ASAP: Advancing Medical Volumetric Representation Learning with Anatomy-aware Semantically-adaptive Pre-training
Pith reviewed 2026-06-28 19:14 UTC · model grok-4.3
The pith
ASAP pre-trains chest CT models to respect organ anatomy and align report sentences to specific scan regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
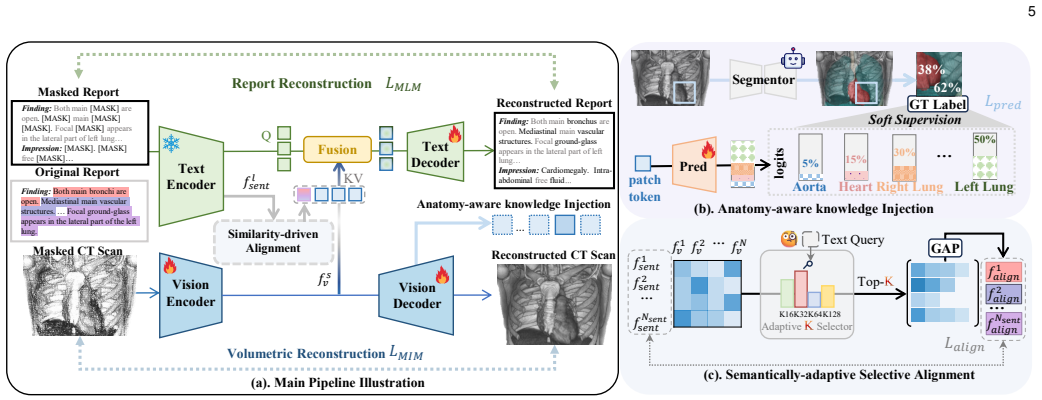
ASAP integrates an anatomy-aware knowledge injection module that incorporates organ-level structural priors via an off-the-shelf segmentation tool, a semantically-adaptive selective alignment mechanism that dynamically associates sentence-level findings with localized volumetric regions, and a semantically-adaptive fusion module for interaction between anatomically informed visual features and grounded textual cues under a dual-modal masked modeling paradigm. This combination produces state-of-the-art results across the benchmark tasks, with larger improvements when supervision is limited or when test data comes from a different distribution.
What carries the argument
The three-module ASAP framework that injects organ priors from segmentation, performs selective sentence-to-region alignment, and fuses visual and textual cues under masked modeling.
If this is right
- Representations improve on abnormality classification, segmentation, disease prognosis, report generation, cross-modal retrieval, and visual question answering from chest CT.
- Gains become larger when labeled data for downstream tasks is scarce.
- Performance holds up better when test scans come from a different source or scanner than the pre-training data.
- The learned features remain clinically interpretable because they are tied to specific organs and report findings.
Where Pith is reading between the lines
- If the selective alignment proves reliable, the same pre-training could support more precise report generation that points to exact locations inside the volume.
- The approach could be tested on other volumetric modalities such as MRI once comparable segmentation tools exist.
- Success on the benchmark suggests that similar anatomy-aware alignment might help vision-language models in non-medical domains where spatial structure matters.
Load-bearing premise
The off-the-shelf segmentation tool supplies accurate organ-level structural priors that improve representation quality without segmentation errors being amplified by the alignment and fusion modules.
What would settle it
An ablation that removes the anatomy-aware injection module and measures whether performance drops to the level of prior methods on the 22-task benchmark, especially under limited supervision.
