Beyond Task-Agnostic: Task-Aware Grouping for Communication-Efficient Multi-Task MoE Inference
Pith reviewed 2026-06-28 17:30 UTC · model grok-4.3
The pith
Task-aware grouping of experts by family-specific co-activation cuts distributed MoE inference communication by 31 percent while keeping load balance near perfect.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
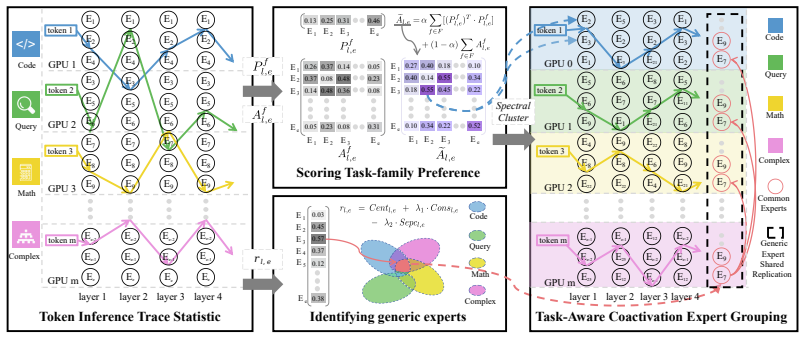
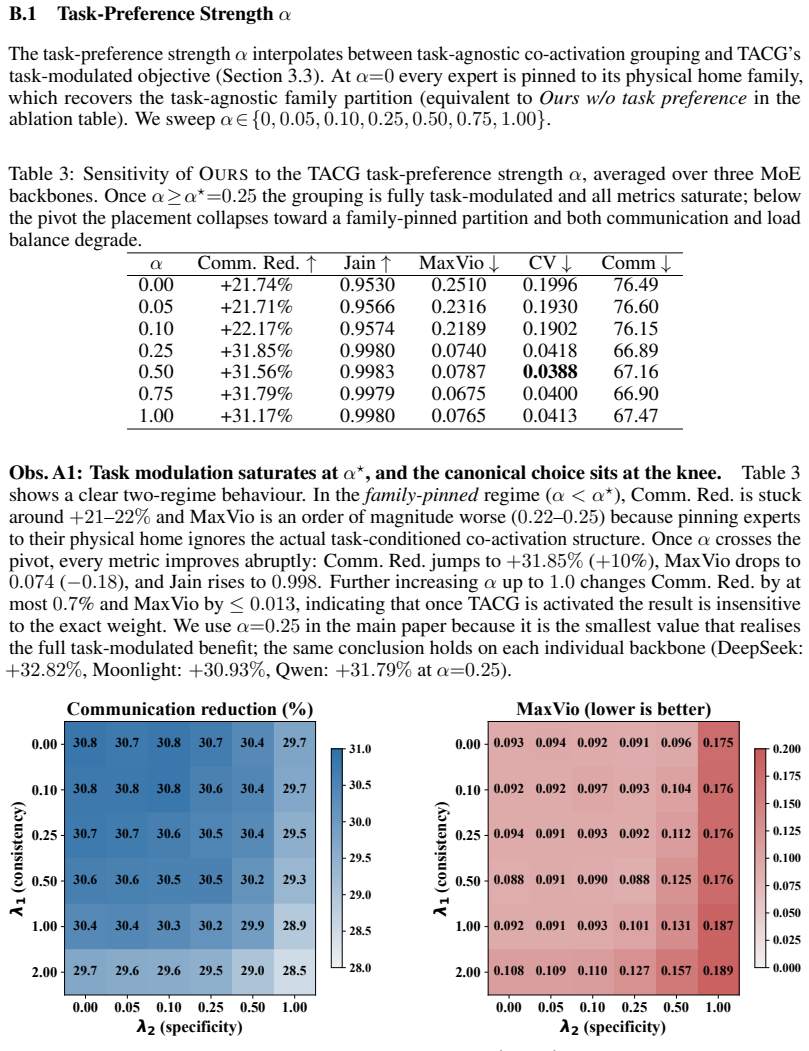
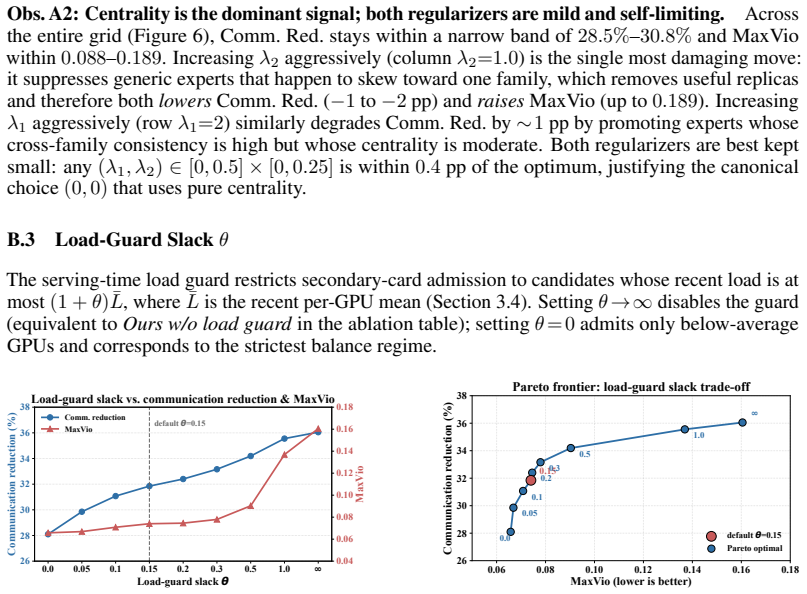
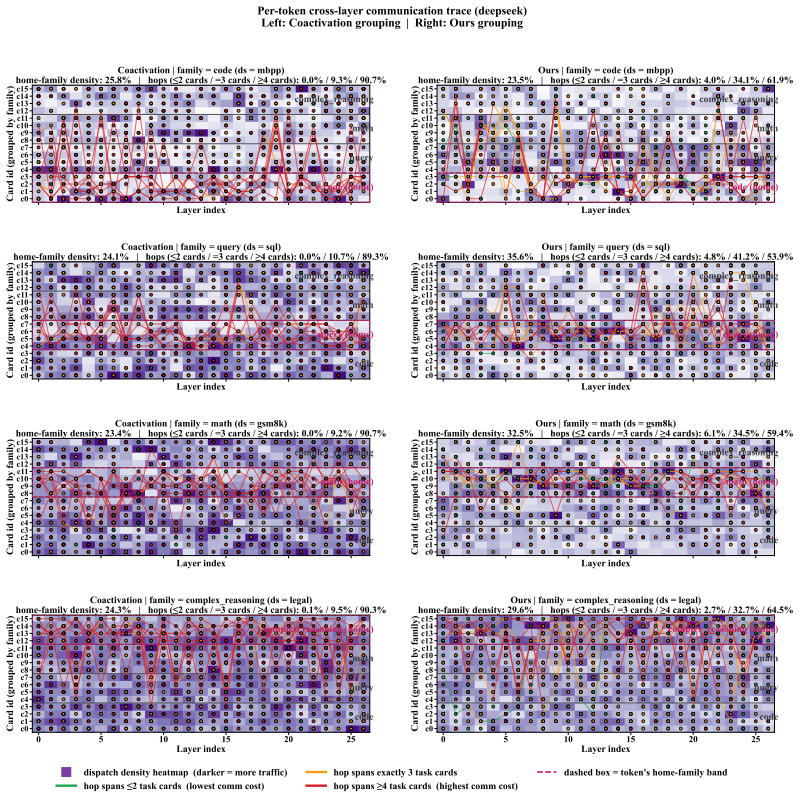
The central claim is that expert co-activation is strongly task-conditioned: pairs tightly coupled in one task family are often uncorrelated in another. Therefore a deployment plan must be derived from family-specific traces rather than a global average. TACG reweights the co-activation graph by per-expert task-family preference vectors so that intra-family locality dominates the final grouping, then assigns experts to primary GPUs under exact capacity constraints. GESR identifies generic experts with consistently central profiles, replicates them on a small set of secondary GPUs, and selects among replicas at runtime using locality and load signals. Experiments confirm the resulting static
What carries the argument
Task-Aware Coactivation Grouping (TACG): a deployment-time procedure that extracts family-specific dispatch traces, derives per-expert task-family preference vectors, reweights the co-activation graph to favor intra-family edges, and solves a capacity-constrained assignment of experts to primary GPUs; paired with Generic Expert Shared Replication (GESR) that replicates only the generic experts across secondary GPUs and selects replicas at serving time.
