Demystifying the Optimal Fair Classifier in Multi-Class Classification
Pith reviewed 2026-06-28 18:47 UTC · model grok-4.3
The pith
An analytically tractable probabilistic formulation identifies the optimal fair classifier for multi-class tasks and yields two algorithms that reach the accuracy-fairness Pareto frontier.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An analytically tractable probabilistic formulation of the optimal classifier under fairness constraints exists in multi-class settings. Two attribute-blind algorithms—an in-processing reduction approach and a post-processing plug-in approach—both converge to the optimal accuracy-fairness Pareto frontier.
What carries the argument
The analytically tractable probabilistic formulation of the optimal classifier under fairness constraints, which serves as the basis for deriving algorithms that attain the Pareto frontier.
If this is right
- The in-processing reduction approach enforces fairness requirements during model training.
- The post-processing plug-in estimation approach fine-tunes output probabilities after training.
- Both algorithms remain attribute-blind, so sensitive attributes are not required at inference time.
- The methods extend fairness guarantees from binary to multi-class settings while preserving the optimal trade-off.
Where Pith is reading between the lines
- The separation between the theoretical formulation and the two practical algorithms allows flexibility in choosing when to apply fairness intervention.
- The convergence guarantees provide a benchmark that future multi-class fairness methods can be measured against.
- The formulation may serve as a starting point for analyzing fairness in other structured prediction tasks with multiple discrete outputs.
Load-bearing premise
An analytically tractable probabilistic formulation of the optimal classifier under fairness constraints exists and can be used to derive practical algorithms.
What would settle it
On a synthetic multi-class dataset with known class-conditional distributions, compute the true optimal accuracy-fairness frontier by exhaustive search and verify whether the proposed in-processing and post-processing algorithms match it.
Figures

read the original abstract
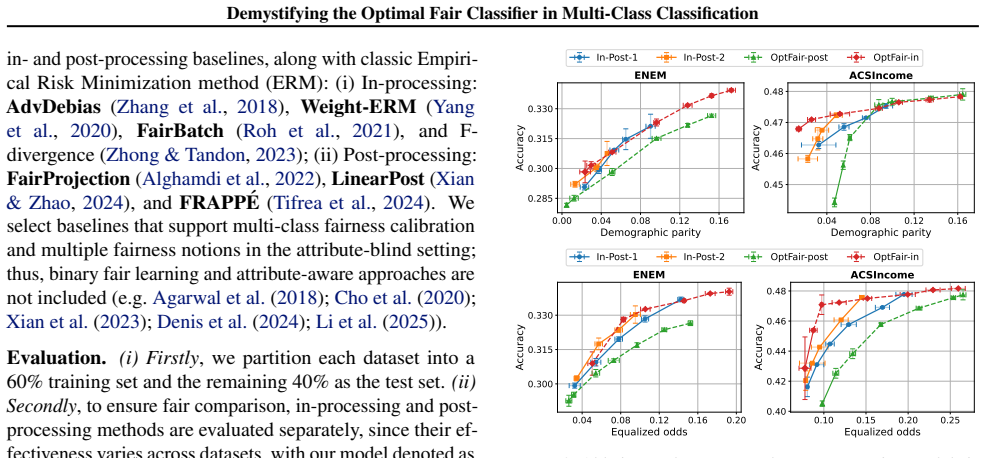
Ensuring fair and equitable treatment across diverse groups, particularly in multi-class classification tasks, poses a significant challenge due to the persistent biases inherent in machine learning models. Most existing bias mitigation techniques are tailored to binary settings, and the presence of multi-dimensional outputs and complex fairness mechanisms makes their extension to multi-class scenarios neither straightforward nor effective. In this paper, we investigate two fundamental, unresolved challenges in fair classification: (i) characterizing the optimal accuracy-fairness frontier in multi-class settings, and (ii) designing practical algorithms that attain this optimum in different training phases. To tackle these challenges, we first specify an analytically tractable probabilistic formulation of the optimal classifier under fairness constraints. Building upon this, we propose two attribute-blind algorithms to enforce fairness requirements in practice: an in-processing approach for fairness intervention during training via the reduction approach, and a post-processing approach for fine-tuning output probabilities with plug-in estimation. Theoretical analysis reveals that both methods converge to the optimal accuracy-fairness Pareto frontier. Experiments conducted on multiple datasets demonstrate the superior performance of our methods in balancing accuracy and fairness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to resolve two challenges in multi-class fair classification by first providing an analytically tractable probabilistic formulation of the optimal classifier under fairness constraints, then deriving two attribute-blind algorithms (a reduction-based in-processing method and a plug-in post-processing method) whose theoretical analysis shows convergence to the optimal accuracy-fairness Pareto frontier, with empirical superiority demonstrated on multiple datasets.
