Sakura: An Approach for Generating Complex Tests from Natural Language Test Descriptions
Pith reviewed 2026-06-28 18:38 UTC · model grok-4.3
The pith
Sakura generates complex unit tests from natural language descriptions using a multi-agent system with static analysis grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
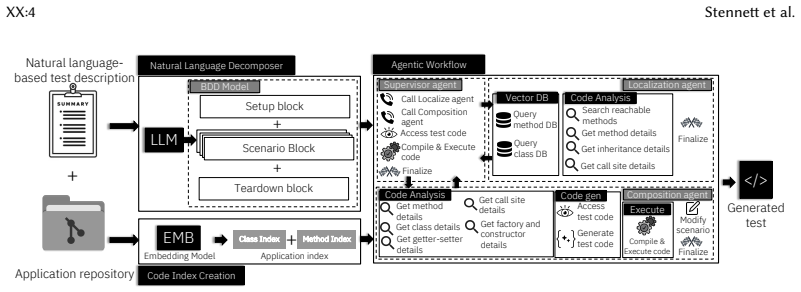
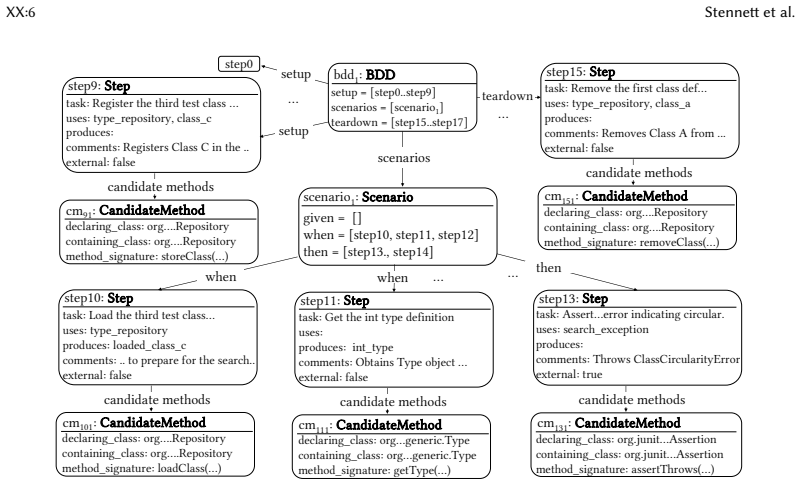
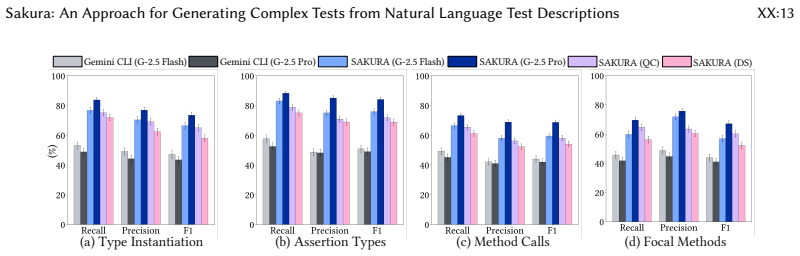
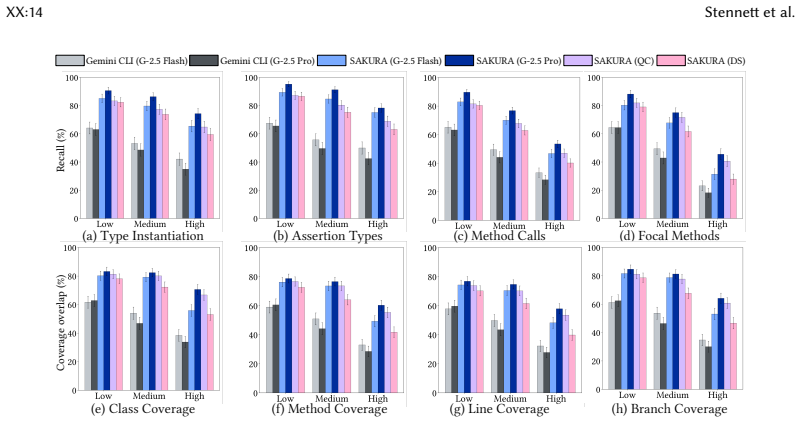
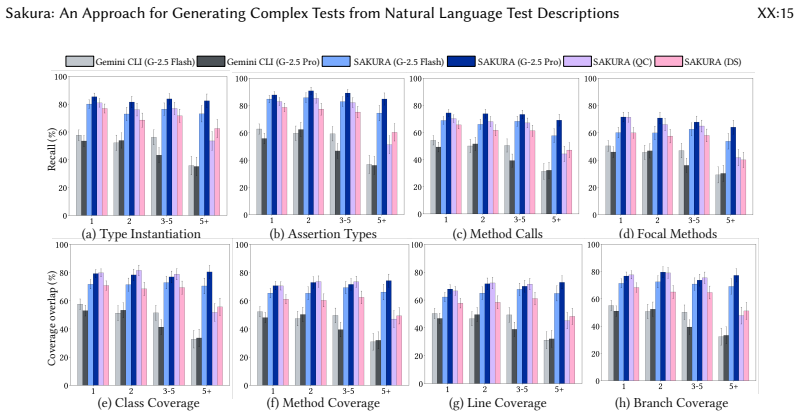
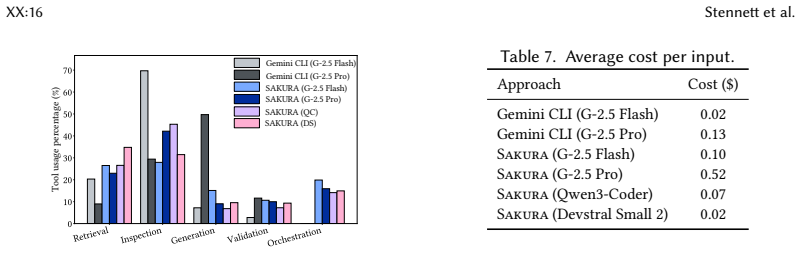
Sakura is the first agent-based framework for generating structurally complex test cases from NL descriptions. It decomposes NL descriptions into structured blocks and processes them using a multi-agent system consisting of a localization agent that grounds test steps in concrete application code via static analysis, a composition agent that synthesizes compilable test code and iteratively refines it using execution feedback, and a supervisor agent that coordinates agent interactions. Across 20 applications and 1,464 test scenarios from Apache Commons projects, Sakura achieves 50-78% higher test compilability and 38-66% higher coverage overlap with ground-truth tests compared to baselines us
