Large-scale Uncertainty Quantification for Latent Variable Models Using Subsampling Markov Chain Monte Carlo
Pith reviewed 2026-06-28 23:19 UTC · model grok-4.3
The pith
A joint jump-diffusion limit for SGLD-Gibbs reveals how to tune hyperparameters for statistically meaningful uncertainty quantification in latent variable models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under appropriate space-time rescaling, the global parameters in SGLD-Gibbs converge to a diffusion-type limit while each latent variable converges to a jump process. This joint jump-diffusion structure reveals the contribution of latent-variable randomness to the stationary distribution of the global parameters, enabling explicit guidance on hyperparameter tuning for meaningful uncertainty quantification.
What carries the argument
The joint asymptotic jump-diffusion limit under space-time rescaling, which characterizes the interaction between global parameters and latent variables in the scaled process.
If this is right
- Global parameters converge to a diffusion-type limit.
- Each latent variable converges to a jump process reflecting intermittent Gibbs updates.
- The joint structure allows explicit characterization of how latent randomness affects global parameter stationary distribution.
- Explicit hyperparameter tuning guidance ensures statistically meaningful uncertainty quantification.
- SGLD-Gibbs with the guidance outperforms stochastic variational inference in estimates and predictions.
Where Pith is reading between the lines
- The tuning rules may extend to other subsampling MCMC methods that combine continuous and discrete updates.
- Similar scaling limits could inform tuning in non-latent variable models with intermittent sampling.
- Empirical validation of the jump-diffusion limits in high-dimensional settings would strengthen applicability to large-scale problems.
- The framework suggests ways to adjust update frequencies for better mixing in latent variable inference.
Load-bearing premise
The space-time rescaling must be chosen so that the intermittent Gibbs updates produce a jump-process limit for the latent variables whose contribution to the global-parameter stationary distribution can be explicitly characterized.
What would settle it
A simulation or analysis showing that the proposed tuning rules fail to produce calibrated uncertainty estimates when the space-time rescaling does not yield the predicted jump-diffusion behavior.
Figures

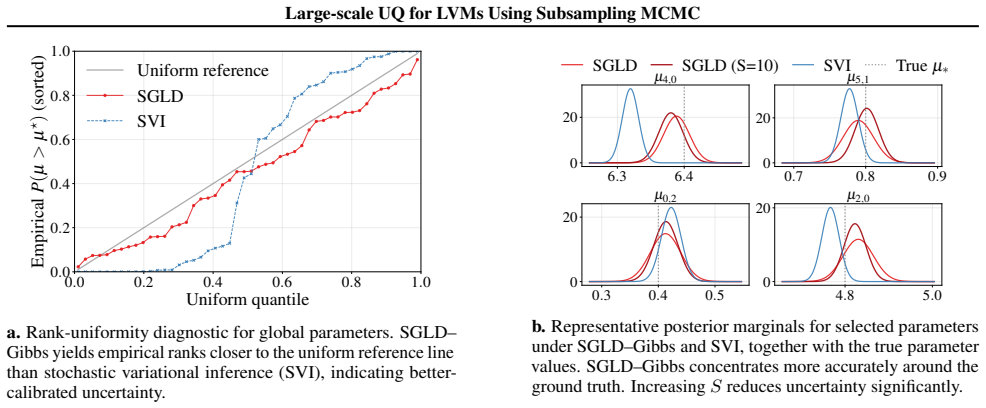
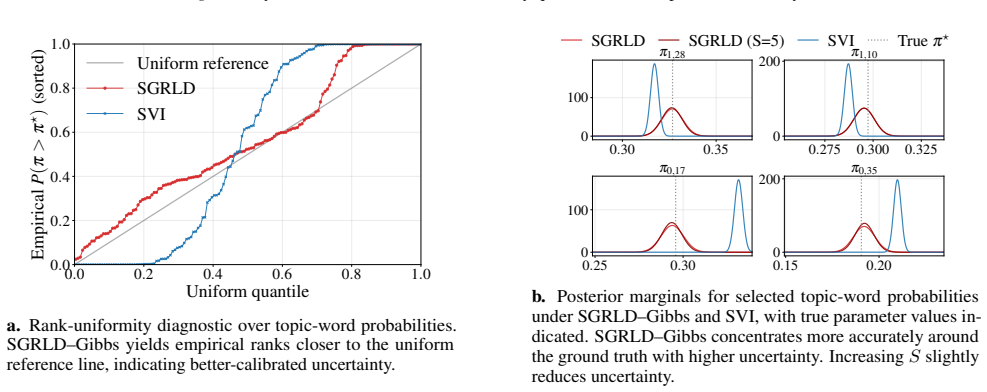
read the original abstract
Stochastic gradient Langevin dynamics combined with Gibbs updates (SGLD--Gibbs) provides a highly scalable approach to approximate Bayesian inference in latent variable models. However, it remains unclear how to tune the algorithm's hyperparameters in a principled manner to ensure the uncertainty estimates are statistically meaningful. In this work, we address this gap in tuning guidance by developing a statistical scaling limit theory for SGLD--Gibbs. We derive a joint asymptotic limit for the global parameters and latent variables under appropriate space-time rescaling. We show that global parameters converge to a diffusion-type limit, while each latent variable converges to a jump process, reflecting the use of intermittent Gibbs updates. This joint jump-diffusion structure reveals how latent-variable randomness contributes to the stationary distribution of the global parameters. We leverage our results to propose explicit guidance on hyperparameter tuning for SGLD--Gibbs that ensures meaningful uncertainty quantification. Numerical experiments show that SGLD--Gibbs with our tuning guidance leads to better parameter estimates, uncertainty quantification, and predictive performance than stochastic variational inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a