Towards Understanding Modality Interaction in Multimodal Language Models via Partial Information Decomposition
Pith reviewed 2026-06-28 17:38 UTC · model grok-4.3
The pith
Partial Information Decomposition separates unique, redundant, and synergistic contributions from vision and language in multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
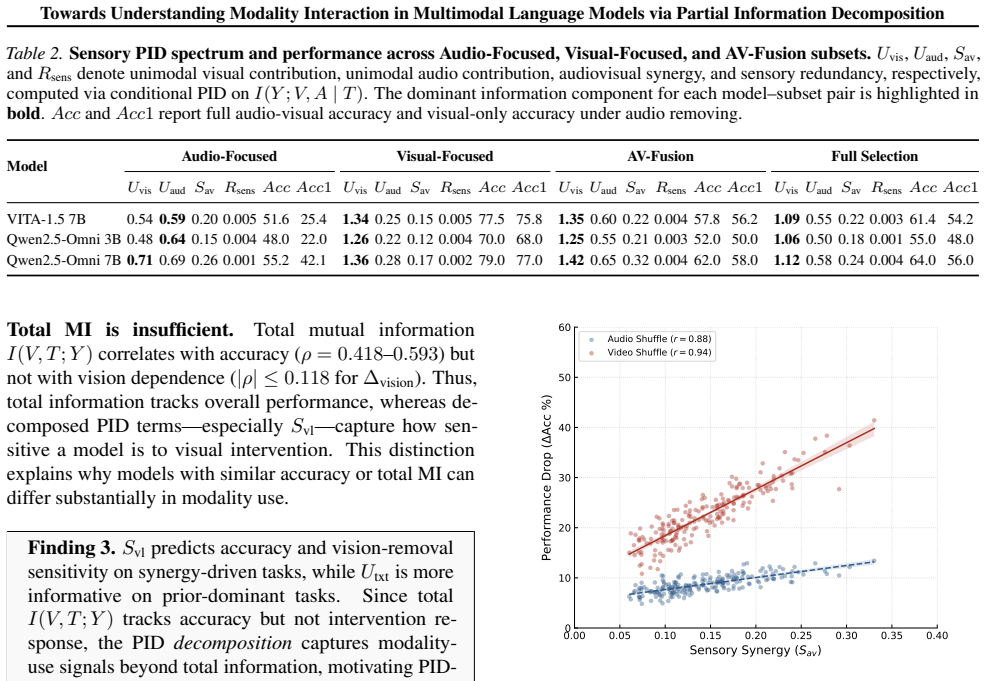
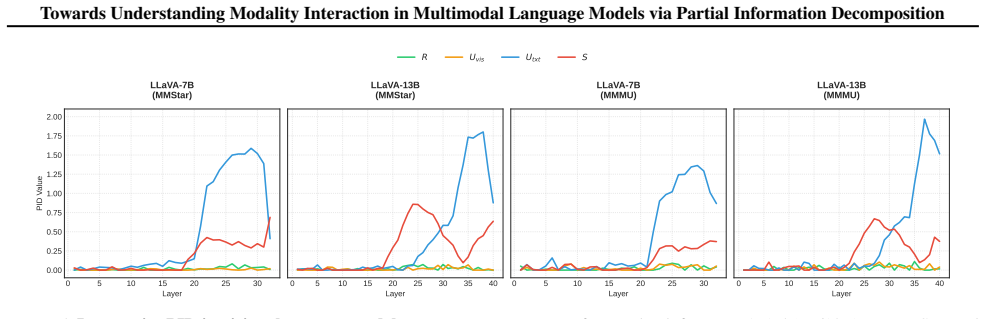
Applying PID to model outputs shows that reasoning-oriented tasks exhibit high synergy between sensory and linguistic inputs whereas expert and knowledge-oriented tasks show stronger language-unique reliance; these profiles generalize across model families and predict sensitivity to modality-level interventions, while Sensory PID applied to omni-modal models identifies a visual dominance bottleneck even on audio-visual tasks.
What carries the argument
Partial Information Decomposition (PID) applied at the decision level to quantify unique, redundant, and synergistic information contributions from each input modality.