Significance. If the central formulation is both optimal and tractable for general multi-class settings without restrictive assumptions on the fairness metric or class cardinality, the work would advance the field by extending beyond binary classification and supplying explicit convergence guarantees for practical algorithms in different training phases.
major comments (2)
- [Formulation section (post-introduction)] The probabilistic formulation of the optimal classifier (introduced immediately after the problem statement and used to derive both algorithms): the manuscript does not provide an explicit derivation or convexity argument showing that the multi-class fairness-constrained optimization remains analytically tractable for arbitrary fairness metrics and K>2 classes; without this, the subsequent convergence claims for the reduction and plug-in methods do not follow for the general setting advertised.
- [Theoretical analysis] Theoretical analysis section (claims of convergence to the Pareto frontier): the proofs rely on the tractability of the formulation in the preceding section; if that formulation requires convex relaxations or specific metric assumptions that do not preserve exact optimality, the convergence guarantees are limited to the relaxed case rather than the exact multi-class optimum.
minor comments (2)
- [Experiments] Dataset details and experimental controls (e.g., number of classes, sensitive attribute dimensionality, exact fairness metrics used) are referenced only at a high level in the experiments; adding a table with these parameters would improve reproducibility.
- [Notation and preliminaries] Notation for the multi-class output probabilities and fairness constraints could be clarified with an explicit table comparing the new formulation to prior binary reductions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Formulation section (post-introduction)] The probabilistic formulation of the optimal classifier (introduced immediately after the problem statement and used to derive both algorithms): the manuscript does not provide an explicit derivation or convexity argument showing that the multi-class fairness-constrained optimization remains analytically tractable for arbitrary fairness metrics and K>2 classes; without this, the subsequent convergence claims for the reduction and plug-in methods do not follow for the general setting advertised.
Authors: We agree that the current presentation would benefit from greater explicitness. In the revised manuscript we will add a dedicated subsection immediately following the problem statement that provides a step-by-step derivation of the probabilistic formulation, including the convexity argument that establishes analytical tractability for arbitrary fairness metrics and any K>2 without additional assumptions on the metric or class cardinality. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis section (claims of convergence to the Pareto frontier): the proofs rely on the tractability of the formulation in the preceding section; if that formulation requires convex relaxations or specific metric assumptions that do not preserve exact optimality, the convergence guarantees are limited to the relaxed case rather than the exact multi-class optimum.
