Revise, Don't Freeze: Sampler-Matched Training for Self-Correcting Masked Diffusion Language Models
Pith reviewed 2026-06-28 17:35 UTC · model grok-4.3
The pith
A parameter-free sampler D3IM lets masked diffusion models revise already-committed tokens, and SCOPE training overcomes the model's bias to preserve its own errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
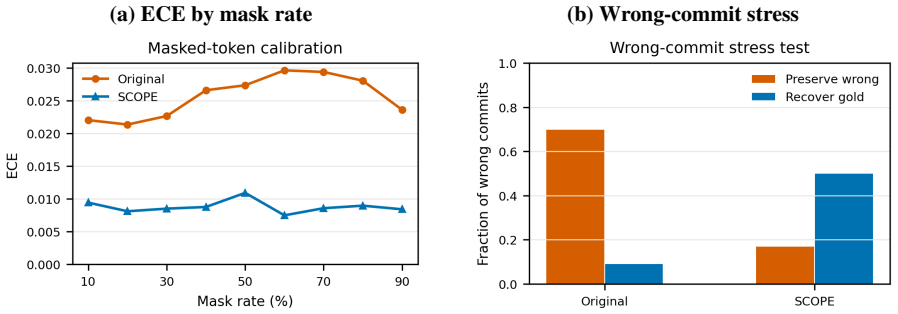
D3IM is a corrector-style reverse update that allows direct revision of visible tokens during denoising; paired with SCOPE training that simulates the same process, it removes preservation bias and yields gains of +13.0 on GSM8K, +4.8 on MATH-500, +15.3 on HumanEval, and +10.4 on MBPP over the baseline unmasking sampler at 64 steps.
What carries the argument
D3IM, a parameter-free sampler derived as a corrector-style reverse update that permits direct visible-to-visible revision without auxiliary modules.
If this is right
- Gains grow with the number of denoising steps on math and code tasks.
- No auxiliary revision modules or remasking passes are required.
- The model can now use its per-step re-prediction capability on tokens it has already revealed.
- Preservation bias is reduced by training on simulated self-errors.
Where Pith is reading between the lines
- The same sampler-training pairing could be tested on other diffusion-based sequence models beyond language.
- Longer sampling trajectories become more useful once revision is enabled.
- The approach might reduce reliance on external verifiers or multiple independent samples.
Load-bearing premise
The measured gains arise because the model has learned to correct its own committed errors rather than from incidental changes in the post-training distribution or the fixed step schedule.
What would settle it
An ablation that applies D3IM sampling to the original untrained model and shows no gain over standard unmasking, or that freezes tokens after commitment and recovers the original baseline scores.
Figures

read the original abstract
Masked diffusion language models (MDLMs) re-predict every position at each denoising step, but standard samplers commit tokens once revealed, leaving this revision capability unused. Existing approaches either add heuristic or learned mechanisms to revise committed tokens, or remask them back to [MASK] before re-predicting; a principled sampler that directly revises visible tokens without auxiliary modules remains underexplored. We introduce D3IM, a parameter-free sampler derived as a corrector-style reverse update that permits direct visible-to-visible revision without additional modules or auxiliary passes. D3IM also reveals a model-side obstacle we term preservation bias: the model tends to reproduce its own wrong committed tokens rather than correct them. We address this with SCOPE (Self-Conditioned On Prediction Errors), a lightweight post-training procedure that simulates D3IM's sampling process. On LLaDA-8B at 64 denoising steps, SCOPE+D3IM improves over the original LLaDA-8B with standard unmasking by +13.0 on GSM8K (68.3%), +4.8 on MATH-500 (23.6%), +15.3 on HumanEval (29.3%), and +10.4 on MBPP (30.8%), with gains that increase as more denoising steps are used on math and HumanEval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces D3IM, a parameter-free sampler for masked diffusion language models derived as a corrector-style reverse update that permits direct visible-to-visible token revision without auxiliary modules. It identifies a preservation bias in models and proposes SCOPE, a lightweight post-training procedure that simulates D3IM sampling to train the model to correct its own errors. On LLaDA-8B at 64 denoising steps, SCOPE+D3IM is reported to yield gains of +13.0 on GSM8K (to 68.3%), +4.8 on MATH-500 (to 23.6%), +15.3 on HumanEval (to 29.3%), and +10.4 on MBPP (to 30.8%) over the base model with standard unmasking, with gains increasing at higher step counts on some tasks.
