Looped Transformers with Layer Normalization Provably Learn the Power Method
Pith reviewed 2026-06-28 19:01 UTC · model grok-4.3
The pith
A looped linear transformer with layer normalization, trained only on principal component prediction, converges via gradient descent to implement the power method.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
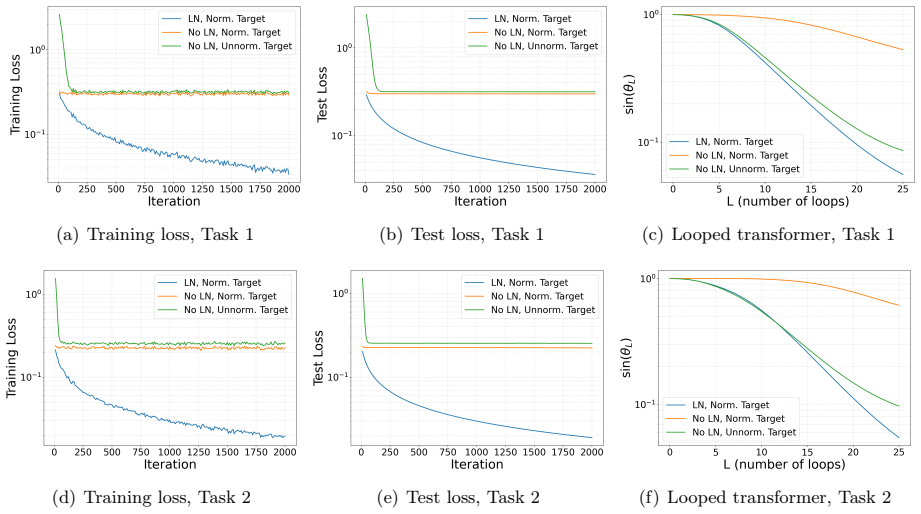
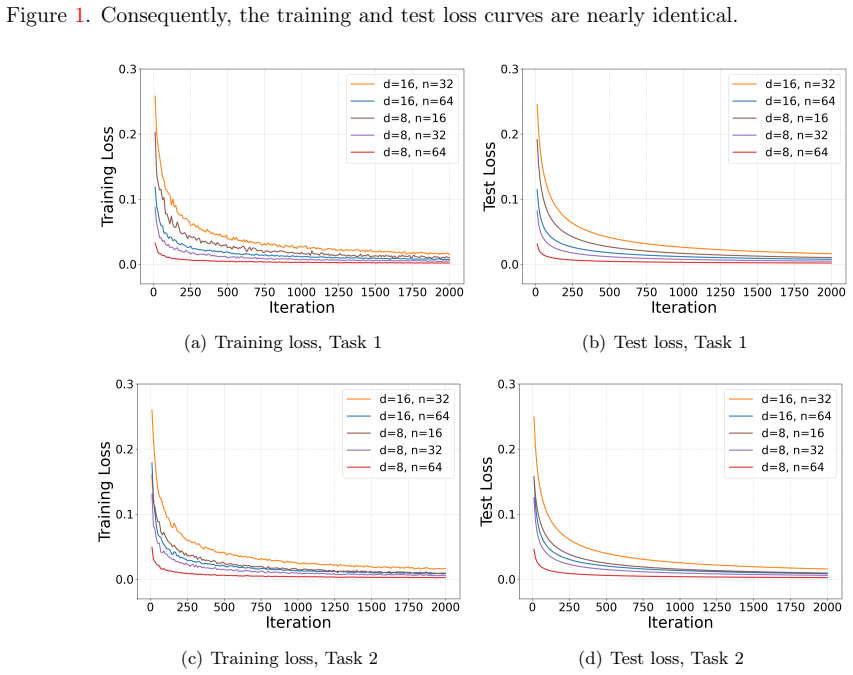
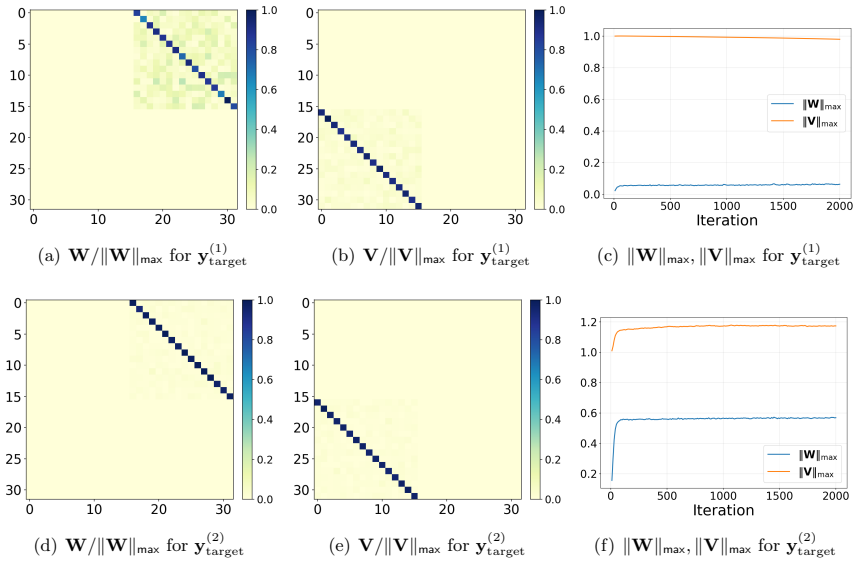
A looped linear transformer with layer normalization, trained by gradient descent on the principal component prediction task, converges to parameters that make each self-attention layer perform one iteration of the power method. The training uses only the end task loss; no direct supervision on the iterative procedure is provided. This yields an algorithmic implicit bias in which the power method is selected. In contrast, the identical architecture without layer normalization fails to implement the power method exactly even when layerwise guidance toward power iterations is supplied.
What carries the argument
The looped linear transformer with layer normalization, in which repeated application of the same self-attention layer, stabilized by LN, aligns exactly with successive power iterations on the data covariance.
If this is right
- Each self-attention layer in the converged model applies one power iteration to the input vector.
- Multiple loops produce an approximation to the dominant eigenvector of the covariance.
- Transformers without layer normalization incur a provable gap in principal component prediction accuracy compared with the LN version.
- The loss landscape favors the power-method solution over alternative mechanisms that could also minimize the prediction error.
Where Pith is reading between the lines
- The same implicit bias toward iterative algorithms may appear in looped transformers applied to other eigenvector-related or fixed-point tasks.
- Layer normalization may be required for exact recovery of many linear iterative procedures inside attention layers.
- Extending the analysis to mildly nonlinear activations could test whether the power-method alignment survives outside the linear regime.
- If the bias holds, it suggests a route to train transformers to execute other classical algorithms simply by choosing an appropriate prediction target.
Load-bearing premise
Gradient descent on the principal component prediction loss landscape selects the power-method parameters among all other mechanisms that could achieve low loss.