Figures






read the original abstract
Learning transferable and interpretable representations from medical volumetric scans remains challenging due to complex anatomical structures and weak, heterogeneous supervision provided by radiology reports. In this paper, we propose Anatomy-aware Semantically-Adaptive Pre-training (ASAP), a principled vision-language pre-training framework for fine-grained medical volumetric representation learning from large-scale chest CT scans and their corresponding radiology reports. ASAP integrates three key components: (1) an anatomy-aware knowledge injection module that incorporates organ-level structural priors via off-the-shelf segmentation tool to encourage anatomically coherent representations; (2) a semantically-adaptive selective alignment mechanism that dynamically associates sentence-level findings with localized volumetric regions; and (3) a semantically-adaptive fusion module for effective interaction between anatomically informed visual features and grounded textual cues under dual-modal masked modeling paradigm. Beyond methodological contributions, we establish a comprehensive benchmark for medical volumetric vision-language pre-training on chest CT, covering 15 datasets and 22 downstream tasks spanning abnormality classification, segmentation, disease prognosis prediction, report generation, vocabulary classification, cross-modal retrieval and visual question answering. This benchmark provides standardized evaluation protocols to systematically assess representation quality under diverse clinical settings and data regimes. Extensive experiments demonstrate that ASAP consistently achieves state-of-the-art performance across tasks and datasets, with particularly pronounced gains under limited supervision and distribution shift, validating its effectiveness in learning transferable and clinically meaningful volumetric representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Anatomy-aware Semantically-Adaptive Pre-training (ASAP), a vision-language pre-training framework for chest CT volumes paired with radiology reports. It introduces three components: (1) an anatomy-aware knowledge injection module that injects organ-level structural priors obtained from an off-the-shelf segmentation tool, (2) a semantically-adaptive selective alignment mechanism that links sentence-level findings to localized volumetric regions, and (3) a semantically-adaptive fusion module operating under a dual-modal masked modeling objective. The authors also present a new benchmark spanning 15 datasets and 22 downstream tasks (classification, segmentation, prognosis, report generation, retrieval, VQA) and claim consistent state-of-the-art performance, with larger gains under limited supervision and distribution shift.
Significance. If the reported gains are reproducible and attributable to the proposed modules rather than segmentation artifacts, the work would supply both a methodological template and a standardized multi-task benchmark for volumetric medical vision-language pre-training. The focus on anatomy-aware priors and adaptive alignment directly targets the challenges of complex 3-D structure and weak report supervision, which are central to clinical deployment under data scarcity and domain shift.
major comments (2)
- [Anatomy-aware knowledge injection module] Anatomy-aware knowledge injection module (abstract and §3): the central claim that this module produces 'anatomically coherent representations' that drive SOTA gains rests on the assumption that the off-the-shelf segmentation tool supplies sufficiently accurate organ priors. No segmentation-quality ablations, error-injection experiments, per-dataset Dice scores on the 15 evaluation sets, or analysis of error propagation through the subsequent alignment and fusion modules are provided. This is load-bearing for the claim of transferable representations under distribution shift.
- [Benchmark and experimental results] Benchmark and experimental results (abstract and §4–5): the manuscript asserts 'particularly pronounced gains under limited supervision and distribution shift' across 22 tasks, yet provides no quantitative tables, error bars, statistical tests, or dataset-shift definitions in the supplied text. Without these, it is impossible to verify whether the performance advantage is robust or an artifact of the particular segmentation tool and data splits.
minor comments (2)
- [Method] The description of the selective alignment and fusion modules would benefit from explicit equations or pseudocode showing how sentence-level embeddings are dynamically matched to volumetric regions.
- [Experiments] Figure captions and table headers should explicitly state the number of runs, random seeds, and whether results are averaged or best-of-N.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the anatomy-aware module and experimental reporting. We address the two major comments below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Anatomy-aware knowledge injection module] Anatomy-aware knowledge injection module (abstract and §3): the central claim that this module produces 'anatomically coherent representations' that drive SOTA gains rests on the assumption that the off-the-shelf segmentation tool supplies sufficiently accurate organ priors. No segmentation-quality ablations, error-injection experiments, per-dataset Dice scores on the 15 evaluation sets, or analysis of error propagation through the subsequent alignment and fusion modules are provided. This is load-bearing for the claim of transferable representations under distribution shift.
Authors: We agree that the accuracy of the off-the-shelf segmentation tool is a critical assumption underlying claims of anatomically coherent representations and robustness under distribution shift. The current manuscript does not contain segmentation-quality ablations, error-injection experiments, Dice scores, or error-propagation analysis. We will add these elements in revision: an ablation injecting controlled segmentation noise, Dice scores on the subset of benchmark datasets that provide organ-level ground truth, and a discussion of error propagation through the alignment and fusion modules. Where full per-dataset Dice scores are infeasible due to missing annotations, we will explicitly note the limitation. revision: yes
-
Referee: [Benchmark and experimental results] Benchmark and experimental results (abstract and §4–5): the manuscript asserts 'particularly pronounced gains under limited supervision and distribution shift' across 22 tasks, yet provides no quantitative tables, error bars, statistical tests, or dataset-shift definitions in the supplied text. Without these, it is impossible to verify whether the performance advantage is robust or an artifact of the particular segmentation tool and data splits.
