A Registry-Bound LLM Pipeline for Evidence-Grounded Trait Extraction across Tropical Plants, Aquatic Species, and Exotic Pets
Pith reviewed 2026-06-28 17:39 UTC · model grok-4.3
The pith
Four mechanisms—a 39-key trait registry, verbatim quotes, confidence labels, and versioning—make LLM-derived species trait records auditable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
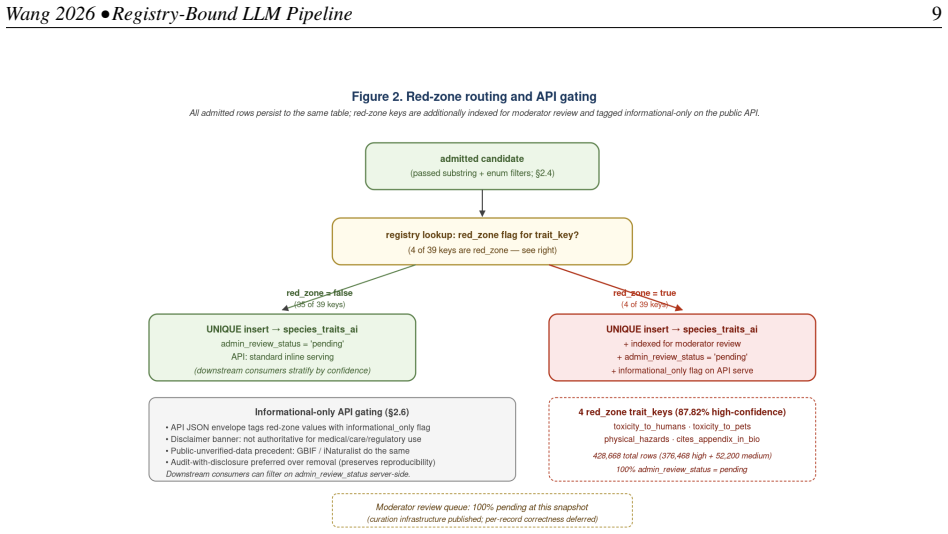
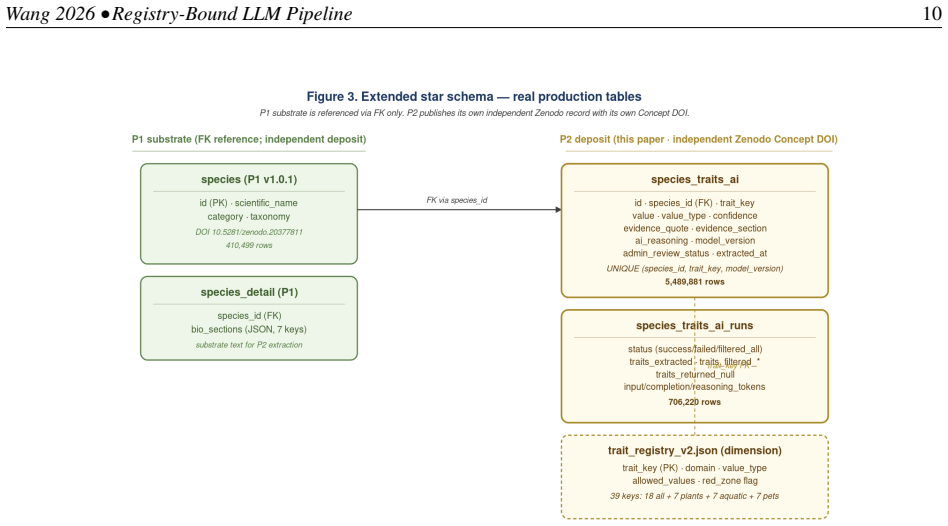
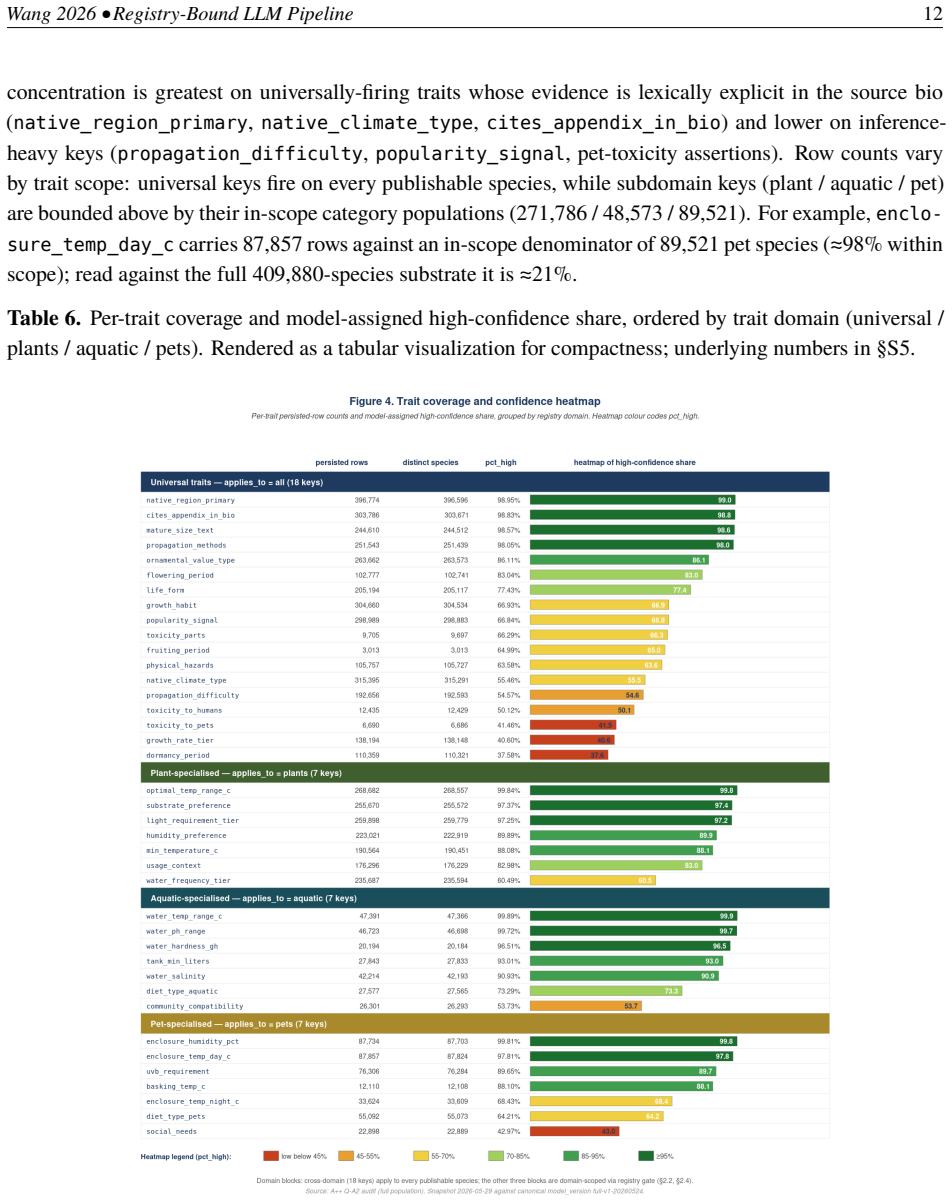
The contribution is the four-mechanism framework that renders LLM-derived rows auditable: a versioned 39-key closed-vocabulary trait registry constraining every admitted value to a typed schema; a per-row verbatim evidence quote tying each value to source text; a per-row confidence label (high or medium; low dropped pre-persist); and multi-version preservation. Applied to 409,880 species, the pipeline persisted 5,489,881 trait records with 81.57 percent at high confidence and three layers of validation showing high rates of quote support.
What carries the argument
The four-mechanism auditability framework: versioned 39-key closed-vocabulary trait registry, per-row verbatim evidence quote, per-row confidence label, and multi-version preservation.
If this is right
- The pipeline processed 409,880 species and produced records for 99.985 percent of them.
- 90.12 percent of 5,427,588 evidence-bearing rows have their quote as a verbatim source substring.
- A quote-supports-value audit on 100 stratified rows yielded 100 out of 100 successes.
- Face-validity review on 50 red-zone rows yielded 50 out of 50 acceptances.
- Per-record correctness is not claimed and requires pending human curation.
Where Pith is reading between the lines
- The same four mechanisms could be tested on text corpora outside species descriptions, such as medical case reports or legal documents, to check if auditability transfers.
- The fixed 39-key registry may systematically exclude traits that fall outside its vocabulary, creating a measurable coverage gap that future work could quantify by comparing against open-ended extractions.
