Not All Flips Are Conformity: Decomposing Stance Convergence in Multi-Agent LLM Debate
Pith reviewed 2026-06-28 18:44 UTC · model grok-4.3
The pith
The conventional answer flip rate in multi-agent LLM debates conflates spontaneous instability, stance-induced conformity, and reasoning-induced persuasion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
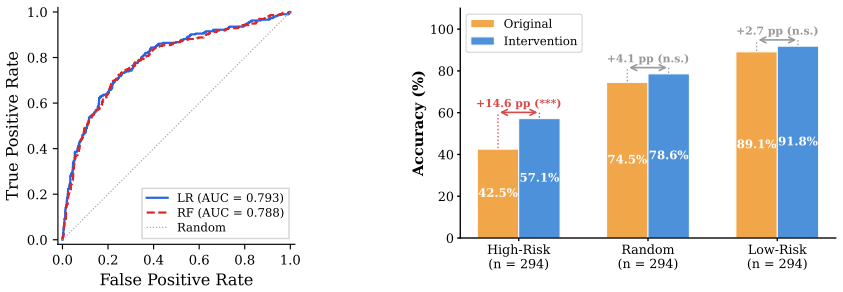
The conventional answer flip rate conflates three distinct mechanisms: spontaneous instability (changes under self-reflection alone), stance-induced conformity (changes triggered by peer stances without reasoning content), and reasoning-induced persuasion (influence from the content of reasoning). A three-source decomposition framework isolates each mechanism through controlled counterfactual conditions, revealing in the primary MMLU-Pro setting that 37 percent of agent-question observations change under self-reflection alone, that strict conformity is 29 percent and remains predominantly harmful across replications, and that even vacuous reasoning is associated with 20-39 percent error adop
What carries the argument
Three-source decomposition framework that isolates spontaneous instability, stance-induced conformity, and reasoning-induced persuasion via controlled counterfactual conditions such as self-reflection alone.
If this is right
- Without correctness labels or self-reflection controls, reducing peer adoption does not improve accuracy because harmful and beneficial influence cannot be distinguished.
- Harmful conformity can be predicted from Round 0 features with AUC of 0.79.
- Risk-targeted intervention reduces harmful conformity by 13.6 percentage points.
- Even reasoning-like presentation without content carries substantial persuasive weight, leading resistant agents to adopt errors.
- Robustness tests show substantial model-dependent instability across GPQA-Diamond and three model families.
Where Pith is reading between the lines
- Debate protocols could routinely run a self-reflection baseline first and discard or reweight agents that prove unstable before peer interaction begins.
- The same decomposition could be applied to multi-agent negotiation or planning tasks to separate social compliance from informational transfer.
- If instability proves highly model-dependent, selecting base models with lower self-flip rates might shrink the apparent benefit of debate more than any change to the debate rules themselves.
Load-bearing premise
The controlled counterfactual conditions isolate spontaneous instability, stance-induced conformity, and reasoning-induced persuasion as distinct mechanisms without significant confounding from the multi-agent setup itself.
What would settle it
If the flip rate under self-reflection alone equals the full multi-agent debate rate in a new run, or if the three measured components fail to sum consistently across conditions, the claim that the counterfactuals cleanly separate the mechanisms would be falsified.