What carries the argument
Multi-agent system with localization agent for grounding NL steps via static analysis, composition agent for test synthesis and iterative refinement using execution feedback, and supervisor agent for coordination.
If this is right
- Generated tests achieve substantially higher compilability rates than off-the-shelf agentic tools.
- Coverage overlap with developer-written tests increases by 38-66 percent.
- Small open-source models paired with Sakura can outperform large proprietary models.
- The approach reduces cost while improving results on complex multi-method test scenarios.
Where Pith is reading between the lines
- The decomposition into structured blocks and static-analysis grounding could transfer to other NL-to-code tasks such as generating documentation or refactoring scripts.
- Embedding the three-agent loop inside an IDE might allow developers to iterate on test intent in natural language and receive immediately executable results.
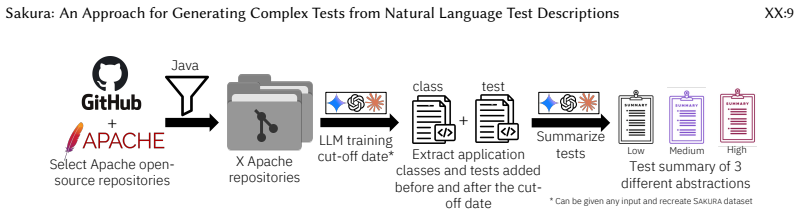
- The dataset construction method of deriving NL descriptions from existing tests offers a template for creating evaluation benchmarks in related software engineering problems.