If this is right
- Average communication cost falls by 31.39 percent across the three tested models relative to a task-agnostic baseline.
- Jain fairness index across GPUs stays at 0.9975 on average, indicating the capacity-constrained assignment does not create load imbalance.
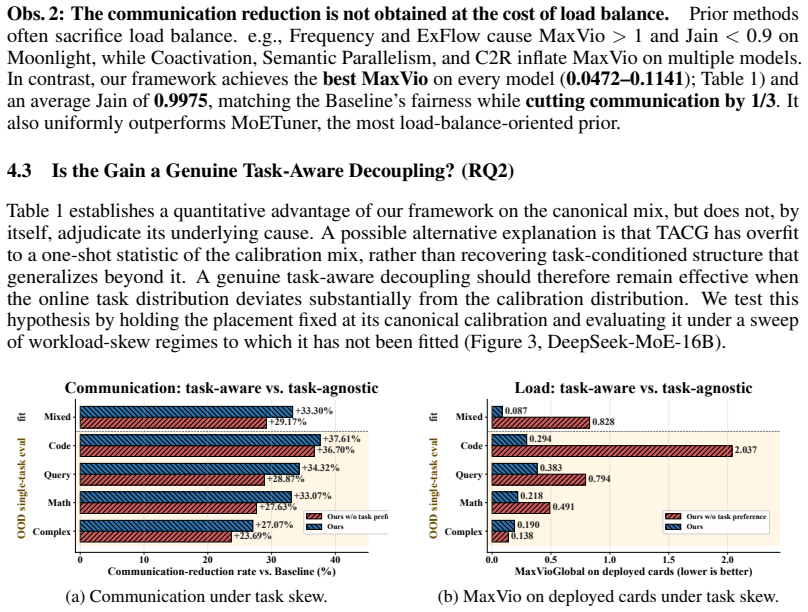
- The cost reduction and fairness both persist when inference data undergoes severe distribution shifts away from the traces used for grouping.
- The method outperforms existing strong baselines that rely on globally aggregated routing information.
Where Pith is reading between the lines
- The same family-conditioned reweighting idea could be applied to any conditional-computation architecture whose activation statistics vary systematically by input domain.
- Production systems that already collect per-task routing logs could adopt the grouping step with little extra instrumentation, but would need to decide how many distinct task families to maintain separate traces for.
- Because only a small number of generic experts are replicated, the memory overhead remains modest even when the number of task families grows.
- The static placement plus selective replication may serve as a middle ground between fully static and fully dynamic expert migration strategies.
Load-bearing premise
Expert co-activation patterns differ substantially across task families, so that reweighting the graph by family preferences produces groupings whose dominant locality is intra-family rather than global.
What would settle it
Run the same three open-source MoE models under identical multi-task workloads but replace the family-specific reweighting step with a single global-average graph; if the measured communication volume is no higher than the task-aware version, the benefit of conditioning on task families does not hold.