Authors: The experimental sections (§4–5) contain comparative tables across the 22 tasks. To directly address the concern that these details were not evident in the supplied text, the revision will explicitly include error bars (standard deviation across runs), statistical significance tests, and precise definitions of distribution shift (e.g., scanner vendor or acquisition protocol differences). Results under limited-supervision regimes will be highlighted with the same rigor. revision: yes
- Per-dataset Dice scores on all 15 evaluation sets, as the majority of downstream tasks lack organ-level segmentation ground truth.
Circularity Check
No circularity; derivation is self-contained with external components
full rationale
The paper describes a standard vision-language pre-training setup augmented by three modules: anatomy-aware injection via an off-the-shelf segmentation tool (external input), selective alignment, and fusion under masked modeling. No equations or steps reduce by construction to fitted parameters renamed as predictions, no self-citations are load-bearing for uniqueness or ansatz, and no self-definitional loops appear. The benchmark and SOTA claims rest on empirical evaluation across 15 datasets rather than internal re-derivation. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Simcrop: Radiograph representation learning with similarity-driven cross-granularity pre-training,
R. Wanget al., “Simcrop: Radiograph representation learning with similarity-driven cross-granularity pre-training,” inMIC- CAI. Springer, 2025, pp. 563–573
2025
-
[2]
Unimiss+: Universal medical self-supervised learn- ing from cross-dimensional unpaired data,
Y. Xieet al., “Unimiss+: Universal medical self-supervised learn- ing from cross-dimensional unpaired data,”TP AMI, vol. 46, no. 12, pp. 10 021–10 035, 2024
2024
-
[3]
Medical image segmentation review: The success of u-net,
R. Azadet al., “Medical image segmentation review: The success of u-net,”TP AMI, vol. 46, no. 12, pp. 10 076–10 095, 2024
2024
-
[4]
Visionunite: A vision-language foundation model for ophthalmology enhanced with clinical knowledge,
Z. Liet al., “Visionunite: A vision-language foundation model for ophthalmology enhanced with clinical knowledge,”TP AMI, 2025
2025
-
[5]
Pathway-aware multimodal transformer (pamt): Integrating pathological image and gene expression for inter- pretable cancer survival analysis,
R. Yanet al., “Pathway-aware multimodal transformer (pamt): Integrating pathological image and gene expression for inter- pretable cancer survival analysis,”TP AMI, vol. 48, no. 1, pp. 896– 913, 2026
2026
-
[6]
A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises,
S. K. Zhouet al., “A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises,”Proceedings of the IEEE, 2021
2021
-
[7]
Minimizing estimated risks on unlabeled data: A new formulation for semi-supervised medical image segmentation,
F. Wu and X. Zhuang, “Minimizing estimated risks on unlabeled data: A new formulation for semi-supervised medical image segmentation,”TP AMI, vol. 45, no. 5, pp. 6021–6036, 2023
2023
-
[8]
Deep transfer learning based classification model for covid-19 disease,
Y. Pathaket al., “Deep transfer learning based classification model for covid-19 disease,”Irbm, vol. 43, no. 2, pp. 87–92, 2022
2022
-
[9]
Recent advances and clinical applications of deep learning in medical image analysis,
X. Chenet al., “Recent advances and clinical applications of deep learning in medical image analysis,”MedIA, vol. 79, p. 102444, 2022
2022
-
[10]
Diagnose like a radiologist: Hybrid neuro- probabilistic reasoning for attribute-based medical image diag- nosis,
G. Zhaoet al., “Diagnose like a radiologist: Hybrid neuro- probabilistic reasoning for attribute-based medical image diag- nosis,”TP AMI, vol. 44, no. 11, pp. 7400–7416, 2022
2022
-
[11]
Homeomorphism prior for false positive and nega- tive problem in medical image dense contrastive representation learning,
