ETC: Extreme Token Compression via Task-aware Visual Information Distillation in VLMs
Pith reviewed 2026-06-28 18:49 UTC · model grok-4.3
The pith
Vision-language models can compress high-resolution images to a single visual token by preserving only the instruction-aware visual information needed for the task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
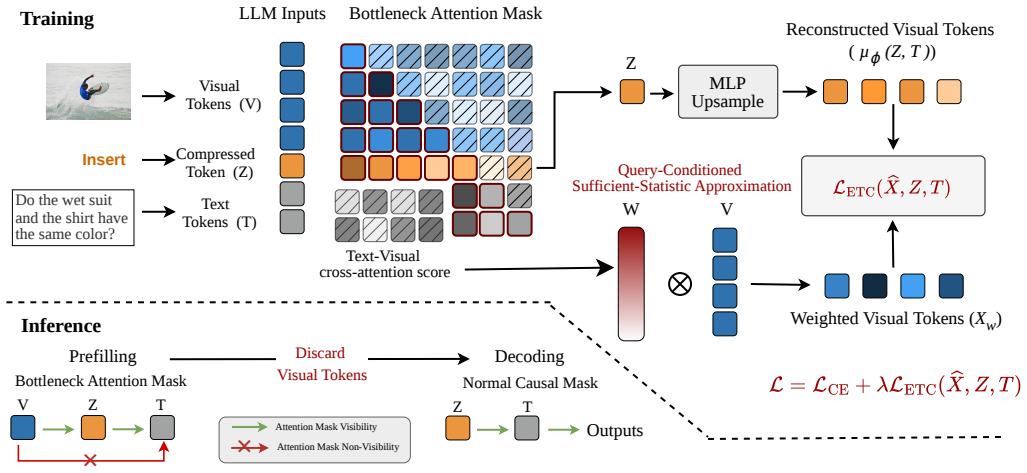
Minimizing task loss requires the compact representation to preserve the instruction-aware sufficient statistic of the task-relevant visual information for prediction. ETC approximates this statistic by weighting original visual features with text-to-image cross-attention scores and uses variational information distillation so the reduced tokens recover the same predictive content.
What carries the argument
The instruction-aware sufficient statistic of task-relevant visual information, approximated by text-to-image cross-attention weights and preserved via variational information distillation.
If this is right
- VLMs can process high-resolution inputs with far lower KV-cache memory during inference.
- Performance on standard vision-language benchmarks holds even when visual tokens are reduced to one.
- The same compression pipeline works on both LLaVA-1.5-7B and Qwen3-VL-2B without retraining the base model.
- Task loss directly guides the amount of visual information retained rather than relying on generic token pruning.
Where Pith is reading between the lines
- Attention scores already computed inside the model may be reused for compression decisions in future architectures.
- The same sufficient-statistic principle could guide compression of other modalities if analogous cross-modal statistics can be identified.
- Designers might embed the distillation step as a fixed layer rather than a separate training phase.
- Limits of the method would appear first on tasks where cross-attention fails to highlight the truly predictive visual regions.
Load-bearing premise
Text-to-image cross-attention weights serve as a reliable proxy for the latent instruction-aware predictive statistic that must be kept under compression.
What would settle it
Measure task accuracy at single-token compression after replacing the cross-attention weighting step with uniform or random weights; a large drop would indicate the approximation is necessary.