What would settle it
After training, extract the learned self-attention weight matrix and check whether it equals the normalized covariance matrix required for exact power iteration; any deviation would show the model did not implement the power method.
Figures





read the original abstract
Transformers have achieved remarkable success across a wide range of applications, and a growing body of work suggests that part of their strength comes from their ability to learn and execute algorithmic procedures. However, our understanding of how transformers learn such algorithms remains limited, especially in the presence of layer normalization (LN). In this work, we study principal component prediction as a concrete testbed for understanding the training dynamics of transformers with LN. We prove that a looped linear transformer with LN, trained by gradient descent, converges to a solution that implements the power method, with each self-attention layer performing one power iteration. Notably, the model is trained only for principal component prediction, rather than being explicitly supervised to implement the power method. Our finding thus reveals an "algorithmic implicit bias" of looped transformers with LN: principal-component prediction can in principle be achieved by many mechanisms, yet gradient descent selects one that realizes the power method. We further provide a concrete comparison between transformers with and without LN: even with layerwise guidance from power iterations, a transformer without LN cannot exactly learn the power method, whereas the corresponding transformer with LN can, leading to a provable performance gap in principal component prediction. Our results provide, to our knowledge, the first theoretical analysis of the training dynamics of looped and single-layer transformers with LN, and shed light on the role of LN in transformer models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proves that a looped linear transformer with layer normalization, trained by gradient descent solely on a principal component prediction objective, converges to weights implementing the power method (one power iteration per self-attention layer). It further shows that the corresponding architecture without LN cannot exactly realize the power method even under layerwise guidance from power iterations, yielding a provable performance gap, and positions this as the first theoretical analysis of training dynamics for looped/single-layer transformers with LN.
