Through the PRISM: Principle-Aware, Interpretable, and Multi-Scale Evaluation of Visual Designs
Pith reviewed 2026-06-28 19:17 UTC · model grok-4.3
The pith
PRISM benchmark perturbs layouts to reveal how vision-language models detect or miss specific design principle violations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PRISM systematically perturbs 100K training and 10K validation designs to isolate principle violations, demonstrating that existing multimodal models either overlook targeted degradations or fail to disentangle them, and that a multi-scale framework of scorers and vision-language models can deliver interpretable explanations leading to measurable layout improvements.
What carries the argument
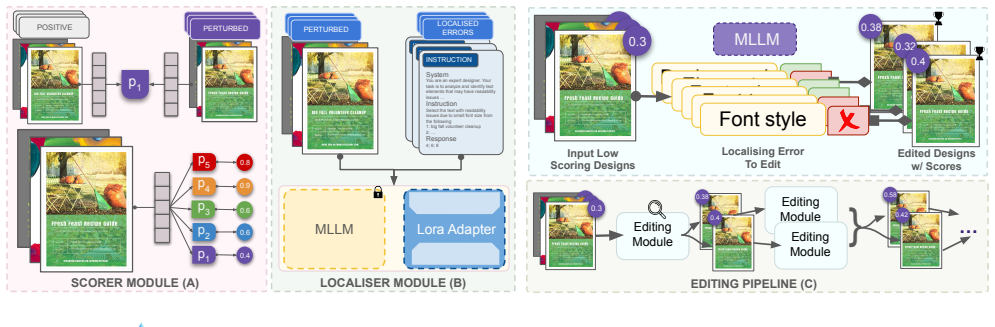
PRISM benchmark of perturbed Crello layouts that isolate specific design principle violations for controlled multimodal reasoning analysis, paired with a multi-scale evaluation framework integrating quantitative scorers and localized feedback.
If this is right
- Targeted refinements using localized insights from the framework improve layout quality.
- The framework supplies interpretable explanations for design failures.
- PRISM and the framework support interpretable design-literate multimodal reasoning systems.
- Models can be evaluated for their ability to reason about individual design principles separately.
Where Pith is reading between the lines
- Training future models on PRISM-style disentangled data could enhance their fine-grained design understanding.
- The isolation method might be adapted to evaluate other creative or visual reasoning tasks beyond graphic design.
- Integration into design software could allow real-time principle-specific suggestions for users.
Load-bearing premise
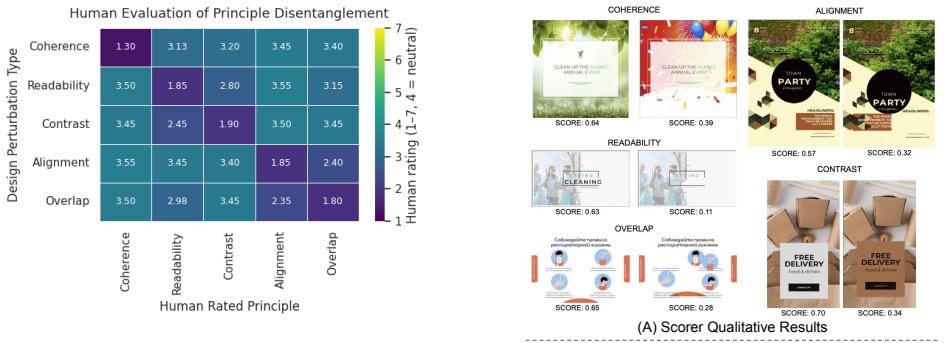
The perturbations of Crello layouts isolate individual design principle violations without confounding effects on other principles or perceived quality.
What would settle it
A study finding that perturbing one principle, like alignment, consistently and substantially alters scores for unrelated principles such as contrast would indicate the benchmark does not successfully isolate violations.