Figures


read the original abstract
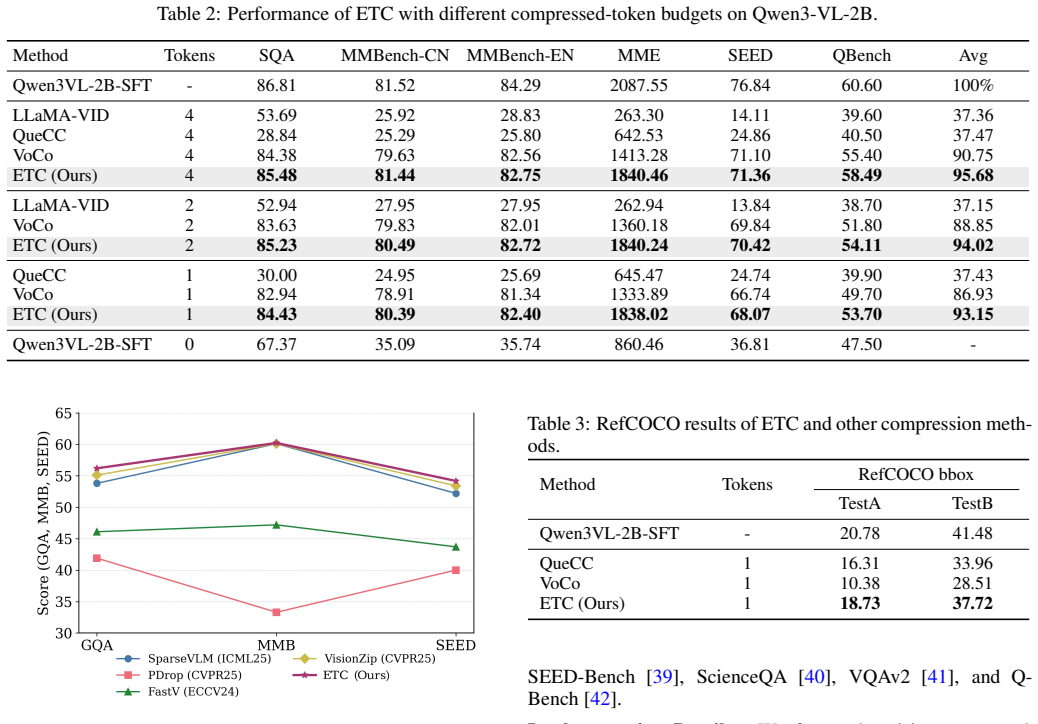
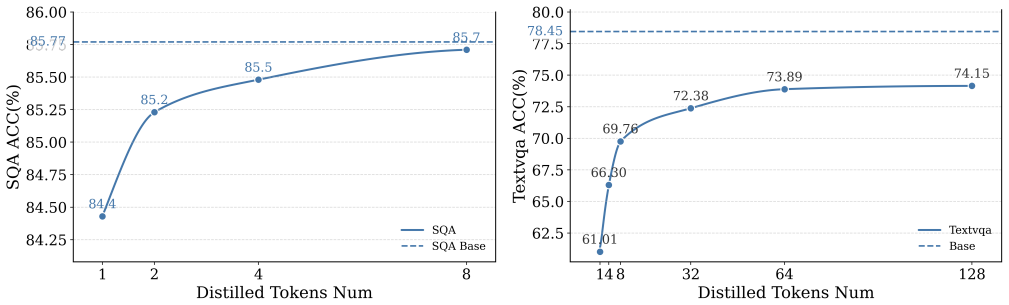
In Vision-Language Models (VLMs), high-resolution images produce a large number of visual tokens, resulting in high computational costs and KV-cache overhead during inference. To address this problem, we propose an Extreme Token Compression (ETC) framework that minimizes task loss when reducing the number of input tokens based on the principle of variational information distillation. Specifically, from an information-theoretic perspective, we show that minimizing task loss requires the compact representation to preserve the instruction-aware sufficient statistic of the task-relevant visual information for prediction. In practice, ETC leverages text-to-image cross-attention to weight the original visual features to approximate the latent instruction-aware predictive statistic. Moreover, ETC introduces a variational information distillation, enabling the compact representation to preserve the essential information to recover this predictive statistic. Experiments on LLaVA-1.5-7B and Qwen3-VL-2B show that ETC remains effective even under single-token compression, substantially reducing KV-cache overhead while retaining strong task performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ETC, a framework for extreme token compression in VLMs that minimizes task loss via variational information distillation. It claims an information-theoretic result that the compact representation must preserve the instruction-aware sufficient statistic of task-relevant visual information, which is approximated in practice by weighting original visual features with text-to-image cross-attention; a variational step then distills the compact tokens to retain information needed to recover this statistic. Experiments on LLaVA-1.5-7B and Qwen3-VL-2B report that the method remains effective even at single-token compression while substantially reducing KV-cache overhead.