If this is right
- Reasoning and grounding tasks tend to exhibit high synergy between modalities.
- Expert and knowledge-oriented tasks show stronger reliance on language-unique information.
- Modality-use profiles generalize across model families and predict sensitivity to modality interventions.
- PID-guided reweighting yields initial gains on multimodal reasoning and grounding tasks.
- Sensory PID reveals visual information dominance as a bottleneck in tri-modal fusion.
Where Pith is reading between the lines
- This could support task classification by information requirements that applies across architectures.
- Reweighting informed by PID profiles might reduce the cost of modality-specific fine-tuning.
- Extending the method to additional modalities could expose systematic underuse of certain inputs in current systems.
Load-bearing premise
The PID quantities computed from model outputs on existing benchmarks faithfully reflect the underlying causal contributions of each modality rather than artifacts of the chosen tasks or output format.
What would settle it
Computing PID profiles on the same models but with a new benchmark that uses different output formats or task structures and finding that the reported modality-use patterns and intervention predictions no longer hold.
Figures



read the original abstract
Understanding modality interaction in multimodal large language models (MLLMs) is central to reliable deployment. We introduce Partial Information Decomposition (PID) as a decision-level framework that separates unique, redundant, and synergistic contributions of sensory and linguistic inputs, beyond representation alignment and outcome-based evaluation. Across vision--language benchmarks, PID reveals recurring modality-use profiles: reasoning and grounding-oriented tasks tend to exhibit high synergy, whereas expert and knowledge-oriented tasks show stronger language-unique reliance. These profiles generalize across model families and predict sensitivity to modality-level interventions. We further extend PID to tri-modal systems with Sensory PID, treating language as a control variable to decompose video--audio information gain. Applied to omni-modal models, Sensory PID reveals a sensory synergy bottleneck dominated by visual information even on audio--visual fusion tasks. Finally, PID-guided reweighting provides initial evidence for improving multimodal reasoning and grounding performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Partial Information Decomposition (PID) as a decision-level framework to separate unique, redundant, and synergistic contributions of sensory and linguistic inputs in multimodal LLMs. It reports recurring modality-use profiles across vision-language benchmarks (high synergy for reasoning/grounding tasks, language-unique reliance for expert/knowledge tasks), shows these profiles generalize across model families and predict sensitivity to modality interventions, extends the approach to tri-modal Sensory PID (with language as control), identifies a visual-dominated sensory synergy bottleneck, and provides initial evidence that PID-guided reweighting can improve multimodal reasoning and grounding performance.
Significance. If the PID quantities are shown to capture intrinsic causal modality contributions rather than benchmark artifacts, the framework would supply a new information-theoretic tool for analyzing and intervening on modality interactions that goes beyond representation alignment or outcome metrics. The reported cross-family generalization, predictive validity for interventions, and reweighting results would constitute a substantive contribution to understanding multimodal model behavior.
major comments (2)
- [Evaluation and Results] The central claim that PID reveals intrinsic modality-use profiles (rather than artifacts of task design or output format) is load-bearing for all downstream results on generalization and intervention sensitivity. The manuscript must include an explicit invariance test: recompute PID on semantically equivalent but format-altered prompts (e.g., rephrased questions or changed answer formats) and demonstrate stability of the unique/redundant/synergistic quantities; without this, the recurring profiles could be downstream of benchmark construction.
- [Abstract and Evaluation] Profiles are derived from the same benchmarks subsequently used to validate generalization across model families and to predict intervention sensitivity. This creates a circularity risk: the task groupings that define the profiles may already encode the modality requirements that later appear as predictive patterns. An independent hold-out set of tasks or an a priori task taxonomy (not derived from the PID outputs) is needed to break the dependence.
minor comments (2)
- [Abstract] The abstract states results but supplies no equations for the PID decomposition, no dataset or model details, and no description of controls, making it impossible for a reader to assess whether the reported profiles are supported by the computation.