Authors: The proofs are constructed directly from the exact (non-relaxed) probabilistic formulation. To make this dependence transparent, the revised theoretical analysis section will explicitly restate that no convex relaxations are introduced and will include a short lemma confirming that the optimality and convergence results hold for the general multi-class setting once the derivation in the formulation section is supplied. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper first specifies an analytically tractable probabilistic formulation of the optimal classifier under fairness constraints, then builds two algorithms (reduction-based in-processing and plug-in post-processing) whose convergence to the resulting Pareto frontier is asserted via theoretical analysis. No step reduces a claimed prediction or first-principles result to a fitted parameter, self-citation, or definitional tautology; the formulation is presented as an independent characterization rather than derived from the algorithms themselves. The provided abstract and context contain no load-bearing self-citations or renamings that would trigger the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fairness constraints admit an analytically tractable probabilistic formulation of the optimal classifier
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
2018 , isbn =
Nesterov, Yurii , title =. 2018 , isbn =
2018
-
[5]
Journal of Physics A: Mathematical and Theoretical , volume=
A sharp continuity estimate for the von Neumann entropy , author=. Journal of Physics A: Mathematical and Theoretical , volume=. 2007 , publisher=
2007
-
[6]
Alquier, Pierre , title =. 2024 , issue_date =. doi:10.1561/2200000100 , journal =
-
[7]
, author=
On the Consistency of Multiclass Classification Methods. , author=. Journal of Machine Learning Research , volume=
-
[8]
Advances in neural information processing systems , volume=
Multi-class svms: From tighter data-dependent generalization bounds to novel algorithms , author=. Advances in neural information processing systems , volume=
-
[9]
International Conference on Algorithmic Learning Theory , pages=
A vector-contraction inequality for rademacher complexities , author=. International Conference on Algorithmic Learning Theory , pages=. 2016 , organization=
2016
-
[10]
Stich and Sai Praneeth Karimireddy , title =
Sebastian U. Stich and Sai Praneeth Karimireddy , title =. Journal of Machine Learning Research , year =
-
[11]
Journal of multivariate Analysis , volume=
Estimation of the precision matrix of a singular Wishart distribution and its application in high-dimensional data , author=. Journal of multivariate Analysis , volume=. 2008 , publisher=
2008
-
[12]
Stochastic Optimization for Large-scale Optimal Transport , volume =
Genevay, Aude and Cuturi, Marco and Peyr\'. Stochastic Optimization for Large-scale Optimal Transport , volume =. Advances in Neural Information Processing Systems , editor =
-
[13]
Advances in neural information processing systems , volume=
The limit points of (optimistic) gradient descent in min-max optimization , author=. Advances in neural information processing systems , volume=
-
[14]
International workshop on computer science logic , pages=
On Nash equilibria in stochastic games , author=. International workshop on computer science logic , pages=. 2004 , organization=
2004
-
[15]
Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2 , pages =
Cuturi, Marco , title =. Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2 , pages =. 2013 , publisher =
2013
-
[16]
Advances in neural information processing systems , volume=
Ensemble distillation for robust model fusion in federated learning , author=. Advances in neural information processing systems , volume=
-
[17]
Advances in Neural Information Processing Systems , volume=
Dense: Data-free one-shot federated learning , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
arXiv preprint arXiv:2402.15070 , year=
Enhancing one-shot federated learning through data and ensemble co-boosting , author=. arXiv preprint arXiv:2402.15070 , year=
-
[19]
The Eleventh International Conference on Learning Representations , year=
Towards addressing label skews in one-shot federated learning , author=. The Eleventh International Conference on Learning Representations , year=
-
[20]
arXiv preprint arXiv:2006.05148 , year=
