NBQ: Next-Best-Question for Dynamic Profiling
Pith reviewed 2026-06-28 18:32 UTC · model grok-4.3
The pith
NBQ selects the question with highest expected information gain to build structured user profiles from free-form dialogue.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
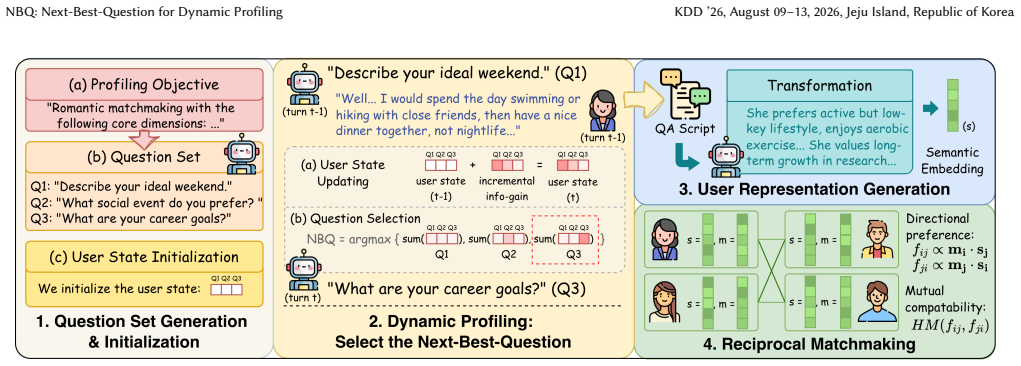
At each turn an interviewer should ask the question with the highest expected information gain given what has already been learned and the conversation goal. NBQ seeds a diverse pool of candidate questions, maintains a compact and continuously updated user state, adaptively selects the next question within a turn budget, and distills the resulting free-form dialogue into a structured vector-based user profile. For reciprocal matchmaking compatibility is modeled by both self-description and counterpart-preference representations, and QuickMatch recasts pairwise scoring as approximate vector search.
What carries the argument
Expected information gain computed from a compact user state to choose the next question from a seeded diverse pool.
If this is right
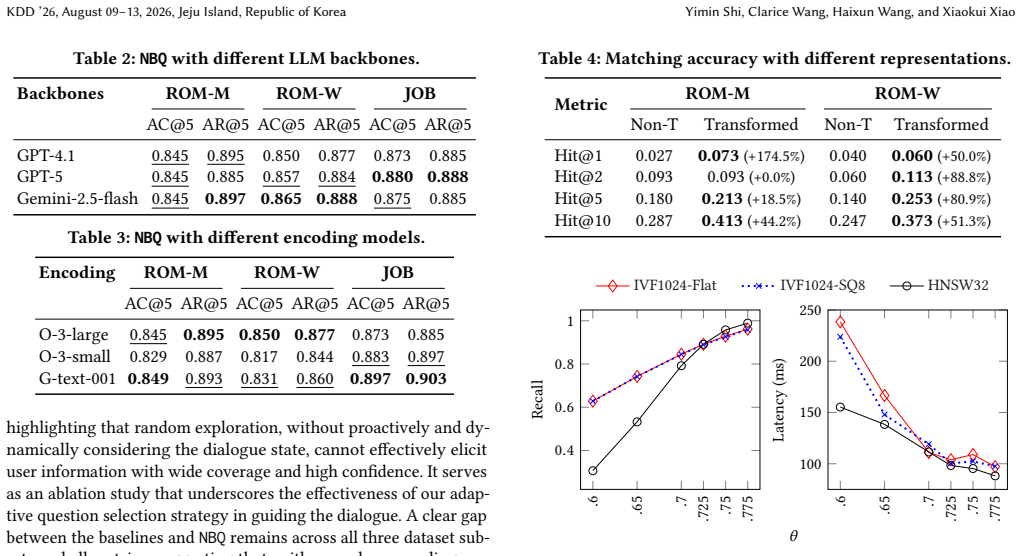
- Profiling quality rises by up to 13.6 percent in AC@T and 14.0 percent in AR@T.
