Rethinking Amortized Neural Representations for High-Resolution Terrain Elevation Data
Pith reviewed 2026-06-28 22:29 UTC · model grok-4.3
The pith
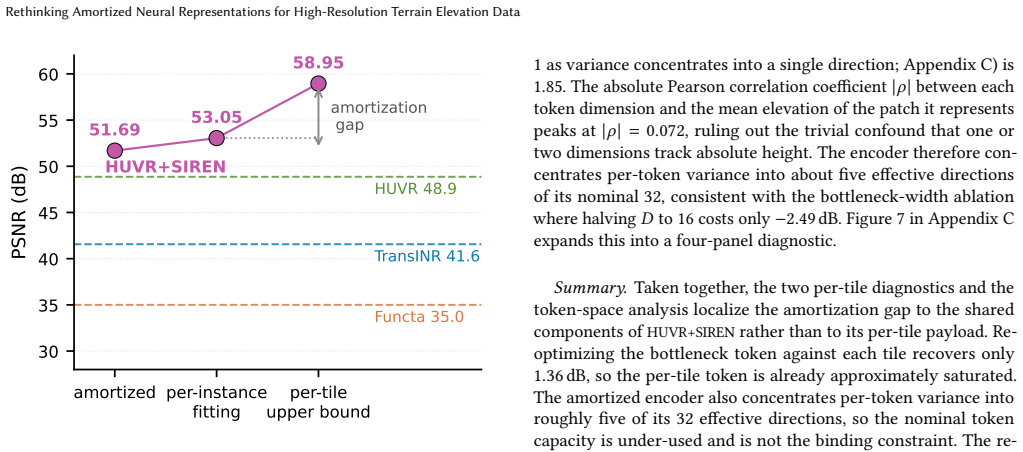
HUVR+SIREN attains the best height and derivative fidelity on the 1 m/pixel terrain benchmark with no added per-tile storage and lower decode cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
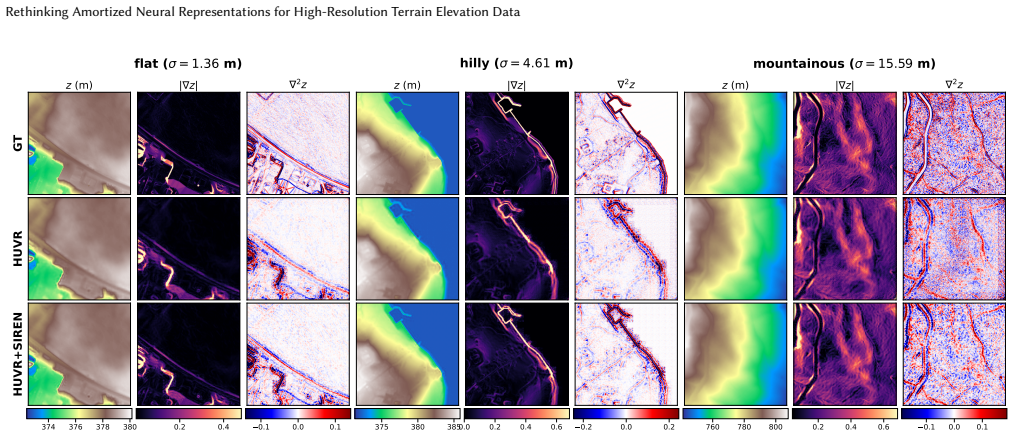
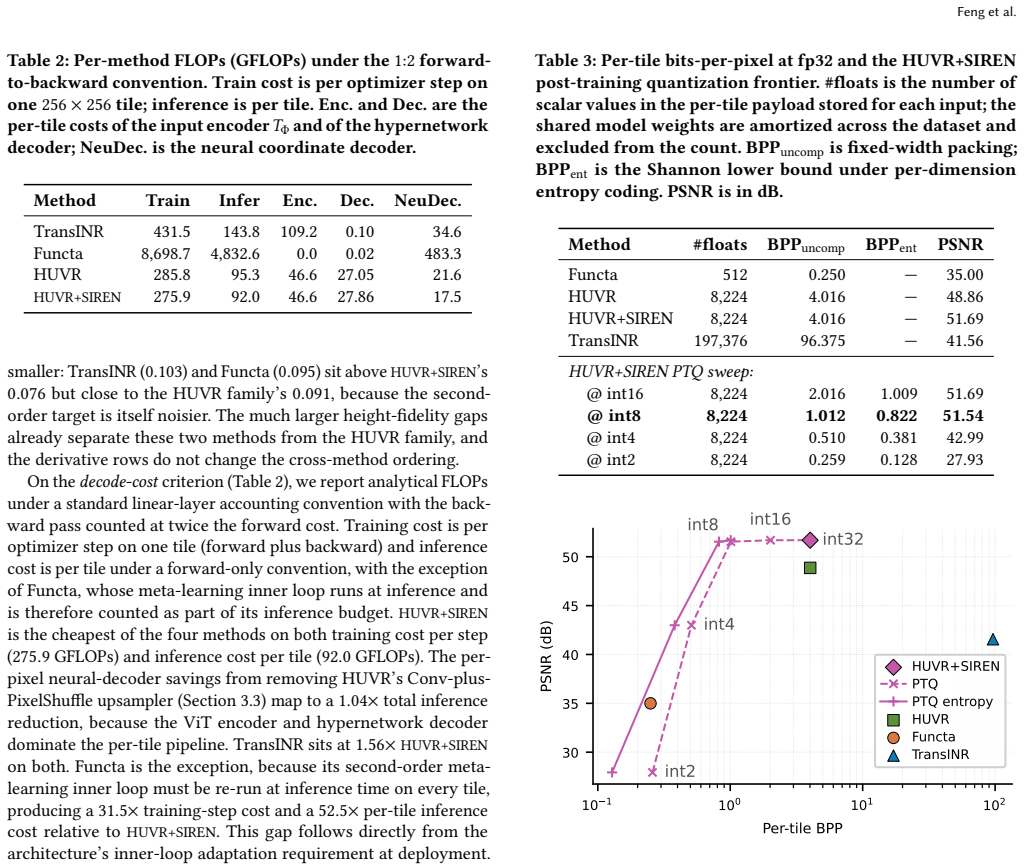
HUVR+SIREN, formed by substituting a SIREN decoder into the strongest benchmarked hypernetwork method, attains the best height and