Figures


read the original abstract
Multi-agent debate (MAD) is a promising strategy for improving LLM reasoning, but when agents converge on a shared answer, it is unclear whether that convergence reflects genuine deliberation or social compliance. We show that the conventional answer flip rate conflates three distinct mechanisms: spontaneous instability, stance-induced conformity, and reasoning-induced persuasion. Our three-source decomposition framework isolates each through controlled counterfactual conditions. In the primary MMLU-Pro setting, 37% of agent-question observations change under self-reflection alone, while robustness tests show substantial model-dependent instability across GPQA-Diamond and three model families; strict conformity is 29% in the primary setting and remains predominantly harmful across model replications (57-77% correct-to-wrong). A controlled information-gradient experiment reveals that even vacuous reasoning is associated with 20-39% error adoption among resistant agents, with reasoning-like presentation carrying substantial persuasive weight. Harmful conformity can be predicted from Round 0 features (AUC = 0.79), and risk-targeted intervention reduces it by 13.6 percentage points (p < 0.001). However, without correctness labels or self-reflection controls, reducing peer adoption does not improve accuracy, because harmful and beneficial influence cannot be distinguished.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that conventional answer flip rates in multi-agent LLM debate conflate three mechanisms—spontaneous instability, stance-induced conformity, and reasoning-induced persuasion—and introduces a three-source decomposition framework using controlled counterfactual conditions. In the primary MMLU-Pro setting it reports 37% flips under self-reflection alone, 29% strict conformity (predominantly harmful at 57-77% correct-to-wrong), and 20-39% error adoption from an information-gradient experiment even with vacuous reasoning; it further shows that harmful conformity is predictable from Round-0 features (AUC 0.79) and that a risk-targeted intervention reduces it by 13.6 pp, while noting that reducing peer adoption without correctness labels does not improve accuracy.
Significance. If the decomposition is valid, the work supplies a more precise empirical vocabulary for convergence in MAD, distinguishes harmful from beneficial influence, and supplies actionable prediction and intervention results. The multi-benchmark, multi-model replication and the explicit demonstration that accuracy gains require correctness labels are concrete strengths that would inform both analysis and system design.
major comments (3)
- [Abstract / counterfactual conditions] The central decomposition claim rests on the counterfactual conditions cleanly isolating the three mechanisms, yet the shared multi-agent prompt scaffolding, agent identities, and debate format are held constant across arms; any systematic effect of repeated question phrasing or model response bias would therefore be attributed to the named mechanisms rather than the experimental framing itself. (Abstract, primary MMLU-Pro setting and information-gradient experiment)
- [Abstract / information-gradient experiment] The information-gradient result attributes 20-39% error adoption to 'reasoning-like presentation' even under vacuous reasoning, but the manuscript does not report how vacuous content is constructed or verified to contain no substantive reasoning; without that operationalization the persuasive-weight claim cannot be separated from residual content effects. (Abstract)
- [Abstract / intervention results] The risk-targeted intervention is reported to reduce harmful conformity by 13.6 pp (p < 0.001), yet the paper does not specify whether the Round-0 predictor is applied prospectively or whether the reduction is measured in a held-out condition that avoids leakage from the same agent-question pairs used to train the predictor. (Abstract)
minor comments (2)
- [Abstract] The abstract states 'robustness tests show substantial model-dependent instability across GPQA-Diamond and three model families' but supplies no model names, exact flip percentages, or table reference; adding these numbers would allow readers to assess the claimed variability.
- [Abstract] The phrase 'strict conformity is 29% in the primary setting' would benefit from an explicit definition of the 'strict conformity' counterfactual condition (e.g., whether agents see only the peer answer or also the peer's reasoning trace).