Figures

read the original abstract
Sparsely activated Mixture-of-Experts (MoE) models scale capacity via conditional computation, but distributed inference suffers from cross-GPU expert communication and routing-induced load imbalance. Existing placement methods reduce this cost by co-locating frequently co-activated experts; however, they derive a single deployment plan from globally aggregated routing traces, thereby averaging away the heterogeneous, task-specific co-activation patterns that actually drive communication in multi-task serving. We observe that expert co-activation is strongly task-conditioned: pairs tightly coupled in one task family are often uncorrelated in another, so effective deployment should group experts by task-aware co-activation rather than by a task-agnostic average. Based on this insight, we propose \emph{Task-Aware Coactivation Grouping} (TACG), a deployment-time framework that uses family-specific dispatch and co-activation traces to derive per-expert task-family preferences, reweights the co-activation graph so that intra-family locality dominates grouping, and assigns each expert to a primary GPU under exact capacity constraints. To keep the static placement robust under online workload skew, we further introduce \emph{Generic Expert Shared Replication} (GESR), a lightweight companion that identifies generic experts with consistently central co-activation profiles, replicates them across a small set of secondary GPUs, and applies locality- and load-aware selection at serving time. Experiments on three representative open-source MoE models demonstrate that our framework reduces the average communication cost by 31.39\% over the baseline, while preserving an average Jain fairness index of 0.9975. This advantage persists even under severe distribution shifts in the inference data, consistently outperforming strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Task-Aware Coactivation Grouping (TACG), a deployment-time framework that derives per-expert task-family preferences from family-specific dispatch traces, reweights the co-activation graph to emphasize intra-family locality, and solves an assignment problem under exact capacity constraints. It is paired with Generic Expert Shared Replication (GESR) to replicate generic experts for robustness to online skew. On three open-source MoE models the method reports a 31.39% average reduction in communication cost while maintaining an average Jain fairness index of 0.9975, with the advantage persisting under severe distribution shifts.
Significance. If the claimed task-conditioned heterogeneity in expert co-activation is both substantial and quantitatively verified, the framework offers a practical route to lower communication overhead in multi-task MoE serving while preserving load balance; the data-driven construction and explicit capacity constraints are strengths that would make the result reproducible if the heterogeneity metrics are supplied.
major comments (2)
