Images as Tables: In-Context Learning with TabPFN for Low-Data Detection of AI-Generated Images
Pith reviewed 2026-06-28 18:40 UTC · model grok-4.3
The pith
Encoding images as PCA-reduced DINOv3 rows lets TabPFN classify real versus AI-generated images more accurately than task-specific detectors when labels are scarce.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
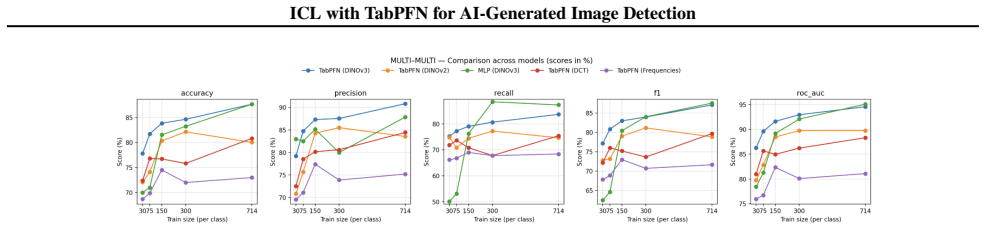
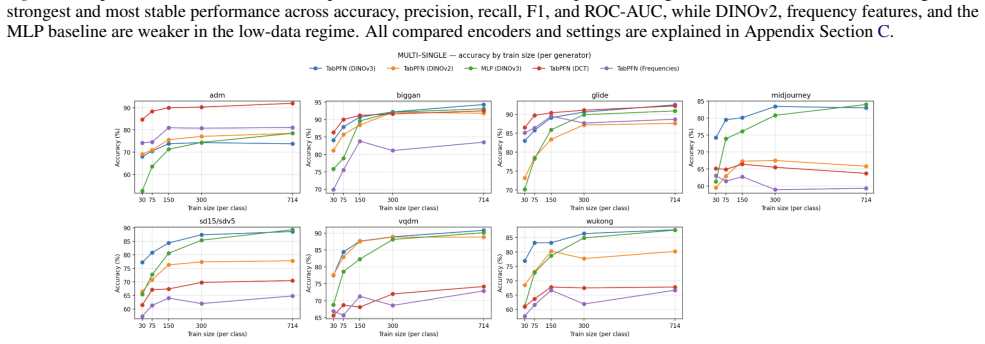