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our decomposition framework. We respond to each major comment below and note planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / counterfactual conditions] The central decomposition claim rests on the counterfactual conditions cleanly isolating the three mechanisms, yet the shared multi-agent prompt scaffolding, agent identities, and debate format are held constant across arms; any systematic effect of repeated question phrasing or model response bias would therefore be attributed to the named mechanisms rather than the experimental framing itself. (Abstract, primary MMLU-Pro setting and information-gradient experiment)
Authors: We agree that holding the overall prompt scaffolding, agent identities, and debate format constant across conditions means that any residual effects from repeated question phrasing or model response biases are not fully separated from the targeted mechanisms. Our design isolates the mechanisms by varying only the presence/absence of peer stances and reasoning content while keeping other elements fixed, which is the standard approach for such decompositions; however, we acknowledge this does not eliminate all possible framing confounds. We will add an explicit discussion of this limitation, along with any related robustness checks, to the Methods and Limitations sections. revision: partial
-
Referee: [Abstract / information-gradient experiment] The information-gradient result attributes 20-39% error adoption to 'reasoning-like presentation' even under vacuous reasoning, but the manuscript does not report how vacuous content is constructed or verified to contain no substantive reasoning; without that operationalization the persuasive-weight claim cannot be separated from residual content effects. (Abstract)
Authors: The full manuscript (Section 3.2) describes vacuous reasoning as templated generic phrases (e.g., 'After careful consideration of the options...') that preserve surface format but contain no logical steps, evidence, or domain content; verification combined manual inspection by the authors with automated scans for reasoning-related keywords and sentence structures. We will revise the abstract to include a brief statement of this operationalization and expand the methods description for clarity. revision: yes
-
Referee: [Abstract / intervention results] The risk-targeted intervention is reported to reduce harmful conformity by 13.6 pp (p < 0.001), yet the paper does not specify whether the Round-0 predictor is applied prospectively or whether the reduction is measured in a held-out condition that avoids leakage from the same agent-question pairs used to train the predictor. (Abstract)
Authors: The predictor was trained on a random subset of agent-question pairs and evaluated prospectively on a disjoint held-out set of pairs to avoid leakage; the reported reduction and p-value reflect performance on this held-out condition. We will add this detail to the abstract and the corresponding experimental section in the revision. revision: yes
Circularity Check
No circularity: empirical decomposition via controlled experiments
full rationale
The paper presents an empirical framework that measures flip rates under distinct experimental conditions (self-reflection alone, strict conformity setup, information-gradient). These are direct observational contrasts, not derivations, equations, or fitted parameters renamed as predictions. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing premises. The central claim rests on the experimental design itself, which is externally falsifiable through replication on different models and datasets. This is self-contained empirical work with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Controlled counterfactual conditions (e.g., self-reflection alone) isolate spontaneous instability, stance-induced conformity, and reasoning-induced persuasion as distinct mechanisms.
Reference graph
Works this paper leans on
-
[1]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[2]
International Conference on Machine Learning , pages=
Should we be going MAD? A Look at Multi-Agent Debate Strategies for LLMs , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[3]
arXiv preprint arXiv:2509.05396 , year=
Talk Isn't Always Cheap: Understanding Failure Modes in Multi-Agent Debate , author=. arXiv preprint arXiv:2509.05396 , year=
-
[4]
arXiv preprint arXiv:2502.08788 , year=