Figures






read the original abstract
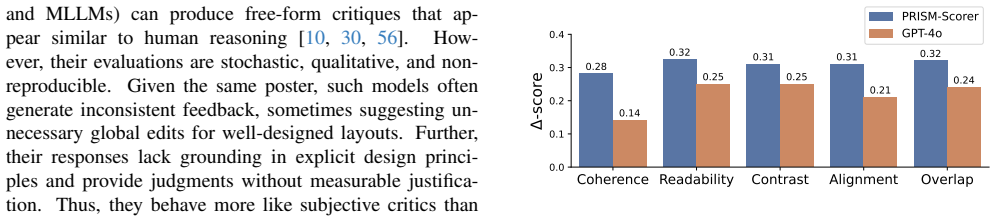
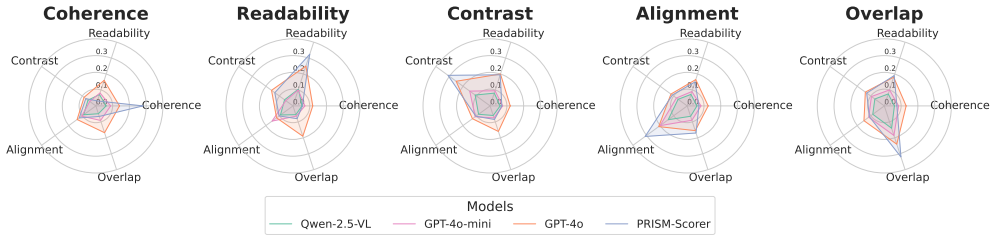
Effective visual communication stems from the harmony of multiple design principles, such as readability, contrast, alignment, overlap, and coherence, which collectively govern clarity and intent of the communicator. While human designers reason holistically over these principles, machine agents typically condense them into a single heuristic score, offering limited interpretability and diagnostic precision. To address this gap, we introduce PRISM (PRinciple-aware, Interpretable, and Structure-guided Design Modifications), a benchmark that systematically perturbs professional layouts from the Crello dataset along measurable design principles. The benchmark comprises 100K perturbed training samples and 10K perturbed validation designs, each isolating a specific principle violation for controlled analysis of multimodal reasoning about design quality. We show that models like Qwen-2.5-VL and GPT-4o-mini are largely insensitive to targeted principle degradations, whereas GPT-4o exhibits global awareness without fine-grained disentanglement. Building on these insights, we propose a multi-scale evaluation framework that integrates lightweight scorers for quantitative assessment, instruction-tuned vision-language models for localised feedback, and prompt-based methods for global reasoning. Our framework provides interpretable explanations of design failures. Using these localised insights, we show targeted refinements that improve layout quality. Together, PRISM and our framework lay the foundation for interpretable design-literate multimodal reasoning systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the PRISM benchmark, which generates 100K training and 10K validation perturbed layouts from the Crello dataset to isolate specific violations of design principles (readability, contrast, alignment, overlap, coherence). It evaluates several vision-language models on their sensitivity to these targeted degradations, reporting that Qwen-2.5-VL and GPT-4o-mini are largely insensitive while GPT-4o shows global but not fine-grained awareness. The work further proposes a multi-scale evaluation framework combining lightweight scorers, instruction-tuned VLMs, and prompt-based global reasoning to provide interpretable explanations and enable targeted layout refinements.
Significance. If the perturbations can be shown to isolate individual principles without measurable confounding, PRISM would supply a rare controlled testbed for diagnostic multimodal reasoning about visual design, moving beyond aggregate quality scores. The multi-scale framework's emphasis on localized feedback and refinement loops could also support more actionable VLM applications in design tools.
major comments (2)
- [Abstract] Abstract: The central claim that each of the 100K/10K perturbations 'isolates a specific principle violation' for 'controlled analysis' is load-bearing for all reported model behaviors and the utility of the multi-scale framework, yet the manuscript supplies no implementation details on perturbation operators, no quantitative checks (e.g., cross-principle correlation matrices or ablation on residual leakage), and no human validation that a readability-only change leaves contrast, alignment, and overall perceived quality unaffected. Without such evidence the reported insensitivity of Qwen-2.5-VL/GPT-4o-mini versus GPT-4o's global awareness cannot be unambiguously attributed to principle-specific reasoning.