derivative fidelity on the benchmark with no additional per-tile storage and lower decode cost, tolerates aggressive post-training quantization with negligible quality loss, and thereby supplies a compact neural format for large terrain datasets.
What carries the argument
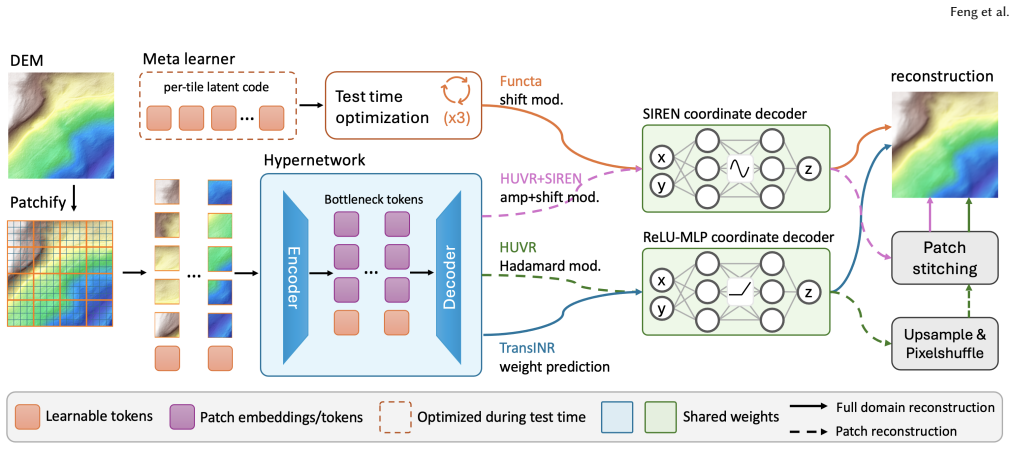
HUVR+SIREN hypernetwork: a shared network that encodes each terrain tile into a compact payload decoded by a SIREN coordinate network instead of the original decoder.
If this is right
- Amortized representations become practical for terrain once the decoder is replaced by a smooth analytic one.