Stop Overvaluing Multi-Agent Debate--We Must Rethink Evaluation and Embrace Model Heterogeneity , author=. arXiv preprint arXiv:2502.08788 , year=
-
[5]
arXiv preprint arXiv:2505.22960 , year=
Revisiting multi-agent debate as test-time scaling: A systematic study of conditional effectiveness , author=. arXiv preprint arXiv:2505.22960 , year=
-
[6]
2025 IEEE International Conference on Information Reuse and Integration and Data Science (IRI) , pages=
Towards simulating social influence dynamics with llm-based multi-agents , author=. 2025 IEEE International Conference on Information Reuse and Integration and Data Science (IRI) , pages=. 2025 , organization=
2025
-
[7]
The Thirteenth International Conference on Learning Representations , year=
Do as We Do, Not as You Think: the Conformity of Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[8]
arXiv preprint arXiv:2505.21588 , year=
Herd behavior: Investigating peer influence in llm-based multi-agent systems , author=. arXiv preprint arXiv:2505.21588 , year=
-
[9]
arXiv preprint arXiv:2508.14918 , year=
Disentangling the Drivers of LLM Social Conformity: An Uncertainty-Moderated Dual-Process Mechanism , author=. arXiv preprint arXiv:2508.14918 , year=
-
[10]
arXiv preprint arXiv:2601.11563 , year=
Human-like Social Compliance in Large Language Models: Unifying Sycophancy and Conformity through Signal Competition Dynamics , author=. arXiv preprint arXiv:2601.11563 , year=
-
[11]
International Conference on Learning Representations , volume=
Towards understanding sycophancy in language models , author=. International Conference on Learning Representations , volume=
-
[12]
Simple synthetic data reduces sycophancy in large language models
Simple synthetic data reduces sycophancy in large language models , author=. arXiv preprint arXiv:2308.03958 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
When truth is overridden: Uncovering the internal origins of sycophancy in large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[14]
When Identity Skews Debate: Anonymization for Bias-Reduced Multi-Agent Reasoning
When Identity Skews Debate: Anonymization for Bias-Reduced Multi-Agent Reasoning , author=. arXiv preprint arXiv:2510.07517 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
arXiv preprint arXiv:2509.23055 , year=
Peacemaker or Troublemaker: How Sycophancy Shapes Multi-Agent Debate , author=. arXiv preprint arXiv:2509.23055 , year=
-
[16]
Advances in Neural Information Processing Systems , volume=
Multi-llm debate: Framework, principals, and interventions , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:2509.11035 , year=
Free-mad: Consensus-free multi-agent debate , author=. arXiv preprint arXiv:2509.11035 , year=
-
[18]
The Fourteenth International Conference on Learning Representations , year=
Multi-Agent Debate with Memory Masking , author=. The Fourteenth International Conference on Learning Representations , year=
-
[19]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
arXiv preprint arXiv:2507.13038 , year=
MAD-Spear: A Conformity-Driven Prompt Injection Attack on Multi-Agent Debate Systems , author=. arXiv preprint arXiv:2507.13038 , year=
-
[21]
Transactions on Machine Learning Research , year=
Teaching Models to Express Their Uncertainty in Words , author=. Transactions on Machine Learning Research , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
First Conference on Language Modeling , year=
GPQA: A Graduate-Level Google-Proof Q&A Benchmark , author=. First Conference on Language Modeling , year=
-
[24]
International conference on learning representations , volume=
Large language models cannot self-correct reasoning yet , author=. International conference on learning representations , volume=
-
[25]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[26]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[27]
International conference on learning representations , volume=
Chateval: Towards better llm-based evaluators through multi-agent debate , author=. International conference on learning representations , volume=
-
[28]
Do androids laugh at electric sheep? humor" understanding" benchmarks from the new yorker caption contest , author=. arXiv preprint arXiv:2209.06293 , year=
-
[29]
arXiv preprint arXiv:2312.12241 , year=
Geomverse: A systematic evaluation of large models for geometric reasoning , author=. arXiv preprint arXiv:2312.12241 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Debate or vote: Which yields better decisions in multi-agent large language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