Significance. If the performance deltas are shown to arise specifically from learned self-correction under the D3IM process rather than incidental distribution shift, the work would offer a clean, module-free way to exploit the re-prediction capability of MDLMs. The parameter-free derivation of D3IM would be a clear technical contribution to sampler design in diffusion language models.
major comments (1)
- [Abstract] Abstract: the central attribution—that the reported gains arise because SCOPE trains the model to overcome preservation bias under D3IM's visible-to-visible revision—requires a control that post-trains an otherwise identical model by simulating standard unmasking instead of D3IM. No such ablation is described, so the observed lifts could be produced by the altered post-training distribution alone; this control is load-bearing for the mechanistic claim.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger evidence isolating the source of the reported gains. We agree that the mechanistic claim requires an explicit control and will add the requested ablation in revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central attribution—that the reported gains arise because SCOPE trains the model to overcome preservation bias under D3IM's visible-to-visible revision—requires a control that post-trains an otherwise identical model by simulating standard unmasking instead of D3IM. No such ablation is described, so the observed lifts could be produced by the altered post-training distribution alone; this control is load-bearing for the mechanistic claim.
Authors: We agree that the current experiments leave open the possibility that gains arise from post-training distribution shift rather than specifically from learning to correct under D3IM. In the revised manuscript we will add the requested control: an otherwise identical model post-trained by simulating standard unmasking (instead of D3IM), then evaluated under both standard unmasking and D3IM. This will allow direct comparison of whether the performance lift is D3IM-specific. revision: yes
Circularity Check
No significant circularity; derivation and gains are externally benchmarked
full rationale
The paper presents D3IM as a derived parameter-free sampler and SCOPE as a post-training procedure that simulates D3IM sampling to mitigate preservation bias, with reported gains on external benchmarks (GSM8K, MATH-500, HumanEval, MBPP) versus the base LLaDA-8B model. No load-bearing step reduces by construction to its own inputs: there is no self-definitional equation, no fitted parameter renamed as prediction, and no self-citation chain invoked as uniqueness theorem. The deliberate matching of training distribution to inference sampler is a design choice whose effect is measured against held-out benchmarks rather than being tautological. The paper is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Large Language Diffusion Models , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Advances in Neural Information Processing Systems , volume=
Simple and Effective Masked Diffusion Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Proceedings of the 41st International Conference on Machine Learning , pages=
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author=. Proceedings of the 41st International Conference on Machine Learning , pages=. 2024 , publisher=
2024
-
[4]
Advances in Neural Information Processing Systems , volume=
Structured Denoising Diffusion Models in Discrete State-Spaces , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
arXiv preprint arXiv:2508.15487 , year=
Dream 7B: Diffusion Large Language Models , author=. arXiv preprint arXiv:2508.15487 , year=
-
[6]
Advances in Neural Information Processing Systems , volume=
Discrete Flow Matching , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
International Conference on Learning Representations , year=
Sequence Level Training with Recurrent Neural Networks , author=. International Conference on Learning Representations , year=
-
[8]
Advances in Neural Information Processing Systems , pages=
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks , author=. Advances in Neural Information Processing Systems , pages=
-
[9]
International Conference on Learning Representations , year=
Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning , author=. International Conference on Learning Representations , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Remasking Discrete Diffusion Models with Inference-Time Scaling , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Wide-In, Narrow-Out: Revokable Decoding for Efficient and Effective
Hong, Feng and Yu, Geng and Ye, Yushi and Huang, Haicheng and Zheng, Huangjie and Zhang, Ya and Wang, Yanfeng and Yao, Jiangchao , booktitle=. Wide-In, Narrow-Out: Revokable Decoding for Efficient and Effective
-
[12]
arXiv preprint arXiv:2510.05090 , year=
Finish First, Perfect Later: Test-Time Token-Level Cross-Validation for Diffusion Large Language Models , author=. arXiv preprint arXiv:2510.05090 , year=
-
[13]
Zhai, Kevin and Mollah, Sabbir and Wang, Zhenyi and Shah, Mubarak , journal=
-
[14]
Bie, Tiwei and Cao, Maosong and Cao, Xiang and Chen, Bingsen and Chen, Fuyuan and Chen, Kun and Du, Lun and Feng, Daozhuo and Feng, Haibo and Gong, Mingliang and others , journal=
-
[15]
arXiv preprint arXiv:2604.18738 , year=
Remask, Don't Replace: Token-to-Mask Refinement in Masked Diffusion Language Models , author=. arXiv preprint arXiv:2604.18738 , year=
-
[16]
International Conference on Learning Representations , year=
Don't Settle Too Early: Self-Reflective Remasking for Diffusion Language Models , author=. International Conference on Learning Representations , year=
-
[17]
arXiv preprint arXiv:2510.01384 , year=
Fine-Tuning Masked Diffusion for Provable Self-Correction , author=. arXiv preprint arXiv:2510.01384 , year=
-
[18]
arXiv preprint arXiv:2602.11590 , year=
Learn from Your Mistakes: Self-Correcting Masked Diffusion Models , author=. arXiv preprint arXiv:2602.11590 , year=
-
[19]
Liu, Liming and Huang, Binxuan and Zhang, Zixuan and Liu, Xin and Yin, Bing and Zhao, Tuo , journal=
-
[20]
arXiv preprint arXiv:2512.15596 , year=
Corrective Diffusion Language Models , author=. arXiv preprint arXiv:2512.15596 , year=
-
[21]
Huang, Pengcheng and Liu, Shuhao and Liu, Zhenghao and Yan, Yukun and Wang, Shuo and Chen, Zulong and Xiao, Tong , journal=
-
[22]
He, Haoyu and Renz, Katrin and Cao, Yong and Geiger, Andreas , journal=
-
[23]
Chen, Zigeng and Fang, Gongfan and Ma, Xinyin and Yu, Ruonan and Wang, Xinchao , journal=
-
[24]
arXiv preprint arXiv:2602.01362 , year=
Balancing Understanding and Generation in Discrete Diffusion Models , author=. arXiv preprint arXiv:2602.01362 , year=
-
[25]
Proceedings of the 42nd International Conference on Machine Learning , pages=
Generalized Interpolating Discrete Diffusion , author=. Proceedings of the 42nd International Conference on Machine Learning , pages=. 2025 , volume=
2025
-
[26]
arXiv preprint arXiv:2604.10556 , year=
Lost in Diffusion: Uncovering Hallucination Patterns and Failure Modes in Diffusion Large Language Models , author=. arXiv preprint arXiv:2604.10556 , year=
-
[27]
Gong, Shansan and Zhang, Ruixiang and Zheng, Huangjie and Gu, Jiatao and Jaitly, Navdeep and Kong, Lingpeng and Zhang, Yizhe , booktitle=
-
[28]
Sun, Xinhao and Zhao, Huaijin and Li, Maoliang and Zheng, Zihao and Chen, Jiayu and Liang, Yun and Chen, Xiang , journal=
-
[29]
arXiv preprint arXiv:2604.10567 , year=
Early Decisions Matter: Proximity Bias and Initial Trajectory Shaping in Non-Autoregressive Diffusion Language Models , author=. arXiv preprint arXiv:2604.10567 , year=
-
[30]
arXiv preprint arXiv:2604.11035 , year=
Introspective Diffusion Language Models , author=. arXiv preprint arXiv:2604.11035 , year=
-
[31]
International Conference on Learning Representations , year=
Soft-Masked Diffusion Language Models , author=. International Conference on Learning Representations , year=
-
[32]
Advances in Neural Information Processing Systems , volume=
d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[34]
arXiv preprint arXiv:2107.03374 , year=
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[35]
arXiv preprint arXiv:2108.07732 , year=
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[36]
International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. International Conference on Learning Representations , year=
-
[37]
Hugging Face Blog , year=
FineWeb-Edu: The Finest Collection of Educational Content the Web Has to Offer , author=. Hugging Face Blog , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.