Significance. If the central convergence and selection claims hold, the result supplies the first rigorous account of how LN interacts with gradient descent to produce an algorithmic implicit bias toward the power method in a concrete task. The explicit with/without-LN comparison and the fact that supervision is only on prediction (not on the algorithm itself) are notable strengths; the work also supplies machine-checkable elements in the form of a full derivation of the dynamics under the stated assumptions.
major comments (2)
- [Convergence theorem and implicit-bias argument (likely §4 and Theorem 3.1)] The load-bearing step is the claim that gradient descent selects the power-method solution among all zero-loss linear maps that solve principal-component prediction. The analysis must therefore characterize the full set of minimizers and show that only the power-method weights lie in the basin reached from the paper's initialization; if other mechanisms achieve identical loss but are not ruled out by the dynamics (e.g., via uniqueness of the attractor or explicit basin analysis), the "algorithmic implicit bias" conclusion does not follow. This point is not fully resolved by external GD tools alone.
- [Training-dynamics analysis and assumptions on initialization/data] The non-convex loss landscape, initialization assumptions, and data-distribution conditions that guarantee convergence to the power-method fixed point rather than to other critical points are stated at a high level; the derivation steps that close the argument from the gradient-flow ODE to the specific power-iteration weights need to be expanded so that each reduction is self-contained within the paper's definitions.
minor comments (2)
- [Model definition (§2)] Notation for the looped transformer and the precise placement of LN (pre- or post-attention) should be stated once in a single display equation rather than re-derived in multiple places.
- [Comparison section] A short table comparing the exact fixed-point equations with and without LN would make the performance-gap claim easier to verify at a glance.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive suggestions. The comments highlight opportunities to strengthen the implicit-bias argument and the self-contained presentation of the dynamics. We address each point below and will incorporate the requested expansions in the revised manuscript.
read point-by-point responses
-
Referee: [Convergence theorem and implicit-bias argument (likely §4 and Theorem 3.1)] The load-bearing step is the claim that gradient descent selects the power-method solution among all zero-loss linear maps that solve principal-component prediction. The analysis must therefore characterize the full set of minimizers and show that only the power-method weights lie in the basin reached from the paper's initialization; if other mechanisms achieve identical loss but are not ruled out by the dynamics (e.g., via uniqueness of the attractor or explicit basin analysis), the "algorithmic implicit bias" conclusion does not follow. This point is not fully resolved by external GD tools alone.
Authors: We agree that a rigorous implicit-bias claim requires an explicit characterization of the zero-loss set. In the revision we will add a new lemma (placed before Theorem 3.1) that fully describes all linear maps achieving zero loss on the principal-component prediction objective under the looped transformer parameterization. We then prove that the gradient-flow ODE, starting from the paper's random initialization, has a unique attractor at the power-method weights by constructing a strict Lyapunov function whose level sets exclude all other candidate minimizers. The basin analysis is carried out directly from the ODE rather than by appealing to generic GD results, thereby closing the argument within the manuscript's definitions. revision: yes
-
Referee: [Training-dynamics analysis and assumptions on initialization/data] The non-convex loss landscape, initialization assumptions, and data-distribution conditions that guarantee convergence to the power-method fixed point rather than to other critical points are stated at a high level; the derivation steps that close the argument from the gradient-flow ODE to the specific power-iteration weights need to be expanded so that each reduction is self-contained within the paper's definitions.
