MMDG-Bench: A Benchmark for Multimodal Domain Generalization
Pith reviewed 2026-06-28 18:48 UTC · model grok-4.3
The pith
Structured pairings of a unified multi-modal setup with five domain generalization techniques in two orderings frequently outperform existing state-of-the-art methods on unseen domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
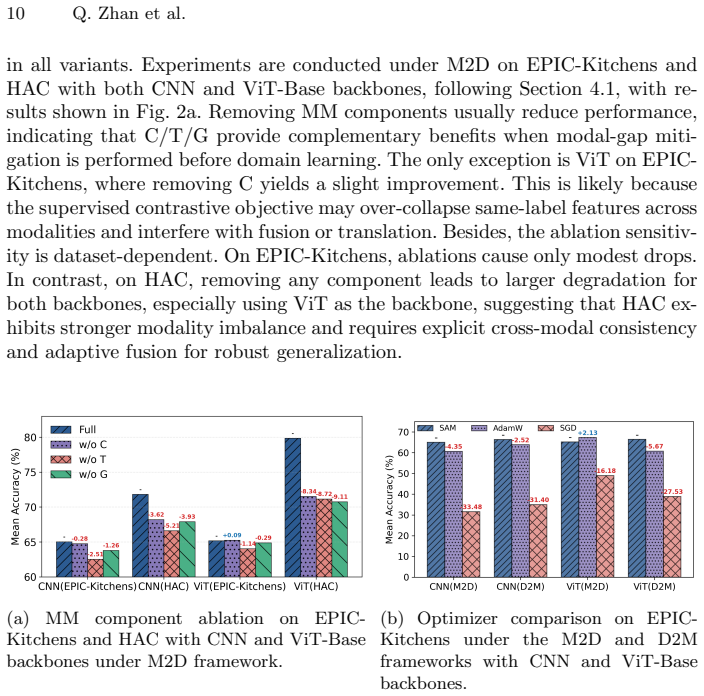
We introduce MMDG-Bench featuring DG-then-MML and MML-then-DG frameworks along with unified protocols across tasks. By instantiating ten MMDG baselines through pairing a unified MML configuration with five DG techniques under both orderings, we demonstrate that these structured combinations frequently outperform existing state-of-the-art methods. Our analysis yields three key insights: integrating DG techniques provides consistent generalization gains across various backbones whereas non-DG methods are highly sensitive to backbone shifts; the optimal framework choice depends on inter-modal stability with D2M excelling when modal relations are stable across domains while M2D is more robust to
What carries the argument
The D2M (DG then MML) and M2D (MML then DG) frameworks that structure the integration of one unified multi-modal learning configuration with five domain generalization techniques.
If this is right
- Structured MMDG baselines frequently outperform existing state-of-the-art methods.
- Integrating DG techniques provides consistent generalization gains across various backbones, whereas non-DG methods are highly sensitive to backbone shifts.
- The optimal framework choice depends on inter-modal stability: D2M excels when modal relations are stable across domains, while M2D is more robust to cross-domain relational variance.
- Stronger backbones yield amplified performance dividends when integrated into the structured frameworks.
Where Pith is reading between the lines
- Testing the same frameworks on tasks with greater modal variance, such as medical imaging, could show whether the stability-based ordering rule holds more broadly.
- Measuring inter-modal stability directly might allow automatic selection between D2M and M2D without exhaustive search.
- The amplified gains from stronger backbones suggest that scaling model capacity inside these frameworks could produce larger robustness improvements than scaling alone.
- Releasing the benchmark code enables direct comparison of new DG or MML techniques against the ten baselines rather than isolated SOTA numbers.
Load-bearing premise
The two selected tasks and the specific choice of one MML configuration paired with five DG techniques are representative enough to support general claims about framework superiority.
What would settle it
Running the same ten baselines on a new task or additional unseen domains and finding they no longer outperform state-of-the-art methods, or that the three reported insights on gains, ordering, and backbones fail to hold.