Load-bearing premise
Natural language descriptions systematically generated from developer-written tests preserve the structural complexity, call sequences, and assertion intent of the originals so that grounding them via static analysis produces equivalent test behavior.
What would settle it
Direct execution of Sakura-generated tests against the 20 applications to measure actual coverage overlap and behavioral match with the original developer tests, checking whether the reported 38-66% gains hold or fall to baseline levels.
Figures




read the original abstract
Testing is a core activity in software development workflows, and research on its automation has spanned several decades. Most existing approaches generate unit tests for individual methods, validate isolated API endpoints, or target user interface (UI) layers, with non-API and non-UI automated test generators typically exercising only a single focal method. Recent empirical evidence shows a substantial gap between such generated tests and developer-written ones, which often span multiple focal methods, involve complex call sequences, and contain elaborate assertions that current automated approaches fail to capture. To address this gap, we propose generating tests from natural language (NL) descriptions of developer intent. We present Sakura, the first agent-based framework for generating structurally complex test cases from NL descriptions. Sakura decomposes NL descriptions into structured blocks and processes them using a multi-agent system consisting of a localization agent that grounds test steps in concrete application code via static analysis, a composition agent that synthesizes compilable test code and iteratively refines it using execution feedback, and a supervisor agent that coordinates agent interactions. To evaluate Sakura, we curate a novel dataset of NL test descriptions at three levels of abstraction, systematically generated from developer-written tests mined from Apache Commons projects. Across 20 applications and 1,464 test scenarios, Sakura significantly outperforms off-the-shelf agentic tools such as Gemini CLI. Specifically, Sakura achieves 50-78% higher test compilability and 38-66% higher coverage overlap with ground-truth tests compared to baselines using the same models. Moreover, Sakura paired with small open-source models such as Devstral Small 2 and Qwen3-Coder outperforms Gemini CLI using large proprietary models, while also being more cost-effective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sakura, a multi-agent framework for generating structurally complex unit tests from natural language descriptions of developer intent. It decomposes NL descriptions into blocks processed by a localization agent (grounding via static analysis), a composition agent (synthesizing and refining compilable code with execution feedback), and a supervisor agent. Evaluated on a novel dataset of 1,464 NL test scenarios at three abstraction levels, systematically generated from developer-written tests mined from 20 Apache Commons projects, Sakura reports 50-78% higher test compilability and 38-66% higher coverage overlap with ground-truth tests than baselines (including Gemini CLI) using the same models; it also claims smaller open-source models with Sakura outperform larger proprietary models while being more cost-effective.
Significance. If the evaluation holds without structural leakage in the NL descriptions, the work would meaningfully advance automated test generation by addressing the documented gap between single-focal-method tools and developer-written tests that involve multi-method sequences and complex assertions. The cost and model-size advantages would be practically relevant for adoption.
major comments (1)
- [Abstract] Abstract: The dataset is described only as 'systematically generated from developer-written tests' at three levels of abstraction, with no procedure, pseudocode, or examples provided. This is load-bearing for the central 38-66% coverage-overlap claim, because the localization agent's static analysis could recover focal methods, call sequences, or assertion structure directly from the NL if the generation process preserves such cues; without the generation details it is impossible to confirm that the NL descriptions constitute independent intent rather than partially leaked structural information.
minor comments (2)
- [Abstract] Abstract: The baselines are referred to only as 'off-the-shelf agentic tools such as Gemini CLI' without naming the exact models, prompts, or configurations used in the comparison.
- [Abstract] Abstract: No mention of statistical tests, confidence intervals, or per-application variance for the reported percentage improvements across the 1,464 scenarios.
Simulated Author's Rebuttal
We thank the referee for this detailed and constructive comment. We agree that the dataset generation procedure must be described with sufficient transparency to allow readers to assess whether the NL descriptions preserve structural cues or represent independent developer intent. We will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract: The dataset is described only as 'systematically generated from developer-written tests' at three levels of abstraction, with no procedure, pseudocode, or examples provided. This is load-bearing for the central 38-66% coverage-overlap claim, because the localization agent's static analysis could recover focal methods, call sequences, or assertion structure directly from the NL if the generation process preserves such cues; without the generation details it is impossible to confirm that the NL descriptions constitute independent intent rather than partially leaked structural information.