statistical scaling-limit theory for the SGLD-Gibbs algorithm in latent-variable models. Under a specific space-time rescaling, the global parameters are shown to converge to a diffusion process while each latent variable converges to a jump process induced by the intermittent Gibbs steps. The resulting joint jump-diffusion structure is used to characterize the stationary distribution of the global parameters and to extract explicit hyperparameter tuning rules that aim to produce calibrated uncertainty estimates. Numerical experiments are reported to demonstrate improved parameter recovery, uncertainty quantification, and predictive performance relative to stochastic variational inference.
Significance. If the limit theorem and the extraction of tuning rules are valid, the work supplies principled, theoretically grounded guidance for hyperparameter selection in a scalable hybrid MCMC method for latent-variable models. This directly addresses a practical gap in ensuring statistically meaningful uncertainty quantification at large scale and could influence the design of sampling-based inference procedures in machine learning.
minor comments (3)
- [Introduction] The precise statement of the space-time rescaling (including the scaling exponents for time, step size, and Gibbs frequency) should be stated explicitly in the introduction or early in §3 so that readers can immediately connect the abstract claim to the theorem.
- [Experiments] In the numerical experiments, the reported metrics for uncertainty quantification (e.g., coverage or calibration plots) would benefit from an explicit comparison against the theoretical stationary variance derived from the limit; currently the connection is only qualitative.
- [Theorem statement] A short remark on the regularity conditions required for the jump-diffusion limit (e.g., Lipschitz assumptions on the potential or boundedness of the latent-variable conditional) would help readers assess applicability to common latent-variable models.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work, recognition of its significance for principled hyperparameter tuning in scalable MCMC for latent-variable models, and recommendation of minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The paper's central contribution is a derivation of a joint jump-diffusion scaling limit for SGLD-Gibbs under space-time rescaling, followed by extraction of hyperparameter tuning rules from the resulting stationary distribution. This is a standard mathematical analysis of MCMC dynamics (global parameters to diffusion, latent variables to jump process) whose output is an external statistical property (calibrated uncertainty quantification) rather than a quantity defined by the same procedure. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described derivation chain; the tuning guidance is downstream of the limit rather than presupposed by it. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The model and algorithm satisfy the regularity conditions required for the joint space-time scaling limit to exist and separate into diffusion and jump components.
Reference graph
Works this paper leans on
-
[1]
Large-Scale Distributed Bayesian Matrix Factorization using Stochastic Gradient MCMC
Ahn, S., Korattikara, A., Liu, N., Rajan, S., and Welling, M. Large-scale distributed B ayesian matrix factorization using stochastic gradient MCMC , 2015. URL https://arxiv.org/abs/1503.01596
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[2]
Anastasiou, A., Balasubramanian, K., and Erdogdu, M. A. Normal approximation for stochastic gradient descent via non-asymptotic rates of martingale CLT . In Beygelzimer, A. and Hsu, D. (eds.), Proceedings of the Thirty-Second Conference on Learning Theory, volume 99 of Proceedings of Machine Learning Research, pp.\ 115--137. PMLR, 25--28 Jun 2019. URL htt...