Significance. If the central information-theoretic argument is valid and the cross-attention approximation is justified, ETC would provide a principled, task-aware alternative to heuristic token pruning methods, enabling efficient high-resolution VLM inference. The reported single-token results, if reproducible across tasks, would be a notable empirical contribution to the compression literature.
major comments (2)
- [§3] The information-theoretic claim (abstract and §3) requires that the compact tokens preserve exactly the instruction-aware sufficient statistic; however, the manuscript approximates this statistic via text-to-image cross-attention weights without a derivation showing why these weights yield (an approximation to) the minimal sufficient statistic rather than a heuristic relevance score. The subsequent variational distillation step assumes the weighted features already encode the target statistic, which is not independently verified and is load-bearing for the central claim.
- [§4] §4 and experimental section: no ablation studies isolate the contribution of the cross-attention approximation versus the variational distillation objective, nor compare against other potential estimators of the sufficient statistic; this leaves open whether performance under extreme compression is due to the claimed information-theoretic grounding or to the specific implementation choices.
minor comments (1)
- [§3] Notation for the variational objective and the definition of the 'instruction-aware sufficient statistic' should be introduced with explicit equations early in §3 to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comments point by point below. We agree that clarifications and additional experiments are warranted and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] The information-theoretic claim (abstract and §3) requires that the compact tokens preserve exactly the instruction-aware sufficient statistic; however, the manuscript approximates this statistic via text-to-image cross-attention weights without a derivation showing why these weights yield (an approximation to) the minimal sufficient statistic rather than a heuristic relevance score. The subsequent variational distillation step assumes the weighted features already encode the target statistic, which is not independently verified and is load-bearing for the central claim.
Authors: We acknowledge that the manuscript presents cross-attention weighting as a practical approximation to the instruction-aware sufficient statistic without a formal derivation establishing it as the minimal sufficient statistic. The information-theoretic argument shows that the compact tokens must preserve this statistic to minimize task loss, but the choice of cross-attention is motivated by its ability to capture text-conditioned relevance rather than proven optimality. The variational distillation then operates on these weighted features. We will revise §3 to explicitly distinguish the theoretical requirement from the practical approximation, add discussion of why cross-attention is a reasonable proxy, and note the lack of independent verification of the statistic. This will be addressed in the revision. revision: yes
-
Referee: [§4] §4 and experimental section: no ablation studies isolate the contribution of the cross-attention approximation versus the variational distillation objective, nor compare against other potential estimators of the sufficient statistic; this leaves open whether performance under extreme compression is due to the claimed information-theoretic grounding or to the specific implementation choices.
Authors: We agree that the current experiments do not include ablations separating the cross-attention weighting from the variational objective, nor comparisons to alternative estimators of the sufficient statistic. Such studies would strengthen the claims regarding the source of performance gains under extreme compression. We will add these ablations in the revised manuscript, including variants that replace cross-attention with uniform or random weighting and comparisons to other relevance estimators where feasible. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
Abstract states an information-theoretic claim that minimizing task loss requires preserving the instruction-aware sufficient statistic, then describes using cross-attention weights as a practical approximation to that statistic followed by variational distillation. No equations are provided, no self-citations are invoked to justify the approximation as a theorem, and the method is not shown to reduce to a fitted input or renamed known result by construction. The derivation chain is self-contained against external benchmarks with no load-bearing reductions exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv Preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Y e, Jie Shao, et al. InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv Preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
LLaV A-CoT: Let vision lan- guage models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Y uan. LLaV A-CoT: Let vision lan- guage models reason step-by-step. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 2087–2098, 2025
2087
-
[4]
TokenPacker: Efficient visual projector for multimodal LLM
Wentong Li, Y uqian Y uan, Jian Liu, Dongqi Tang, Song Wang, Jie Qin, Jianke Zhu, and Lei Zhang. TokenPacker: Efficient visual projector for multimodal LLM. Inter- national Journal of Computer Vision , pages 6794–6812, 2025
2025
-
[5]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Y uheng Li, and Y ong Jae Lee. Improved baselines with visual instruction tuning. In Pro- ceedings of the IEEE /CVF Conference on Computer Vi- sion and Pattern Recognition, pages 26296–26306, 2024
2024
-
[6]
Attention is all you need
Ashish V aswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Ad- vances in Neural Information Processing Systems , 30: 5998–6008, 2017
2017
-
[7]
SparseVLM: Visual token sparsification for e fficient vision-language model inference
Y uan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis A Gudovskiy, To- moyuki Okuno, Y ohei Nakata, Kurt Keutzer, and Shang- hang Zhang. SparseVLM: Visual token sparsification for e fficient vision-language model inference. In Inter- national Conference on Machine Learning , pages 74840– 74857, 2025
2025
-
[8]
TopV: Compatible token pruning with inference time optimization for fast and low- memory multimodal vision language model
Cheng Y ang, Y ang Sui, Jinqi Xiao, Lingyi Huang, Y u Gong, Chendi Li, Jinghua Y an, Y u Bai, Ponnuswamy Sadayappan, Xia Hu, et al. TopV: Compatible token pruning with inference time optimization for fast and low- memory multimodal vision language model. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19803–19...