- [Tri-modal Extension] Notation for the tri-modal Sensory PID extension (language as control variable) is introduced without an explicit equation or diagram showing how the three-way decomposition is computed from model outputs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify important robustness checks that will strengthen the claims regarding intrinsic modality-use profiles. We address each below and will incorporate the requested analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Evaluation and Results] The central claim that PID reveals intrinsic modality-use profiles (rather than artifacts of task design or output format) is load-bearing for all downstream results on generalization and intervention sensitivity. The manuscript must include an explicit invariance test: recompute PID on semantically equivalent but format-altered prompts (e.g., rephrased questions or changed answer formats) and demonstrate stability of the unique/redundant/synergistic quantities; without this, the recurring profiles could be downstream of benchmark construction.
Authors: We agree that demonstrating invariance to prompt and output format variations is essential to support the claim that PID quantities reflect intrinsic modality interactions rather than benchmark artifacts. In the revised manuscript we will add a dedicated invariance experiment: for a representative subset of tasks we will recompute PID using semantically equivalent but rephrased questions and altered answer formats, reporting the resulting changes (or lack thereof) in unique, redundant, and synergistic values. This will directly test stability and address the concern that observed profiles may be downstream of specific task construction. revision: yes
-
Referee: [Abstract and Evaluation] Profiles are derived from the same benchmarks subsequently used to validate generalization across model families and to predict intervention sensitivity. This creates a circularity risk: the task groupings that define the profiles may already encode the modality requirements that later appear as predictive patterns. An independent hold-out set of tasks or an a priori task taxonomy (not derived from the PID outputs) is needed to break the dependence.
Authors: We acknowledge the circularity risk. To break the dependence, the revised manuscript will introduce an a priori task taxonomy drawn from established multimodal evaluation literature (distinguishing reasoning/grounding tasks from knowledge/expert tasks) that is defined independently of our PID computations. We will then evaluate generalization and intervention sensitivity on a hold-out set of tasks excluded from the initial profile derivation, confirming that the reported patterns persist. These additions will be included in the updated version. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces PID as an external information-theoretic tool and applies it post-hoc to model outputs on benchmarks to identify modality profiles. No equations or steps in the provided text reduce a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction. The generalization and intervention-sensitivity observations are presented as empirical findings rather than tautological outputs of the input data definitions. The derivation remains self-contained against external benchmarks and does not invoke load-bearing self-citations or ansatzes that collapse to the target claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PID decomposition of model outputs on benchmarks separates unique, redundant, and synergistic modality contributions in a causally meaningful way.
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
National Science Review , volume=
A survey on multimodal large language models , author=. National Science Review , volume=. 2024 , publisher=
2024
-
[10]
Journal of medical Internet research , volume=
The impact of multimodal large language models on health care’s future , author=. Journal of medical Internet research , volume=. 2023 , publisher=
2023
-
[11]
arXiv preprint arXiv:2402.17385 , year=
Determinants of llm-assisted decision-making , author=. arXiv preprint arXiv:2402.17385 , year=
-
[12]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
1948
-
[13]
Advances in Neural Information Processing Systems , volume=
Quantifying & modeling multimodal interactions: An information decomposition framework , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
European conference on computer vision , pages=
Mmbench: Is your multi-modal model an all-around player? , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[15]
Advances in Neural Information Processing Systems , volume=
Are we on the right way for evaluating large vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[17]
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering
Pmc-vqa: Visual instruction tuning for medical visual question answering , author=. arXiv preprint arXiv:2305.10415 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning to answer questions in dynamic audio-visual scenarios , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