- [Abstract] Abstract (model evaluation paragraph): The statements that models are 'largely insensitive to targeted principle degradations' and that the framework 'enables targeted refinements that improve layout quality' rest on the unverified isolation assumption; any operator that couples multiple principles would render both the diagnostic conclusions and the refinement results uninterpretable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to rigorously verify isolation of principle violations in the PRISM perturbations. We agree this is essential for the interpretability of the model evaluations and framework. We address the points below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that each of the 100K/10K perturbations 'isolates a specific principle violation' for 'controlled analysis' is load-bearing for all reported model behaviors and the utility of the multi-scale framework, yet the manuscript supplies no implementation details on perturbation operators, no quantitative checks (e.g., cross-principle correlation matrices or ablation on residual leakage), and no human validation that a readability-only change leaves contrast, alignment, and overall perceived quality unaffected. Without such evidence the reported insensitivity of Qwen-2.5-VL/GPT-4o-mini versus GPT-4o's global awareness cannot be unambiguously attributed to principle-specific reasoning.
Authors: We agree that the manuscript as submitted lacks sufficient implementation details and validation for the isolation claim. In the revised version we will add a new subsection detailing each perturbation operator (with pseudocode), quantitative checks including cross-principle correlation matrices and leakage ablations on the generated samples, and a human validation study on a representative subset confirming that targeted changes primarily affect the intended principle with minimal impact on others or overall perceived quality. These additions will support unambiguous attribution of the observed model behaviors. revision: yes
-
Referee: [Abstract] Abstract (model evaluation paragraph): The statements that models are 'largely insensitive to targeted principle degradations' and that the framework 'enables targeted refinements that improve layout quality' rest on the unverified isolation assumption; any operator that couples multiple principles would render both the diagnostic conclusions and the refinement results uninterpretable.
Authors: We concur that both the diagnostic findings on model sensitivity and the refinement results depend on verifiable isolation. The planned revisions (operator details, correlation analyses, and human validation) will directly substantiate the assumption or, if residual coupling is detected, allow us to qualify the conclusions and report any confounding effects explicitly. revision: yes
Circularity Check
No circularity; empirical benchmark and evaluation framework
full rationale
The paper constructs a benchmark by perturbing Crello layouts along five design principles and evaluates VLMs empirically on the resulting samples. It then proposes a multi-scale framework combining scorers, VLMs, and prompts for feedback and refinement. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Claims rest on observed model behaviors and qualitative improvements rather than any self-referential reduction. The principle-isolation assumption is a methodological claim open to external validation but does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Computational modeling and experimental investigation of effects of compositional ele- ments on interface and design aesthetics.Int