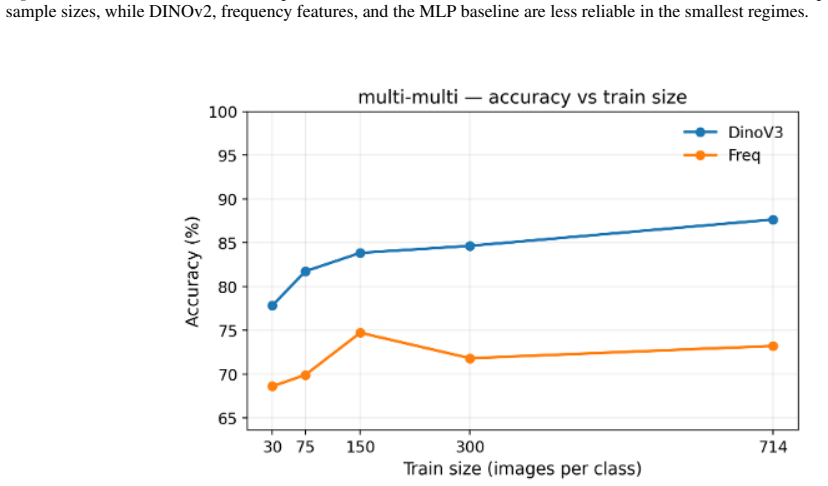
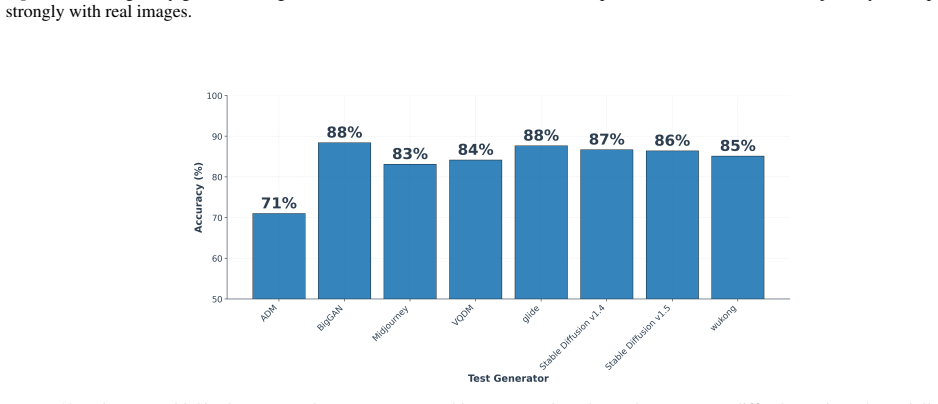
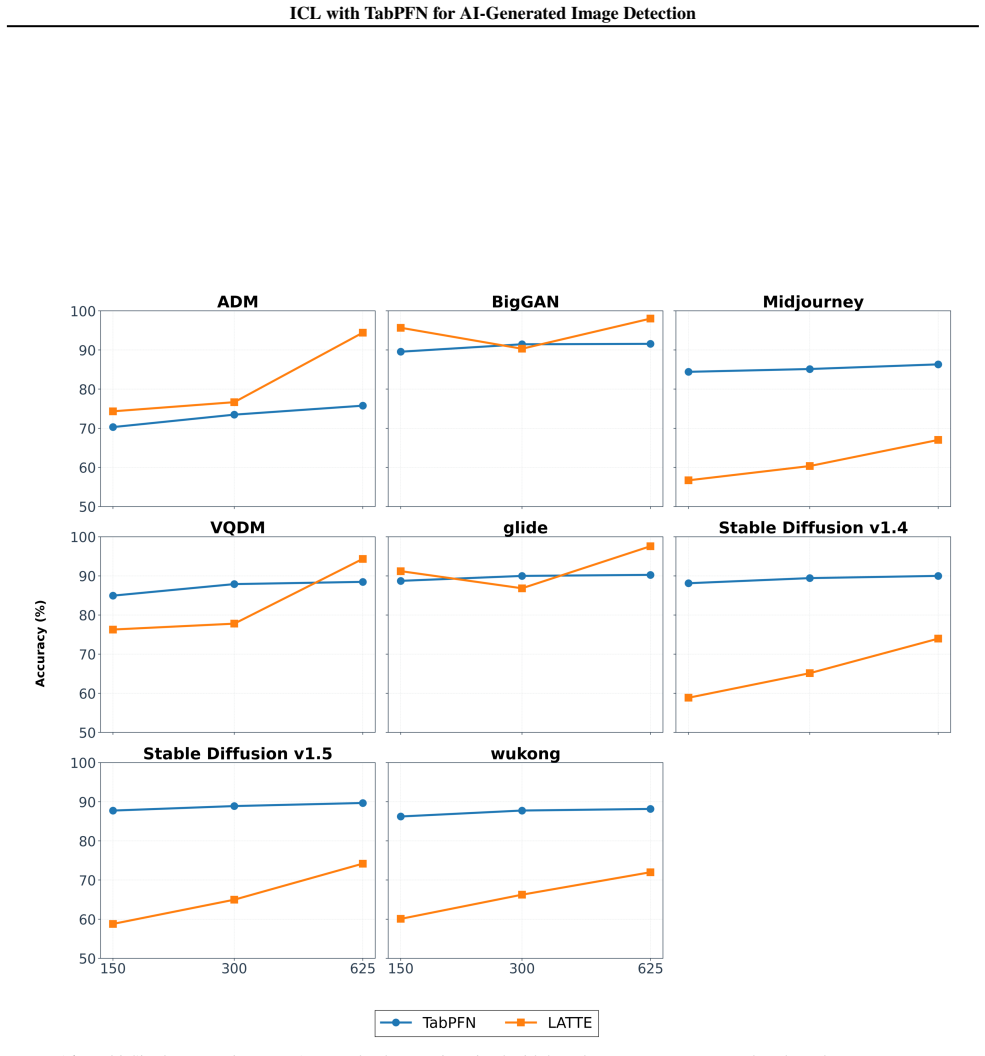
DINOv3-PCA-TabPFN outperforms LATTE by up to 8.2 percent in the low-data regime and in cross-generator transfer settings because real/fake classification is performed by TabPFN's in-context tabular inference over fixed 500-dimensional visual feature rows instead of task-specific classifier training.