- [Abstract] Abstract: the central premise that 'expert co-activation is strongly task-conditioned' (pairs tightly coupled in one task family are often uncorrelated in another) is asserted without any quantitative support such as cosine similarity between task-specific adjacency matrices, overlap of top-k pairs, or matrix distances. This evidence is load-bearing for attributing the 31.39% communication reduction to the task-aware reweighting step rather than to the global baseline or the assignment solver itself.
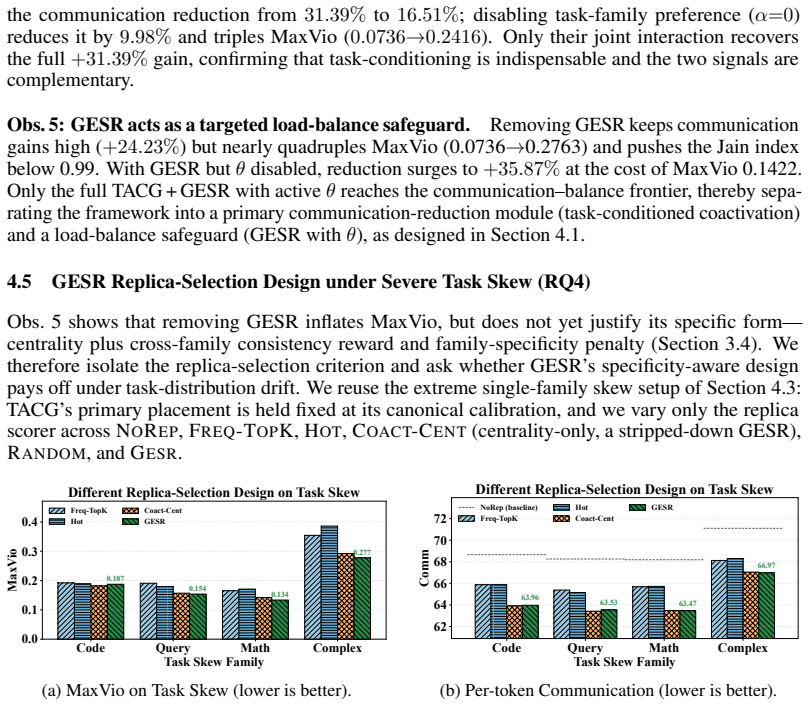
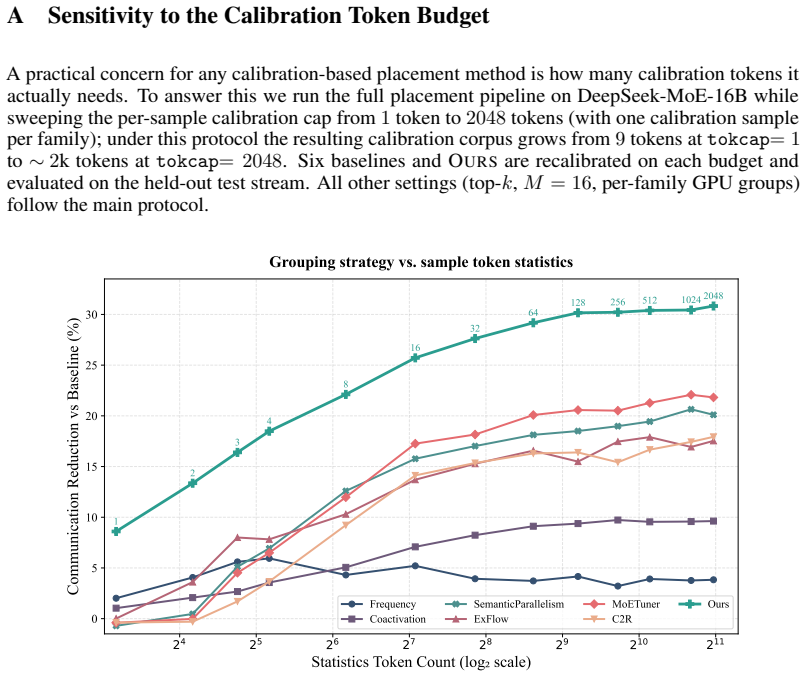
- [Abstract] Abstract / Experiments section: the reported 31.39% reduction and 0.9975 fairness are given only as averages across three models; without per-model breakdowns, number of task families, severity metrics for the distribution shifts, or variance across runs, it is impossible to judge whether the gains are driven by the task-aware component or by other placement choices.
minor comments (1)
- [Abstract] The acronym TACG should be expanded on first use ('Task-Aware Coactivation Grouping') for readers unfamiliar with the terminology.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the quantitative grounding of our central claim and to improve the transparency of the reported results. We address each point below and will make corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central premise that 'expert co-activation is strongly task-conditioned' (pairs tightly coupled in one task family are often uncorrelated in another) is asserted without any quantitative support such as cosine similarity between task-specific adjacency matrices, overlap of top-k pairs, or matrix distances. This evidence is load-bearing for attributing the 31.39% communication reduction to the task-aware reweighting step rather than to the global baseline or the assignment solver itself.
Authors: We agree that explicit quantitative metrics would strengthen the attribution of gains specifically to the task-aware reweighting. The manuscript presents the observation through dispatch-trace analysis and qualitative examples in Sections 3 and 4, but does not report the suggested matrix-level statistics in the abstract. In revision we will add cosine similarities between task-specific adjacency matrices, top-k pair overlap percentages, and Frobenius distances between task-family co-activation graphs, both in an expanded abstract and in a new quantitative-analysis subsection. These additions will directly support the claim that the 31.39% reduction arises from task-conditioned heterogeneity rather than from the global baseline or solver alone. revision: yes
-
Referee: [Abstract] Abstract / Experiments section: the reported 31.39% reduction and 0.9975 fairness are given only as averages across three models; without per-model breakdowns, number of task families, severity metrics for the distribution shifts, or variance across runs, it is impossible to judge whether the gains are driven by the task-aware component or by other placement choices.