Michael Bauerly and Yili Liu. Computational modeling and experimental investigation of effects of compositional ele- ments on interface and design aesthetics.Int. J. Hum. Com- put. Stud., 64(8):670–682, 2006. 2
2006
-
[3]
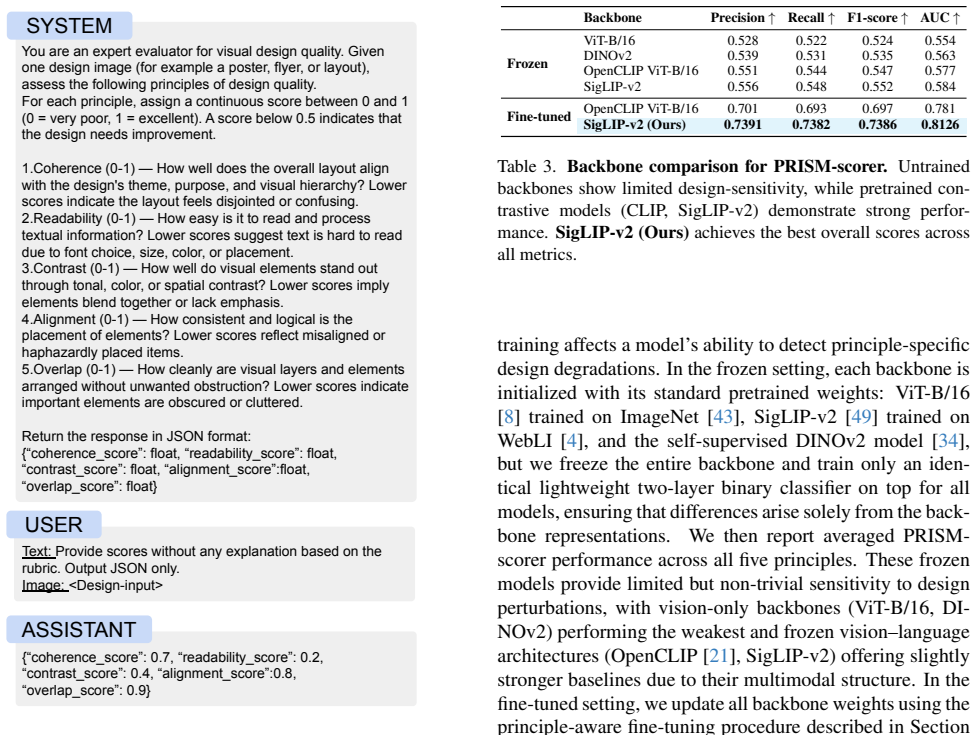
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multi- modal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Pali: A jointly-scaled multilingual language-image model, 2023
Xi Chen, Xiao Wang, Soravit Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, Alexander Kolesnikov, Joan Puigcerver, Nan Ding, Keran Rong, Hassan Akbari, Gaurav Mishra, Linting Xue, Ashish Thapliyal, James Brad- bury, Weicheng Kuo, Mojtaba Seyedhosseini, Chao Jia, Burcu Karagol Ayan, Ca...
2023
-
[5]
Meerkat: Audio-visual large language model for grounding in space and time
Sanjoy Chowdhury, Sayan Nag, Subhrajyoti Dasgupta, Jun Chen, Mohamed Elhoseiny, Ruohan Gao, and Dinesh Manocha. Meerkat: Audio-visual large language model for grounding in space and time. InEuropean Conference on Computer Vision, pages 52–70. Springer, 2024. 3
2024
-
[6]
Sanjoy Chowdhury, Mohamed Elmoghany, Yohan Abeysinghe, Junjie Fei, Sayan Nag, Salman Khan, Mohamed Elhoseiny, and Dinesh Manocha. Magnet: A multi-agent framework for finding audio-visual needles by reasoning over multi-video haystacks.arXiv preprint arXiv:2506.07016, 2025. 3
-
[7]
Emerging properties in unified multimodal pretraining, 2025
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining, 2025. 2
2025
-
[8]
An image is worth 16x16 words: Transformers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021. 2
2021
-
[9]
Webthetics: Quantifying webpage aesthetics with deep learning.Int
Qi Dou, Xianjun Sam Zheng, Tongfang Sun, and Pheng-Ann Heng. Webthetics: Quantifying webpage aesthetics with deep learning.Int. J. Hum. Comput. Stud., 124:56–66, 2019. 2
2019
-
[10]
Uicrit: Enhancing automated design evaluation with a ui critique dataset
Peitong Duan, Chin-Yi Cheng, Gang Li, Bjoern Hartmann, and Yang Li. Uicrit: Enhancing automated design evaluation with a ui critique dataset. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technol- ogy, pages 1–17, 2024. 2
2024
-
[11]
Can gpts evaluate graphic design based on design principles? InSIGGRAPH Asia 2024
Haraguchi et al. Can gpts evaluate graphic design based on design principles? InSIGGRAPH Asia 2024. 3
2024
-
[12]
Neural multimodal topic modeling: A comprehensive evaluation
Felipe Gonz’alez-Pizarro and Giuseppe Carenini. Neural multimodal topic modeling: A comprehensive evaluation. ArXiv, abs/2403.17308, 2024. 3
-
[13]
Design-o-meter: Towards evaluating and refin- ing graphic designs
Sahil Goyal, Abhinav Mahajan, Swasti Mishra, Prateksha Udhayanan, Tripti Shukla, KJ Joseph, and Balaji Vasan Srinivasan. Design-o-meter: Towards evaluating and refin- ing graphic designs. 2025. 1, 2
2025
-
[14]
Can gpts eval- uate graphic design based on design principles? InSIG- GRAPH Asia 2024 Technical Communications, SA 2024, Tokyo, Japan, December 3-6, 2024, pages 5:1–5:4
Daichi Haraguchi, Naoto Inoue, Wataru Shimoda, Hayato Mitani, Seiichi Uchida, and Kota Yamaguchi. Can gpts eval- uate graphic design based on design principles? InSIG- GRAPH Asia 2024 Technical Communications, SA 2024, Tokyo, Japan, December 3-6, 2024, pages 5:1–5:4. ACM,
2024
-
[15]
Harrington, J