Figures

read the original abstract
Multi-modal Domain Generalization (MMDG) seeks to leverage complementary modalities to enhance model robustness on unseen domains. Despite extensive progress in Multi-modal Learning (MML) and Domain Generalization (DG) as individual fields, their systematic integration remains under-explored. Current MMDG research is largely confined to action recognition and lacks standardized evaluation protocols. To address this, we introduce MMDG-Bench, a comprehensive benchmark featuring two foundational frameworks: DG then MML (D2M) and MML then DG (M2D). We provide unified experimental protocols across diverse tasks, including video-audio-flow action recognition and RGB-Depth-IR face anti-spoofing. By instantiating ten MMDG baselines through pairing a unified MML configuration with five DG techniques under both D2M and M2D orderings, we demonstrate that these structured combinations frequently outperform existing state-of-the-art methods, underscoring the necessity of a unified benchmarking effort. Our analysis yields three key insights: (1) Integrating DG techniques provides consistent generalization gains across various backbones, whereas non-DG methods are highly sensitive to backbone shifts; (2) The optimal framework choice depends on inter-modal stability: D2M excels when modal relations are stable across domains, while M2D is more robust to cross-domain relational variance; (3) Stronger backbones yield amplified performance dividends when integrated into our structured frameworks. MMDG-Bench provides a principled foundation and actionable design guidelines for future research in multi-modal robustness. Code is released at https://github.com/qszhan/MMDG-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MMDG-Bench, a benchmark for multi-modal domain generalization (MMDG) that defines two frameworks (D2M: DG then MML; M2D: MML then DG). It instantiates ten baselines by pairing one unified MML configuration with five DG techniques under both orderings, evaluates them on video-audio-flow action recognition and RGB-Depth-IR face anti-spoofing, and reports that these baselines frequently outperform existing SOTA methods. The work also derives three insights: DG integration yields consistent gains independent of backbone; optimal framework depends on inter-modal stability vs. relational variance; and stronger backbones amplify gains within the frameworks. Code is released.
Significance. If the empirical claims hold under broader validation, the benchmark could help standardize evaluation in an under-explored intersection of MML and DG, and the released code supports reproducibility. The structured instantiation of baselines and the three insights offer actionable guidelines, though their scope is constrained by the evaluated tasks.
major comments (1)
- [Abstract] Abstract: The central claim that the ten structured MMDG baselines 'frequently outperform existing state-of-the-art methods' and that the three reported insights are generally valid rests on results from only two task families (video-audio-flow action recognition and RGB-Depth-IR face anti-spoofing). This limited diversity is load-bearing for the assertion that a unified benchmarking effort is necessary and that the insights generalize across multimodal domain shifts; the manuscript provides no additional tasks or cross-category validation to support broader applicability.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment on evaluation scope. We address the major comment below with a commitment to textual revisions that accurately reflect the manuscript's empirical basis.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the ten structured MMDG baselines 'frequently outperform existing state-of-the-art methods' and that the three reported insights are generally valid rests on results from only two task families (video-audio-flow action recognition and RGB-Depth-IR face anti-spoofing). This limited diversity is load-bearing for the assertion that a unified benchmarking effort is necessary and that the insights generalize across multimodal domain shifts; the manuscript provides no additional tasks or cross-category validation to support broader applicability.
Authors: We agree that the empirical results and derived insights are based on two task families. These were deliberately chosen to span distinct modality sets (video-audio-flow; RGB-Depth-IR) and domain-shift regimes (cross-dataset action recognition; cross-device spoofing), which are the primary settings explored in prior MMDG literature. Nevertheless, the limited number of categories means the claims of frequent outperformance and general insight validity should be scoped to the evaluated benchmarks. We will revise the abstract to replace the unqualified phrasing with 'frequently outperform existing state-of-the-art methods on the evaluated tasks' and similarly qualify the three insights as holding under the tested conditions. A new Limitations paragraph will be added to the discussion section explicitly noting the current task coverage and encouraging extensions to additional multimodal categories (e.g., vision-language or audio-text). These changes require only textual edits and do not alter the experimental results or code release. revision: yes
Circularity Check
No circularity: empirical benchmark paper with no derivation chain
full rationale