What carries the argument
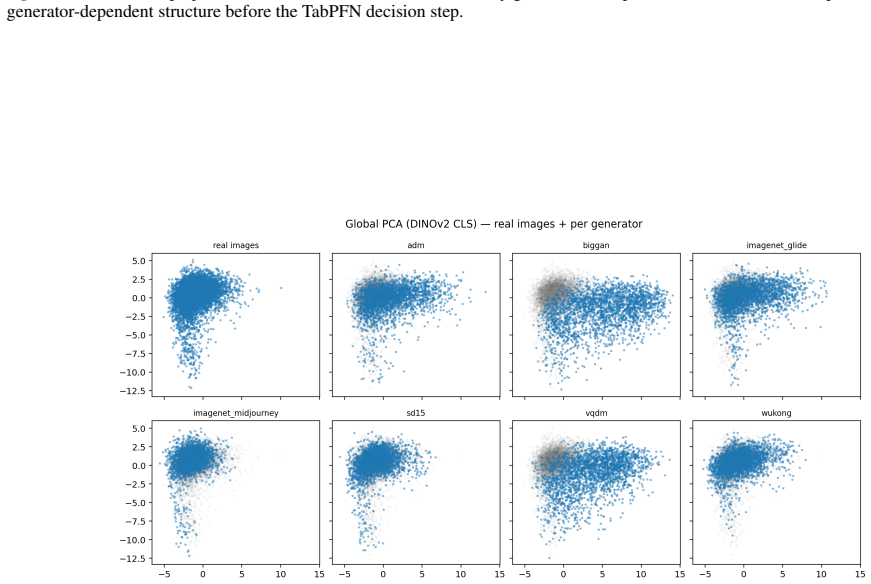
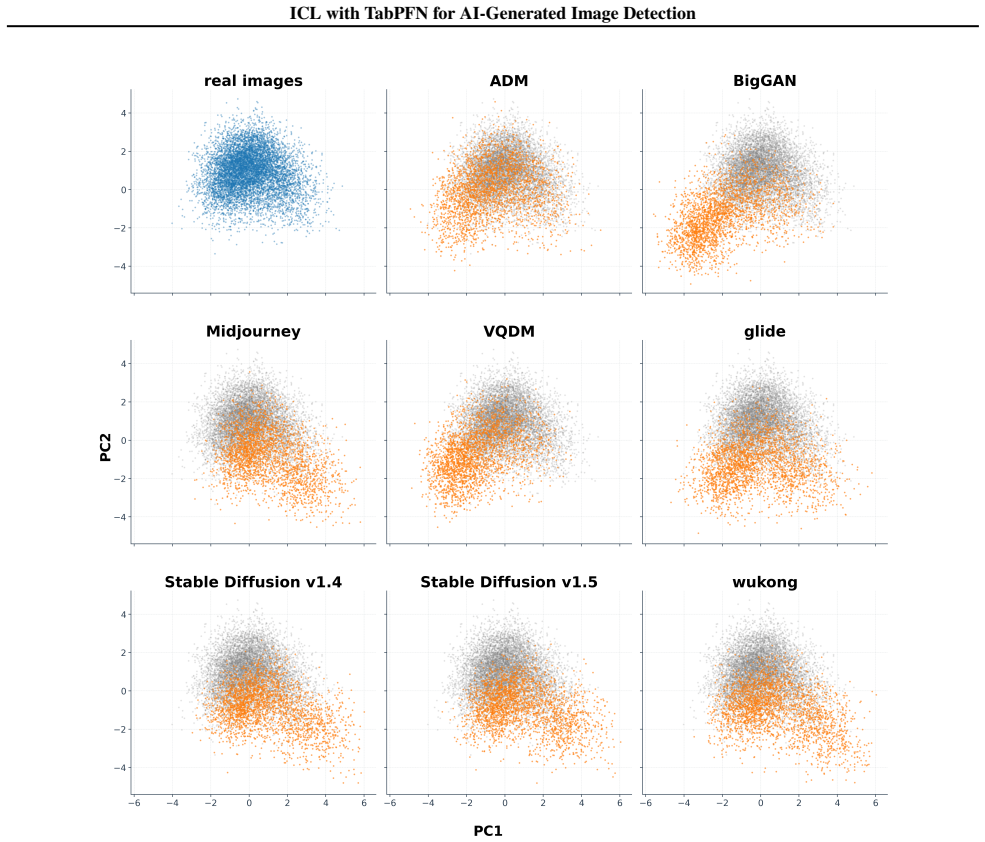
The image-to-table conversion that reduces frozen DINOv3 CLS features to 500-dimensional PCA rows and feeds them to TabPFN for in-context real/fake prediction.