Steven J. Harrington, J. Fernando Naveda, Rhys Price Jones, Paul G. Roetling, and Nishant Thakkar. Aesthetic mea- sures for automated document layout. InProceedings of the 2004 ACM Symposium on Document Engineering, Milwau- kee, Wisconsin, USA, October 28-30, 2004, pages 109–111. ACM, 2004. 2
2004
-
[16]
Retrieval-augmented lay- out transformer for content-aware layout generation.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 67–76, 2023
Daichi Horita, Naoto Inoue, Kotaro Kikuchi, Kota Yam- aguchi, and Kiyoharu Aizawa. Retrieval-augmented lay- out transformer for content-aware layout generation.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 67–76, 2023. 2
2024
-
[17]
Posterlayout: A new benchmark and approach for content-aware visual-textual presentation layout, 2023
HsiaoYuan Hsu, Xiangteng He, Yuxin Peng, Hao Kong, and Qing Zhang. Posterlayout: A new benchmark and approach for content-aware visual-textual presentation layout, 2023. 2
2023
-
[18]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. 7
2021
-
[19]
A survey for graphic design intelligence.arXiv preprint arXiv:2309.01371, 2023
Danqing Huang, Jiaqi Guo, Shizhao Sun, Hanling Tian, Jieru Lin, Zheng Hu, Chin-Yew Lin, Jian-Guang Lou, and Dong- mei Zhang. A survey for graphic design intelligence.arXiv preprint arXiv:2309.01371, 2023. 1, 3
-
[20]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Openclip, 2021
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Benjamin Recht, Simon Kumar, Ludwig Schmidt, and Alessandro Ross. Openclip, 2021. 2
2021
-
[22]
COLE: A hierarchical generation framework for graphic design
Peidong Jia, Chenxuan Li, Zeyu Liu, Yichao Shen, Xingru Chen, Yuhui Yuan, Yinglin Zheng, Dong Chen, Ji Li, Xi- aodong Xie, Shanghang Zhang, and Baining Guo. COLE: A hierarchical generation framework for graphic design. CoRR, abs/2311.16974, 2023. 2
-
[23]
Aesthetics++: Refining graphic designs by exploring design principles and human preference.IEEE Trans
Wenyuan Kong, Zhaoyun Jiang, Shizhao Sun, Zhuoning Guo, Weiwei Cui, Ting Liu, Jianguang Lou, and Dongmei Zhang. Aesthetics++: Refining graphic designs by exploring design principles and human preference.IEEE Trans. Vis. Comput. Graph., 29(6):3093–3104, 2023. 2
2023
-
[24]
Lisa: Reasoning segmentation via large language model.arXiv preprint arXiv:2308.00692,
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model.arXiv preprint arXiv:2308.00692,
-
[25]
Attribute-conditioned lay- out gan for automatic graphic design.IEEE Transactions on Visualization and Computer Graphics, 27:4039–4048, 2020
Jianan Li, Jimei Yang, Jianming Zhang, Chang Liu, Christina Wang, and Tingfa Xu. Attribute-conditioned lay- out gan for automatic graphic design.IEEE Transactions on Visualization and Computer Graphics, 27:4039–4048, 2020. 2
2020
-
[26]
Rockport Publishers, second edition edition, 2010
William Lidwell, Kritina Holden, and Jill Butler.Universal Principles of Design. Rockport Publishers, second edition edition, 2010. 3
2010
-
[27]
Instructlayout: Instruction-driven 2d and 3d layout synthesis with semantic graph prior.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 47: 11040–11050, 2024
Chenguo Lin, Yuchen Lin, Panwang Pan, Xuanyang Zhang, and Yadong Mu. Instructlayout: Instruction-driven 2d and 3d layout synthesis with semantic graph prior.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 47: 11040–11050, 2024. 2
2024
-
[28]
Simon Lok and Steven K. Feiner. A survey of automated layout techniques for information presentations. 2005. 2