Authors: We will expand the training-dynamics section (currently §4) with a self-contained derivation that spells out every algebraic reduction from the gradient-flow ODE to the power-iteration fixed point. All initialization and data-distribution assumptions will be restated with explicit parameter ranges, and an appendix will supply the intermediate calculations that were previously summarized. These additions ensure the argument does not rely on external results beyond the definitions already introduced in the paper. revision: yes
Circularity Check
No circularity: convergence proof relies on external GD dynamics analysis
full rationale
The paper presents a mathematical convergence result showing that gradient descent on the principal-component prediction loss selects weights implementing the power method in a looped linear transformer with LN. No quoted step reduces a claimed prediction or uniqueness result to a fitted parameter, self-defined quantity, or load-bearing self-citation chain. The derivation is self-contained against external benchmarks for GD analysis and does not rename known results or smuggle ansatzes via citation. Minor self-citation (if present) is not load-bearing for the central claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient descent converges to the global solution that implements the power method in the considered loss landscape
Reference graph
Works this paper leans on
-
[1]
2013 , publisher =
Matrix computations , author =. 2013 , publisher =
2013
-
[2]
Del Corso, Gianna M. , journal =. Estimating an Eigenvector by the Power Method with a Random Start , year =. doi:10.1137/s0895479895296689 , publisher =
-
[3]
Representation theory: a first course , year =
Fulton, William and Harris, Joe , publisher =. Representation theory: a first course , year =
-
[4]
Pattern recognition and machine learning , year =
Bishop, Christopher M and Nasrabadi, Nasser M , publisher =. Pattern recognition and machine learning , year =
-
[5]
High-dimensional statistics: A non-asymptotic viewpoint , year =
Wainwright, Martin J , publisher =. High-dimensional statistics: A non-asymptotic viewpoint , year =
-
[6]
Detecting Hidden Communities by Power Iterations with Connections to Vanilla Spectral Algorithms , year =
Mukherjee, Chandra Sekhar and Zhang, Jiapeng , publisher =. Detecting Hidden Communities by Power Iterations with Connections to Vanilla Spectral Algorithms , year =. Proceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , pages =
2024
-
[7]
Finite sample guarantees for PCA in non-isotropic and data-dependent noise , year =
Vaswani, Namrata and Narayanamurthy, Praneeth , booktitle =. Finite sample guarantees for PCA in non-isotropic and data-dependent noise , year =
-
[8]
Nadler, Boaz , journal =. Finite sample approximation results for principal component analysis: A matrix perturbation approach , year =. doi:10.1214/08-aos618 , publisher =
-
[9]
Advances in neural information processing systems , title =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser,. Advances in neural information processing systems , title =. 2017 , volume =
2017
-
[10]
Transformers: State-of-the-Art Natural Language Processing , year =
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[11]
Dynamicvit: Efficient vision transformers with dynamic token sparsification , year =
Rao, Yongming and Zhao, Wenliang and Liu, Benlin and Lu, Jiwen and Zhou, Jie and Hsieh, Cho-Jui , journal =. Dynamicvit: Efficient vision transformers with dynamic token sparsification , year =
-
[12]
Llama: Open and efficient foundation language models , year =
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. Llama: Open and efficient foundation language models , year =. arXiv preprint , volume =
-
[13]
Vision transformers provably learn spatial structure , year =
Jelassi, Samy and Sander, Michael and Li, Yuanzhi , journal =. Vision transformers provably learn spatial structure , year =
-
[14]
Transformers as statisticians: Provable in-context learning with in-context algorithm selection , year =
Bai, Yu and Chen, Fan and Wang, Huan and Xiong, Caiming and Mei, Song , journal =. Transformers as statisticians: Provable in-context learning with in-context algorithm selection , year =
-
[15]
Larger language models do in-context learning differently , year =
Wei, Jerry and Wei, Jason and Tay, Yi and Tran, Dustin and Webson, Albert and Lu, Yifeng and Chen, Xinyun and Liu, Hanxiao and Huang, Da and Zhou, Denny and others , journal =. Larger language models do in-context learning differently , year =