2025
-
[9]
LLaV A-PruMerge: Adaptive token reduction for efficient large multimodal models
Y uzhang Shang, Mu Cai, Bingxin Xu, Y ong Jae Lee, and Y an Y an. LLaV A-PruMerge: Adaptive token reduction for efficient large multimodal models. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 22857–22867, 2025
2025
-
[10]
A TP-LLaV A: Adaptive token pruning for large vision language models
Xubing Y e, Y ukang Gan, Yixiao Ge, Xiao-Ping Zhang, and Y ansong Tang. A TP-LLaV A: Adaptive token pruning for large vision language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24972–24982, 2025
2025
-
[11]
Matryoshka query transformer for large vision-language models
Wenbo Hu, Zi-Yi Dou, Liunian Li, Amita Kamath, Nanyun Peng, and Kai-Wei Chang. Matryoshka query transformer for large vision-language models. Advances in Neural Information Processing Systems , pages 50168– 50188, 2024.7
2024
-
[12]
V oco-LLaMA: Towards vision compres- sion with large language models
Xubing Y e, Y ukang Gan, Xiaoke Huang, Yixiao Ge, and Y ansong Tang. V oco-LLaMA: Towards vision compres- sion with large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 29836–29846, 2025
2025
-
[13]
PVC: Progressive visual token com- pression for unified image and video processing in large vision-language models
Chenyu Y ang, Xuan Dong, Xizhou Zhu, Weijie Su, Jia- hao Wang, Hao Tian, Zhe Chen, Wenhai Wang, Lewei Lu, and Jifeng Dai. PVC: Progressive visual token com- pression for unified image and video processing in large vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 24939–24949, 2025
2025
-
[14]
V ariational information dis- tillation for knowledge transfer
Sungsoo Ahn, Shell Xu Hu, Andreas Damianou, Neil D Lawrence, and Zhenwen Dai. V ariational information dis- tillation for knowledge transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9163–9171, 2019
2019
-
[15]
E fficient self-attention with smart pruning for sustainable large lan- guage models
Samir Brahim Belhaouari and Insaf Kraidia. E fficient self-attention with smart pruning for sustainable large lan- guage models. Scientific Reports, 15(1):10171, 2025
2025
-
[16]
DyLoFViT: A novel approach for real-time metal 3d printing surface quality classification
Y uqin Zeng, Lianli Liu, Ze Wen, Jiquan Liu, and Shuqian Fan. DyLoFViT: A novel approach for real-time metal 3d printing surface quality classification. IET Image Process- ing, 19(1):e70182, 2025
2025
-
[17]
LLaV A-OneVision: Easy visual task transfer
Bo Li, Y uanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Y anwei Li, Ziwei Liu, and Chunyuan Li. LLaV A-OneVision: Easy visual task transfer. Transactions on Machine Learn- ing Research, 2025. ISSN 2835-8856
2025
-
[18]
Qwen 2.5: A comprehensive review of the lead- ing resource-e fficient LLM with potentioal to surpass all competitors
Imtiaz Ahmed, Sadman Islam, Partha Protim Datta, Im- ran Kabir, Naseef Ur Rahman Chowdhury, and Ahshanul Haque. Qwen 2.5: A comprehensive review of the lead- ing resource-e fficient LLM with potentioal to surpass all competitors. Authorea Preprints, 2025
2025
-
[19]
RocketKV: Ac- celerating long-context LLM inference via two-stage KV cache compression
Payman Behnam, Y aosheng Fu, Ritchie Zhao, Po-An Tsai, Zhiding Y u, and Alexey Tumanov. RocketKV: Ac- celerating long-context LLM inference via two-stage KV cache compression. In International Conference on Ma- chine Learning, pages 3358–3392, 2025
2025
-
[20]
SCOPE: Optimizing key- value cache compression in long-context generation
Jialong Wu, Zhenglin Wang, Linhai Zhang, Yilong Lai, Y ulan He, and Deyu Zhou. SCOPE: Optimizing key- value cache compression in long-context generation. In Proceedings of the 63rd Annual Meeting of the Associa- tion for Computational Linguistics , pages 10775–10790, 2025
2025
-
[21]
Accelerating multi- modal large language models by searching optimal vision token reduction
Shiyu Zhao, Zhenting Wang, Felix Juefei-Xu, Xide Xia, Miao Liu, Xiaofang Wang, Mingfu Liang, Ning Zhang, Dimitris N Metaxas, and Licheng Y u. Accelerating multi- modal large language models by searching optimal vision token reduction. In Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition , pages 29869–29879, 2025