The paper defines MMDG-Bench as an empirical evaluation framework, instantiates ten baselines via explicit pairings of one MML config with five DG methods under D2M/M2D orderings, and reports performance on two task families. No equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citation chains appear in the provided text. All claims reduce directly to the described experimental protocol and released code rather than to any input by construction. This is a standard benchmark contribution whose central results are externally falsifiable via the public repository.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Carlucci, F.M., D’Innocente, A., Bucci, S., Caputo, B., Tommasi, T.: Domain gen- eralization by solving jigsaw puzzles. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2229–2238 (2019)
2019
-
[2]
In: European Conference on Computer Vision
Cha, J., Lee, K., Park, S., Chun, S.: Domain generalization by mutual-information regularization with pre-trained models. In: European Conference on Computer Vision. pp. 440–457. Springer (2022)
2022
-
[3]
In: ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing
Chen, H., Xie, W., Vedaldi, A., Zisserman, A.: Vggsound: A large-scale audio- visual dataset. In: ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing. pp. 721–725. IEEE (2020)
2020
-
[4]
Contributors, M.: Openmmlab’s next generation video understanding toolbox and benchmark.https://github.com/open-mmlab/mmaction2(2020)
2020
-
[5]
Advances in Neural Information Processing Systems36, 78674–78695 (2023)
Dong, H., Nejjar, I., Sun, H., Chatzi, E., Fink, O.: Simmmdg: A simple and effective framework for multi-modal domain generalization. Advances in Neural Information Processing Systems36, 78674–78695 (2023)
2023
-
[6]
Advances in Neural Information Processing Systems37, 66773–66795 (2024)
Fan, Y., Xu, W., Wang, H., Guo, S.: Cross-modal representation flattening for multi-modal domain generalization. Advances in Neural Information Processing Systems37, 66773–66795 (2024)
2024
-
[7]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Feichtenhofer, C., Fan, H., Malik, J., He, K.: Slowfast networks for video recog- nition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6202–6211 (2019)
2019
-
[8]
In: International Conference on Learning Representations (2021)
Foret, P., Kleiner, A., Mobahi, H., Neyshabur, B.: Sharpness-aware minimization for efficiently improving generalization. In: International Conference on Learning Representations (2021)
2021
-
[9]
IEEE Transactions on Information Forensics and Security15, 42–55 (2019)
George, A., Mostaani, Z., Geissenbuhler, D., Nikisins, O., Anjos, A., Marcel, S.: Biometric face presentation attack detection with multi-channel convolutional neu- ral network. IEEE Transactions on Information Forensics and Security15, 42–55 (2019)
2019
-
[10]
Gong, Y., Chung, Y.A., Glass, J.: AST: Audio Spectrogram Transformer. In: Proc. Interspeech 2021. pp. 571–575 (2021).https://doi.org/10.21437/Interspeech. 2021-698
-
[11]
In: International Conference on Machine Learning
Gower, R.M., Loizou, N., Qian, X., Sailanbayev, A., Shulgin, E., Richt´ arik, P.: Sgd: General analysis and improved rates. In: International Conference on Machine Learning. pp. 5200–5209 (2019)
2019
-
[12]
Advances in Neural Information Processing Systems 19(2006)
Gretton, A., Borgwardt, K., Rasch, M., Sch¨ olkopf, B., Smola, A.: A kernel method for the two-sample-problem. Advances in Neural Information Processing Systems 19(2006)
2006
-
[13]
In: Interna- tional Conference on Learning Representations (2021)
Gulrajani, I., Lopez-Paz, D.: In search of lost domain generalization. In: Interna- tional Conference on Learning Representations (2021)
2021
-
[14]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 770–778 (2016)
2016
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
Huang, H., Xia, Y., Zhou, S., Wang, H., Wang, S., Zhao, Z.: Bridging domain generalization to multimodal domain generalization via unified representations. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
2025
-
[16]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Ji, H., Lee, J., Park, E.: Alignment and distillation: A robust framework for mul- timodal domain generalizable human action recognition. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 6913– 6924 (2026) MMDG-Bench 17
2026
-
[17]
In: International Conference on Machine Learning
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International Conference on Machine Learning. pp. 4904–4916. PMLR (2021)
2021
-
[18]
The Kinetics Human Action Video Dataset
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., et al.: The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Psychological Bulletin85(2), 410 (1978)
Knapp, T.R.: Canonical correlation analysis: A general parametric significance- testing system. Psychological Bulletin85(2), 410 (1978)
1978
-
[20]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, D., Yang, Y., Song, Y.Z., Hospedales, T.: Learning to generalize: Meta-learning for domain generalization. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 32 (2018)
2018
-
[21]
In: Proceedings of the IEEE International Conference on Computer Vision
Li, D., Yang, Y., Song, Y.Z., Hospedales, T.M.: Deeper, broader and artier domain generalization. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 5542–5550 (2017)
2017
-
[22]