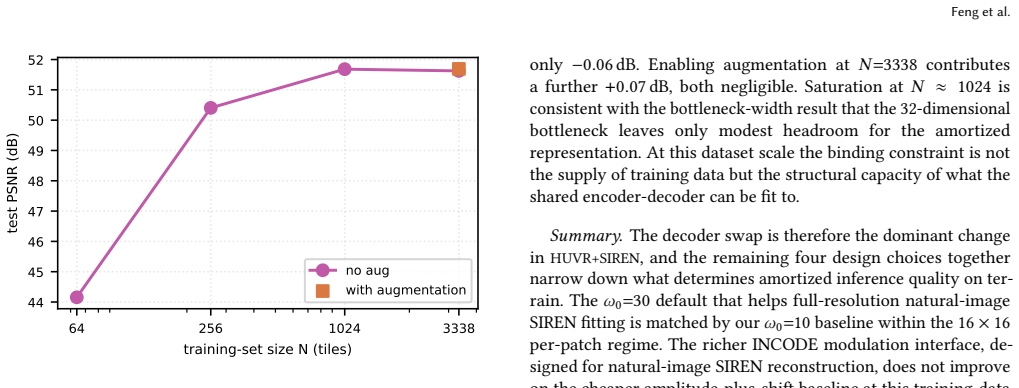
- The per-tile payload size is already near its useful limit, so further storage reduction must come from the shared hypernetwork.
- Design choices that transfer from image methods to terrain can be isolated by the controlled benchmark.
- The resulting format supports analytic derivatives and arbitrary-resolution decoding at low cost.
Where Pith is reading between the lines
- Similar decoder substitutions may close domain gaps for other continuous signals such as velocity fields or density volumes.
- Architectural search over the shared hypernetwork could now be the highest-leverage next step once the per-tile bottleneck is saturated.
- Quantization robustness suggests the format could be deployed directly on resource-constrained devices without retraining.
Load-bearing premise
The 1 m/pixel dataset together with the three evaluated methods suffice to establish a general cross-domain gap whose closure by the SIREN substitution will hold for other terrain collections and scales.
What would settle it
Running the identical three methods plus HUVR+SIREN on a second terrain collection at a different native resolution or scale would show whether the observed fidelity gains and quantization tolerance persist.
Figures

read the original abstract
Implicit neural representations (INRs) model a signal as a continuous coordinate-to-value function. For terrain elevation data, this supports analytic derivatives, arbitrary-resolution decoding, and a smooth surface model of the underlying heightfield. However, fitting and storing a separate INR for every tile does not scale to large terrain datasets. Amortized neural representations reduce this cost with a shared network: a new tile is mapped to a compact per-tile payload, and a shared decoder reconstructs the heightfield from it. Most such methods are hypernetworks that predict the payload in a single forward pass, while others recover it through a short per-tile optimization. These methods were developed primarily for natural images, and their suitability for terrain heightfields remains unclear. We introduce a controlled benchmark on a 1 m/pixel terrain dataset and evaluate three representative methods under a unified protocol. Observing a clear cross-domain gap, we propose HUVR+SIREN, a hypernetwork that adapts the strongest benchmarked method (HUVR) by replacing its coordinate decoder with a smooth, analytically differentiable one. It attains the best height and derivative fidelity on the benchmark with no additional per-tile storage and lower decode cost, and tolerates aggressive post-training quantization with negligible quality loss, giving a compact terrain neural format. Ablations and diagnostics further identify which design choices transfer to terrain and show that the per-tile bottleneck is already near its useful limit, leaving the remaining gap in the shared hypernetwork's architectural design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HUVR+SIREN, an adaptation of the HUVR hypernetwork for amortized implicit neural representations of terrain elevation data. It replaces the coordinate decoder with a SIREN to improve smoothness and analytic differentiability. On a controlled benchmark using a single 1 m/pixel terrain dataset and three representative amortized INR methods, HUVR+SIREN achieves the highest height and derivative fidelity without extra per-tile storage or increased decode cost, tolerates aggressive post-training quantization, and the ablations identify transferable design choices, leading to the conclusion that the per-tile bottleneck is near its useful limit.
Significance. If the observed gains and cross-domain gap generalize, the work would provide a compact neural terrain format supporting analytic derivatives and arbitrary-resolution decoding at lower storage and compute cost than per-tile INRs. The controlled benchmark protocol and focus on derivative fidelity plus quantization are relevant strengths for terrain applications.
major comments (2)
- [Benchmark and Results] § on benchmark and results (the experimental evaluation): The benchmark uses only one 1 m/pixel dataset and three methods. This makes the central claims—that HUVR+SIREN attains the best fidelity, that a clear cross-domain gap exists, and that the per-tile bottleneck is already near its useful limit—dependent on untested generalization; the SIREN substitution benefit and method ranking may not hold at other resolutions or on different terrain collections. A concrete test would be repeating the protocol on at least one additional dataset or scale.