Authors: We acknowledge that the current abstract and manuscript provide only a high-level statement ('systematically generated from developer-written tests') without the concrete procedure, pseudocode, or examples needed to evaluate potential leakage. In the revised manuscript we will (1) expand the abstract with a concise description of the generation pipeline, (2) add a dedicated subsection (with pseudocode) that details the three abstraction levels, the mining process from Apache Commons tests, and the abstraction steps used to remove direct references to method names, call sequences, and assertion structures, and (3) include representative examples of the resulting NL descriptions at each level. These additions will make explicit that the NL is intentionally paraphrased to capture intent rather than code structure, thereby supporting the validity of the coverage-overlap metric. revision: yes
Circularity Check
No circularity: evaluation uses independently mined ground-truth tests and standard metrics
full rationale
The paper's central evaluation compares generated tests against developer-written ground-truth tests mined from Apache Commons projects using compilability and coverage-overlap metrics. The NL descriptions are derived from those tests, but the derivation chain does not reduce any claimed result to a fitted parameter or self-referential definition by construction. No equations, self-citations, or uniqueness theorems are invoked in a load-bearing way that collapses the performance claims. The setup is self-contained against external benchmarks and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can reliably decompose natural language test descriptions into structured blocks suitable for agent processing.
- domain assumption Static analysis can accurately map NL test steps to concrete code locations without significant loss of intent.
Reference graph
Works this paper leans on
-
[1]
Toufique Ahmed, Jatin Ganhotra, Rangeet Pan, Avraham Shinnar, Saurabh Sinha, and Martin Hirzel. [n. d.]. Otter: Generating Tests from Issues to Validate SWE Patches. InForty-second International Conference on Machine Learning
- [2]
-
[3]
Saranya Alagarsamy, Chakkrit Tantithamthavorn, Wannita Takerngsaksiri, Chetan Arora, and Aldeida Aleti. 2025. Enhancing large language models for text-to-testcase generation.Journal of Systems and Software(2025), 112531
2025
-
[4]
Alibaba Cloud. 2026. Qwen3-Coder. https://huggingface.co/Qwen/Qwen3-Coder-480B-A35B-Instruct. Open-source code-focused large language model
2026
-
[5]
Silviu Andrica and George Candea. 2011. WaRR: A tool for high-fidelity web application record and replay. In2011 IEEE/IFIP 41st International Conference on Dependable Systems & Networks (DSN). IEEE, 403–410
2011
-
[6]
Anthropic. 2025. Claude Sonnet 4.5 System Card. Anthropic System Card. https://www.anthropic.com/claude-sonnet- 4-5-system-card
2025
-
[7]
Anthropic PBC. 2024. Claude CLI. https://docs.anthropic.com/. Command-line interface for Claude language models
2024
-
[8]
Apache. 2026. Apache Commons. https://github.com/apache
2026
-
[9]
Apache Software Foundation. 2004. Apache Byte Code Engineering Library (BCEL). https://commons.apache.org/ proper/commons-bcel/. Java bytecode analysis and manipulation library
2004
-
[10]
Andrea Arcuri. 2019. RESTful API Automated Test Case Generation with EvoMaster.ACM Transactions on Software Engineering and Methodology (TOSEM)28, 1, Article 3 (jan 2019), 37 pages. doi:10.1145/3293455
-
[11]
Andrea Arcuri and Lionel Briand. 2011. Adaptive Random Testing: An Illusion of Effectiveness?. InProceedings of the 2011 International Symposium on Software Testing and Analysis. 265–275. doi:10.1145/2001420.2001452
-
[12]
SAKURA Artifact
artifact 2026. SAKURA Artifact. https://github.com/filenotfoundhere/sakura
2026
- [13]
-
[14]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732 (2021). Proc. ACM Softw. Eng., Vol. 3, No. ISSTA, Article XX. Publication date: October 2026. XX:20 Stennett et al
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [15]
-
[16]