If this is right
- Detector adaptation depends only on swapping the labeled context set rather than on gradient-based retraining.
- Accuracy gains appear specifically when the number of labeled samples per generator is small.
- Cross-generator generalization improves without any fine-tuning on the target generator's data.
Where Pith is reading between the lines
- The same frozen-backbone-plus-tabular-inference pipeline could be tested on other visual detection tasks that face rapid distribution shift.
- Tabular foundation models may reduce the labeled-data requirement for many forensics problems that currently rely on repeated model retraining.
Load-bearing premise
The 500-dimensional PCA projection of DINOv3 features retains enough structure to let TabPFN separate real from generated images across different generators.
What would settle it
A new generator where DINOv3-PCA-TabPFN accuracy with a small context set falls below a retrained baseline given identical labels.
Figures












read the original abstract
AI-generated image detection is a moving-target problem: detectors trained on one generator often fail when a new generator appears, and only a few labeled examples are available. We study a simple image-to-table formulation for this regime, where each image is encoded by a frozen DINOv3 backbone, its CLS feature is reduced to a 500-dimensional structured row with PCA, and TabPFN performs real/fake classification by in-context tabular inference rather than task-specific classifier training. This turns fake-image detection into low-data structured prediction over learned visual features, making detector adaptation depend on the labeled context set instead of gradient-based fine-tuning. On GenImage, LATTE, a recent state-of-the-art detector, remains stronger when many labeled samples from all generators are available, by 7.4% in the largest pooled setting, but DINOv3-PCA-TabPFN is stronger in the practically important low-data regime, outperforming LATTE by up to 8.2%, and in transfer settings where the detector must generalize from one generator to another. These results position tabular foundation models as a strong complementary adaptation mechanism for image forensics, shifting adaptation from detector retraining to lightweight in-context updates with a small labeled set of examples. Code URL: https://github.com/jpwalter30/Towards-Generalizable-Detection-of-AI-Generated-Images
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a simple image-to-table pipeline—encoding images via a frozen DINOv3 backbone, reducing the CLS token to a 500-dimensional vector with PCA, and performing real/fake classification with TabPFN via in-context tabular inference—outperforms the LATTE baseline by up to 8.2% in low-data regimes and in cross-generator transfer settings on GenImage, while trailing LATTE by 7.4% in the largest pooled high-data setting. Adaptation is achieved by supplying a small labeled context set rather than gradient-based fine-tuning.
Significance. If the empirical gains hold under proper statistical controls, the work establishes tabular foundation models as a viable complementary mechanism for low-data, generalizable AI-image detection. It shifts the adaptation burden from model retraining to lightweight in-context updates and supplies reproducible code, which strengthens the contribution for the forensics community.
major comments (3)
- [Abstract / experimental results] Abstract and experimental results section: the reported deltas (8.2% low-data, 7.4% pooled) are presented without error bars, exact per-regime sample counts, number of random seeds, or cross-validation details, preventing verification of whether the gains are statistically reliable or sensitive to the particular low-data splits.
- [Methods (PCA step)] Methods (PCA reduction step): no cumulative explained variance ratio is reported for the 500-component PCA of DINOv3 CLS features, nor is there an ablation on component count. Because the central claim rests on the 500-dimensional projection retaining sufficient generator-discriminative structure for TabPFN in-context inference (especially in transfer), the absence of this diagnostic directly undermines confidence in the 8.2% and transfer gains.
- [Experiments / ablation studies] Experimental protocol: the manuscript supplies no analysis of which variance directions are discarded by the fixed 500-component cutoff and whether those directions contain subtle generator artifacts critical for cross-generator generalization, leaving the weakest assumption untested.
minor comments (2)
- [Abstract] The abstract states 'up to 8.2%' without clarifying whether this is the maximum across all low-data regimes or a specific setting; a table or figure reference would improve clarity.
- [Experiments] The code URL is provided, which is a strength, but the manuscript does not state the exact TabPFN context-set sizes used in each low-data experiment.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that add the requested statistical and methodological details.
read point-by-point responses
-
Referee: [Abstract / experimental results] Abstract and experimental results section: the reported deltas (8.2% low-data, 7.4% pooled) are presented without error bars, exact per-regime sample counts, number of random seeds, or cross-validation details, preventing verification of whether the gains are statistically reliable or sensitive to the particular low-data splits.