- Pairing the automated pipeline with targeted human review only on low-confidence or red-zone rows could form a hybrid workflow that scales while preserving verifiability.
Load-bearing premise
Source texts contain extractable verbatim evidence that the LLM can reliably quote and the 39-key registry adequately covers traits without significant information loss or bias.
What would settle it
A check on a large sample of rows finding many cases where the quoted evidence is absent from the source text or does not support the extracted value.
Figures





read the original abstract
We describe a registry-bound large-language-model extraction pipeline producing evidence-grounded structured trait records at scale, on cultivated tropical plant, aquatic, and pet species. Four mechanisms render LLM-derived rows auditable: a versioned 39-key closed-vocabulary trait registry constraining every admitted value to a typed schema; a per-row verbatim evidence quote tying each value to source text; a per-row confidence label (high or medium; low dropped pre-persist); and multi-version preservation. Applied to 409,880 publishable species from the Tropical Species Encyclopedia, the pipeline executed 706,220 runs and persisted 5,489,881 trait records across 409,820 species (99.985%), 81.57% at high confidence. We report three validation layers in descending evidentiary strength: at full population, 90.12% of 5,427,588 evidence-bearing rows have their quote as a verbatim source substring (93.49% excluding one compliance meta-trait); a quote-supports-value audit on n=100 stratified non-red-zone rows yielded 100/100 (lower bound 96.30%); face-validity on n=50 red-zone rows yielded 50/50 Accept (lower bound 92.86%). Per-record correctness is not claimed; 100% pending human curation. The contribution is the four-mechanism framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a registry-bound LLM pipeline for extracting structured trait records from species descriptions across tropical plants, aquatic species, and exotic pets. It applies the system to 409,880 species from the Tropical Species Encyclopedia, generating 5,489,881 records via 706,220 runs. The core contribution is a four-mechanism framework for auditability: a versioned 39-key closed-vocabulary trait registry, per-row verbatim evidence quotes, high/medium confidence filtering (low dropped), and multi-version preservation. Three validation layers are reported: 90.12% quote-substring match at population scale, 100/100 on an n=100 stratified audit, and 50/50 on n=50 red-zone rows, with the explicit caveat that per-record correctness is not claimed.
Significance. If the four mechanisms reliably support auditability, the work offers a practical framework for scaling evidence-grounded LLM extraction in biodiversity data curation, where traceability and schema constraints are critical. The transparency around not claiming per-record correctness and the use of external validation metrics are positive elements. The approach could influence similar pipelines in applied NLP for scientific domains if the evidence-grounding holds beyond the reported checks.
major comments (1)
- [Abstract] Abstract (validation layers paragraph): The population-level substring check (90.12% of 5,427,588 rows) only confirms quote presence in source text and does not verify entailment of the extracted value by that quote. The direct test of quote-supports-value is restricted to an n=100 stratified audit on non-red-zone rows (100/100 success, lower bound 96.30%), which is two orders of magnitude smaller than the 5.5M persisted records and excludes the 18.43% medium-confidence records; this sample size is insufficient to support the central claim that the four mechanisms render rows auditable at scale.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the distinction between the validation layers. We address the comment below and maintain that the manuscript's central claim concerns the design of the four-mechanism framework rather than a statistical guarantee of per-record correctness.
read point-by-point responses
-
Referee: [Abstract] Abstract (validation layers paragraph): The population-level substring check (90.12% of 5,427,588 rows) only confirms quote presence in source text and does not verify entailment of the extracted value by that quote. The direct test of quote-supports-value is restricted to an n=100 stratified audit on non-red-zone rows (100/100 success, lower bound 96.30%), which is two orders of magnitude smaller than the 5.5M persisted records and excludes the 18.43% medium-confidence records; this sample size is insufficient to support the central claim that the four mechanisms render rows auditable at scale.