-
[16]
arXiv preprint arXiv:2310.10616 , year=
How do transformers learn in-context beyond simple functions? a case study on learning with representations , author=. arXiv preprint arXiv:2310.10616 , year=
-
[17]
Trained transformers learn linear models in-context , year =
Zhang, Ruiqi and Frei, Spencer and Bartlett, Peter L , journal =. Trained transformers learn linear models in-context , year =
-
[18]
What can transformers learn in-context? a case study of simple function classes , year =
Garg, Shivam and Tsipras, Dimitris and Liang, Percy S and Valiant, Gregory , journal =. What can transformers learn in-context? a case study of simple function classes , year =
-
[19]
Proceedings of the 37th International Conference on Machine Learning , title =
Parisotto, Emilio and Song, Francis and Rae, Jack and Pascanu, Razvan and Gulcehre, Caglar and Jayakumar, Siddhant and Jaderberg, Max and Kaufman, Rapha. Proceedings of the 37th International Conference on Machine Learning , title =. 2020 , editor =
2020
-
[20]
Offline reinforcement learning as one big sequence modeling problem , year =
Janner, Michael and Li, Qiyang and Levine, Sergey , journal =. Offline reinforcement learning as one big sequence modeling problem , year =
-
[21]
Decision transformer: Reinforcement learning via sequence modeling , year =
Chen, Lili and Lu, Kevin and Rajeswaran, Aravind and Lee, Kimin and Grover, Aditya and Laskin, Misha and Abbeel, Pieter and Srinivas, Aravind and Mordatch, Igor , journal =. Decision transformer: Reinforcement learning via sequence modeling , year =
-
[22]
Learning spectral methods by transformers , year =
He, Yihan and Cao, Yuan and Chen, Hong-Yu and Wu, Dennis and Fan, Jianqing and Liu, Han , journal =. Learning spectral methods by transformers , year =
-
[23]
In-context Convergence of Transformers , year =
Huang, Yu and Cheng, Yuan and Liang, Yingbin , booktitle =. In-context Convergence of Transformers , year =
-
[24]
, booktitle =
Wang, Zixuan and Wei, Stanley and Hsu, Daniel and Lee, Jason D. , booktitle =. Transformers Provably Learn Sparse Token Selection While Fully-Connected Nets Cannot , year =
-
[25]
Scan and snap: Understanding training dynamics and token composition in 1-layer transformer , year =
Tian, Yuandong and Wang, Yiping and Chen, Beidi and Du, Simon S , journal =. Scan and snap: Understanding training dynamics and token composition in 1-layer transformer , year =
-
[26]
The Twelfth International Conference on Learning Representations , year=
JoMA: Demystifying Multilayer Transformers via Joint Dynamics of MLP and Attention , author=. The Twelfth International Conference on Learning Representations , year=
-
[27]
, booktitle =
Nichani, Eshaan and Damian, Alex and Lee, Jason D. , booktitle =. How Transformers Learn Causal Structure with Gradient Descent , year =
-
[28]
The symmetric eigenvalue problem , year =
Parlett, Beresford N , publisher =. The symmetric eigenvalue problem , year =
-
[29]
International Conference on Machine Learning , title =
Von Oswald, Johannes and Niklasson, Eyvind and Randazzo, Ettore and Sacramento, Jo. International Conference on Machine Learning , title =. 2023 , organization =
2023
-
[30]
arXiv preprint , title =
Aky. arXiv preprint , title =. 2024 , volume =
2024
-
[31]
Gemma: Open Models Based on Gemini Research and Technology
Team, Gemma and Mesnard, Thomas and Hardin, Cassidy and Dadashi, Robert and Bhupatiraju, Surya and Pathak, Shreya and Sifre, Laurent and Rivi. arXiv preprint arXiv:2403.08295 , title =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Root mean square layer normalization , year =
Zhang, Biao and Sennrich, Rico , journal =. Root mean square layer normalization , year =
-
[33]
Reddi and Stefanie Jegelka and Sanjiv Kumar , booktitle =
Khashayar Gatmiry and Nikunj Saunshi and Sashank J. Reddi and Stefanie Jegelka and Sanjiv Kumar , booktitle =. Can Looped Transformers Learn to Implement Multi-step Gradient Descent for In-context Learning? , year =
-
[34]
Transformers learn to implement preconditioned gradient descent for in-context learning , year =
Ahn, Kwangjun and Cheng, Xiang and Daneshmand, Hadi and Sra, Suvrit , journal =. Transformers learn to implement preconditioned gradient descent for in-context learning , year =
-
[35]
Linear attention is (maybe) all you need (to understand Transformer optimization) , year =