- Retrieval speed increases by up to 22.9 times while retaining recall of 0.989.
- The same selection logic applies to other conversational knowledge-discovery settings such as hiring screens and podcasts.
Where Pith is reading between the lines
- Compact state representations may reduce the need to store full conversation histories, lowering storage and privacy costs.
- The approach could be tested in domains where the profiling goal changes mid-conversation.
- Seeding the question pool from domain-specific sources might be replaced by learned generation without breaking the rest of the pipeline.
Load-bearing premise
Expected information gain can be reliably estimated from the maintained compact user state and a seeded diverse pool of candidate questions is sufficient to cover the profiling goal across turns.
What would settle it
A controlled user study in which profiles built with NBQ-selected questions show no accuracy gain over random or fixed-order questions when measured by downstream task performance.
Figures




read the original abstract
Many real-world conversational settings for knowledge discovery, including podcasts, hiring screens, and marketplaces, require a purpose-driven understanding of a person. We study the Next-Best-Question (NBQ) problem: at each turn, an interviewer should ask the question with the highest expected information gain given what has already been learned and the conversation goal. We propose NBQ, a plug-and-play framework that seeds a diverse pool of candidate questions, maintains a compact and continuously updated user state, adaptively selects the next question within a turn budget, and distills the resulting free-form dialogue into a structured vector-based user profile. As a demanding application, we instantiate NBQ for reciprocal matchmaking, where compatibility must be mutual and each person is modeled by both self-description and counterpart-preference representations. To support large-scale matching, we further introduce QuickMatch, an efficient retrieval layer that recasts reciprocal matching from quadratic pairwise scoring to approximate vector search. Experiments show that NBQ improves user profiling quality by up to 13.6% and 14.0% in AC@T and AR@T, respectively, while QuickMatch accelerates retrieval by up to 22.9x with recall up to 0.989.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Next-Best-Question (NBQ) problem for purpose-driven conversational profiling and proposes a plug-and-play framework that seeds a diverse candidate question pool, maintains a compact continuously updated user state, adaptively selects questions to maximize expected information gain within a turn budget, and distills free-form dialogue into a structured vector profile. It instantiates the approach for reciprocal matchmaking (modeling both self-description and counterpart preferences) and introduces QuickMatch to reduce quadratic pairwise scoring to approximate vector search. Experiments report up to 13.6% and 14.0% gains in AC@T and AR@T profiling metrics plus 22.9x retrieval speedup at recall 0.989.
Significance. If the central claims hold, the work offers a practical, modular approach to dynamic profiling that combines information-theoretic question selection with scalable retrieval; this could be useful for conversational applications in hiring, marketplaces, and knowledge discovery. The explicit separation of state maintenance, selection, and distillation plus the efficiency layer are positive design choices.
major comments (3)
- [Abstract / NBQ framework] Abstract and framework description: the headline AC@T/AR@T gains rest on the claim that expected information gain can be reliably estimated from the maintained compact user state. No ablation or comparison to a full-history oracle is reported that would confirm the compact representation preserves sufficient signal across multiple turns; without this, the adaptive selection benefit cannot be isolated from the assumption.
- [Experiments] Experiments section (profiling results): the reported 13.6% and 14.0% improvements are stated without error bars, statistical significance tests, or breakdown by number of turns. It is therefore unclear whether the gains are robust or driven by particular dataset characteristics or the seeded pool diversity.
- [QuickMatch] QuickMatch description: the reduction from quadratic to approximate vector search is presented as exact in recall@0.989, but no analysis is given of how the reciprocal (mutual) constraint is preserved under the approximation or of failure cases where high recall still yields poor matchmaking quality.
minor comments (2)
- [Experiments] Notation for AC@T and AR@T is introduced without an explicit equation or definition in the main text; a short formal definition would improve reproducibility.
- [NBQ framework] The seeded candidate pool is described as 'diverse' but no quantitative measure of pool coverage or diversity (e.g., embedding variance or coverage of profiling dimensions) is provided.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment point-by-point below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / NBQ framework] Abstract and framework description: the headline AC@T/AR@T gains rest on the claim that expected information gain can be reliably estimated from the maintained compact user state. No ablation or comparison to a full-history oracle is reported that would confirm the compact representation preserves sufficient signal across multiple turns; without this, the adaptive selection benefit cannot be isolated from the assumption.