Xor mixup: Privacy-preserving data augmentation for one-shot federated learning , author=. arXiv preprint arXiv:2006.05148 , year=
-
[21]
arXiv preprint arXiv:2010.01017 , year=
Practical one-shot federated learning for cross-silo setting , author=. arXiv preprint arXiv:2010.01017 , year=
-
[22]
Denoising Diffusion Probabilistic Models , volume =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , booktitle =. Denoising Diffusion Probabilistic Models , volume =
-
[23]
2019 , eprint=
One-Shot Federated Learning , author=. 2019 , eprint=
2019
-
[24]
FedPrompt: Communication-Efficient and Privacy-Preserving Prompt Tuning in Federated Learning , year=
Zhao, Haodong and Du, Wei and Li, Fangqi and Li, Peixuan and Liu, Gongshen , booktitle=. FedPrompt: Communication-Efficient and Privacy-Preserving Prompt Tuning in Federated Learning , year=
-
[25]
and Golden, Donald G
McCracken, Daniel D. and Golden, Donald G. , title =. 1990 , isbn =
1990
-
[26]
The analysis of linear partial differential operators
H. The analysis of linear partial differential operators. 1985 , PAGES =
1985
-
[27]
IEEE", address =
A. Adya and P. Bahl and J. Padhye and A.Wolman and L. Zhou , title =. Proceedings of the IEEE 1st International Conference on Broadnets Networks (BroadNets'04) , publisher = "IEEE", address = "Los Alamitos, CA", year =
-
[28]
I. F. Akyildiz and W. Su and Y. Sankarasubramaniam and E. Cayirci , title =. Comm. ACM , volume = 38, number = "4", year =
-
[29]
I. F. Akyildiz and T. Melodia and K. R. Chowdhury , title =. Computer Netw. , volume = 51, number = "4", year =
-
[30]
ACM", address =
P. Bahl and R. Chancre and J. Dungeon , title =. Proceeding of the 10th International Conference on Mobile Computing and Networking (MobiCom'04) , publisher = "ACM", address = "New York, NY", year =
-
[31]
8 (Special Issue on Sensor Networks)
D. Culler and D. Estrin and M. Srivastava , title =. IEEE Comput. , volume = 37, number = "8 (Special Issue on Sensor Networks)", publisher = "IEEE", address = "Los Alamitos, CA", year =
-
[32]
Natarajan and M
A. Natarajan and M. Motani and B. de Silva and K. Yap and K. C. Chua , title =. Network Architectures , editor =. 960935712
-
[33]
Tzamaloukas and J
A. Tzamaloukas and J. J. Garcia-Luna-Aceves , title =
-
[34]
Zhou and J
G. Zhou and J. Lu and C.-Y. Wan and M. D. Yarvis and J. A. Stankovic , title =
-
[35]
Mapping Powerlists onto Hypercubes
Jacob Kornerup. Mapping Powerlists onto Hypercubes. 1994
1994
-
[36]
Automatic Parallelization for Distributed-Memory Multiprocessing Systems
Michael Gerndt. Automatic Parallelization for Distributed-Memory Multiprocessing Systems
-
[37]
J. E. Archer, Jr. and R. Conway and F. B. Schneider. User recovery and reversal in interactive systems. ACM Trans. Program. Lang. Syst
-
[38]
D. D. Dunlop and V. R. Basili. Generalizing specifications for uniformly implemented loops. ACM Trans. Program. Lang. Syst
-
[39]
Heering and P
J. Heering and P. Klint. Towards monolingual programming environments. ACM Trans. Program. Lang. Syst
-
[40]
Donald E. Knuth. The book
-
[41]
Korach and D
E. Korach and D. Rotem and N. Santoro. Distributed algorithms for finding centers and medians in networks. ACM Trans. Program. Lang. Syst
-
[42]
: A Document Preparation System
Leslie Lamport. : A Document Preparation System
-
[43]
F. Nielson. Program transformations in a denotational setting. ACM Trans. Program. Lang. Syst
-
[44]
Donald E. Knuth. Seminumerical Algorithms. 1981
1981
-
[45]
Brian K. Reid. A high-level approach to computer document formatting. Proceedings of the 7th Annual Symposium on Principles of Programming Languages
-
[46]
Zhou, Gang and Wu, Yafeng and Yan, Ting and He, Tian and Huang, Chengdu and Stankovic, John A. and Abdelzaher, Tarek F. , title =. ACM Trans. Embed. Comput. Syst. , issue_date =. doi:10.1145/1721695.1721705 , acmid = 1721705, publisher =
-
[47]
Institutional members of the Users Group
-
[48]
Boris Veytsman , title =
-
[49]
Robin Schneider , title =
-
[50]
and Peterson, Larry L
Bowman, Mic and Debray, Saumya K. and Peterson, Larry L. , title =. ACM Trans. Program. Lang. Syst. , volume =. 1993 , doi =
1993
-
[51]
TUGboat , volume =
Braams, Johannes , title =. TUGboat , volume =
-
[52]
Post Congress Tristesse
Malcolm Clark. Post Congress Tristesse. TeX90 Conference Proceedings
-
[53]
ACM Trans
Herlihy, Maurice , title =. ACM Trans. Program. Lang. Syst. , volume =. 1993 , doi =