Matteo Biagiola, Andrea Stocco, Filippo Ricca, and Paolo Tonella. 2019. Diversity-based web test generation. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 142–153
2019
-
[17]
Mark Chen. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Tsong Yueh Chen, Fei-Ching Kuo, Robert G. Merkel, and T. H. Tse. 2010. Adaptive Random Testing: The ART of Test Case Diversity.J. Syst. Softw.83, 1 (Jan. 2010), 60–66. doi:10.1016/j.jss.2009.02.022
-
[19]
Yinghao Chen, Zehao Hu, Chen Zhi, Junxiao Han, Shuiguang Deng, and Jianwei Yin. 2024. ChatUniTest: A Framework for LLM-Based Test Generation. doi:10.48550/arXiv.2305.04764 arXiv:2305.04764 [cs]
-
[20]
Ilinca Ciupa, Andreas Leitner, Manuel Oriol, and Bertrand Meyer. 2008. ARTOO: Adaptive Random Testing for Object-Oriented Software. InProceedings of the 30th International Conference on Software Engineering. 71–80
2008
-
[21]
Lori A. Clarke. 1976. A program testing system. InProceedings of the 1976 Annual Conference. Association for Computing Machinery, 488–491. doi:10.1145/800191.805647
-
[22]
EclEmma. [n. d.]. JaCoCo: Java Code Coverage Library. Accessed: 2024-07-27
2024
- [23]
-
[24]
Gordon Fraser and Andrea Arcuri. 2011. EvoSuite: Automatic Test Suite Generation for Object-Oriented Software. InProceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering. 416–419
2011
-
[25]
Gordon Fraser, Matt Staats, Phil McMinn, Andrea Arcuri, and Frank Padberg. 2015. Does Automated Unit Test Generation Really Help Software Testers? A Controlled Empirical Study.ACM Trans. Softw. Eng. Methodol., Article 23 (Sept. 2015). doi:10.1145/2699688
- [26]
-
[27]
Patrice Godefroid, Nils Klarlund, and Koushik Sen. 2005. DART: Directed automated random testing. InProceedings of the 2005 ACM SIGPLAN conference on Programming language design and implementation. 213–223
2005
-
[28]
Google DeepMind. 2026. Gemini 2.5 Flash. https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/ 2-5-flash. Efficient multimodal foundation model
2026
-
[29]
Google DeepMind. 2026. Gemini 2.5 Pro. https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/2- 5-pro. Large multimodal foundation model
2026
-
[30]
Google LLC. 2024. Gemini CLI. https://ai.google.dev/. Command-line interface for Gemini models
2024
-
[31]
Google LLC. 2026. Google Cloud Platform. https://cloud.google.com/. Cloud computing infrastructure and managed services
2026
-
[32]
Florian Gross, Gordon Fraser, and Andreas Zeller. 2012. EXSYST: Search-based GUI testing. In2012 34th International Conference on Software Engineering (ICSE). IEEE, 1423–1426
2012
-
[33]
Mark Harman and Phil McMinn. 2010. A Theoretical and Empirical Study of Search-Based Testing: Local, Global, and Hybrid Search.IEEE Transactions on Software Engineering36, 2 (2010), 226–247. doi:10.1109/TSE.2009.71
-
[34]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. 2023. MetaGPT: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations
2023
-
[35]
Dong Huang, Jie M Zhang, Michael Luck, Qingwen Bu, Yuhao Qing, and Heming Cui. 2023. Agentcoder: Multi-agent- based code generation with iterative testing and optimisation.arXiv preprint arXiv:2312.13010(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
IBM. 2024. watsonx Code Assistant for Enterprise Java Applications. https://www.ibm.com/products/watsonx-code- assistant-for-enterprise-java-applications
2024
-
[37]
JavaParser
javaparser 2025. JavaParser. https://github.com/javaparser/javaparser
2025
-
[38]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [39]
-
[40]
Myeongsoo Kim, Davide Corradini, Saurabh Sinha, Alessandro Orso, Michele Pasqua, Rachel Tzoref-Brill, and Mariano Ceccato. 2023. Enhancing REST API Testing with NLP Techniques. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis. Association for Computing Machinery, 1232–1243. doi:10.1145/3597926. 3598131
-
[41]
Myeongsoo Kim, Saurabh Sinha, and Alessandro Orso. 2023. Adaptive REST API Testing with Reinforcement Learning. InProceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering. IEEE Press, 446–458. Proc. ACM Softw. Eng., Vol. 3, No. ISSTA, Article XX. Publication date: October 2026. Sakura: An Approach for Generating Complex ...