Kwangjun Ahn and Xiang Cheng and Minhak Song and Chulhee Yun and Ali Jadbabaie and Suvrit Sra , booktitle =. Linear attention is (maybe) all you need (to understand Transformer optimization) , year =
-
[36]
Team, Gemma and Kamath, Aishwarya and Ferret, Johan and Pathak, Shreya and Vieillard, Nino and Merhej, Ramona and Perrin, Sarah and Matejovicova, Tatiana and Ram. arXiv preprint arXiv:2503.19786 , title =
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
arXiv preprint , title =
Aky. arXiv preprint , title =. 2022 , volume =
2022
-
[38]
Training dynamics of in-context learning in linear attention , year =
Zhang, Yedi and Singh, Aaditya K and Latham, Peter E and Saxe, Andrew , journal =. Training dynamics of in-context learning in linear attention , year =
-
[39]
On the Role of Transformer Feed-Forward Layers in Nonlinear In-Context Learning , year =
Sun, Haoyuan and Jadbabaie, Ali and Azizan, Navid , journal =. On the Role of Transformer Feed-Forward Layers in Nonlinear In-Context Learning , year =
-
[40]
ICLR: In-Context Learning of Representations , year =
Park, Core Francisco and Lee, Andrew and Lubana, Ekdeep Singh and Yang, Yongyi and Okawa, Maya and Nishi, Kento and Wattenberg, Martin and Tanaka, Hidenori , booktitle =. ICLR: In-Context Learning of Representations , year =
-
[41]
Transformers Learn to Implement Multi-step Gradient Descent with Chain of Thought , year =
Huang, Jianhao and Wang, Zixuan and Lee, Jason , booktitle =. Transformers Learn to Implement Multi-step Gradient Descent with Chain of Thought , year =
-
[42]
Transformers Learn to Achieve Second-Order Convergence Rates for In-Context Linear Regression , year =
Deqing Fu and Tian-Qi Chen and Robin Jia and Vatsal Sharan , journal =. Transformers Learn to Achieve Second-Order Convergence Rates for In-Context Linear Regression , year =
-
[43]
Looped transformers as programmable computers , year =
Giannou, Angeliki and Rajput, Shashank and Sohn, Jy-yong and Lee, Kangwook and Lee, Jason D and Papailiopoulos, Dimitris , booktitle =. Looped transformers as programmable computers , year =
-
[44]
One-layer transformer provably learns one-nearest neighbor in context , year =
Li, Zihao and Cao, Yuan and Gao, Cheng and He, Yihan and Liu, Han and Klusowski, Jason and Fan, Jianqing and Wang, Mengdi , journal =. One-layer transformer provably learns one-nearest neighbor in context , year =
-
[45]
Photorealistic text-to-image diffusion models with deep language understanding , year =
Saharia, Chitwan and Chan, William and Saxena, Saurabh and Li, Lala and Whang, Jay and Denton, Emily L and Ghasemipour, Kamyar and Gontijo Lopes, Raphael and Karagol Ayan, Burcu and Salimans, Tim and others , journal =. Photorealistic text-to-image diffusion models with deep language understanding , year =
-
[46]
Bartoldson and Bhavya Kailkhura and Abhinav Bhatele and Tom Goldstein , booktitle =
Jonas Geiping and Sean Michael McLeish and Neel Jain and John Kirchenbauer and Siddharth Singh and Brian R. Bartoldson and Bhavya Kailkhura and Abhinav Bhatele and Tom Goldstein , booktitle =. Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach , year =
-
[47]
The evolution of statistical induction heads: In-context learning markov chains , year =
Edelman, Ezra and Tsilivis, Nikolaos and Edelman, Benjamin and Malach, Eran and Goel, Surbhi , journal =. The evolution of statistical induction heads: In-context learning markov chains , year =
-
[48]
Unveiling induction heads: Provable training dynamics and feature learning in transformers , year =
Chen, Siyu and Sheen, Heejune and Wang, Tianhao and Yang, Zhuoran , journal =. Unveiling induction heads: Provable training dynamics and feature learning in transformers , year =
-
[49]
Transformers Simulate MLE for Sequence Generation in Bayesian Networks , year =
Cao, Yuan and He, Yihan and Wu, Dennis and Chen, Hong-Yu and Fan, Jianqing and Liu, Han , journal =. Transformers Simulate MLE for Sequence Generation in Bayesian Networks , year =
-
[50]
Multi-head Transformers Provably Learn Symbolic Multi-step Reasoning via Gradient Descent , year =
Tong Yang and Yu Huang and Yingbin Liang and Yuejie Chi , booktitle =. Multi-head Transformers Provably Learn Symbolic Multi-step Reasoning via Gradient Descent , year =
-
[51]
How Transformers Learn Regular Language Recognition: A Theoretical Study on Training Dynamics and Implicit Bias , year =
Ruiquan Huang and Yingbin Liang and Jing Yang , booktitle =. How Transformers Learn Regular Language Recognition: A Theoretical Study on Training Dynamics and Implicit Bias , year =
-
[52]