- [Ablations] Ablations section: The ablations identify which design choices transfer to terrain, but all are performed inside the same single-dataset, three-method protocol; they therefore do not test whether the observed ranking or the conclusion about the per-tile bottleneck persists outside this narrow setting.
minor comments (1)
- [Abstract] Abstract: Performance claims are stated without any quantitative metrics, error bars, or dataset statistics, making it harder for readers to gauge the magnitude of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of the benchmark and ablations. We address each major comment below, clarifying the intended scope of our claims while acknowledging the limitations of a single-dataset protocol.
read point-by-point responses
-
Referee: [Benchmark and Results] § on benchmark and results (the experimental evaluation): The benchmark uses only one 1 m/pixel dataset and three methods. This makes the central claims—that HUVR+SIREN attains the best fidelity, that a clear cross-domain gap exists, and that the per-tile bottleneck is already near its useful limit—dependent on untested generalization; the SIREN substitution benefit and method ranking may not hold at other resolutions or on different terrain collections. A concrete test would be repeating the protocol on at least one additional dataset or scale.
Authors: The benchmark protocol is deliberately controlled to a single high-resolution (1 m/pixel) dataset to isolate the cross-domain performance gap between methods developed on natural images and their application to terrain elevation data. The central claims (best fidelity for HUVR+SIREN, existence of the gap, and near-limit per-tile bottleneck) are scoped to results observed under this unified protocol; the cross-domain gap is supported by comparing against the methods' reported image-domain performance. We agree that broader generalization across resolutions or terrain collections remains untested and constitutes a limitation. We will revise the manuscript to explicitly state the scope of the claims and add a limitations paragraph discussing the single-dataset design. Repeating the full protocol on additional data would require substantial new resources and is left for future work. revision: partial
-
Referee: [Ablations] Ablations section: The ablations identify which design choices transfer to terrain, but all are performed inside the same single-dataset, three-method protocol; they therefore do not test whether the observed ranking or the conclusion about the per-tile bottleneck persists outside this narrow setting.
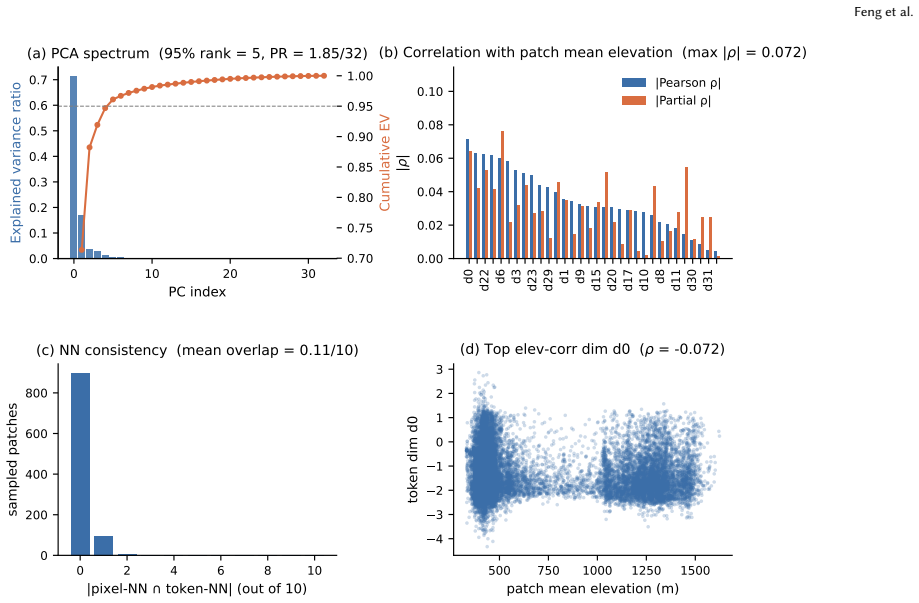
Authors: The ablations serve as diagnostics to identify which architectural choices (e.g., SIREN decoder, hypernetwork design) contribute to performance within the controlled benchmark, rather than as a test of generalization. They support the conclusion that the per-tile bottleneck is near its useful limit by showing saturation of gains from payload size and related factors inside this protocol. We agree that the ablations do not demonstrate whether the ranking or bottleneck conclusion holds on other datasets. We will revise the text to clarify that the ablations are diagnostic for the benchmark setting and to avoid implying broader transferability without further evidence. revision: partial
Circularity Check
Empirical benchmark and adaptation with no circular derivations
full rationale