Authors: We appreciate the referee highlighting this point. The compact state is designed to retain the information necessary for estimating expected information gain, but we agree that an explicit ablation against a full-history oracle would strengthen the isolation of the adaptive selection benefit. We will add this comparison in the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments section (profiling results): the reported 13.6% and 14.0% improvements are stated without error bars, statistical significance tests, or breakdown by number of turns. It is therefore unclear whether the gains are robust or driven by particular dataset characteristics or the seeded pool diversity.
Authors: We agree that additional statistical rigor and breakdowns would improve clarity. In the revised version we will report error bars, include statistical significance tests, and provide results broken down by number of turns. revision: yes
-
Referee: [QuickMatch] QuickMatch description: the reduction from quadratic to approximate vector search is presented as exact in recall@0.989, but no analysis is given of how the reciprocal (mutual) constraint is preserved under the approximation or of failure cases where high recall still yields poor matchmaking quality.
Authors: We acknowledge the value of analyzing how the reciprocal constraint behaves under approximation. We will add a discussion of this preservation mechanism together with an examination of potential failure cases in the revised QuickMatch section. revision: yes
Circularity Check
No circularity: empirical gains reported from proposed framework without reduction to inputs by construction
full rationale
The paper describes a plug-and-play NBQ framework that seeds a candidate pool, maintains a compact user state, selects via expected information gain, and distills to a vector profile, then reports experimental improvements (up to 13.6% AC@T, 14.0% AR@T) and QuickMatch speedups. No equations, derivations, or self-citations are shown that make any claimed result equivalent to its inputs by definition, rename a fitted quantity as a prediction, or rely on load-bearing self-citation chains. The central claims rest on external experimental validation rather than internal self-reference, making the derivation self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhiliang Chen, Xinyuan Niu, Chuan-Sheng Foo, and Bryan Kian Hsiang Low
-
[2]
InInternational Conference on Learning Representations (ICLR ’25), Spotlight
Broaden your SCOPE! Efficient Multi-turn Conversation Planning for LLMs with Semantic Space. InInternational Conference on Learning Representations (ICLR ’25), Spotlight. https://openreview.net/forum?id=3cgMU3TyyE
-
[3]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The faiss library.arXiv preprint arXiv:2401.08281(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Naghmeh Farzi and Laura Dietz. 2025. Criteria-Based LLM Relevance Judgments. InProceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval (ICTIR). 254–263
2025
-
[5]
Aristides Gionis, Piotr Indyk, Rajeev Motwani, et al. 1999. Similarity search in high dimensions via hashing. InVldb, Vol. 99. 518–529
1999
-
[6]
Yunchao Gong, Svetlana Lazebnik, Albert Gordo, and Florent Perronnin. 2012. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval.IEEE transactions on pattern analysis and machine intelligence35, 12 (2012), 2916–2929
2012
-
[7]
Baidu Inc. 2023. PUCK: A High-Performance Approximate Nearest Neighbor Search Library. https://github.com/baidu/puck
2023
-
[8]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search.IEEE transactions on pattern analysis and machine intelligence33, 1 (2010), 117–128
2010
-
[9]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data7, 3 (2019), 535–547
2019
-
[10]
Andrew Kane. 2021. pgvector: Open-Source Vector Similarity Search Extension for PostgreSQL. https://github.com/pgvector/pgvector
2021
-
[11]
Sara Kemper, Justin Cui, Kai Dicarlantonio, Kathy Lin, Danjie Tang, Anton Ko- rikov, and Scott Sanner. 2024. Retrieval-Augmented Conversational Recommen- dation with Prompt-based Semi-Structured Natural Language State Tracking. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’24). AC...