Authors: We agree that the population-level substring match verifies only verbatim quote presence and not entailment, and that the n=100 audit is small, excludes medium-confidence rows, and cannot support population-level statistical inference on correctness. The manuscript already states explicitly that 'Per-record correctness is not claimed; 100% pending human curation' and positions the contribution as the four-mechanism framework itself. The reported checks demonstrate that the mechanisms operate as specified (quote presence at full scale; support in the sampled non-red-zone cases), with lower-bound intervals provided to reflect sample limitations. We do not interpret the results as claiming statistical auditability at scale; the framework enables human audit rather than replacing it. The abstract wording is therefore consistent with the stated scope. No change to the manuscript is required. revision: no
Circularity Check
No circularity; descriptive applied system with independent empirical validations
full rationale
The paper describes a four-mechanism pipeline for evidence-grounded trait extraction and reports three layers of validation (population-level substring match at 90.12%, n=100 stratified audit at 100/100, n=50 red-zone face-validity at 50/50). No derivation chain, fitted parameters presented as predictions, self-citations, or ansatzes exist in the provided text. The central claim (auditable rows via registry + quote + confidence + versioning) is supported by external checks rather than reducing to its own inputs by construction. The validations are statistically independent of the pipeline definition itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be prompted to produce structured outputs with verbatim quotes from input text
Reference graph
Works this paper leans on
-
[1]
Wang, J. (2026). Tropicals.cn: Tropical Species Encyclopedia (v1.0.1) [Data set]. Zenodo. https://doi.org/10.5281/zenodo.20377811
-
[2]
Wang, J. (2026). A cross-domain tropical species dataset with Chinese vernacular names and CITES source links [Data Descriptor]. Zenodo. https://doi.org/10.5281/zenodo.20424981
-
[3]
Kattge, J., Bönisch, G., Díaz, S., Lavorel, S., Prentice, I. C., Leadley, P ., et al. (2020). TRY plant trait database — enhanced coverage and open access. Global Change Biology, 26(1), 119–188. https://doi.org/10.1111/gcb.14904. Database portal: https://www.try-db.org
-
[4]
S., Boyle, B., Casler, N., Condit, R., Donoghue, J., Durán, S
Maitner, B. S., Boyle, B., Casler, N., Condit, R., Donoghue, J., Durán, S. M., et al. (2018). The bien r package: A tool to access the Botanical Information and Ecology Network (BIEN) database. Methods in Ecology and Evolution, 9(2), 373–379. https://doi.org/10.1111/2041-210X.12861
-
[5]
Weigelt, P ., König, C., & Kreft, H. (2020). GIFT — A Global Inventory of Floras and Traits for macroe- cology and biogeography. Journal of Biogeography, 47(1), 16–43. https://doi.org/10.1111/jbi.13623
-
[6]
LoDoPaB-CT, a benchmark dataset for low-dose computed tomography reconstruction,
Falster, D., Gallagher, R., Wenk, E. H., Wright, I. J., Indiarto, D., Andrew, S. C., et al. (2021). AusTraits, a curated plant trait database for the Australian flora. Scientific Data, 8, 254. https://doi.org/10.1038/s41597- 021-01006-6
-
[7]
GBIF: The Global Biodiversity Information Facility
GBIF Secretariat (2024). GBIF: The Global Biodiversity Information Facility. https://www.gbif.org
2024
-
[8]
iNaturalist — A joint initiative of the California Academy of Sciences and the National Geographic Society
iNaturalist (2024). iNaturalist — A joint initiative of the California Academy of Sciences and the National Geographic Society. https://www.inaturalist.org
2024
-
[9]
Toxic and Non-Toxic Plants
American Society for the Prevention of Cruelty to Animals (ASPCA) (2024). Toxic and Non-Toxic Plants. https://www.aspca.org/pet-care/animal-poison-control/toxic-and-non-toxic-plants
2024
-
[10]
Species+
UNEP-WCMC and CITES Secretariat (2024). Species+. https://www.speciesplus.net
2024
-
[11]
The IUCN Red List of Threatened Species
IUCN (2024). The IUCN Red List of Threatened Species. https://www.iucnredlist.org
2024
-
[12]
Plants of the World Online (POWO)
Royal Botanic Gardens, Kew (2024). Plants of the World Online (POWO). https://powo.science.kew.org
2024
-
[13]
Wieczorek, J., Bloom, D., Guralnick, R., Blum, S., Döring, M., Giovanni, R., Robertson, T., & Vieglais, D. (2012). Darwin Core: An evolving community-developed biodiversity data standard. PLoS ONE, 7(1), e29715. https://doi.org/10.1371/journal.pone.0029715
-
[14]
Wilson, E. B. (1927). Probable Inference, the Law of Succession, and Statistical Inference. Journal of the American Statistical Association, 22(158), 209–212. https://doi.org/10.1080/01621459.1927.10502953 Supplementary Materials This appendix supplies the auxiliary material referenced from the main text: (S1) the full enumeration of the 39-key trait regi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.