2019
-
[3]
B., Gheissari, R., and Jagannath, A
Arous, G. B., Gheissari, R., and Jagannath, A. High-dimensional limit theorems for SGD : effective dynamics and critical scaling. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA, 2022. Curran Associates Inc. ISBN 9781713871088
2022
-
[4]
Bottou, L., Curtis, F. E., and Nocedal, J. Optimization methods for large-scale machine learning. SIAM Review, 60 0 (2): 0 223--311, 2018. doi:10.1137/16M1080173. URL https://doi.org/10.1137/16M1080173
-
[5]
Stochastic gradient and L angevin processes
Cheng, X., Yin, D., Bartlett, P., and Jordan, M. Stochastic gradient and L angevin processes. In International Conference on Machine Learning, pp.\ 1810--1819. PMLR, 2020
2020
-
[6]
Collins-Woodfin, E., Paquette, C., Paquette, E., and Seroussi, I. Hitting the high-dimensional notes: An ode for sgd learning dynamics on glms and multi-index models, 2023. URL https://arxiv.org/abs/2308.08977
-
[7]
Collins-Woodfin, E., Seroussi, I., Malaxechebarr\' a, B. n. G., Mackenzie, A. W., Paquette, E., and Paquette, C. The high line: exact risk and learning rate curves of stochastic adaptive learning rate algorithms. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS '24, Red Hook, NY, USA, 2024. Curran Associat...
2024
-
[8]
Efficient and generalizable tuning strategies for stochastic gradient mcmc
Coullon, J., South, L., and Nemeth, C. Efficient and generalizable tuning strategies for stochastic gradient mcmc. Statistics and Computing, 33 0 (3), April 2023. ISSN 0960-3174. doi:10.1007/s11222-023-10233-3. URL https://doi.org/10.1007/s11222-023-10233-3
-
[9]
Danaher, P. J. Optimal microtargeting of advertising. Journal of Marketing Research, 60 0 (3): 0 564--584, 2023. doi:10.1177/00222437221116034. URL https://doi.org/10.1177/00222437221116034
-
[10]
Bridging the gap between constant step size stochastic gradient descent and M arkov chains
Dieuleveut, A., Durmus, A., and Bach, F. Bridging the gap between constant step size stochastic gradient descent and M arkov chains . The Annals of Statistics, 48 0 (3): 0 1348 -- 1382, 2020. URL https://doi.org/10.1214/19-AOS1850
-
[11]
Ethier, S. N. and Kurtz, T. G. Markov Processes: Characterization and Convergence . Wiley Series in Probability and Statistics. John Wiley & Sons, 2009. ISBN 9780470412035
2009
-
[12]
Escaping from saddle points—online stochastic gradient for tensor decomposition
Ge, R., Huang, F., Jin, C., and Yuan, Y. Escaping from saddle points—online stochastic gradient for tensor decomposition. In Conference on learning theory, pp.\ 797--842. PMLR, 2015
2015
-
[13]
B ayesian Data Analysis
Gelman, A., Carlin, J., Stern, H., Dunson, D., Vehtari, A., and Rubin, D. B ayesian Data Analysis . Chapman & Hall/CRC Texts in Statistical Science Series. CRC, Boca Raton, Florida, third edition, 2013. ISBN 9781439840955 1439840954. URL https://stat.columbia.edu/ gelman/book/
2013
-
[14]
Giordano, R., Broderick, T., and Jordan, M. I. Covariances, robustness and V ariational B ayes. J. Mach. Learn. Res., 19 0 (1): 0 1981–2029, January 2018. ISSN 1532-4435
1981
-
[15]
Online learning for L atent D irichlet A llocation
Hoffman, M., Bach, F., and Blei, D. Online learning for L atent D irichlet A llocation. In Lafferty, J., Williams, C., Shawe-Taylor, J., Zemel, R., and Culotta, A. (eds.), Advances in Neural Information Processing Systems, volume 23. Curran Associates, Inc., 2010. URL https://proceedings.neurips.cc/paper_files/paper/2010/file/71f6278d140af599e06ad9bf1ba03...