2005
-
[29]
Pg-video-llava: Pixel grounding large video- language models.arXiv preprint arXiv:2311.13435, 2023
Shehan Munasinghe, Rusiru Thushara, Muhammad Maaz, Hanoona Abdul Rasheed, Salman Khan, Mubarak Shah, and Fahad Khan. Pg-video-llava: Pixel grounding large video- language models.arXiv preprint arXiv:2311.13435, 2023. 3
-
[30]
Sayan Nag, KJ Joseph, Koustava Goswami, Vlad I Morariu, and Balaji Vasan Srinivasan. Agentic design review system. arXiv preprint arXiv:2508.10745, 2025. 1, 2
-
[31]
A mathematical theory of interface aesthetics
David Chek Ling Ngo, Lian Seng Teo, and John G Byrne. A mathematical theory of interface aesthetics. InVisual math- ematics. Mathematical Institute SASA, 2000. 2
2000
-
[32]
Designscape: Design with interactive layout suggestions
Peter O’Donovan, Aseem Agarwala, and Aaron Hertzmann. Designscape: Design with interactive layout suggestions. Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, 2015. 2
2015
-
[33]
Gpt-4o mini.https://openai.com, 2024
OpenAI. Gpt-4o mini.https://openai.com, 2024. Accessed: 2025-02-13. 2
2024
-
[34]
Dinov2: Learning robust visual features with- out supervision, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Je- gou, Julien Mairal, Patric...
2024
-
[35]
Mayu Otani, Naoto Inoue, Kotaro Kikuchi, and Riku To- gashi. Ltsim: Layout transportation-based similarity mea- sure for evaluating layout generation.arXiv preprint arXiv:2407.12356, 2024. 1
-
[36]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
2022
-
[37]
Learning layouts for single-pagegraphic designs.IEEE transactions on visualization and computer graphics, 20(8): 1200–1213, 2014
Peter O’Donovan, Aseem Agarwala, and Aaron Hertzmann. Learning layouts for single-pagegraphic designs.IEEE transactions on visualization and computer graphics, 20(8): 1200–1213, 2014. 2
2014
-
[38]
Aesthetiq: Enhancing graphic layout design via aesthetic-aware preference alignment of multi- modal large language models, 2025
Sohan Patnaik, Rishabh Jain, Balaji Krishnamurthy, and Mausoom Sarkar. Aesthetiq: Enhancing graphic layout design via aesthetic-aware preference alignment of multi- modal large language models, 2025. 1
2025
-
[39]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Ground- ing multimodal large language models to the world.arXiv preprint arXiv:2306.14824, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Jack of all tasks master of many: Designing general-purpose coarse-to-fine vision- language model
Shraman Pramanick, Guangxing Han, Rui Hou, Sayan Nag, Ser-Nam Lim, Nicolas Ballas, Qifan Wang, Rama Chel- lappa, and Amjad Almahairi. Jack of all tasks master of many: Designing general-purpose coarse-to-fine vision- language model. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 14076–14088, 2024. 3
2024
-
[41]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Er- mon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model, 2024. 8
2024
-
[42]
Glamm: Pixel grounding large multimodal model.arXiv preprint arXiv:2311.03356, 2023
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdel- rahman Shaker, Salman Khan, Hisham Cholakkal, Rao M Anwer, Erix Xing, Ming-Hsuan Yang, and Fahad S Khan. Glamm: Pixel grounding large multimodal model.arXiv preprint arXiv:2311.03356, 2023. 3
-
[43]
Berg, and Li Fei-Fei
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge,
-
[44]
Chufan Shi, Haoran Yang, Deng Cai, Zhisong Zhang, Yi- fan Wang, Yujiu Yang, and Wai Lam. A thorough examina- tion of decoding methods in the era of llms.arXiv preprint arXiv:2402.06925, 2024. 2, 7
