro- cessor power reduction. InProceedings. 36th Annual IEEE/ACM International Symposium on Microarchitecture, 2003. MICRO-36., pages 81–92. IEEE, 2003
2003
-
[79]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention.Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles, 2023
2023
-
[80]
Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Boratko, Yi Luan, Sébastien M. R. Arnold, Vincent Perot, Siddharth Dalmia, et al. Can long-context language models subsume retrieval, RAG, SQL, and more?arXiv preprint arXiv:2406.13121, 2024
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.