Y. Heet al., “Homeomorphism prior for false positive and nega- tive problem in medical image dense contrastive representation learning,”TP AMI, vol. 47, no. 5, pp. 4122–4139, 2025
2025
-
[12]
Generalized radiograph representation learn- ing via cross-supervision between images and free-text radiology reports,
H.-Y. Zhouet al., “Generalized radiograph representation learn- ing via cross-supervision between images and free-text radiology reports,”Nature Machine Intelligence, vol. 4, no. 1, pp. 32–40, 2022
2022
-
[13]
Knowledge- enhanced visual-language pre-training on chest radiology im- ages,
X. Zhang, C. Wu, Y. Zhang, W. Xie, and Y. Wang, “Knowledge- enhanced visual-language pre-training on chest radiology im- ages,”Nature Communications, vol. 14, no. 1, p. 4542, 2023
2023
-
[14]
Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data,
C. Wuet al., “Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data,”Nature Communi- cations, vol. 16, no. 1, p. 7866, 2025
2025
-
[15]
A unified visual information preservation framework for self-supervised pre-training in medical image analysis,
H.-Y. Zhouet al., “A unified visual information preservation framework for self-supervised pre-training in medical image analysis,”TP AMI, vol. 45, no. 7, pp. 8020–8035, 2023
2023
-
[16]
A medical multimodal large language model for future pandemics,
F. Liuet al., “A medical multimodal large language model for future pandemics,”NPJ Digital Medicine, vol. 6, no. 1, p. 226, 2023
2023
-
[17]
Abdomenct-1k: Is abdominal organ segmentation a solved problem?
J. Maet al., “Abdomenct-1k: Is abdominal organ segmentation a solved problem?”TP AMI, vol. 44, no. 10, pp. 6695–6714, 2022
2022
-
[18]
Development of a large-scale medical visual question-answering dataset,
X. Zhanget al., “Development of a large-scale medical visual question-answering dataset,”Communications Medicine, vol. 4, no. 1, p. 277, 2024
2024
-
[19]
Large-scale long-tailed disease diagnosis on radiology images,
Q. Zhenget al., “Large-scale long-tailed disease diagnosis on radiology images,”Nature Communications, vol. 15, no. 1, p. 10147, 2024
2024
-
[20]
Medical multimodal multitask foundation model for lung cancer screening,
C. Niuet al., “Medical multimodal multitask foundation model for lung cancer screening,”Nature Communications, vol. 16, no. 1, p. 1523, 2025
2025
-
[21]
Hi-end-mae: Hierarchical encoder-driven masked autoencoders are stronger vision learners for medical image segmentation,
F. Tanget al., “Hi-end-mae: Hierarchical encoder-driven masked autoencoders are stronger vision learners for medical image segmentation,”MedIA, p. 103770, 2026
2026
-
[22]
Contrastive learning of medical visual repre- sentations from paired images and text,
Y. Zhanget al., “Contrastive learning of medical visual repre- sentations from paired images and text,” inMachine learning for healthcare conference. PMLR, 2022, pp. 2–25
2022
-
[23]
Gloria: A multimodal global-local repre- sentation learning framework for label-efficient medical image recognition,
S.-C. Huanget al., “Gloria: A multimodal global-local repre- sentation learning framework for label-efficient medical image recognition,” inICCV, 2021, pp. 3942–3951
2021
-
[24]
Multi-granularity cross-modal align- ment for generalized medical visual representation learning,
F. Wang, Y. Zhouet al., “Multi-granularity cross-modal align- ment for generalized medical visual representation learning,” in NeurIPS, vol. 35, 2022, pp. 33 536–33 549
2022
-
[25]
MedCLIP: Contrastive learning from unpaired medical images and text,
Z. Wanget al., “MedCLIP: Contrastive learning from unpaired medical images and text,” inEMNLP, Dec. 2022, pp. 3876–3887
2022
-
[26]
Medklip: Medical knowledge enhanced language- image pre-training,
C. Wuet al., “Medklip: Medical knowledge enhanced language- image pre-training,” inICCV, 2023
2023
-
[27]
Expert-level detection of pathologies from unan- notated chest x-ray images via self-supervised learning,