2025
-
[22]
ST3: Accelerating multimodal large language model by spatial-temporal visual token trimming
Jiedong Zhuang, Lu Lu, Ming Dai, Rui Hu, Jian Chen, Qiang Liu, and Haoji Hu. ST3: Accelerating multimodal large language model by spatial-temporal visual token trimming. In Proceedings of the AAAI Conference on Ar- tificial Intelligence, pages 11049–11057, 2025
2025
-
[23]
L VPruning: An e ffective yet simple language-guided vi- sion token pruning approach for multi-modal large lan- guage models
Yizheng Sun, Y anze Xin, Hao Li, Jingyuan Sun, Chenghua Lin, and Riza Theresa Batista-Navarro. L VPruning: An e ffective yet simple language-guided vi- sion token pruning approach for multi-modal large lan- guage models. In Findings of the Association for Com- putational Linguistics: NAACL , pages 4299–4308, 2025
2025
-
[24]
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models
Weihao Y e, Qiong Wu, Wenhao Lin, and Yiyi Zhou. Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. In Proceedings of the AAAI Conference on Artificial Intelligence , pages 22128– 22136, 2025
2025
-
[25]
PACT: Pruning and clustering-based to- ken reduction for faster visual language models
Mohamed Dhouib, Davide Buscaldi, Sonia V anier, and Aymen Shabou. PACT: Pruning and clustering-based to- ken reduction for faster visual language models. In Pro- ceedings of the IEEE /CVF Conference on Computer Vi- sion and Pattern Recognition, pages 14582–14592, 2025
2025
-
[26]
TempMe: Video temporal token merging for efficient text- video retrieval
Leqi Shen, Tianxiang Hao, Tao He, Sicheng Zhao, Yifeng Zhang, pengzhang liu, Y ongjun Bao, and Guiguang Ding. TempMe: Video temporal token merging for efficient text- video retrieval. In International Conference on Learning Representations, pages 60839–60860, 2025
2025
-
[27]
E fficient visual transformer by learnable token merging
Y ancheng Wang and Yingzhen Y ang. E fficient visual transformer by learnable token merging. IEEE Transac- tions on Pattern Analysis & Machine Intelligence, 47(11): 9597–9608, 2025
2025
-
[28]
HierarQ: Task-aware hierarchical Q-Former for enhanced video understanding
Shehreen Azad, Vibhav Vineet, and Y ogesh Singh Rawat. HierarQ: Task-aware hierarchical Q-Former for enhanced video understanding. In Proceedings of the IEEE /CVF Conference on Computer Vision and Pattern Recognition , pages 8545–8556, 2025
2025
-
[29]
Per- ceive
Roberto Amoroso, Gengyuan Zhang, Rajat Koner, Lorenzo Baraldi, Rita Cucchiara, and V olker Tresp. Per- ceive. query & reason: Enhancing video QA with question-guided temporal queries. In IEEE/CVF Winter Conference on Applications of Computer Vision , pages 8853–8862. IEEE, 2025
2025
-
[30]
LLaMA-Vid: An image is worth 2 tokens in large language models
Y anwei Li, Chengyao Wang, and Jiaya Jia. LLaMA-Vid: An image is worth 2 tokens in large language models. In European Conference on Computer Vision, pages 323–
-
[31]
Semedo, and J Zico Kolter
Kevin Li, Sachin Goyal, João D. Semedo, and J Zico Kolter. Inference optimal VLMs need fewer visual to- kens and more parameters. In International Conference on Learning Representations, pages 96066–96083, 2025
2025
-
[32]
Microsoft COCO: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common objects in context. In European Conference on Computer Vision , pages 740–755. Springer, 2014
2014
-
[33]
GQA: A new dataset for real-world visual reasoning and com- positional question answering
Drew A Hudson and Christopher D Manning. GQA: A new dataset for real-world visual reasoning and com- positional question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6700–6709, 2019
2019
-
[34]
OCR-VQA: Visual question8 answering by reading text in images
Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. OCR-VQA: Visual question8 answering by reading text in images. In International Con- ference on Document Analysis and Recognition , pages 947–952. IEEE, 2019
2019
-
[35]
Towards VQA models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Y u Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards VQA models that can read. In Pro- ceedings of the IEEE /CVF Conference on Computer Vi- sion and Pattern Recognition, pages 8317–8326, 2019