-
[12]
Heeseon Kim, Hyeongjun Yang, and Kyong Ho Lee. 2023. Confident Action Decision via Hierarchical Policy Learning for Conversational Recommendation. InProceedings of the ACM Web Conference 2023 (WWW ’23). ACM, Austin, TX, USA, 1386–1395. doi:10.1145/3543507.3583536
-
[13]
Kai-Huang Lai, Zhe-Rui Yang, Pei-Yuan Lai, Chang-Dong Wang, Mohsen Guizani, and Min Chen. 2024. Knowledge-Aware Explainable Reciprocal Recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 8636–8644. doi:10.1609/aaai.v38i8.28708
-
[14]
Belinda Z Li, Alex Tamkin, Noah Goodman, and Jacob Andreas. 2025. Elicit- ing Human Preferences with Language Models. InThe Thirteenth International Conference on Learning Representations
2025
-
[15]
Allen Lin, Ziwei Zhu, Jianling Wang, and James Caverlee. 2023. Enhancing User Personalization in Conversational Recommenders. InProceedings of the ACM Web Conference 2023 (WWW ’23). doi:10.48550/arXiv.2302.06656 Extended version: arXiv:2302.06656
-
[16]
Jiarui Luo, Miao Qiao, Chaoji Zuo, and Dong Deng. 2025. Tag-Filtered Approxi- mate Nearest Neighbor Search. In2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE, 3642–3654
2025
-
[17]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE transactions on pattern analysis and machine intelligence42, 4 (2018), 824–836
2018
-
[18]
Behnam Neyshabur and Nathan Srebro. 2015. On symmetric and asymmetric lshs for inner product search. InInternational Conference on Machine Learning. PMLR, 1926–1934
2015
-
[19]
Hiroyuki Ootomo, Akira Naruse, Corey Nolet, Ray Wang, Tamas Feher, and Yong Wang. 2024. Cagra: Highly parallel graph construction and approximate nearest neighbor search for gpus. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 4236–4247
2024
-
[20]
James Jie Pan, Jianguo Wang, and Guoliang Li. 2024. Survey of vector database management systems.The VLDB Journal33, 5 (2024), 1591–1615
2024
-
[21]
Luiz Pizzato, Tomek Rej, Thomas Chung, Irena Koprinska, and Judy Kay. 2010. RECON: a reciprocal recommender for online dating. InProceedings of the fourth ACM conference on Recommender systems. 207–214
2010
-
[22]
Inc. Redis. [n. d.]. Redis as a Vector Database. https://redis.io/docs/latest/develop/ get-started/vector-database/
-
[23]
Burr Settles. 2009. Active learning literature survey. (2009)
2009
-
[24]
Anshumali Shrivastava and Ping Li. 2014. Asymmetric LSH (ALSH) for sublinear time maximum inner product search (MIPS).Advances in neural information processing systems27 (2014)
2014
-
[25]
Harsha Vardhan Simhadri, George Williams, Martin Aumüller, Matthijs Douze, Artem Babenko, Dmitry Baranchuk, Qi Chen, Lucas Hosseini, Ravishankar Krish- naswamny, Gopal Srinivasa, et al. 2022. Results of the NeurIPS’21 challenge on billion-scale approximate nearest neighbor search. InNeurIPS 2021 Competitions and Demonstrations Track. PMLR, 177–189
2022
-
[26]
Yitong Song, Kai Wang, Bin Yao, Zhida Chen, Jiong Xie, and Feifei Li. 2024. Effi- cient Reverse 𝑘 Approximate Nearest Neighbor Search Over High-Dimensional Vectors. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 4262–4274
2024
-
[27]
Hongda Sun, Hongzhan Lin, Haiyu Yan, Yang Song, Xin Gao, and Rui Yan. 2025. MockLLM: A Multi-Agent Behavior Collaboration Framework for Online Job Seeking and Recruiting. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 2714–2724
2025
-
[28]
Ji Sun, Guoliang Li, James Pan, Jiang Wang, Yongqing Xie, Ruicheng Liu, and Wen Nie. 2025. GaussDB-Vector: A Large-Scale Persistent Real-Time Vector Database for LLM Applications.Proceedings of the VLDB Endowment18, 12 (2025), 4951–4963
2025
-
[29]