E. Tiuet al., “Expert-level detection of pathologies from unan- notated chest x-ray images via self-supervised learning,”Nature Biomedical Engineering, vol. 6, no. 12, pp. 1399–1406, 2022
2022
-
[28]
Advancing radiograph representation learning with masked record modeling,
H.-Y. Zhouet al., “Advancing radiograph representation learning with masked record modeling,” inICLR, 2023
2023
-
[29]
Mlip: Enhancing medical visual representation with divergence encoder and knowledge-guided contrastive learn- ing,
Z. Liet al., “Mlip: Enhancing medical visual representation with divergence encoder and knowledge-guided contrastive learn- ing,” inCVPR, 2024, pp. 11 704–11 714
2024
-
[30]
Enhancing representation in radiography- reports foundation model: A granular alignment algorithm using masked contrastive learning,
W. Huanget al., “Enhancing representation in radiography- reports foundation model: A granular alignment algorithm using masked contrastive learning,”Nature Communications, vol. 15, no. 1, p. 7620, 2024
2024
-
[31]
Ecamp: Entity-centered context-aware medical vision language pre-training,
R. Wang, Q. Yao, Z. Jiang, H. Lai, Z. He, X. Tao, and S. K. Zhou, “Ecamp: Entity-centered context-aware medical vision language pre-training,”MedIA, vol. 105, p. 103690, 2025
2025
-
[32]
Efficient medical vision-language alignment through adapting masked vision models,
C. Lianet al., “Efficient medical vision-language alignment through adapting masked vision models,”TMI, 2025
2025
-
[33]
Bootstrapping chest ct image understanding by distilling knowledge from x-ray expert models,
W. Caoet al., “Bootstrapping chest ct image understanding by distilling knowledge from x-ray expert models,” inCVPR, 2024, pp. 11 238–11 247
2024
-
[34]
Merlin: a computed tomography vision– language foundation model and dataset,
L. Blankemeieret al., “Merlin: a computed tomography vision– language foundation model and dataset,”Nature, pp. 1–11, 2026
2026
-
[35]
Large-scale 3d medical image pre-training with geometric context priors,
L. Wu, J. Zhuang, and H. Chen, “Large-scale 3d medical image pre-training with geometric context priors,”TP AMI, pp. 1–18, 2025
2025
-
[36]
Generalist foundation models from a mul- timodal dataset for 3d computed tomography,
I. E. Hamamciet al., “Generalist foundation models from a mul- timodal dataset for 3d computed tomography,”Nature Biomedical Engineering, pp. 1–19, 2026
2026
-
[37]
Machine-learning-based multiple abnor- mality prediction with large-scale chest computed tomography volumes,
R. L. Draeloset al., “Machine-learning-based multiple abnor- mality prediction with large-scale chest computed tomography volumes,”MedIA, vol. 67, p. 101857, 2021
2021
-
[38]
Bimcv covid-19+: A large annotated dataset of rx and ct images from covid-19 patients,
M. D. L. I. Vay ´aet al., “Bimcv covid-19+: A large annotated dataset of rx and ct images from covid-19 patients,”arXiv preprint arXiv:2006.01174, 2020
-
[39]
Large-scale and fine-grained vision-language pre- training for enhanced ct image understanding,
Z. Shuiet al., “Large-scale and fine-grained vision-language pre- training for enhanced ct image understanding,” inICLR, 2025
2025
-
[40]
Boosting vision semantic density with anatomy normality modeling for medical vision-language pre-training,
W. Caoet al., “Boosting vision semantic density with anatomy normality modeling for medical vision-language pre-training,” inICCV, 2025, pp. 23 041–23 050
2025
-
[41]
J. Linet al., “Ct-glip: 3d grounded language-image pretraining with ct scans and radiology reports for full-body scenarios,” arXiv preprint arXiv:2404.15272, 2024
-
[42]
F. Baiet al., “M3d: Advancing 3d medical image analy- sis with multi-modal large language models,”arXiv preprint arXiv:2404.00578, 2024
-
[43]
T3d: Advancing 3d medical vision-language pre- training by learning multi-view visual consistency,
C. Liuet al., “T3d: Advancing 3d medical vision-language pre- training by learning multi-view visual consistency,” inICCV Workshops, October 2025, pp. 6704–6714
2025