Authors: We agree that the current manuscript lacks error bars, exact sample counts per regime, number of random seeds, and cross-validation details. In the revision we will report means and standard deviations over at least five random seeds, specify the precise number of labeled examples in each low-data regime, document the splitting procedure, and include these statistics in both the abstract and experimental results section. revision: yes
-
Referee: [Methods (PCA step)] Methods (PCA reduction step): no cumulative explained variance ratio is reported for the 500-component PCA of DINOv3 CLS features, nor is there an ablation on component count. Because the central claim rests on the 500-dimensional projection retaining sufficient generator-discriminative structure for TabPFN in-context inference (especially in transfer), the absence of this diagnostic directly undermines confidence in the 8.2% and transfer gains.
Authors: We acknowledge that the manuscript does not report the cumulative explained variance ratio for the 500-component PCA nor provide an ablation on the number of components. In the revised version we will add the cumulative explained variance for the chosen 500 components and include an ablation study varying the component count (e.g., 100, 300, 500, 1000) with corresponding performance metrics on the low-data and transfer settings. revision: yes
-
Referee: [Experiments / ablation studies] Experimental protocol: the manuscript supplies no analysis of which variance directions are discarded by the fixed 500-component cutoff and whether those directions contain subtle generator artifacts critical for cross-generator generalization, leaving the weakest assumption untested.
Authors: We agree that the manuscript does not analyze the variance directions discarded by the 500-component cutoff. In the revision we will add an analysis comparing the discriminative power (e.g., via feature importance or transfer performance) of the retained versus discarded components to assess whether critical generator artifacts are lost. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential reductions
full rationale
The manuscript contains no equations, derivations, fitted parameters presented as predictions, or self-citation chains that bear the central claim. The method (DINOv3 CLS features + 500-dim PCA + TabPFN in-context classification) is described procedurally and evaluated via direct empirical comparison to the external baseline LATTE on GenImage. All reported gains (e.g., +8.2% in low-data regime) are experimental outcomes, not reductions to the inputs by construction. The PCA step is a fixed preprocessing choice whose adequacy is an empirical question, not a definitional loop. This is the normal case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- PCA target dimension
axioms (1)
- domain assumption DINOv3 CLS features contain information sufficient to distinguish real from generated images after linear PCA reduction.
Reference graph
Works this paper leans on
-
[1]
and Lim, Jongwoo and Lin, Ruei-Sung and Yang, Ming-Hsuan , title =
Ross, David A. and Lim, Jongwoo and Lin, Ruei-Sung and Yang, Ming-Hsuan , title =. International Journal of Computer Vision , volume =. 2008 , month =. doi:10.1007/s11263-007-0075-7 , url =
-
[2]
and Pouget-Abadie, Jean and Mirza, Mehdi and Xu, Bing and Warde-Farley, David and Ozair, Sherjil and Courville, Aaron and Bengio, Yoshua , title =
Goodfellow, Ian J. and Pouget-Abadie, Jean and Mirza, Mehdi and Xu, Bing and Warde-Farley, David and Ozair, Sherjil and Courville, Aaron and Bengio, Yoshua , title =. Advances in Neural Information Processing Systems , volume =. 2014 , url =
2014
-
[3]
Brock, Andrew and Donahue, Jeff and Simonyan, Karen , booktitle=
-
[4]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =. 2016 , url =
2016
-
[5]
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and others , booktitle=
-
[6]
Advances in Neural Information Processing Systems , volume =
Dhariwal, Prafulla and Nichol, Alexander , title =. Advances in Neural Information Processing Systems , volume =. 2021 , url =
2021
-
[7]
Proceedings of the 39th International Conference on Machine Learning , pages =
Nichol, Alexander Quinn and Dhariwal, Prafulla and Ramesh, Aditya and Shyam, Pranav and Mishkin, Pamela and McGrew, Bob and Sutskever, Ilya and Chen, Mark , title =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2022 , url =