, author=
A study of normative and informational social influences upon individual judgment. , author=. The journal of abnormal and social psychology , volume=. 1955 , publisher=
1955
-
[32]
A minority of one against a unanimous majority
Studies of independence and conformity: I. A minority of one against a unanimous majority. , author=. Psychological monographs: General and applied , volume=. 1956 , publisher=
1956
-
[33]
1986 , publisher=
Communication and persuasion: Central and peripheral routes to attitude change , author=. 1986 , publisher=
1986
-
[34]
Journal of political Economy , volume=
A theory of fads, fashion, custom, and cultural change as informational cascades , author=. Journal of political Economy , volume=. 1992 , publisher=
1992
-
[35]
The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.0
-
[36]
Council of LLM s: Evaluating Capability of Large Language Models to Annotate Propaganda
Sharma, Vivek and Jain, Shweta and Shokri, Mohammad and Levitan, Sarah Ita and Filatova, Elena. Council of LLM s: Evaluating Capability of Large Language Models to Annotate Propaganda. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.1
-
[37]
Emoji Reactions on Telegram: Unreliable Indicators of Emotional Resonance
Tardelli, Serena and Alvisi, Lorenzo and Cima, Lorenzo and Cresci, Stefano and Tesconi, Maurizio. Emoji Reactions on Telegram: Unreliable Indicators of Emotional Resonance. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.2
-
[38]
Quantifying Social Sentiment in Hostels Using A Domain-Specific Transformer Pipeline
McMurry, Ian W. Quantifying Social Sentiment in Hostels Using A Domain-Specific Transformer Pipeline. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.3
-
[39]
Predicting Convincingness in Political Speech: How Emotional Tone Shapes Persuasive Strength
Verma, Bhuvanesh and Marreddy, Mounika and Mehler, Alexander. Predicting Convincingness in Political Speech: How Emotional Tone Shapes Persuasive Strength. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.4
-
[40]
Measuring LLM s' Sensitivity to Paraphrased Opinion Prompts
Alhetelah, Bushra and Ahmad, Irfan. Measuring LLM s' Sensitivity to Paraphrased Opinion Prompts. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.5
-
[41]
The Impact of Highlighting Subjective Language on Perceived News Trustworthiness
Shokri, Mohammad and Sharma, Vivek and Klapper, Emily and Jain, Shweta and Filatova, Elena and Levitan, Sarah Ita. The Impact of Highlighting Subjective Language on Perceived News Trustworthiness. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.6
-
[42]
Appraisal Trajectories in Narratives Reveal Distinct Patterns of Emotion Evocation
Sch. Appraisal Trajectories in Narratives Reveal Distinct Patterns of Emotion Evocation. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.7
-
[43]
Exploring Subjective Tasks in F arsi: A Survey Analysis and Evaluation of Language Models
Rooein, Donya and Plaza-del-Arco, Flor Miriam and Nozza, Debora and Hovy, Dirk. Exploring Subjective Tasks in F arsi: A Survey Analysis and Evaluation of Language Models. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.8
-
[44]
Iaroshenko, Polina V. and Loukachevitch, Natalia V. Emotional Lexicons: How Large Language Models Predict Emotional Ratings of R ussian Words. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.9
-
[45]
Emotion-aware text simplification of user generated content using LLM s
Bezobrazova, Anastasiia and Sokova, Daria and Orasan, Constantin. Emotion-aware text simplification of user generated content using LLM s. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.10
-
[46]
Aranberri, Nora. Crowd-Based Evaluation of Emotion Intensity Preservation in S panish -- B asque Tweet Machine Translation. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.11
-
[47]
and Markov, Ilia and Vossen, Piek
Schouten, Stefan F. and Markov, Ilia and Vossen, Piek. A Position Paper on Toxic Reasoning: Grounding Categories of Toxic Language in Implications and Attitudes. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.12
-
[48]
Is Sentiment Banana-Shaped? Exploring the Geometry and Portability of Sentiment Concept Vectors
Lyngbaek, Laurits and Feldkamp, Pascale and Bizzoni, Yuri and Nielbo, Kristoffer and Enevoldsen, Kenneth. Is Sentiment Banana-Shaped? Exploring the Geometry and Portability of Sentiment Concept Vectors. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/20...