-
[42]
Myeongsoo Kim, Saurabh Sinha, and Alessandro Orso. 2025. LlamaRestTest: Effective REST API Testing with Small Language Models. doi:10.48550/arXiv.2501.08598 arXiv:2501.08598 [cs]
- [43]
- [44]
-
[45]
Brahma Reddy Korraprolu, Pavitra Pinninti, and Y. Raghu Reddy. 2025. Test Case Generation for Requirements in Natural Language - An LLM Comparison Study. InProceedings of the 18th Innovations in Software Engineering Conference (ISEC ’25). Association for Computing Machinery, New York, NY, USA, Article 9, 5 pages. doi:10.1145/3717383.3717389
-
[46]
Maurizio Leotta, Diego Clerissi, Filippo Ricca, and Paolo Tonella. 2016. Approaches and tools for automated end-to-end web testing. InAdvances in Computers. Vol. 101. Elsevier, 193–237
2016
-
[47]
Yun Lin, You Sheng Ong, Jun Sun, Gordon Fraser, and Jin Song Dong. 2021. Graph-Based Seed Object Synthesis for Search-Based Unit Testing. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1068–1080
2021
-
[48]
Yu Lin, Xucheng Tang, Yuting Chen, and Jianjun Zhao. 2009. A Divergence-Oriented Approach to Adaptive Random Testing of Java Programs. In2009 IEEE/ACM International Conference on Automated Software Engineering. 221–232. doi:10.1109/ASE.2009.13
-
[49]
Andrea Lops, Fedelucio Narducci, Azzurra Ragone, Michelantonio Trizio, and Claudio Bartolini. 2025. A system for automated unit test generation using large language models and assessment of generated test suites. In2025 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 29–36
2025
-
[50]
Stephan Lukasczyk and Gordon Fraser. 2022. Pynguin: Automated unit test generation for python. InProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings. 168–172
2022
-
[51]
Stephan Lukasczyk, Florian Kroiß, and Gordon Fraser. 2023. An empirical study of automated unit test generation for python.Empirical Software Engineering28, 2 (2023). doi:10.1007/s10664-022-10248-w
-
[52]
Alberto Martin-Lopez, Andrea Arcuri, Sergio Segura, and Antonio Ruiz-Cortés. 2021. Black-box and white-box test case generation for RESTful APIs: Enemies or allies?. In2021 IEEE 32nd International Symposium on Software Reliability Engineering (ISSRE). IEEE, 231–241
2021
-
[53]
Alberto Martin-Lopez, Sergio Segura, and Antonio Ruiz-Cortés. 2022. Online Testing of RESTful APIs: Promises and Challenges. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. Association for Computing Machinery, 408–420. doi:10.1145/3540250.3549144
- [54]
-
[55]
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. 2026. Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces.arXiv preprint arXiv:2601.11868(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Mistral AI. 2026. Devstral Small 2. https://huggingface.co/mistralai/Devstral-Small-2-24B-Instruct-2512. Open-source developer-focused language model
2026
- [57]
-
[58]
Dan North. 2006. Introducing Behavior-Driven Development. https://dannorth.net/introducing-bdd/. Accessed: 2006
2006
-
[59]
OpenRouter. 2026. OpenRouter API. https://openrouter.ai/. Unified API gateway for large language models
2026
-
[60]
Carlos Pacheco and Michael D Ernst. 2007. Randoop: feedback-directed random testing for Java. InCompanion to the 22nd ACM SIGPLAN conference on Object-oriented programming systems and applications companion. 815–816
2007
-
[61]
Carlos Pacheco, Shuvendu K Lahiri, Michael D Ernst, and Thomas Ball. 2007. Feedback-directed random test generation. In29th International Conference on Software Engineering (ICSE’07). IEEE, 75–84