The paper conducts a controlled benchmark on one 1 m/pixel terrain dataset, evaluates three representative amortized INR methods under a unified protocol, and proposes HUVR+SIREN as an empirical adaptation that substitutes a SIREN decoder into the strongest baseline. All central claims (best height/derivative fidelity, lower decode cost, quantization tolerance) are supported by reported performance metrics on the benchmark rather than by any equations, fitted parameters renamed as predictions, or self-citation chains. No load-bearing step reduces a claimed result to an input by construction, and the work contains no uniqueness theorems, ansatzes, or renamings of known results. The derivation chain is therefore self-contained as standard empirical comparison.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Yinbo Chen and Xiaolong Wang. 2022. Transformers as Meta-Learners for Implicit Neural Representations. InEuropean Conference on Computer Vision (ECCV). 170–187. doi:10.1007/978-3-031-19790-1_11 Project page and code: https://yinboc.github.io/trans-inr/
- [3]
-
[4]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations (ICLR). h...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Emilien Dupont, Adam Goliński, Milad Alizadeh, Yee Whye Teh, and Arnaud Doucet. 2021. COIN: COmpression with Implicit Neural representations. InICLR 2021 Neural Compression Workshop
2021
-
[6]
Emilien Dupont, Hyunjik Kim, S. M. Ali Eslami, Danilo Jimenez Rezende, and Dan Rosenbaum. 2022. From data to functa: Your data point is a function and you can treat it like one. InProceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 162). PMLR, 5694–5725. https://arxiv.org/abs/2201.12204
-
[7]
Emilien Dupont, Hrushikesh Loya, Milad Alizadeh, Adam Goliński, Yee Whye Teh, and Arnaud Doucet. 2022. COIN++: Neural Compression Across Modalities. Transactions on Machine Learning Research(2022)
2022
-
[8]
Esri. 2021. LERC: Limited Error Raster Compression. Open-source specification and reference implementation. https://github.com/Esri/lerc
2021
-
[9]
Haoan Feng, Xin Xu, and Leila De Floriani. 2024. ImplicitTerrain: a Continu- ous Surface Model for Terrain Data Analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop. 899–909
2024
-
[10]
Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-Agnostic Meta- Learning for Fast Adaptation of Deep Networks. InProceedings of the 34th Inter- national Conference on Machine Learning (ICML). 1126–1135
2017
-
[11]
Éric Guérin, Julie Digne, Éric Galin, Adrien Peytavie, Christian Wolf, Bedrich Benes, and Benoît Martinez. 2017. Interactive Example-Based Terrain Authoring with Conditional Generative Adversarial Networks. InACM Transactions on Graphics (Proceedings of SIGGRAPH Asia), Vol. 36. 228:1–228:13. doi:10.1145/ 3130800.3130804
- [12]
-
[13]
David Ha, Andrew M. Dai, and Quoc V. Le. 2017. HyperNetworks. InInternational Conference on Learning Representations (ICLR). https://arxiv.org/abs/1609.09106
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Peng He, Yongmei Cheng, Mingdong Qi, Zhi Cao, Heng Zhang, Shaoxian Ma, Shun Yao, and Qiang Wang. 2022. Super-Resolution of Digital Elevation Model with Local Implicit Function Representation. In2022 International Conference on Machine Learning and Intelligent Systems Engineering (MLISE). 158–163. doi:10. 1109/MLISE57402.2022.00030
-
[15]
Amirhossein Kazerouni, Reza Azad, Alireza Hosseini, Dorit Merhof, and Ulas Bagci. 2024. INCODE: Implicit Neural Conditioning with Prior Knowledge Embeddings. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 1298–1307
2024
-
[16]
Chiheon Kim, Doyup Lee, Saehoon Kim, Minsu Cho, and Wook-Shin Han. 2023. Generalizable Implicit Neural Representations via Instance Pattern Composers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR). 11808–11817. doi:10.1109/CVPR52729.2023.01136
-
[17]
Théo Ladune, Pierrick Philippe, Félix Henry, Erwan Le Pennec, and Clare E. Gordon. 2023. Cool-chic: Coordinate-based Low Complexity Hierarchical Image Codec. InIEEE International Conference on Computer Vision (ICCV)
2023
-
[18]