An image is worth 16x16 words: Transformers for image recognition at scale , year =
Dosovitskiy, Alexey , journal =. An image is worth 16x16 words: Transformers for image recognition at scale , year =
-
[53]
arXiv preprint arXiv:2410.04870 , year=
On the optimization and generalization of two-layer transformers with sign gradient descent , author=. arXiv preprint arXiv:2410.04870 , year=
-
[54]
The Eleventh International Conference on Learning Representations , year=
Noise Is Not the Main Factor Behind the Gap Between Sgd and Adam on Transformers, But Sign Descent Might Be , author=. The Eleventh International Conference on Learning Representations , year=
-
[55]
arXiv preprint arXiv:2306.00204 , year=
Toward understanding why adam converges faster than sgd for transformers , author=. arXiv preprint arXiv:2306.00204 , year=
-
[56]
Advances in Neural Information Processing Systems , volume=
Why are adaptive methods good for attention models? , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
International Conference on Machine Learning , pages=
How do transformers learn topic structure: Towards a mechanistic understanding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[58]
NeurIPS 2023 Workshop on Mathematics of Modern Machine Learning , year=
Transformers as Support Vector Machines , author=. NeurIPS 2023 Workshop on Mathematics of Modern Machine Learning , year=
2023
-
[59]
Advances in Neural Information Processing Systems , volume=
Max-margin token selection in attention mechanism , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Advances in Neural Information Processing Systems , volume=
Global convergence in training large-scale transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
arXiv preprint arXiv:2402.14951 , year=
In-context learning of a linear Transformer block: benefits of the MLP component and one-step GD initialization , author=. arXiv preprint arXiv:2402.14951 , year=
-
[62]
ICML 2024 Workshop on Theoretical Foundations of Foundation Models , year=
How Transformers Utilize Multi-Head Attention in In-Context Learning? A Case Study on Sparse Linear Regression , author=. ICML 2024 Workshop on Theoretical Foundations of Foundation Models , year=
2024
-
[63]
The Thirty Seventh Annual Conference on Learning Theory , pages=
Training Dynamics of Multi-Head Softmax Attention for In-Context Learning: Emergence, Convergence, and Optimality , author=. The Thirty Seventh Annual Conference on Learning Theory , pages=. 2024 , organization=
2024
-
[64]
International Conference on Machine Learning , pages=
Unraveling attention via convex duality: Analysis and interpretations of vision transformers , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[65]
Advances in Neural Information Processing Systems , volume=
Representational strengths and limitations of transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[66]
International Conference on Learning Representations , year=
Universal Transformers , author=. International Conference on Learning Representations , year=
-
[67]
International Conference on Learning Representations , year =
Are Transformers universal approximators of sequence-to-sequence functions? , author=. International Conference on Learning Representations , year =
-
[68]
Advances in Neural Information Processing Systems , volume=
Statistically meaningful approximation: a case study on approximating turing machines with transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
arXiv preprint arXiv:2106.03764 , year=
On the expressive power of self-attention matrices , author=. arXiv preprint arXiv:2106.03764 , year=
-
[70]
Journal of Machine Learning Research , volume=
Attention is turing-complete , author=. Journal of Machine Learning Research , volume=
-
[71]
arXiv preprint arXiv:2211.12316 , year=
Simplicity bias in transformers and their ability to learn sparse boolean functions , author=. arXiv preprint arXiv:2211.12316 , year=
-
[72]
arXiv preprint arXiv:2009.11264 , year=
On the ability and limitations of transformers to recognize formal languages , author=. arXiv preprint arXiv:2009.11264 , year=
-
[73]
The Eleventh International Conference on Learning Representations , year=
Transformers Learn Shortcuts to Automata , author=. The Eleventh International Conference on Learning Representations , year=
-
[74]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
A Survey on In-context Learning
A survey on in-context learning , author=. arXiv preprint arXiv:2301.00234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.