2022
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Gu, Shuyang and Chen, Dong and Bao, Jianmin and Wen, Fang and Zhang, Bo and Chen, Dongdong and Yuan, Lu and Guo, Baining , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2022 , url =
2022
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Liu, Zhuang and Mao, Hanzi and Wu, Chao-Yuan and Feichtenhofer, Christoph and Darrell, Trevor and Xie, Saining , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2022 , url =
2022
-
[11]
Transactions on Machine Learning Research , year=
Oquab, Maxime and Darcet, Timoth. Transactions on Machine Learning Research , year=
-
[12]
International Conference on Learning Representations , year =
Hollmann, Noah and M. International Conference on Learning Representations , year =
-
[13]
Advances in Neural Information Processing Systems , volume =
Zhu, Mingjian and Chen, Hanting and Yan, Qiangyu and Huang, Xudong and Lin, Guanyu and Li, Wei and Tu, Zhijun and Hu, Hailin and Hu, Jie and Wang, Yunhe , title =. Advances in Neural Information Processing Systems , volume =. 2023 , note =
2023
-
[14]
Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops , pages =
Epstein, Dave and Jain, Ishan and Wang, Oliver and Zhang, Richard , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops , pages =. 2023 , url =
2023
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages =
Cozzolino, Davide and Poggi, Giovanni and Corvi, Riccardo and Nie. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages =. 2024 , url =
2024
-
[16]
Yu, Ning and Davis, Larry S. and Fritz, Mario , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =. 2019 , publisher =. doi:10.1109/ICCV.2019.00765 , isbn =
-
[17]
Sim. arXiv preprint arXiv:2508.10104 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Vasilcoiu, Ana and Najdenkoska, Ivona and Geradts, Zeno and Worring, Marcel , journal=
-
[19]
ACM Computing Surveys , volume =
Pei, Gan and Zhang, Jiangning and Hu, Menghan and Zhang, Zhenyu and Wang, Chengjie and Wu, Yunsheng and Zhai, Guangtao and Yang, Jian and Tao, Dacheng , title =. ACM Computing Surveys , volume =. 2026 , publisher =. doi:10.1145/3801962 , url =
-
[20]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages =
Yermakov, Andrii and Cech, Jan and Matas, Jiri and Fritz, Mario , title =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages =. 2026 , url =
2026
-
[21]
Computer Science Review , volume =
Mahara, Arpan and Rishe, Naphtali , title =. Computer Science Review , volume =. 2026 , doi =
2026
-
[22]
URL https://www.nature.com/articles/ s41586-024-08328-6
Hollmann, Noah and M. Nature , volume =. 2025 , month =. doi:10.1038/s41586-024-08328-6 , url =
-
[23]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Grinsztajn, L. arXiv preprint arXiv:2511.08667 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
2026 , url =
Oei, Victor and Schmalfuss, Jenny and Mehl, Lukas and Bartsch, Madlen and Agnihotri, Shashank and Keuper, Margret and Bulling, Andreas and Bruhn, Andres , booktitle =. 2026 , url =
2026
-
[25]
2026 , url =
Basu, Abhipsa and Singh, Mohana and Agnihotri, Shashank and Keuper, Margret and Radhakrishnan, Venkatesh Babu , booktitle =. 2026 , url =
2026
-
[26]
Synthetic Data for Computer Vision Workshop @ CVPR 2025 , year =
Agnihotri, Shashank and Schader, David and Sharei, Nico and Ka. Synthetic Data for Computer Vision Workshop @ CVPR 2025 , year =
2025
-
[27]
2025 , url =
Agnihotri, Shashank and Jakubassa, Jonas and Dey, Priyam and Goyal, Sachin and Schiele, Bernt and Radhakrishnan, Venkatesh Babu and Keuper, Margret , booktitle =. 2025 , url =
2025
-
[28]
Jung, Steffen and Keuper, Margret , booktitle =
-
[29]
2024 , url =
Gavrikov, Paul and Agnihotri, Shashank and Keuper, Margret and Keuper, Janis , booktitle =. 2024 , url =
2024
-
[30]
Agnihotri, Shashank and Schader, David and Jakubassa, Jonas and Sharei, Nico and Kral, Simon and Weber, Ruben and Keuper, Margret and others , journal =
-
[31]
2025 , url =
Agnihotri, Shashank and Caspary, Julian Yuya and Schwarz, Luca and Gao, Xinyan and Schmalfuss, Jenny and Bruhn, Andres and Keuper, Margret , journal =. 2025 , url =
2025
-
[32]
Poggi, Nicolas and Agnihotri, Shashank and Keuper, Margret , journal =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.