Peter Lindstrom. 2014. Fixed-Rate Compressed Floating-Point Arrays.IEEE Trans. Vis. Comput. Graph.20, 12 (2014), 2674–2683. doi:10.1109/TVCG.2014.2346458
-
[19]
Hodges, Nick Faust, and Gregory A
Peter Lindstrom, David Koller, William Ribarsky, Larry F. Hodges, Nick Faust, and Gregory A. Turner. 1996. Real-Time, Continuous Level of Detail Rendering of Height Fields. InProceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH ’96). 109–118. doi:10.1145/237170.237217
-
[20]
Ishit Mehta, Michaël Gharbi, Connelly Barnes, Eli Shechtman, Ravi Ramamoorthi, and Manmohan Chandraker. 2021. Modulated periodic activations for generaliz- able local functional representations. InProceedings of the IEEE/CVF International Conference on Computer Vision. 14214–14223
2021
-
[21]
Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. 2019. Occupancy networks: Learning 3d reconstruction in function space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4460–4470
2019
-
[22]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. Nerf: Representing scenes as neural radiance fields for view synthesis.Commun. ACM65, 1 (2021), 99–106
2021
-
[23]
Open Geospatial Consortium. 2023. Cloud Optimized GeoTIFF (COG) Standard, Version 1.0. OGC Implementation Standard 21-026. https://www.ogc.org/ standard/cog/
2023
-
[24]
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. 2019. Deepsdf: Learning continuous signed distance functions for shape representation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 165–174
2019
-
[25]
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. 2018. FiLM: Visual Reasoning with a General Conditioning Layer. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 32. doi:10.1609/ aaai.v32i1.11671
2018
-
[26]
Oriane Siméoni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Rama- monjisoa, et al. 2025. Dinov3.arXiv preprint arXiv:2508.10104(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Vincent Sitzmann, Julien N. P. Martel, Alexander W. Bergman, David B. Lindell, and Gordon Wetzstein. 2020. Implicit Neural Representations with Periodic Activation Functions. InAdvances in Neural Information Processing Systems, Vol. 33. 7462–7473
2020
-
[28]
Vincent Sitzmann, Michael Zollhöfer, and Gordon Wetzstein. 2019. Scene Repre- sentation Networks: Continuous 3D-Structure-Aware Neural Scene Representa- tions. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 32
2019
-
[29]
Yannick Strümpler, Janis Postels, Ren Yang, Luc Van Gool, and Federico Tombari
-
[30]
InEuropean Conference on Computer Vision (ECCV)
Implicit Neural Representations for Image Compression. InEuropean Conference on Computer Vision (ECCV). 74–91. doi:10.1007/978-3-031-19790-1_5
-
[31]
Srini- vasan, Jonathan T
Matthew Tancik, Ben Mildenhall, Terrance Wang, Divi Schmidt, Pratul P. Srini- vasan, Jonathan T. Barron, and Ren Ng. 2021. Learned Initializations for Opti- mizing Coordinate-Based Neural Representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2846–2855
2021
-
[32]
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng
-
[33]
Fourier features let networks learn high frequency functions in low dimen- sional domains.Advances in Neural Information Processing Systems33 (2020), 7537–7547
2020
-
[34]
Randolph Franklin, and Daniel M
Zhongyi Xie, W. Randolph Franklin, and Daniel M. Tracy. 2010. Slope Preserving Lossy Terrain Compression.ACM SIGSPATIAL Special2, 1 (2010), 19–24. doi:10. 1145/1953102.1953106
-
[35]
Shun Yao, Yongmei Cheng, Fei Yang, and Mikhail G. Mozerov. 2024. A continuous digital elevation representation model for DEM super-resolution.ISPRS Journal of Photogrammetry and Remote Sensing208 (2024), 1–13. doi:10.1016/j.isprsjprs. 2024.01.001 10 Rethinking Amortized Neural Representations for High-Resolution Terrain Elevation Data A Reproduction, hype...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.