-
[44]
Radzero3d: Bridging self-supervised video models and medical vision-language alignment for zero-shot chest ct interpretation,
J. Parket al., “Radzero3d: Bridging self-supervised video models and medical vision-language alignment for zero-shot chest ct interpretation,” inICCV Workshops, October 2025, pp. 6742–6749
2025
-
[45]
Large-vocabulary segmentation for medical im- ages with text prompts,
Z. Zhaoet al., “Large-vocabulary segmentation for medical im- ages with text prompts,”NPJ Digital Medicine, vol. 8, no. 1, p. 566, 2025
2025
-
[46]
Totalsegmentator: robust segmentation of 104 anatomic structures in ct images,
J. Wasserthalet al., “Totalsegmentator: robust segmentation of 104 anatomic structures in ct images,”Radiology: Artificial Intelligence, vol. 5, no. 5, p. e230024, 2023
2023
-
[47]
Towards scalable language-image pre-training for 3d medical imaging,
C. Zhaoet al., “Towards scalable language-image pre-training for 3d medical imaging,”Transactions on Machine Learning Research, 2026
2026
-
[48]
Multi-modal masked autoencoders for medical vision-and-language pre-training,
Z. Chenet al., “Multi-modal masked autoencoders for medical vision-and-language pre-training,” inMICCAI. Springer, 2022, pp. 679–689
2022
-
[49]
Learning transferable visual models from natural language supervision,
A. o. Radford, “Learning transferable visual models from natural language supervision,” inICML. PMLR, 2021, pp. 8748–8763
2021
-
[50]
Scaling up visual and vision-language representation learning with noisy text supervision,
C. Jiaet al., “Scaling up visual and vision-language representation learning with noisy text supervision,” inICML. PMLR, 2021, pp. 4904–4916
2021
-
[51]
CoCa: Contrastive Captioners are Image-Text Foundation Models
J. Yuet al., “Coca: Contrastive captioners are image-text founda- tion models,”arXiv preprint arXiv:2205.01917, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[52]
Grounded language-image pre-training,
L. H. Li, P . Zhang, H. Zhang, J. Yang, C. Li, Y. Zhong, L. Wang, L. Yuan, L. Zhang, J.-N. Hwanget al., “Grounded language-image pre-training,” inCVPR, 2022, pp. 10 965–10 975. 17
2022
-
[53]
Scaling language-image pre-training via masking,
Y. Liet al., “Scaling language-image pre-training via masking,” in CVPR, 2023
2023
-
[54]
Flamingo: a visual language model for few- shot learning,
J.-B. Alayracet al., “Flamingo: a visual language model for few- shot learning,”NeurIPS, vol. 35, pp. 23 716–23 736, 2022
2022
-
[55]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,
J. Liet al., “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” in ICML. PMLR, 2023, pp. 19 730–19 742
2023
-
[56]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” NeurIPS, vol. 36, pp. 34 892–34 916, 2023
2023
-
[57]
Sigmoid loss for language image pre-training,
X. Zhaiet al., “Sigmoid loss for language image pre-training,” in ICCV, 2023, pp. 11 975–11 986
2023
-
[58]
Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,
J. Luet al., “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,”NeurIPS, vol. 32, 2019
2019
-
[59]
Vl-bert: Pre-training of generic visual-linguistic representations,
W. Su, X. Zhu, Y. Cao, B. Li, L. Lu, F. Wei, and J. Dai, “Vl-bert: Pre-training of generic visual-linguistic representations,” inICLR, 2020
2020
-
[60]
Beit: Bert pre-training of image transformers,
H. Bao, L. Dong, S. Piao, and F. Wei, “Beit: Bert pre-training of image transformers,” inICLR, 2022
2022
-
[61]
Flava: A foundational language and vision alignment model,
A. Singhet al., “Flava: A foundational language and vision alignment model,” inCVPR, June 2022, pp. 15 638–15 650
2022
-
[62]
Image as a foreign language: Beit pretraining for vision and vision-language tasks,
W. Wanget al., “Image as a foreign language: Beit pretraining for vision and vision-language tasks,” inCVPR, 2023, pp. 19 175– 19 186
2023
-
[63]
Valor: Vision-audio-language omni-perception pre- training model and dataset,