2007
-
[62]
Rangeet Pan, Myeongsoo Kim, Rahul Krishna, Raju Pavuluri, and Saurabh Sinha. 2025. ASTER: Natural and Multi- language Unit Test Generation with LLMs. InACM/IEEE International Conference on Software Engineering
2025
-
[63]
Rangeet Pan, Tyler Stennett, Raju Pavuluri, Nate Levin, Alessandro Orso, and Saurabh Sinha. 2025. Hamster: A Large-Scale Study and Characterization of Developer-Written Tests. arXiv:2509.26204 [cs.SE]
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [64]
- [65]
-
[66]
Corina S. Păsăreanu and Neha Rungta. 2010. Symbolic PathFinder: Symbolic Execution of Java Bytecode. InProceedings of the IEEE/ACM International Conference on Automated Software Engineering. 179–180. doi:10.1145/1858996.1859035 Proc. ACM Softw. Eng., Vol. 3, No. ISSTA, Article XX. Publication date: October 2026. XX:22 Stennett et al
-
[67]
Matthew Renze. 2024. The effect of sampling temperature on problem solving in large language models. InFindings of the association for computational linguistics: EMNLP 2024. 7346–7356
2024
-
[68]
Max Schäfer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. 2023. An empirical evaluation of using large language models for automated unit test generation.IEEE Transactions on Software Engineering(2023)
2023
-
[69]
Koushik Sen, Darko Marinov, and Gul Agha. 2005. CUTE: A concolic unit testing engine for C.ACM SIGSOFT Software Engineering Notes30, 5 (2005), 263–272
2005
-
[70]
Ye Shang, Quanjun Zhang, Chunrong Fang, Siqi Gu, Jianyi Zhou, and Zhenyu Chen. 2025. A large-scale empirical study on fine-tuning large language models for unit testing.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 1678–1700
2025
-
[71]
Derek Tam, Margaret Li, Prateek Yadav, Rickard Brüel Gabrielsson, Jiacheng Zhu, Kristjan Greenewald, Mikhail Yurochkin, Mohit Bansal, Colin Raffel, and Leshem Choshen. 2024. Llm merging: Building llms efficiently through merging. InNeurIPS 2024 Competition Track
2024
-
[72]
Shin Hwei Tan, Darko Marinov, Lin Tan, and Gary T Leavens. 2012. @ tcomment: Testing javadoc comments to detect comment-code inconsistencies. In2012 IEEE Fifth International Conference on Software Testing, Verification and Validation. IEEE, 260–269
2012
-
[73]
Nikolai Tillmann and Jonathan De Halleux. 2008. Pex–white box test generation for. net. InInternational conference on tests and proofs. Springer, 134–153
2008
- [74]
-
[75]
Emanuele Viglianisi, Michael Dallago, and Mariano Ceccato. 2020. RESTTESTGEN: Automated Black-Box Testing of RESTful APIs. In2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST). IEEE, Porto, Portugal, 142–152. doi:10.1109/icst46399.2020.00024
-
[76]
Pasareanu, and Sarfraz Khurshid
Willem Visser, Corina S. Pasareanu, and Sarfraz Khurshid. 2004. Test Input Generation with Java PathFinder. In Proceedings of the 2004 ACM SIGSOFT International Symposium on Software Testing and Analysis. 97–107
2004
- [77]
-
[78]
Fengcai Wen, Csaba Nagy, Gabriele Bavota, and Michele Lanza. 2019. A large-scale empirical study on code-comment inconsistencies. In2019 IEEE/ACM 27th International Conference on Program Comprehension (ICPC). IEEE, 53–64
2019
-
[79]
Rahulkrishna Yandrapally, Saurabh Sinha, Rachel Tzoref-Brill, and Ali Mesbah. 2023. Carving ui tests to generate api tests and api specification. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1971–1982
2023
-
[80]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.