Qwen2. 5-omni technical report , author=. arXiv preprint arXiv:2503.20215 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Vita-1.5: Towards gpt-4o level real-time vision and speech interaction , author=. arXiv preprint arXiv:2501.01957 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Entropy , volume=
Quantifying unique information , author=. Entropy , volume=. 2014 , publisher=
2014
-
[25]
Advances in neural information processing systems , volume=
Sinkhorn distances: Lightspeed computation of optimal transport , author=. Advances in neural information processing systems , volume=
-
[26]
arXiv preprint arXiv:2503.13415 , year=
A comprehensive survey on multi-agent cooperative decision-making: Scenarios, approaches, challenges and perspectives , author=. arXiv preprint arXiv:2503.13415 , year=
-
[27]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
How do multimodal large language models handle complex multimodal reasoning? placing them in an extensible escape game , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[28]
arXiv preprint arXiv:2411.06284 , year=
A comprehensive survey and guide to multimodal large language models in vision-language tasks , author=. arXiv preprint arXiv:2411.06284 , year=
-
[29]
International Journal of Computer Vision , volume=
Learning to prompt for vision-language models , author=. International Journal of Computer Vision , volume=. 2022 , publisher=
2022
-
[30]
arXiv preprint arXiv:2403.17359 , year=
Chain-of-action: Faithful and multimodal question answering through large language models , author=. arXiv preprint arXiv:2403.17359 , year=
-
[31]
arXiv preprint arXiv:2306.03950 , year=
MISGENDERED: Limits of large language models in understanding pronouns , author=. arXiv preprint arXiv:2306.03950 , year=
-
[32]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[33]
Workshop on Responsibly Building the Next Generation of Multimodal Foundational Models , year=
The multi-faceted monosemanticity in multimodal representations , author=. Workshop on Responsibly Building the Next Generation of Multimodal Foundational Models , year=
-
[34]
arXiv preprint arXiv:2502.17514 , year=
Sae-v: Interpreting multimodal models for enhanced alignment , author=. arXiv preprint arXiv:2502.17514 , year=
-
[35]
ACM Transactions on Multimedia Computing, Communications and Applications , year=
Cross-Modal Attention Network with Dual Graph Learning in Multimodal Recommendation , author=. ACM Transactions on Multimedia Computing, Communications and Applications , year=
-
[36]
arXiv preprint arXiv:2509.07979 , year=
Visual representation alignment for multimodal large language models , author=. arXiv preprint arXiv:2509.07979 , year=
-
[37]
Exploring Cross-Modal Flows for Few-Shot Learning
Exploring Cross-Modal Flows for Few-Shot Learning , author=. arXiv preprint arXiv:2510.14543 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
arXiv preprint arXiv:2505.10917 , year=
VISTA: Enhancing Vision-Text Alignment in MLLMs via Cross-Modal Mutual Information Maximization , author=. arXiv preprint arXiv:2505.10917 , year=
-
[39]
arXiv preprint arXiv:2501.04561 , year=
Openomni: Advancing open-source omnimodal large language models with progressive multimodal alignment and real-time self-aware emotional speech synthesis , author=. arXiv preprint arXiv:2501.04561 , year=
-
[40]
arXiv preprint arXiv:2410.12219 , year=
Omnixr: Evaluating omni-modality language models on reasoning across modalities , author=. arXiv preprint arXiv:2410.12219 , year=
-
[41]
arXiv preprint arXiv:2502.18778 , year=
M2-omni: Advancing omni-mllm for comprehensive modality support with competitive performance , author=. arXiv preprint arXiv:2502.18778 , year=
-
[42]
arXiv preprint arXiv:2508.00576 , year=
Multishap: A shapley-based framework for explaining cross-modal interactions in multimodal ai models , author=. arXiv preprint arXiv:2508.00576 , year=
-
[43]
arXiv preprint arXiv:2510.21518 , year=
Head Pursuit: Probing Attention Specialization in Multimodal Transformers , author=. arXiv preprint arXiv:2510.21518 , year=
-
[44]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[45]
Advances in neural information processing systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in neural information processing systems , volume=
-
[46]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[47]
arXiv preprint arXiv:2506.20960 , year=
OmniEval: A Benchmark for Evaluating Omni-modal Models with Visual, Auditory, and Textual Inputs , author=. arXiv preprint arXiv:2506.20960 , year=
-
[48]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[49]
Attention is not explanation , author=. arXiv preprint arXiv:1902.10186 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[50]
Is attention interpretable? , author=. arXiv preprint arXiv:1906.03731 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[51]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Transformer interpretability beyond attention visualization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[52]