-
[45]
Intelligent layout generation based on deep generative models: A com- prehensive survey.Inf
Yong Shi, Mengyuan Shang, and Zhiquan Qi. Intelligent layout generation based on deep generative models: A com- prehensive survey.Inf. Fusion, 100:101940, 2023. 2
2023
-
[46]
De- mystifying tacit knowledge in graphic design: Characteris- tics, instances, approaches, and guidelines
Kihoon Son, DaEun Choi, Tae Soo Kim, and Juho Kim. De- mystifying tacit knowledge in graphic design: Characteris- tics, instances, approaches, and guidelines. InProceedings of the 2024 CHI Conference on Human Factors in Comput- ing Systems, pages 1–18, 2024. 1, 3
2024
-
[47]
Jain, Vlad I Morariu, Ramit Sawhney, Preslav Nakov, and Dinesh Manocha
Manan Suri, Puneet Mathur, Franck Dernoncourt, R. Jain, Vlad I Morariu, Ramit Sawhney, Preslav Nakov, and Dinesh Manocha. Docedit-v2: Document structure editing via mul- timodal llm grounding. InConference on Empirical Methods in Natural Language Processing, 2024. 2
2024
-
[48]
Automatic layout generation for graphical design magazines
Sou Tabata, Hiroki Yoshihara, Haruka Maeda, and Kei Yokoyama. Automatic layout generation for graphical design magazines. InSpecial Interest Group on Com- puter Graphics and Interactive Techniques Conference, SIG- GRAPH 2019, Los Angeles, CA, USA, July 28 - August 1, 2019, Posters, pages 9:1–9:2. ACM, 2019. 2
2019
-
[49]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
The all-seeing project: Towards panop- tic visual recognition and understanding of the open world
Weiyun Wang, Min Shi, Qingyun Li, Wenhai Wang, Zhen- hang Huang, Linjie Xing, Zhe Chen, Hao Li, Xizhou Zhu, Zhiguo Cao, et al. The all-seeing project: Towards panop- tic visual recognition and understanding of the open world. arXiv preprint arXiv:2308.01907, 2023. 3
-
[51]
A hybrid local-global neural network for visual classification using raw eeg signals.Scientific Reports, 14, 2024
Shuning Xue, Bu Jin, Jie Jiang, Longteng Guo, and Jing Liu. A hybrid local-global neural network for visual classification using raw eeg signals.Scientific Reports, 14, 2024. 3
2024
-
[52]
Canvasvae: Learning to generate vector graphic documents
Kota Yamaguchi. Canvasvae: Learning to generate vector graphic documents. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 5481–5489,
-
[53]
Ferret: Refer and Ground Anything Anywhere at Any Granularity
Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity.arXiv preprint arXiv:2310.07704, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Towards an evaluation of graphical user interfaces aesthetics based on metrics
Mathieu Zen and Jean Vanderdonckt. Towards an evaluation of graphical user interfaces aesthetics based on metrics. In IEEE 8th International Conference on Research Challenges in Information Science, RCIS 2014, Marrakech, Morocco, May 28-30, 2014, pages 1–12. IEEE, 2014. 2
2014
-
[55]
Creatidesign: A unified multi-conditional diffusion transformer for creative graphic design, 2025
Hui Zhang, Dexiang Hong, Maoke Yang, Yutao Cheng, Zhao Zhang, Jie Shao, Xinglong Wu, Zuxuan Wu, and Yu-Gang Jiang. Creatidesign: A unified multi-conditional diffusion transformer for creative graphic design, 2025. 6, 2
2025
-
[56]
Jiahao Zhang, Ryota Yoshihashi, Shunsuke Kitada, Atsuki Osanai, and Yuta Nakashima. Vascar: Content-aware layout generation via visual-aware self-correction.arXiv preprint arXiv:2412.04237, 2024. 1, 2
-
[57]