Authors: The abstract reports aggregate figures for brevity. The experiments section already contains per-model tables and figures that list communication cost, fairness, and results under distribution shifts for each of the three models, together with the number of task families used. To make these details immediately visible and to isolate the task-aware contribution, we will (i) revise the abstract to include a compact per-model summary line and (ii) add an explicit ablation table contrasting task-aware versus task-agnostic grouping while reporting run-to-run variance and shift-severity metrics (e.g., KL divergence between training and test routing distributions). These changes will allow readers to verify that the reported advantage is driven by the task-aware component. revision: yes
Circularity Check
No circularity; data-driven grouping from observed traces with independent experimental validation
full rationale
The paper's core steps are: (1) observe task-conditioned co-activation from dispatch traces, (2) reweight the graph using per-family preferences, (3) solve an assignment problem under capacity constraints, and (4) validate via experiments on three MoE models yielding 31.39% communication reduction. No equation, parameter fit, or self-citation reduces the reported savings back to the input traces by construction. The heterogeneity assumption is presented as an empirical observation rather than a derived theorem, and the method remains falsifiable against external baselines. This matches the default case of a self-contained empirical framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
Pith/arXiv arXiv 2017
-
[2]
{GS}hard: Scaling giant models with conditional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. {GS}hard: Scaling giant models with conditional computation and automatic sharding. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=qrwe7XHTmYb
2021
-
[3]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
2022
-
[4]
Megablocks: Efficient sparse training with mixture-of-experts.Proceedings of Machine Learning and Systems, 5:288–304, 2023
Trevor Gale, Deepak Narayanan, Cliff Young, and Matei Zaharia. Megablocks: Efficient sparse training with mixture-of-experts.Proceedings of Machine Learning and Systems, 5:288–304, 2023
2023
-
[5]
Tutel: Adaptive mixture-of-experts at scale.Proceedings of Machine Learning and Systems, 5:269–287, 2023
Changho Hwang, Wei Cui, Yifan Xiong, Ziyue Yang, Ze Liu, Han Hu, Zilong Wang, Rafael Salas, Jithin Jose, Prabhat Ram, et al. Tutel: Adaptive mixture-of-experts at scale.Proceedings of Machine Learning and Systems, 5:269–287, 2023
2023
-
[6]
Semantic paral- lelism: Redefining efficient moe inference via model-data co-scheduling
Yan Li, Zhenyu Zhang, Zhengang Wang, Pengfei chen, and Pengfei Zheng. Semantic paral- lelism: Redefining efficient moe inference via model-data co-scheduling. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=MSHPrMpIHZ
2026
-
[7]
Scaling multi-node mixture- of-experts inference using expert activation patterns, 2026
Abhimanyu Bambhaniya, Geonhwa Jeong, Jason Park, Jiecao Yu, Jaewon Lee, Pengchao Wang, Changkyu Kim, Chunqiang Tang, and Tushar Krishna. Scaling multi-node mixture- of-experts inference using expert activation patterns, 2026. URL https://arxiv.org/abs/ 2604.23150
Pith/arXiv arXiv 2026
-
[8]
Tutel: Adaptive mixture-of-experts at scale
Changho Hwang, Wei Cui, Yifan Xiong, Ziyue Yang, Ze Liu, Han Hu, Zilong Wang, Rafael Salas, Jithin Jose, Prabhat Ram, HoYuen Chau, Peng Cheng, Fan Yang, Mao Yang, and Yongqiang Xiong. Tutel: Adaptive mixture-of-experts at scale. In D. Song, M. Carbin, and T. Chen, editors,Proceedings of Machine Learning and Systems, volume 5, pages 269–
-
[9]
URL https://proceedings.mlsys.org/paper_files/paper/2023/ file/5616d34cf8ff73942cfd5aa922842556-Paper-mlsys2023.pdf
Curan, 2023. URL https://proceedings.mlsys.org/paper_files/paper/2023/ file/5616d34cf8ff73942cfd5aa922842556-Paper-mlsys2023.pdf
2023
-
[10]
Megablocks: Ef- ficient sparse training with mixture-of-experts
Trevor Gale, Deepak Narayanan, Cliff Young, and Matei Zaharia. Megablocks: Ef- ficient sparse training with mixture-of-experts. In D. Song, M. Carbin, and T. Chen, editors,Proceedings of Machine Learning and Systems, volume 5, pages 288–304. Cu- ran, 2023. URL https://proceedings.mlsys.org/paper_files/paper/2023/file/ 5a54f79333768effe7e8927bcccffe40-Pape...