J. Liuet al., “Valor: Vision-audio-language omni-perception pre- training model and dataset,”TP AMI, vol. 47, no. 2, pp. 708–724, 2025
2025
-
[64]
Unsupervised pre-training with language-vision prompts for low-data instance segmentation,
D. Zhanget al., “Unsupervised pre-training with language-vision prompts for low-data instance segmentation,”TP AMI, vol. 47, no. 10, pp. 8642–8657, 2025
2025
-
[65]
Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports,
A. E. Johnsonet al., “Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports,”Scientific data, vol. 6, no. 1, pp. 1–8, 2019
2019
-
[66]
Eva-x: A foundation model for general chest x- ray analysis with self-supervised learning,
J. Yaoet al., “Eva-x: A foundation model for general chest x- ray analysis with self-supervised learning,”npj Digital Medicine, vol. 8, no. 1, p. 678, 2025
2025
-
[67]
Med-unic: Unifying cross-lingual medical vision- language pre-training by diminishing bias,
Z. Wanet al., “Med-unic: Unifying cross-lingual medical vision- language pre-training by diminishing bias,” inNeurIPS, 2023
2023
-
[68]
Rethinking masked image modeling for medical image representation,
Y. Xieet al., “Rethinking masked image modeling for medical image representation,”MedIA, p. 103304, 2024
2024
-
[69]
Voco: A simple-yet-effective volume contrastive learning framework for 3d medical image analysis,
L. Wuet al., “Voco: A simple-yet-effective volume contrastive learning framework for 3d medical image analysis,” inCVPR, June 2024, pp. 22 873–22 882
2024
-
[70]
Mim: Mask in mask self-supervised pre-training for 3d medical image analysis,
J. Zhuanget al., “Mim: Mask in mask self-supervised pre-training for 3d medical image analysis,”TMI, 2025
2025
-
[71]
Enhancing the vision–language foundation model with key semantic knowledge-emphasized report refine- ment,
W. Huanget al., “Enhancing the vision–language foundation model with key semantic knowledge-emphasized report refine- ment,”MedIA, vol. 97, p. 103299, 2024
2024
-
[72]
Imitate: Clinical prior guided hierarchical vision- language pre-training,
C. Liuet al., “Imitate: Clinical prior guided hierarchical vision- language pre-training,”TMI, 2024
2024
-
[73]
Multi-grained vision-and-language model for medical image and text alignment,
H. Yanet al., “Multi-grained vision-and-language model for medical image and text alignment,”TMM, 2025
2025
-
[74]
Semantic-aware hard negative mining for medical vision-language contrastive pretraining,
Y. Liet al., “Semantic-aware hard negative mining for medical vision-language contrastive pretraining,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 3133–3142
2025
-
[75]
Prior: Prototype representation joint learning from medical images and reports,
P . Chenget al., “Prior: Prototype representation joint learning from medical images and reports,” inICCV, 2023, pp. 21 361– 21 371
2023
-
[76]
G2d: From global to dense radiography representa- tion learning via vision-language pre-training,
C. Liuet al., “G2d: From global to dense radiography representa- tion learning via vision-language pre-training,”NeurIPS, vol. 37, pp. 14 751–14 773, 2024
2024
-
[77]
X-ray computed tomography,
P . J. Witherset al., “X-ray computed tomography,”Nature Reviews Methods Primers, vol. 1, no. 1, p. 18, 2021
2021
-
[78]
Geometric visual similarity learning in 3d medical image self-supervised pre-training,
Y. Heet al., “Geometric visual similarity learning in 3d medical image self-supervised pre-training,” inCVPR, 2023, pp. 9538– 9547
2023
-
[79]
Unified medical image pre-training in language- guided common semantic space,
X. Heet al., “Unified medical image pre-training in language- guided common semantic space,” inECCV. Springer, 2024, pp. 123–139
2024
-
[80]
Mg-3d: Multi-grained knowledge-enhanced vision- language pre-training for 3d medical image analysis,
X. Niet al., “Mg-3d: Multi-grained knowledge-enhanced vision- language pre-training for 3d medical image analysis,”MedIA, p. 104027, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.