-
[49]
Disentangling Emotion Understanding and Generation in Large Language Models
Jafari, Sadegh and Lefever, Els and Hoste, Veronique. Disentangling Emotion Understanding and Generation in Large Language Models. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.14
-
[50]
News Credibility Assessment by LLM s and Humans: Implications for Political Bias
Neves, Pia Wenzel and Jakob, Charlott and Schmitt, Vera. News Credibility Assessment by LLM s and Humans: Implications for Political Bias. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.15
-
[51]
Schwager, Nils and M. Towards Simulating Social Media Users with LLM s: Evaluating the Operational Validity of Conditioned Comment Prediction. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.16
-
[52]
Label-Consistent Data Generation for Aspect-Based Sentiment Analysis Using LLM Agents
Monfared, Mohammad Hossein Akbari and Flek, Lucie and Karimi, Akbar. Label-Consistent Data Generation for Aspect-Based Sentiment Analysis Using LLM Agents. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.17
-
[53]
Antisocial Behavior Prediction: A Survey and Practical Guide
Ollagnier, Ana. Antisocial Behavior Prediction: A Survey and Practical Guide. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.18
-
[54]
Real-Time Mitigation of Negative Emotion in Customer Care Calls
Gangopadhyay, Surupendu and Mehrabani, Mahnoosh. Real-Time Mitigation of Negative Emotion in Customer Care Calls. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.19
-
[55]
Says Who? Argument Convincingness and Reader Stance Are Correlated with Perceived Author Personality
Weber, Sabine and Greschner, Lynn and Klinger, Roman. Says Who? Argument Convincingness and Reader Stance Are Correlated with Perceived Author Personality. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.20
-
[56]
A Transformer and Prototype-based Interpretable Model for Contextual Sarcasm Detection
Wen, Ximing and Rezapour, Rezvaneh. A Transformer and Prototype-based Interpretable Model for Contextual Sarcasm Detection. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.21
-
[57]
Multimodal Claim Extraction for Fact-Checking
Teo, Joycelyn and Cao, Rui and Deng, Zhenyun and Ding, Zifeng and Schlichtkrull, Michael Sejr and Vlachos, Andreas. Multimodal Claim Extraction for Fact-Checking. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2026.wassa-1.22
-
[58]
A Multi-Aspect Evaluation Framework for Synthetic Data: Case Study on Irony and Sarcasm
Majer, Laura and Bari \'c , Ana and Sandalj, Florijan and Unkovi \'c , Ivan and Puva c a, Bojan and S najder, Jan. A Multi-Aspect Evaluation Framework for Synthetic Data: Case Study on Irony and Sarcasm. The Proceedings for the 15th Workshop on Computational Approaches to Subjectivity, Sentiment Social Media Analysis ( WASSA 2026). 2026. doi:10.18653/v1/2...
-
[59]
Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.0
-
[60]
Robinson, Nathaniel R. and Abdelmoneim, Shahd and Kantharuban, Anjali and Alsboul, Otba and Lamsiyah, Salima and Marchisio, Kelly and Murray, Kenton. AMIYA Shared Task: A rabic Modeling In Your Accent at V ar D ial 2026. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.1
-
[61]
Far Out: Evaluating Language Models on Slang in A ustralian and I ndian E nglish
Dilsiz, Deniz Kaya and Srirag, Dipankar and Joshi, Aditya. Far Out: Evaluating Language Models on Slang in A ustralian and I ndian E nglish. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.2
-
[62]
Kuparinen, Olli. Effects of Speaker Bias in Dialect Identification and Automatic Transcription with Self-Supervised Speech Models. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.3
-
[63]
O c W iki D ialects: A W ikipedia Dataset With Rich Metadata for O ccitan Dialect Identification
N \'e dey, Oriane and Bawden, Rachel and Cl \'e rice, Thibault and Sagot, Beno \^i t. O c W iki D ialects: A W ikipedia Dataset With Rich Metadata for O ccitan Dialect Identification. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.4
-
[64]
Irastortza-Urbieta, Xabier and Garc \'i a-Miguel, Jos \'e M. and Garcia, Marcos. Language Mixture to Develop Accurate G alician Dependency Parsers: An Exploration of Its Effects. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.5
-
[65]
Crowdsourcing P iedmontese to Test LLM s on Non-Standard Orthography
Vico, Gianluca and Libovick \'y , Jind r ich. Crowdsourcing P iedmontese to Test LLM s on Non-Standard Orthography. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.6
-
[66]