2010
-
[16]
D., Blei, D
Hoffman, M. D., Blei, D. M., Wang, C., and Paisley, J. Stochastic variational inference. Journal of Machine Learning Research, 14 0 (40): 0 1303--1347, 2013. URL http://jmlr.org/papers/v14/hoffman13a.html
2013
-
[17]
Huggins, J. H. and Miller, J. W. Reproducible parameter inference using bagged posteriors . Electronic Journal of Statistics, 18 0 (1), 2024. ISSN 1935-7524. doi:10.1214/24-ejs2237
-
[18]
M., and Jordan, M
Jin, C., Ge, R., Netrapalli, P., Kakade, S. M., and Jordan, M. I. How to escape saddle points efficiently. In International conference on machine learning, pp.\ 1724--1732. PMLR, 2017
2017
-
[19]
and van der Vaart, A
Kleijn, B. and van der Vaart, A. The Bernstein-Von-Mises theorem under misspecification. Electronic Journal of Statistics, 0 (6): 0 354--381, 2012
2012
-
[20]
Kucukelbir, A., Tran, D., Ranganath, R., Gelman, A., and Blei, D. M. Automatic differentiation variational inference. J. Mach. Learn. Res., 18 0 (1): 0 430–474, January 2017. ISSN 1532-4435
2017
-
[21]
and Yin, G
Kushner, H. and Yin, G. Stochastic Approximation and Recursive Algorithms and Applications. Stochastic Modelling and Applied Probability. Springer New York, 2003. ISBN 9780387008943. URL https://books.google.com/books?id=_0bIieuUJGkC
2003
-
[22]
Kushner, H. J. and Huang, H. Asymptotic properties of stochastic approximations with constant coefficients. SIAM Journal on Control and Optimization, 19 0 (1): 0 87--105, 1981. doi:10.1137/0319007. URL https://doi.org/10.1137/0319007
-
[23]
Kushner, H. J. and Yang, J. Stochastic approximation with averaging of the iterates: Optimal asymptotic rate of convergence for general processes. SIAM Journal on Control and Optimization, 31 0 (4): 0 1045--1062, 1993. doi:10.1137/0331047. URL https://doi.org/10.1137/0331047
-
[24]
Scalable MCMC for mixed membership stochastic blockmodels
Li, W., Ahn, S., and Welling, M. Scalable MCMC for mixed membership stochastic blockmodels. In Gretton, A. and Robert, C. C. (eds.), Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, volume 51 of Proceedings of Machine Learning Research, pp.\ 723--731, Cadiz, Spain, 09--11 May 2016. PMLR. URL https://proceedings.m...
2016
-
[25]
Loaiza-Maya, R. and Nibbering, D. Fast V ariational B ayes methods for multinomial probit models. Journal of Business & Economic Statistics, 41 0 (4): 0 1352--1363, 2023. doi:10.1080/07350015.2022.2139267. URL https://doi.org/10.1080/07350015.2022.2139267
-
[26]
Hybrid unadjusted L angevin methods for high-dimensional latent variable models
Loaiza-Maya, R., Nibbering, D., and Zhu, D. Hybrid unadjusted L angevin methods for high-dimensional latent variable models. Journal of Econometrics, 241 0 (2): 0 105741, 2024. ISSN 0304-4076. doi:https://doi.org/10.1016/j.jeconom.2024.105741. URL https://www.sciencedirect.com/science/article/pii/S0304407624000873
-
[27]
D., and Blei, D
Mandt, S., Hoffman, M. D., and Blei, D. M. Stochastic gradient descent as approximate B ayesian inference. Journal of Machine Learning Research, 18 0 (134): 0 1--35, 2017. URL http://jmlr.org/papers/v18/17-214.html
2017
-
[28]
C., Pillaud-Vivien, L., and Saul, L
Margossian, C. C., Pillaud-Vivien, L., and Saul, L. K. Variational inference for uncertainty quantification: An analysis of trade-offs. Journal of Machine Learning Research, 26 0 (202): 0 1--41, 2025
2025
- [29]
-
[30]
Dynamical mean-field theory for stochastic gradient descent in G aussian mixture classification*
Mignacco, F., Krzakala, F., Urbani, P., and Zdeborová, L. Dynamical mean-field theory for stochastic gradient descent in G aussian mixture classification*. Journal of Statistical Mechanics: Theory and Experiment, 2021 0 (12): 0 124008, December 2021. ISSN 1742-5468. doi:10.1088/1742-5468/ac3a80. URL http://dx.doi.org/10.1088/1742-5468/ac3a80
-
[31]
J., Wainwright, M
Mou, W., Li, C. J., Wainwright, M. J., Bartlett, P. L., and Jordan, M. I. On linear stochastic approximation: Fine-grained P olyak- R uppert and non-asymptotic concentration. In Abernethy, J. and Agarwal, S. (eds.), Proceedings of Thirty Third Conference on Learning Theory, volume 125 of Proceedings of Machine Learning Research, pp.\ 2947--2997. PMLR, 09-...
2020
-
[32]
and Bach, F
Moulines, E. and Bach, F. Non-asymptotic analysis of stochastic approximation algorithms for machine learning. In Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., and Weinberger, K. (eds.), Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc., 2011. URL https://proceedings.neurips.cc/paper_files/paper/2011/file/4000...
