SHARP: Sleep-based Hierarchical Accelerated Replay for Long Range Non-Stationary Temporal Pattern Recognition
Pith reviewed 2026-06-28 18:41 UTC · model grok-4.3
The pith
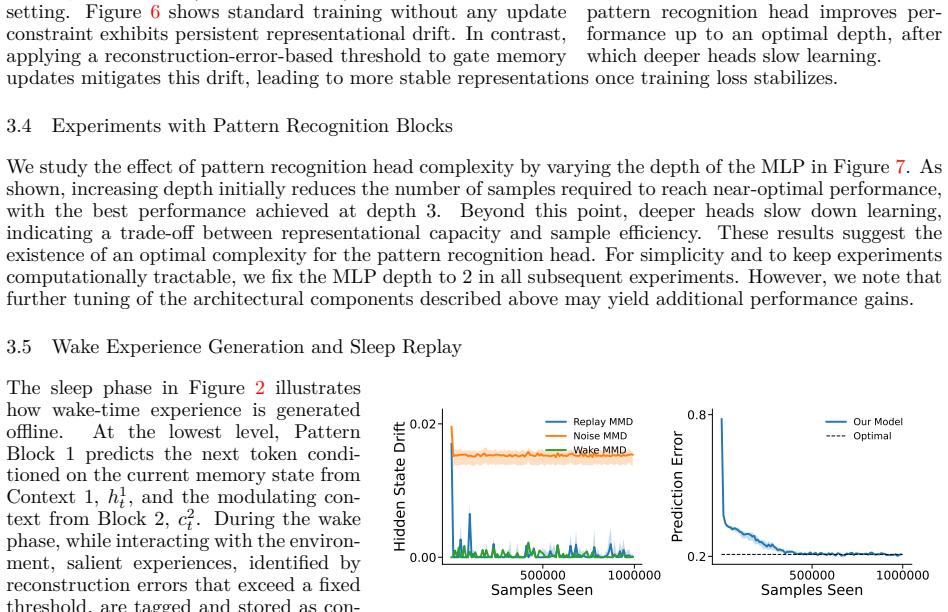
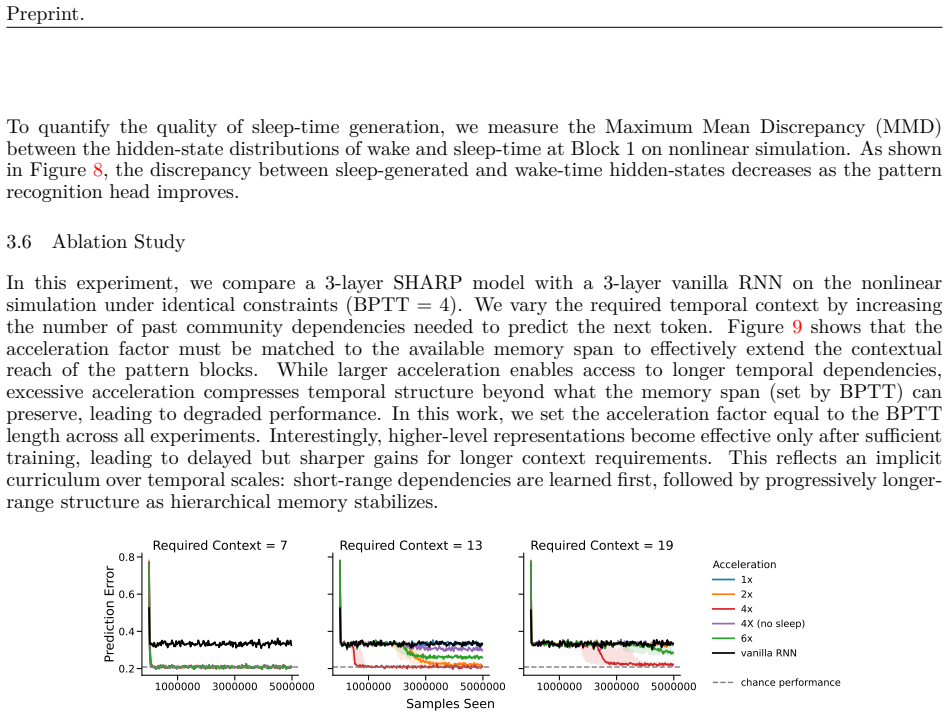
SHARP pairs a memory module with offline accelerated replay to let sequence models retain long-range context in streaming non-stationary data without long backpropagation through time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
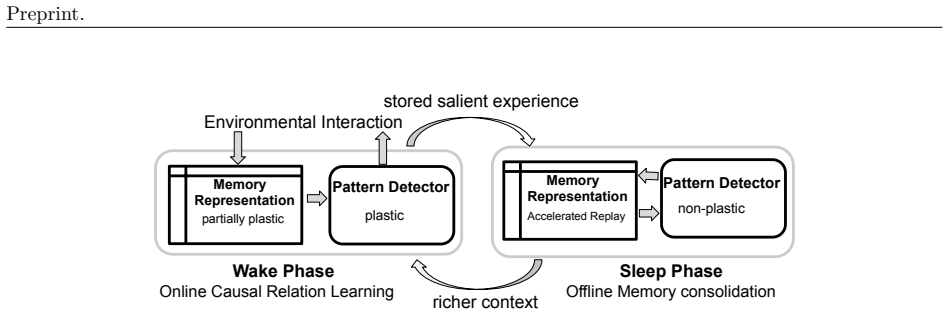
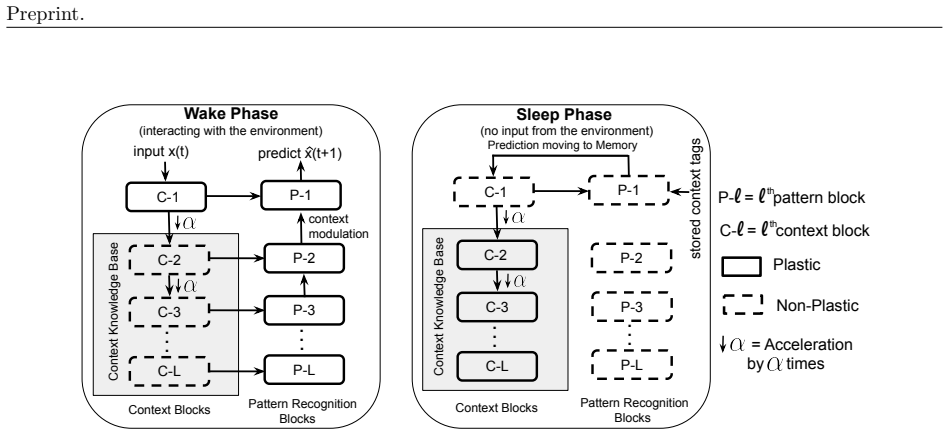
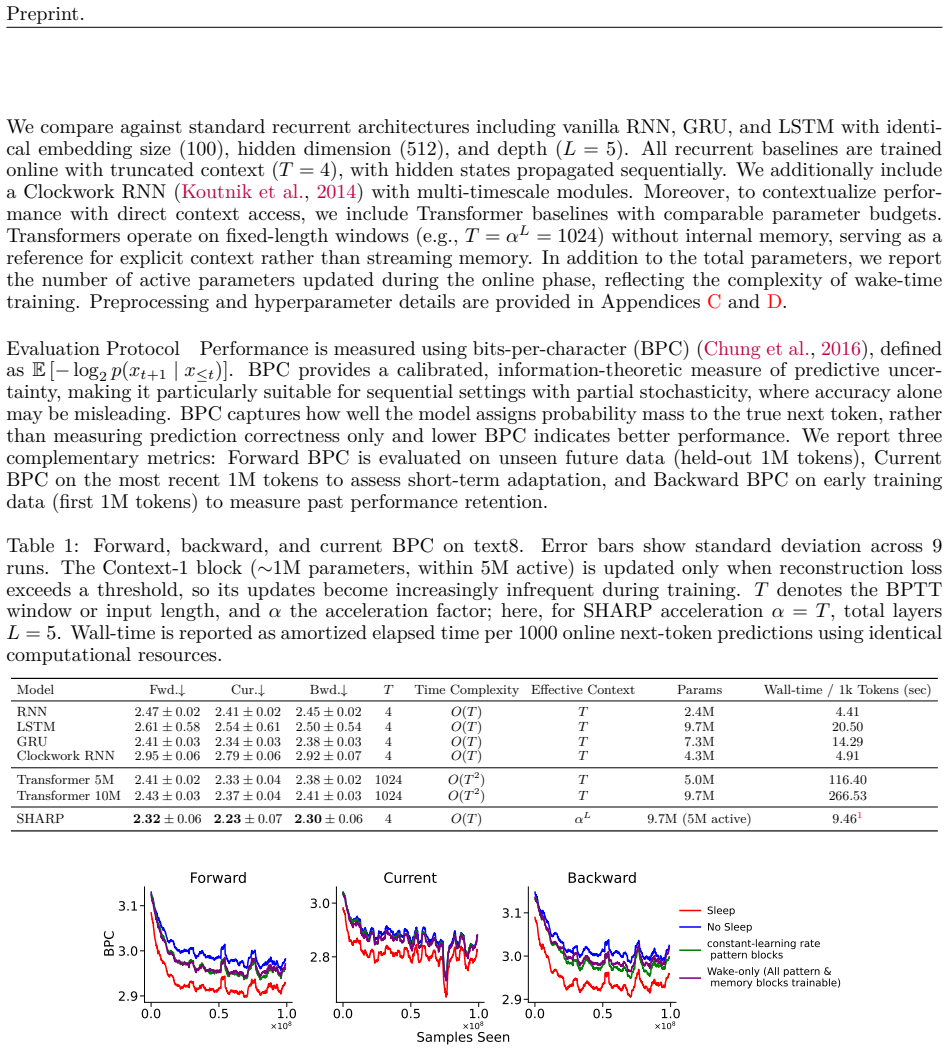
SHARP improves over recurrent baselines by retaining next-token predictive performance on previously seen data while continuing to learn from the current stream and generalizing to future unseen data. These gains are enabled by its hierarchical structure, which yields an exponentially increasing effective temporal context with only linear-time computational cost.
What carries the argument
The separation of a memory module that accumulates structured history from a pattern-recognition module that operates over it, together with accelerated offline replay of memory traces to form higher-level representations.
If this is right
- Next-token prediction accuracy is retained on data seen earlier in the stream.
- Learning continues on the current data stream without revisiting past observations.
- Generalization to future unseen data improves relative to standard recurrent baselines.
- Effective temporal context grows exponentially while compute cost remains linear.
Where Pith is reading between the lines
- The same separation could be tested in reinforcement-learning agents that must adapt policies to changing environments without replaying full trajectories.
- If the memory module can be made differentiable in limited ways, the framework might reduce the need for attention mechanisms in very long sequences.
- The offline replay schedule offers a concrete way to trade compute budget for context length that could be measured against fixed-horizon BPTT.
Load-bearing premise
The separation into a memory module that accumulates structured history and a pattern-recognition module that operates over it enables resource-efficient adaptation to non-stationary dynamics by eliminating the need for backpropagation through time across many steps.
What would settle it
A controlled experiment on text8 or PG-19 in which SHARP fails to retain next-token accuracy on earlier data segments while processing later segments would falsify the central performance claim.