2023
-
[11]
Proceedings of the 29th Symposium on Operating Systems Principles , pages =
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23, page 611–626, New York, NY , USA, 2023. Association for Computing Machin...
-
[12]
Accelerating distributed MoE training and inference with lina
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, and Hong Xu. Accelerating distributed MoE training and inference with lina. In2023 USENIX Annual Technical Conference (USENIX ATC 23), pages 945–959, Boston, MA, July 2023. USENIX Association. ISBN 978-1-939133-35-9. URLhttps://www.usenix.org/conference/atc23/presentation/li-jiamin
2023
-
[13]
Jinghan Yao, Quentin Anthony, Aamir Shafi, Hari Subramoni, and Dhabaleswar K. DK Panda. Exploiting inter-layer expert affinity for accelerating mixture-of-experts model inference. In 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 915–925, 2024. doi: 10.1109/IPDPS57955.2024.00086. 10
-
[14]
Advancing MoE efficiency: A collaboration-constrained routing (C2R) strategy for better expert parallelism design
Mohan Zhang, Pingzhi Li, Jie Peng, Mufan Qiu, and Tianlong Chen. Advancing MoE efficiency: A collaboration-constrained routing (C2R) strategy for better expert parallelism design. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: H...
2025
-
[15]
NeMo guardrails: A toolkit for controllable and safe LLM applications with pro- grammable rails
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/ 2025.naacl-long.347. URLhttps://aclanthology.org/2025.naacl-long.347/
-
[16]
Moetuner: Optimized mixture of expert serving with balanced expert placement and token routing, 2025
Seokjin Go and Divya Mahajan. Moetuner: Optimized mixture of expert serving with balanced expert placement and token routing, 2025. URLhttps://arxiv.org/abs/2502.06643
arXiv 2025
-
[17]
Grace-moe: Grouping and replication with locality-aware routing for efficient distributed moe inference,
Yu Han, Lehan Pan, Jie Peng, Ziyang Tao, Wuyang Zhang, and Yanyong Zhang. Grace-moe: Grouping and replication with locality-aware routing for efficient distributed moe inference,
-
[18]
URLhttps://arxiv.org/abs/2509.25041
-
[19]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022. URLhttp://jmlr.org/papers/v23/21-0998.html
2022
-
[20]
Base layers: Simplifying training of large, sparse models
Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer. Base layers: Simplifying training of large, sparse models. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 6265–6274. PMLR, 18–24 Jul 2021. URL https://proc...
2021
-
[21]
Dai, Zhifeng Chen, Quoc V Le, and James Laudon
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Y Zhao, Andrew M. Dai, Zhifeng Chen, Quoc V Le, and James Laudon. Mixture-of-experts with expert choice routing. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id= jdJo1HIVinI
2022
-
[22]
Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y
Damai Dai, Chengqi Deng, Chenggang Zhao, R.x. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y . Wu, Zhenda Xie, Y .k. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. DeepSeekMoE: Towards ultimate expert special- ization in mixture-of-experts language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, edito...
-
[23]
doi: 10.18653/v1/2024.acl-long.70
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.70. URL https://aclanthology.org/2024.acl-long.70/
-
[24]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H. Chi. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’18, page 1930–1939, New York, NY , USA, 2018. Association for Computing Machinery. ISBN 97814...
-
[25]
Hussein Hazimeh, Zhe Zhao, Aakanksha Chowdhery, Maheswaran Sathiamoorthy, Yihua Chen, Rahul Mazumder, Lichan Hong, and Ed H. Chi. Dselect-k: differentiable selection in the mixture of experts with applications to multi-task learning. InProceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY , USA, ...