In: ACM International Conference on Multimedia
Li, H., Wan, H., Zhang, L., Jiu, M., Li, S., Xu, M., Khan, M.H.: Towards robust multimodal domain generalization via modality-domain joint adversarial training. In: ACM International Conference on Multimedia. pp. 180–188 (2025)
2025
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lin, X., Wang, S., Cai, R., Liu, Y., Fu, Y., Tang, W., Yu, Z., Kot, A.: Suppress and rebalance: Towards generalized multi-modal face anti-spoofing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 211–221 (2024)
2024
-
[24]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Liu, A., Tan, Z., Wan, J., Escalera, S., Guo, G., Li, S.Z.: Casia-surf cefa: A bench- mark for multi-modal cross-ethnicity face anti-spoofing. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 1179– 1187 (2021)
2021
-
[25]
In: International Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019)
2019
-
[26]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F., et al.: Fixing weight decay regularization in adam. arXiv preprint arXiv:1711.051015(5), 5 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
In: Proceedings of the IEEE International Conference on Computer Vision
Motiian, S., Piccirilli, M., Adjeroh, D.A., Doretto, G.: Unified deep supervised domain adaptation and generalization. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 5715–5725 (2017)
2017
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Munro, J., Damen, D.: Multi-modal domain adaptation for fine-grained action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 122–132 (2020)
2020
-
[29]
Advances in Neural Information Processing Systems 34, 14200–14213 (2021)
Nagrani, A., Yang, S., Arnab, A., Jansen, A., Schmid, C., Sun, C.: Attention bottle- necks for multimodal fusion. Advances in Neural Information Processing Systems 34, 14200–14213 (2021)
2021
-
[30]
In: Proceedings of the European Conference on Computer Vision
Owens, A., Efros, A.A.: Audio-visual scene analysis with self-supervised multisen- sory features. In: Proceedings of the European Conference on Computer Vision. pp. 631–648 (2018)
2018
-
[31]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision
Planamente, M., Plizzari, C., Alberti, E., Caputo, B.: Domain generalization through audio-visual relative norm alignment in first person action recognition. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision. pp. 1807–1818 (2022)
2022
-
[32]
In: International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning. pp. 8748–8763 (2021) 18 Q. Zhan et al
2021
-
[33]
IEEE Transactions on Neural Networks10(5), 988–999 (1999)
Vapnik, V.N.: An overview of statistical learning theory. IEEE Transactions on Neural Networks10(5), 988–999 (1999)
1999
-
[34]
IEEE Transactions on Knowledge and Data Engineering35(8), 8052–8072 (2022)
Wang, J., Lan, C., Liu, C., Ouyang, Y., Qin, T., Lu, W., Chen, Y., Zeng, W., Yu, P.S.: Generalizing to unseen domains: A survey on domain generalization. IEEE Transactions on Knowledge and Data Engineering35(8), 8052–8072 (2022)
2022
-
[35]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, L., Huang, B., Zhao, Z., Tong, Z., He, Y., Wang, Y., Wang, Y., Qiao, Y.: Videomae v2: Scaling video masked autoencoders with dual masking. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14549–14560 (2023)
2023
-
[36]
Wang, W., Tran, D., Feiszli, M.: What makes training multi-modal classification networks hard? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12695–12705 (2020)
2020
-
[37]
Proceedings of the AAAI Conference on Artificial Intelligence (2026)
Wang, X., Cheng, Z., Zhong, T., Chen, L., Zhou, F.: Modality-balanced collabora- tive distillation for multi-modal domain generalization. Proceedings of the AAAI Conference on Artificial Intelligence (2026)
2026
-
[38]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(10), 12113– 12132 (2023)
Xu, P., Zhu, X., Clifton, D.A.: Multimodal learning with transformers: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence45(10), 12113– 12132 (2023)
2023
-
[39]
In: Findings of the Association for Computational Linguistics: ACL 2022
Yao, Y., Mihalcea, R.: Modality-specific learning rates for effective multimodal additive late-fusion. In: Findings of the Association for Computational Linguistics: ACL 2022. pp. 1824–1834 (2022)
2022
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, Z., Liu, A., Zhao, C., Cheng, K.H., Cheng, X., Zhao, G.: Flexible-modal face anti-spoofing: A benchmark. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6346–6351 (2023)
2023
-
[41]
Journal of the American Statistical Association67(339), 578–580 (1972)
Zar, J.H.: Significance testing of the spearman rank correlation coefficient. Journal of the American Statistical Association67(339), 578–580 (1972)
1972
-
[42]
International Conference on Learning Representations (2018)
Zhang, H., Cisse, M., Dauphin, Y.N., Lopez-Paz, D.: Mixup: Beyond empirical risk minimization. International Conference on Learning Representations (2018)
2018
-
[43]
IEEE Transactions on Biometrics, Behavior, and Identity Science2(2), 182–193 (2020)
Zhang, S., Liu, A., Wan, J., Liang, Y., Guo, G., Escalera, S., Escalante, H.J., Li, S.Z.: Casia-surf: A large-scale multi-modal benchmark for face anti-spoofing. IEEE Transactions on Biometrics, Behavior, and Identity Science2(2), 182–193 (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.