Figures





read the original abstract
Learning long-range non-stationary temporal patterns remains a core challenge for modern sequence models, particularly in strict streaming settings. In these settings, data arrive sequentially and must be processed in a single pass without simultaneously revisiting past observations. Standard architectures, including recurrent neural networks and transformers, are constrained by either truncated backpropagation through time horizon or explicit input window length for long range credit assignment. To address these limitations, we propose SHARP (Sleep-based Hierarchical Accelerated Replay), a framework that decomposes temporal learning into two complementary components: a memory module that accumulates a structured history of past inputs, and a pattern-recognition module that operates over this memory. This separation enables resource- and compute-efficient adaptation to non-stationary dynamics by eliminating the need for backpropagation through time across many steps for long-range credit assignment. Inspired by the accelerated replay observed in rodents during slow-wave sleep, SHARP incorporates offline (sleep) phases in which temporally structured memory traces are replayed in an accelerated form and integrated into higher-level memory representations, improving long-range context retention. Through controlled simulations and ablation studies, we characterize the key properties of the proposed framework. In benchmark datasets such as text8 and PG-19, we demonstrate that SHARP improves over recurrent baselines by retaining next-token predictive performance on previously seen data while continuing to learn from the current stream and generalizing to future unseen data. These gains are enabled by its hierarchical structure, which yields an exponentially increasing effective temporal context with only linear-time computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SHARP, a framework that decomposes sequence learning into a memory module accumulating structured history and a pattern-recognition module operating over it. Inspired by accelerated replay during rodent slow-wave sleep, it introduces offline phases that replay temporally structured traces in accelerated form to build higher-level representations. The approach is claimed to enable long-range credit assignment in strict single-pass streaming settings without truncated BPTT or fixed input windows, yielding exponentially growing effective temporal context at linear computational cost. On text8 and PG-19, SHARP is asserted to outperform recurrent baselines by retaining next-token predictive performance on past data while continuing to learn from the current stream and generalizing to future data.
Significance. If the empirical gains, ablation results, and complexity claims hold under rigorous streaming protocols, the work could provide a practical alternative to standard recurrent and transformer architectures for non-stationary long-range sequence modeling. The separation of memory accumulation from pattern recognition and the use of offline replay phases are conceptually interesting, but the absence of any quantitative results, error bars, or experimental details in the supplied material prevents assessment of whether these advantages are realized.
major comments (3)
- [Abstract] Abstract: The central empirical claim states that SHARP 'improves over recurrent baselines' on text8 and PG-19 by retaining past performance while learning new data and generalizing. No numerical results, standard deviations, ablation tables, or experimental protocol (e.g., streaming constraints, evaluation splits, or baseline implementations) are supplied, rendering the claim unverifiable from the manuscript.
- [Abstract] Abstract: The statement that the hierarchical structure 'yields an exponentially increasing effective temporal context with only linear-time computational cost' is presented without supporting derivation, complexity analysis, or pseudocode. This load-bearing claim for the framework's efficiency cannot be evaluated.
- [Abstract] Abstract: The description of the memory and pattern-recognition modules and the 'sleep' replay mechanism remains at the level of components and biological inspiration; no equations, formal definitions of the replay process, or integration rules are provided, preventing assessment of internal consistency or correctness.
minor comments (1)
- [Abstract] The abstract refers to 'controlled simulations and ablation studies' but supplies none of the corresponding results or figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We will revise the manuscript to supply the missing quantitative results, complexity analysis, and formal definitions so that all claims are verifiable.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim states that SHARP 'improves over recurrent baselines' on text8 and PG-19 by retaining past performance while learning new data and generalizing. No numerical results, standard deviations, ablation tables, or experimental protocol (e.g., streaming constraints, evaluation splits, or baseline implementations) are supplied, rendering the claim unverifiable from the manuscript.
Authors: We agree the abstract alone does not contain numbers. The full manuscript reports concrete next-token prediction results on text8 and PG-19, including comparisons to recurrent baselines, standard deviations, ablation tables, and the exact streaming protocol with evaluation splits. In revision we will insert key quantitative findings into the abstract and ensure the experimental section explicitly documents all protocol details. revision: yes
-
Referee: [Abstract] Abstract: The statement that the hierarchical structure 'yields an exponentially increasing effective temporal context with only linear-time computational cost' is presented without supporting derivation, complexity analysis, or pseudocode. This load-bearing claim for the framework's efficiency cannot be evaluated.