2021
-
[26]
Beyond distillation: Task-level mixture-of-experts for efficient inference
Sneha Kudugunta, Yanping Huang, Ankur Bapna, Maxim Krikun, Dmitry Lepikhin, Minh- Thang Luong, and Orhan Firat. Beyond distillation: Task-level mixture-of-experts for efficient inference. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Findings of the Association for Computational Linguistics: EMNLP 2021, pages 3577–3...
-
[27]
Task-specific expert pruning for sparse mixture-of-experts, 2022
Tianyu Chen, Shaohan Huang, Yuan Xie, Binxing Jiao, Daxin Jiang, Haoyi Zhou, Jianxin Li, and Furu Wei. Task-specific expert pruning for sparse mixture-of-experts, 2022. URL https://arxiv.org/abs/2206.00277
arXiv 2022
-
[28]
Woodruff, Barnabas Poczos, and Hany Hassan
Hai Pham, Young Jin Kim, Subhabrata Mukherjee, David P. Woodruff, Barnabas Poczos, and Hany Hassan. Task-based MoE for multitask multilingual machine translation. In Duygu Ataman, editor,Proceedings of the 3rd Workshop on Multi-lingual Representation Learning (MRL), pages 164–172, Singapore, December 2023. Association for Computational Linguistics. doi: 1...
-
[29]
Hmora: Making llms more effective with hierarchical mixture of lora experts
Mengqi Liao, Wei Chen, Junfeng Shen, Shengnan Guo, and Huaiyu Wan. Hmora: Making llms more effective with hierarchical mixture of lora experts. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, pages 91309–91330, 2025. URL https://proceedings.iclr.cc/paper_files/paper/2025/ file/e43...
2025
-
[30]
Advancing expert specialization for better moe
Hongcan Guo, Haolang Lu, Guoshun Nan, Bolun Chu, Jialin Zhuang, Yuan Yang, Wenhao Che, Xinye Cao, Sicong Leng, Qimei Cui, and Xudong Jiang. Advancing expert specialization for better moe. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Neural Information Processing Systems, volume 38, pages 48767–488...
2025
-
[31]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
Pith/arXiv arXiv 2023
-
[32]
Muon is scalable for llm training, 2025
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yongsheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, and Zhilin Yang. Muon is sca...
Pith/arXiv arXiv 2025
-
[33]
Program synthesis with large language models, 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021. URLhttps://arxiv.org/abs/2108.07732
Pith/arXiv arXiv 2021
-
[34]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
Pith/arXiv arXiv 2021
-
[35]
Measuring coding challenge competence with apps, 2021
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with apps, 2021. URLhttps://arxiv.org/abs/2105.09938
Pith/arXiv arXiv 2021
-
[36]
Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task,
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task,
-
[37]
URLhttps://arxiv.org/abs/1809.08887. 12
-
[38]
Victor Zhong, Caiming Xiong, and Richard Socher. Seq2sql: Generating structured queries from natural language using reinforcement learning.CoRR, abs/1709.00103, 2017
Pith/arXiv arXiv 2017
-
[39]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/ abs/2110.14168
Pith/arXiv arXiv 2021
-
[40]
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Long Yu, Albert Qiaochu Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, Stanislas Polu, Hugging Face, and AI Mistral. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutio...
-
[41]
Legalbench: A collabora- tively built benchmark for measuring legal reasoning in large language models
Neel Guha, Julian Nyarko, Daniel Ho, Christopher Ré, Adam Chilton, Aditya K, Alex Chohlas- Wood, Austin Peters, Brandon Waldon, Daniel Rockmore, Diego Zambrano, Dmitry Tal- isman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory Dickinson, Hag- gai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan Choi, Kevin Tobia...
2023
-
[42]
Challenging BIG - Bench Tasks and Whether Chain -of- Thought Can Solve Them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, and Jason Wei. Challenging BIG-bench tasks and whether chain-of-thought can solve them. In Anna Rogers, Jordan Boyd- Graber, and Naoaki Okazaki, editors,Findings of the Association for Computational Linguistics: AC...
-
[43]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.