Nanxuan Zhao, Ying Cao, and Rynson W. H. Lau. What characterizes personalities of graphic designs?ACM Trans. Graph., 37(4):116, 2018. 2
2018
-
[58]
Bubogpt: Enabling visual ground- ing in multi-modal llms.arXiv preprint arXiv:2307.08581,
Yang Zhao, Zhijie Lin, Daquan Zhou, Zilong Huang, Jiashi Feng, and Bingyi Kang. Bubogpt: Enabling visual ground- ing in multi-modal llms.arXiv preprint arXiv:2307.08581,
-
[59]
coherence_score
Xingxing Zou, Wen Zhang, and Nanxuan Zhao. From frag- ment to one piece: A review on ai-driven graphic design. Journal of Imaging, 11(9):289, 2025. 1 Through the PRISM: Principle-Aware, Interpretable, and Multi-Scale Evaluation of Visual Designs Supplementary Material The supplementary is organised as follows: A PRISM Perturbations B Prompting Setup for M...
2025
-
[60]
We then report averaged PRISM- scorer performance across all five principles
trained on ImageNet [43], SigLIP-v2 [49] trained on WebLI [4], and the self-supervised DINOv2 model [34], but we freeze the entire backbone and train only an iden- tical lightweight two-layer binary classifier on top for all models, ensuring that differences arise solely from the back- bone representations. We then report averaged PRISM- scorer performanc...
-
[61]
and CreatiDesign [55]. This multimodal contrastive supervision leads to substantial improvements: fine-tuned OpenCLIP ViT-B/16 significantly outperforms all frozen variants, and SigLIP-v2 (Ours) achieves the strongest per- formance across precision, recall, F1, and AUC. These find- ings underscore the importance of principle-aware multi- modal fine-tuning...
-
[62]
Font Size: Text that is too small can be difficult to read, also note the texts which are important with small font size resulting in not drawing enough attention
-
[63]
Font Color: Text that has low contrast with its background can be hard to distinguish, making it less readable
-
[64]
When responding, provide a list of text elements that have readability issues based on the above criteria
Line Height: Text with insufficient line height can appear cramped, making it challenging to read multiple lines. When responding, provide a list of text elements that have readability issues based on the above criteria. If no issues are found, respond with 'No such text'. Only choose from the provided list of texts in the image and respond with only the ...
-
[65]
Text Contrast: Text that has low contrast with its background can be hard to distinguish
-
[66]
When responding, provide a list pairs of elements that have contrast issues based on the above criteria
Icon or Element Contrast: Any icon or element which is difficult to locate due to low contrast. When responding, provide a list pairs of elements that have contrast issues based on the above criteria. If no issues are found, respond with 'No such pairs'. Only choose from the provided list of pairs and respond with only the corresponding pairs of elements ...
-
[67]
Icon-Icon Overlap: Two icons overlap leading to unnecessary occlusion
-
[68]
When responding, provide a list pairs of elements that have overlap issues based on the above criteria
Icon- Element Overlap: Icon overlapping with another element. When responding, provide a list pairs of elements that have overlap issues based on the above criteria. If no issues are found, respond with 'No such pairs'. Only choose from the provided list of pairs and respond with only the corresponding pairs of elements that has overlap issues separated b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.