Advances in neural information processing systems , volume=
Insights on representational similarity in neural networks with canonical correlation , author=. Advances in neural information processing systems , volume=
-
[53]
arXiv preprint arXiv:2010.15327 , year=
Do wide and deep networks learn the same things? uncovering how neural network representations vary with width and depth , author=. arXiv preprint arXiv:2010.15327 , year=
-
[54]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[55]
, author=
A Comprehensive Survey on Deep Learning Multi-Modal Fusion: Methods, Technologies and Applications. , author=. Computers, Materials & Continua , volume=
-
[56]
Advances in Neural Information Processing Systems , volume=
Cambrian-1: A fully open, vision-centric exploration of multimodal llms , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Winoground: Probing vision and language models for visio-linguistic compositionality , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[58]
Entropy , volume=
Information decomposition in multivariate systems: definitions, implementation and application to cardiovascular networks , author=. Entropy , volume=. 2016 , publisher=
2016
-
[59]
2015 ieee information theory workshop (itw) , pages=
Deep learning and the information bottleneck principle , author=. 2015 ieee information theory workshop (itw) , pages=. 2015 , organization=
2015
-
[60]
Entropy , volume=
A novel approach to the partial information decomposition , author=. Entropy , volume=. 2022 , publisher=
2022
-
[61]
Brain and cognition , volume=
Partial information decomposition as a unified approach to the specification of neural goal functions , author=. Brain and cognition , volume=. 2017 , publisher=
2017
-
[62]
Entropy , volume=
The partial information decomposition of generative neural network models , author=. Entropy , volume=. 2017 , publisher=
2017
-
[63]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Evaluating object hallucination in large vision-language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[64]
2024 , eprint=
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering , author=. 2024 , eprint=
2024
-
[65]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Reefknot: A comprehensive benchmark for relation hallucination evaluation, analysis and mitigation in multimodal large language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[66]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
2025 , eprint=
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models , author=. 2025 , eprint=
2025
-
[69]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
To align or not to align: Strategic multimodal representation alignment for optimal performance , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[70]
Data Mining and Machine Learning , volume=
A Survey of Multimodal Models on Language and Vision: A Unified Modeling Perspective , author=. Data Mining and Machine Learning , volume=. 2025 , publisher=
2025
-
[71]
CoRR , volume=
Hanqi Yan and Xiangxiang Cui and Lu Yin and Paul Pu Liang and Yulan He and Yifei Wang , title=. CoRR , volume=. 2025 , month=
2025
-
[72]
Nonnegative Decomposition of Multivariate Information
Nonnegative decomposition of multivariate information , author=. arXiv preprint arXiv:1004.2515 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
Advances in Neural Information Processing Systems , volume=
Can llms reason over non-text modalities in a training-free manner? a case study with in-context representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
arXiv preprint arXiv:2505.20977 , year=
Evaluating and steering modality preferences in multimodal large language model , author=. arXiv preprint arXiv:2505.20977 , year=
-
[75]
Instruction Anchor: Dissecting the Mechanistic Dynamics of Modality Arbitration
Instruction Anchors: Dissecting the Causal Dynamics of Modality Arbitration , author=. arXiv preprint arXiv:2602.03677 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
2026 , eprint=
Beyond Unimodal Shortcuts: MLLMs as Cross-Modal Reasoners for Grounded Named Entity Recognition , author=. 2026 , eprint=
2026
-
[77]
2026 , eprint=
Instruction Anchor: Dissecting the Mechanistic Dynamics of Modality Arbitration , author=. 2026 , eprint=
2026
-
[78]
The Fourteenth International Conference on Learning Representations , year=
A Comprehensive Information-Decomposition Analysis of Large Vision-Language Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[79]
Question-guided Knowledge Graph Re-scoring and Injection for Knowledge Graph Question Answering
Zhang, Yu and Chen, Kehai and Bai, Xuefeng and Kang, Zhao and Guo, Quanjiang and Zhang, Min. Question-guided Knowledge Graph Re-scoring and Injection for Knowledge Graph Question Answering. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.524
-
[80]
Diffusion
Shaurya Rajat Dewan and Rushikesh Zawar and Prakanshul Saxena and Yingshan Chang and Andrew Luo and Yonatan Bisk , booktitle=. Diffusion. 2024 , url=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.