Yufei Tao, Ke Yi, Cheng Sheng, and Panos Kalnis. 2009. Quality and efficiency in high dimensional nearest neighbor search. InProceedings of the 2009 ACM SIGMOD International Conference on Management of data. 563–576
2009
-
[30]
Paul Thomas, Seth Spielman, Nick Craswell, and Bhaskar Mitra. 2024. Large language models can accurately predict searcher preferences. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1930–1940
2024
-
[31]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. 2023. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine- tuned with human feedback.arXiv preprint arXiv:2305.14975(2023)
-
[32]
Yao Tian, Xi Zhao, and Xiaofang Zhou. 2022. DB-LSH: Locality-Sensitive Hashing with Query-based Dynamic Bucketing. In2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2250–2262
2022
-
[33]
Clarice Wang, Yimin Shi, and Xiaokui Xiao. 2025. A Framework for Evaluating AI Agents in Open-Ended Conversations via Scripted Simulation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
2025
-
[34]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. 2021. Milvus: A purpose-built vector data management system. InProceedings of the 2021 international conference on management of data. 2614–2627
2021
-
[35]
Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. 2024. MINT: EVALUATING LLMS IN MULTI-TURN INTERACTION WITH TOOLS AND LANGUAGE FEEDBACK. In12th International Conference on Learning Representations, ICLR 2024
2024
-
[36]
Chuangxian Wei, Bin Wu, Sheng Wang, Renjie Lou, Chaoqun Zhan, Feifei Li, and Yuanzhe Cai. 2020. Analyticdb-v: A hybrid analytical engine towards query fusion for structured and unstructured data.Proceedings of the VLDB Endowment 13, 12 (2020), 3152–3165
2020
-
[37]
Peng Xia, Shuangfei Zhai, Benyuan Liu, Yizhou Sun, and Cindy Chen. 2016. Design of Reciprocal Recommendation Systems for Online Dating.Social Network Analysis and Mining6, 1 (2016), 1–17. NBQ: Next-Best-Question for Dynamic Profiling KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea
2016
-
[38]
Jiadong Xie, Jeffrey Xu Yu, and Yingfan Liu. 2025. Fast Approximate Similarity Join in Vector Databases.Proceedings of the ACM on Management of Data3, 3 (2025), 1–26
2025
-
[39]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi
-
[40]
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms.arXiv preprint arXiv:2306.13063(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Lu Zhang, Chen Li, Yu Lei, Zhu Sun, and Guanfeng Liu. 2024. An empirical analysis on multi-turn conversational recommender systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 841–851
2024
-
[42]
Yizhe Zhang, Jiarui Lu, and Navdeep Jaitly. 2024. Probing the Multi-turn Planning Capabilities of LLMs via 20 Question Games. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1495–1516
2024
-
[43]
Weijie Zhao, Shulong Tan, and Ping Li. 2020. Song: Approximate nearest neighbor search on gpu. In2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 1033–1044
2020
-
[44]
Xi Zhao, Zhonghan Chen, Kai Huang, Ruiyuan Zhang, Bolong Zheng, and Xiao- fang Zhou. 2024. Efficient Approximate Maximum Inner Product Search Over Sparse Vectors. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 3961–3974
2024
-
[45]
Bowen Zheng, Yupeng Hou, Wayne Xin Zhao, Yang Song, and Hengshu Zhu
-
[46]
Reciprocal Sequential Recommendation. InProceedings of the 17th ACM Conference on Recommender Systems (RecSys). —. doi:10.1145/3604915.3608798 A Proof of Theorems A.1 Proof of Theorem 1 Theorem 1.Let 𝑓𝑖 𝑗, 𝑓 𝑗𝑖 ∈ ( 0, 1]. If 𝑔(𝑢𝑖, 𝑢𝑗 ) ≥𝜃 , then necessarily [¯s𝑖; ¯m𝑖 ] · [ ¯m𝑗 ; ¯s𝑗 ] ≥4𝜃−2where ¯m= m ∥m∥ and ¯s= s ∥s∥ . Proof.Assume𝑔(𝑢 𝑖, 𝑢𝑗 ) ≥𝜃. By the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.