Authors: The manuscript contains a complexity analysis establishing the exponential context growth at linear cost via the hierarchical replay structure. We will add a dedicated subsection with the formal derivation, big-O bounds, and pseudocode for the accelerated replay process in the revised version. revision: yes
-
Referee: [Abstract] Abstract: The description of the memory and pattern-recognition modules and the 'sleep' replay mechanism remains at the level of components and biological inspiration; no equations, formal definitions of the replay process, or integration rules are provided, preventing assessment of internal consistency or correctness.
Authors: The full manuscript supplies equations for the memory accumulation, pattern-recognition module, and the replay integration rules. We will revise to place these formal definitions and integration rules in a prominent early section so that internal consistency can be directly assessed. revision: yes
Circularity Check
No significant circularity; framework is descriptive with no derivation chain
full rationale
The provided manuscript text consists of an abstract and high-level architectural description with no equations, formal derivations, parameter-fitting procedures, or self-citation chains that could reduce claims to inputs by construction. Claims about module separation enabling efficient adaptation and replay improving retention are presented as design choices and empirical observations rather than mathematical predictions derived from prior results within the paper. No instances of self-definitional structures, fitted inputs renamed as predictions, or load-bearing self-citations appear. The derivation chain is therefore self-contained at the level of component description and does not exhibit circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Efficient Lifelong Learning with A-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-gem. arXiv preprint arXiv:1812.00420,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
On Tiny Episodic Memories in Continual Learning
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajanthan, Puneet K Dokania, Philip HS Torr, and Marc’Aurelio Ranzato. On tiny episodic memories in continual learning. arXiv preprint arXiv:1902.10486,
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[3]
Hierarchical Multiscale Recurrent Neural Networks