2019
-
[36]
Visual genome: Connecting language and vision using crowd- sourced dense image annotations
Ranjay Krishna, Y uke Zhu, Oliver Groth, Justin John- son, Kenji Hata, Joshua Kravitz, Stephanie Chen, Y annis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowd- sourced dense image annotations. International Journal of Computer Vision, 123(1):32–73, 2017
2017
-
[37]
MMBench: Is your multi- modal model an all-around player? In European Confer- ence on Computer Vision, pages 216–233
Y uan Liu, Haodong Duan, Y uanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Y uan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. MMBench: Is your multi- modal model an all-around player? In European Confer- ence on Computer Vision, pages 216–233. Springer, 2024
2024
-
[38]
MME: A comprehensive evalu- ation benchmark for multimodal large language models
Chaoyou Fu, Peixian Chen, Y unhang Shen, Y ulei Qin, Mengdan Zhang, Xu Lin, Jinrui Y ang, Xiawu Zheng, Ke Li, Xing Sun, et al. MME: A comprehensive evalu- ation benchmark for multimodal large language models. In Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[39]
Seed-Bench: Benchmarking multimodal large language models
Bohao Li, Y uying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-Bench: Benchmarking multimodal large language models. In Pro- ceedings of the IEEE /CVF Conference on Computer Vi- sion and Pattern Recognition, pages 13299–13308, 2024
2024
-
[40]
Learn to explain: Multimodal rea- soning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai- Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal rea- soning via thought chains for science question answering. Advances in Neural Information Processing Systems , 35: 2507–2521, 2022
2022
-
[41]
Making the V in VQA matter: El- evating the role of image understanding in visual question answering
Y ash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: El- evating the role of image understanding in visual question answering. In Proceedings of the IEEE /CVF Conference on Computer Vision and Pattern Recognition, pages 6904– 6913, 2017
2017
-
[42]
Q-Bench: A bench- mark for general-purpose foundation models on low-level vision
Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Chunyi Li, Wenxiu Sun, Qiong Y an, Guangtao Zhai, and Weisi Lin. Q-Bench: A bench- mark for general-purpose foundation models on low-level vision. In International Conference on Learning Repre- sentations, 2024
2024
-
[43]
VisionZIP: Longer is better but not necessary in vision language models
Senqiao Y ang, Y ukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Y u, and Jiaya Jia. VisionZIP: Longer is better but not necessary in vision language models. In Proceedings of the IEEE /CVF Conference on Computer Vision and Pattern Recognition , pages 19792– 19802, 2025
2025
-
[44]
Conical visual concen- tration for e fficient large vision-language models
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Y uhang Zang, Y uhang Cao, Conghui He, Jiaqi Wang, Feng Wu, and Dahua Lin. Conical visual concen- tration for e fficient large vision-language models. In Pro- ceedings of the IEEE /CVF Conference on Computer Vi- sion and Pattern Recognition, pages 14593–14603, 2025
2025
-
[45]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference ac- celeration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Jun- yang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference ac- celeration for large vision-language models. In European Conference on Computer Vision , pages 19–35. Springer, 2024
2024
-
[46]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International Conference on Machine Learning , pages 19730–19742, 2023
2023
-
[47]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Y uandong Tian. Extending context window of large lan- guage models via positional interpolation. arXiv Preprint arXiv:2306.15595, 2023. 9 A Appendix A.1 Proofs and Additional Derivations This appendix provides the full derivations for Section 3. We derive the ideal requirement for the compact representatio...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.