2011
-
[33]
Murphy, K. P. Probabilistic Machine Learning: Advanced Topics. MIT Press, 2023. URL http://probml.github.io/book2
2023
-
[34]
Negrea, J., Yang, J., Feng, H., Roy, D. M., and Huggins, J. H. Tuning stochastic gradient algorithms for statistical inference via large-sample asymptotics, 2023. URL https://arxiv.org/abs/2207.12395
-
[35]
Journal of the American Statistical Association , volume =
Nemeth, C. and Fearnhead, P. Stochastic gradient Markov chain M onte C arlo. Journal of the American Statistical Association, 116 0 (533): 0 433--450, 2021. doi:10.1080/01621459.2020.1847120. URL https://doi.org/10.1080/01621459.2020.1847120
-
[36]
Robust stochastic approximation approach to stochastic programming
Nemirovski, A., Juditsky, A., Lan, G., and Shapiro, A. Robust stochastic approximation approach to stochastic programming. SIAM Journal on Optimization, 19 0 (4): 0 1574--1609, 2009. URL https://doi.org/10.1137/070704277
-
[37]
and Teh, Y
Patterson, S. and Teh, Y. W. Stochastic gradient R iemannian L angevin dynamics on the probability simplex. In Burges, C., Bottou, L., Welling, M., Ghahramani, Z., and Weinberger, K. (eds.), Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc., 2013. URL https://proceedings.neurips.cc/paper/2013/file/309928d4b100a5d75adff4...
2013
-
[38]
Scikit-learn: Machine learning in python
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., et al. Scikit-learn: Machine learning in python. Journal of Machine Learning Research, 12: 0 2825--2830, 2011
2011
-
[39]
Pflug, G. C. Stochastic minimization with constant step-size: Asymptotic laws. SIAM Journal on Control and Optimization, 24 0 (4): 0 655--666, 1986. doi:10.1137/0324039. URL https://doi.org/10.1137/0324039
-
[40]
Polyak, B. T. and Juditsky, A. B. Acceleration of stochastic approximation by averaging. SIAM Journal on Control and Optimization, 30 0 (4): 0 838--855, 1992. URL https://doi.org/10.1137/0330046
-
[41]
Qian, X., Xie, Z., Liu, X., and Zhang, S. Almost sure convergence rates and concentration of stochastic approximation and reinforcement learning with M arkovian noise, 2024. URL https://arxiv.org/abs/2411.13711
-
[42]
Making Gradient Descent Optimal for Strongly Convex Stochastic Optimization
Rakhlin, A., Shamir, O., and Sridharan, K. Making gradient descent optimal for strongly convex stochastic optimization. arXiv preprint arXiv:1109.5647, 2011
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[43]
Efficient estimations from a slowly convergent R obbins- M onro process
Ruppert, D. Efficient estimations from a slowly convergent R obbins- M onro process. 02 1988
1988
-
[44]
Rates of convergence in the central limit theorem for M arkov chains, with an application to td learning, 2024
Srikant, R. Rates of convergence in the central limit theorem for M arkov chains, with an application to td learning, 2024
2024
-
[45]
An invariance principle for the R obbins- M onro process in a H ilbert space
Walk, H. An invariance principle for the R obbins- M onro process in a H ilbert space. Zeitschrift f \"u r Wahrscheinlichkeitstheorie und Verwandte Gebiete , 39: 0 135--150, 1977. URL https://api.semanticscholar.org/CorpusID:119733417
1977
-
[46]
J., Negrea, J., Bourguin, S., and Huggins, J
Wang, X., Kasprzak, M. J., Negrea, J., Bourguin, S., and Huggins, J. H. Quantitative error bounds for scaling limits of stochastic iterative algorithms, 2025. URL https://arxiv.org/abs/2501.12212
-
[47]
Wang, Y., Ding, J., and Huggins, J. H. Accurate large-sample uncertainty quantification using stochastic gradient M arkov chain M onte C arlo. In Proceedings of the 43rd International Conference on Machine Learning, Proceedings of Machine Learning Research. PMLR, 2026
2026
-
[48]
and Teh, Y
Welling, M. and Teh, Y. W. B ayesian learning via stochastic gradient L angevin dynamics. In Getoor, L. and Scheffer, T. (eds.), ICML, pp.\ 681--688. Omnipress, 2011. URL http://dblp.uni-trier.de/db/conf/icml/icml2011.html#WellingT11
2011
-
[49]
Maximum likelihood estimation of misspecified models
White, H. Maximum likelihood estimation of misspecified models. Econometrica: Journal of the econometric society, pp.\ 1--25, 1982
1982
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.