G erman- E nglish Code-Switching in Large Language Models
Aks. G erman- E nglish Code-Switching in Large Language Models. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.7
-
[67]
Perplexity as a Metric for Dialectal Distance: A Computational Study of G reek Varieties
Chatzikyriakidis, Stergios and Psaltaki, Erofili and Papadakis, Dimitrios and Henriksson, Erik and Laippala, Veronika. Perplexity as a Metric for Dialectal Distance: A Computational Study of G reek Varieties. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.8
-
[68]
A Subword Embedding Approach for Variation Detection in L uxembourgish User Comments
Lutgen, Anne-Marie and Plum, Alistair and Purschke, Christoph. A Subword Embedding Approach for Variation Detection in L uxembourgish User Comments. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.9
-
[69]
Onomasiological Sense Alignment Across Dialect Dictionaries
Mederake, Nathalie and Urbach, Nico and Fischer, Hanna and Lameli, Alfred. Onomasiological Sense Alignment Across Dialect Dictionaries. A Taxonomy-Constrained LLM Classification. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.10
-
[70]
and Uban, Ana Sabina and Marchitan, Teodor-George and Iordache, Ioan-Bogdan and Georgescu, Simona
Dinu, Liviu P. and Uban, Ana Sabina and Marchitan, Teodor-George and Iordache, Ioan-Bogdan and Georgescu, Simona. On the Intelligibility of R omance Language Varieties: S panish and P ortuguese in E urope and A merica. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.11
-
[71]
Dialect Matters: Cross-Lingual ASR Transfer for Low-Resource I ndic Language Varieties
Dhasmana, Akriti and Srivastava, Aarohi and Chiang, David. Dialect Matters: Cross-Lingual ASR Transfer for Low-Resource I ndic Language Varieties. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.12
-
[72]
Alabdullah, Abdullah and Han, Lifeng and Lin, Chenghua. Ara- HOPE : Human-Centric Post-Editing Evaluation for Dialectal A rabic to M odern S tandard A rabic Translation. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.13
-
[73]
I ndic- T uned L ens: Interpreting Multilingual Models in I ndian Languages
Panchal, Mihir and Varshney, Deeksha and ., Mamta and Ekbal, Asif. I ndic- T uned L ens: Interpreting Multilingual Models in I ndian Languages. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.14
-
[74]
Building ASR Resources for the Hutsul Dialect of U krainian
Kyslyi, Roman and Orlovskyi, Artem and Khomenko, Pavlo and Onyshchenko, Bohdan and Guzii, Zakhar. Building ASR Resources for the Hutsul Dialect of U krainian. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.15
-
[75]
From F us H a to Folk: Exploring Cross-Lingual Transfer in A rabic Language Models
Khalak, Abdulmuizz and Issam, Abderrahmane and Spanakis, Gerasimos. From F us H a to Folk: Exploring Cross-Lingual Transfer in A rabic Language Models. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.16
-
[76]
Extending ASR Evaluation Resources for M odern G reek Dialects
Tsoukala, Chara and Bompolas, Stavros and Margariti, Antigoni and Panagiotou, Konstantina and Plaiti, Maria Elisavet and Tzanakaki, Nefeli and Karatsareas, Petros and Ralli, Angela and Anastasopoulos, Antonios and Markantonatou, Stella. Extending ASR Evaluation Resources for M odern G reek Dialects. Proceedings of the 13th Workshop on NLP for Similar Lang...
-
[77]
How Should We Model the Probability of a Language?
Dent, Rasul and Ortiz Suarez, Pedro and Cl \'e rice, Thibault and Sagot, Beno \^i t. How Should We Model the Probability of a Language?. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.18
-
[78]
Bridging Dialectal Variation: A Phonetic Transcription Tool for T amil
Mahaganapathy, Ahrane and Karunakaran, Sumirtha and Navakulan, Kavitha and Sarveswaran, Kengatharaiyer. Bridging Dialectal Variation: A Phonetic Transcription Tool for T amil. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.19
-
[79]
Regional Variation in the Performance of ASR Models on C roatian and S erbian
Samard z i \'c , Tanja and Rupnik, Peter and Ljube s i \'c , Nikola. Regional Variation in the Performance of ASR Models on C roatian and S erbian. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.20
-
[80]
Syllable Structures Across A rabic Varieties
Qaddoumi, Abdelrahim and Kodner, Jordan and Khalifa, Salam and Broselow, Ellen and Rambow, Owen. Syllable Structures Across A rabic Varieties. Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects. 2026. doi:10.18653/v1/2026.vardial-1.21
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.