1993
-
[54]
Salas and Einar Hille
S.L. Salas and Einar Hille. Calculus: One and Several Variable. 1978
1978
-
[55]
Publication quality tables in
Simon Fear , month =. Publication quality tables in
-
[56]
Using the amsthm Package , organization =
-
[57]
R: A Language and Environment for Statistical Computing , author =
-
[58]
Sam Anzaroot and Andrew McCallum , title =
-
[59]
Brad and Haunschild, Robin , title =
Bornmann, Lutz and Wray, K. Brad and Haunschild, Robin , title =
-
[60]
2014 , archivePrefix =
Sam Anzaroot and Alexandre Passos and David Belanger and Andrew McCallum , title =. 2014 , archivePrefix =
2014
-
[61]
Proceedings of the 20th International Colloquium on Automata, Languages and Programming , series =
Maintaining Discrete Probability Distributions Optimally , author =. Proceedings of the 20th International Colloquium on Automata, Languages and Programming , series =. 1993 , publisher =
1993
-
[62]
Han, Zhongxuan and Chen, Chaochao and Zheng, Xiaolin and Zhang, Li and Li, Yuyuan , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2024 , isbn =. doi:10.1145/3626772.3657737 , abstract =
-
[63]
Proceedings of the 3rd innovations in theoretical computer science conference , pages=
Fairness through awareness , author=. Proceedings of the 3rd innovations in theoretical computer science conference , pages=
-
[64]
International Conference on Learning Representations , year=
FairBatch: Batch Selection for Model Fairness , author=. International Conference on Learning Representations , year=
-
[65]
Why Is My Classifier Discriminatory? , volume =
Chen, Irene and Johansson, Fredrik D and Sontag, David , booktitle =. Why Is My Classifier Discriminatory? , volume =
-
[66]
The Twelfth International Conference on Learning Representations , year=
Post-hoc bias scoring is optimal for fair classification , author=. The Twelfth International Conference on Learning Representations , year=
-
[67]
Proceedings of the AAAI conference on artificial intelligence , volume=
Fairfed: Enabling group fairness in federated learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[68]
The Twelfth International Conference on Learning Representations , year=
Demystifying Local & Global Fairness Trade-offs in Federated Learning Using Partial Information Decomposition , author=. The Twelfth International Conference on Learning Representations , year=
-
[69]
International conference on machine learning , pages=
Agnostic federated learning , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[70]
International Conference on Machine Learning , pages=
Fare: Provably fair representation learning with practical certificates , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[71]
Advances in Neural Information Processing Systems , volume=
Fedlpa: One-shot federated learning with layer-wise posterior aggregation , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
Sensors , volume=
Federated learning in edge computing: a systematic survey , author=. Sensors , volume=. 2022 , publisher=
2022
-
[73]
Proceedings of machine learning and systems , volume=
Towards federated learning at scale: System design , author=. Proceedings of machine learning and systems , volume=
-
[74]
Advances in Neural Information Processing Systems , volume=
Fusefl: One-shot federated learning through the lens of causality with progressive model fusion , author=. Advances in Neural Information Processing Systems , volume=
-
[75]
arXiv preprint arXiv:2412.05186 , year=
One-shot federated learning via synthetic distiller-distillate communication , author=. arXiv preprint arXiv:2412.05186 , year=
-
[76]
Foundations and Trends
The algorithmic foundations of differential privacy , author=. Foundations and Trends. 2014 , publisher=
2014
-
[77]
IEEE access , volume=
Differential privacy for deep and federated learning: A survey , author=. IEEE access , volume=. 2022 , publisher=
2022
-
[78]
Alexandru Tifrea and Preethi Lahoti and Ben Packer and Yoni Halpern and Ahmad Beirami and Flavien Prost , booktitle=
-
[79]
Learning Fair Classifiers via Min-Max F-divergence Regularization , year=
Zhong, Meiyu and Tandon, Ravi , booktitle=. Learning Fair Classifiers via Min-Max F-divergence Regularization , year=
-
[80]
Advances in Neural Information Processing Systems , volume=
On Optimal Steering to Achieve Exact Fairness , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.