Junyoung Chung, Sungjin Ahn, and Yoshua Bengio. Hierarchical multiscale recurrent neural networks. arXiv preprint arXiv:1609.01704,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Position: Modular Memory is the Key to Continual Learning Agents
Vaggelis Dorovatas, Malte Schwerin, Andrew D Bagdanov, Lucas Caccia, Antonio Carta, Laurent Charlin, Barbara Hammer, Tyler L Hayes, Timm Hess, Christopher Kanan, et al. Modular memory is the key to continual learning agents. arXiv preprint arXiv:2603.01761,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Itamar Lerner and Mark A Gluck
doi: 10.1002/9781119159193.ch18. Itamar Lerner and Mark A Gluck. Sleep and the extraction of hidden regularities: a systematic review and the importance of temporal rules. Sleep Medicine Reviews, 47:39–50,
-
[8]
Compressive Transformers for Long-Range Sequence Modelling
Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap. Compressive transformers for long-range sequence modelling. arXiv preprint arXiv:1911.05507,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[9]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 2001–2010,
2001
-
[10]
The curse of depth in large language models
Wenfang Sun, Xinyuan Song, Pengxiang Li, Lu Yin, Yefeng Zheng, and Shiwei Liu. The curse of depth in large language models. arXiv preprint arXiv:2502.05795,
-
[11]
A Simulation Environments Linear: In this simulation, the token sequence {A, B, C, D, E, F, G} is repeated periodically
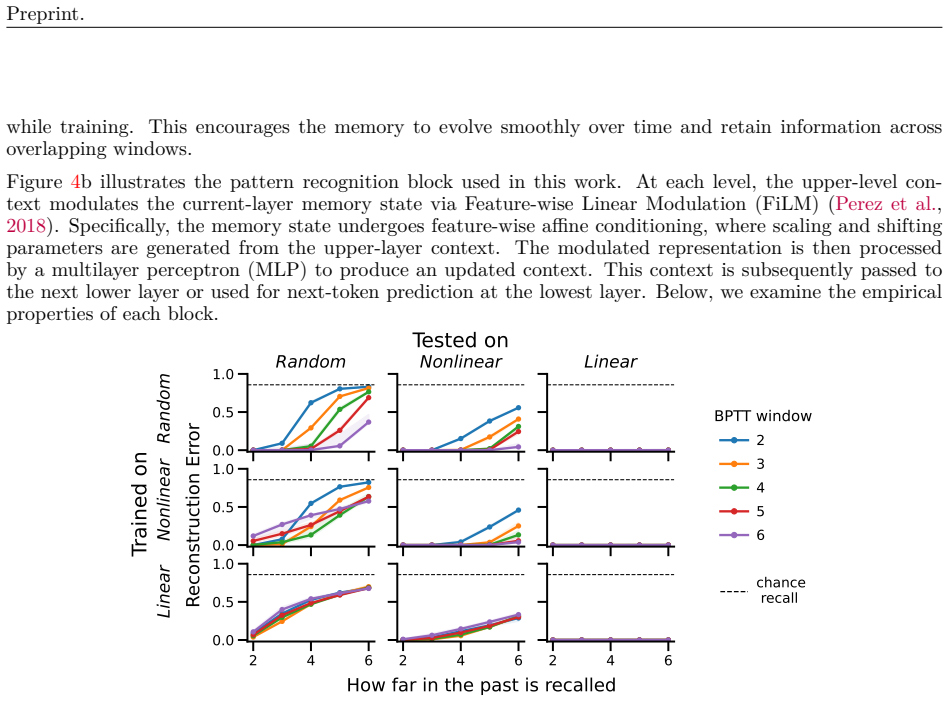
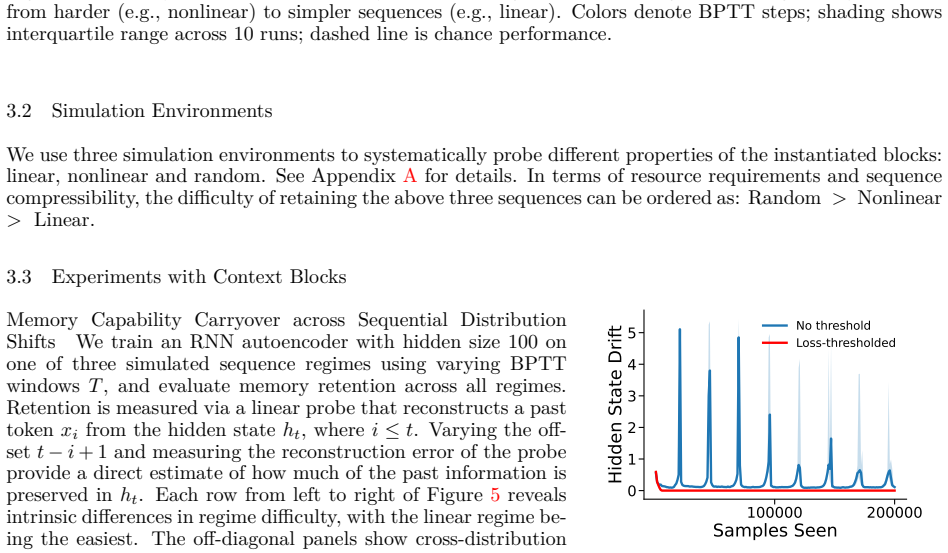
13 Preprint. A Simulation Environments Linear: In this simulation, the token sequence {A, B, C, D, E, F, G} is repeated periodically. We refer to this setting as Linear, since a sequence model with purely linear dynamics should, in principle, be able to capture the underlying periodic rule without requiring nonlinear transformations. C A B G D E F Communi...
2000
-
[12]
Our implementation was built on codes from Sun et al
Architecture follows a Pre-LN LLaMA-style stack (RMSNorm, RoPE, SwiGLU). Our implementation was built on codes from Sun et al. (2025). Hyperparameter Value Shared across all variants Vocabulary size 27 (character-level) / 50,257 (sub-word, GPT-2 BPE) Input token embedding learned, N (0, 0.02) (char-level) / frozen GPT-2 + linear proj. to dmodel (sub-word)...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.