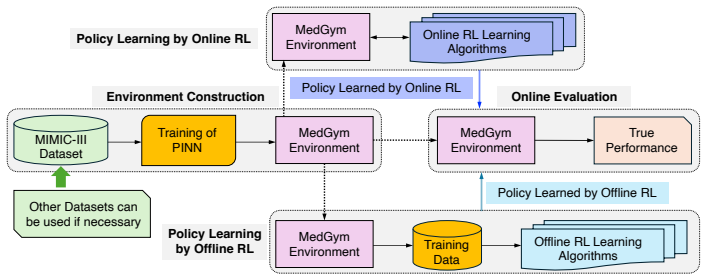
MedGym:A Unified Continuous-Time Benchmark for Dynamic Medical Treatment Reinforcement Learning
Pith reviewed 2026-06-28 17:27 UTC · model grok-4.3
The pith
MedGym constructs a continuous-time benchmark for reinforcement learning in dynamic medical treatment from clinical data using Physics-Informed Neural Networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
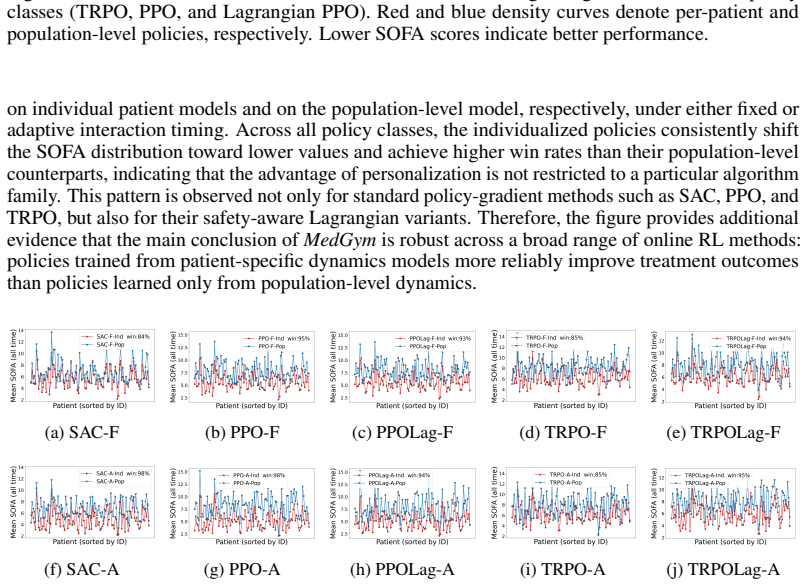
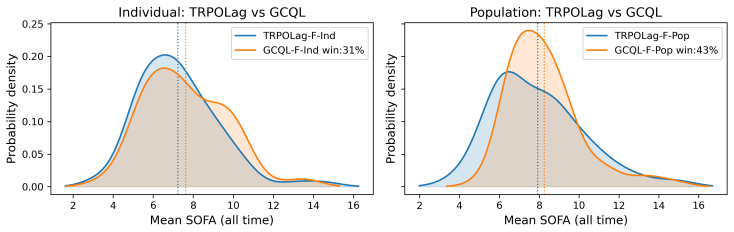
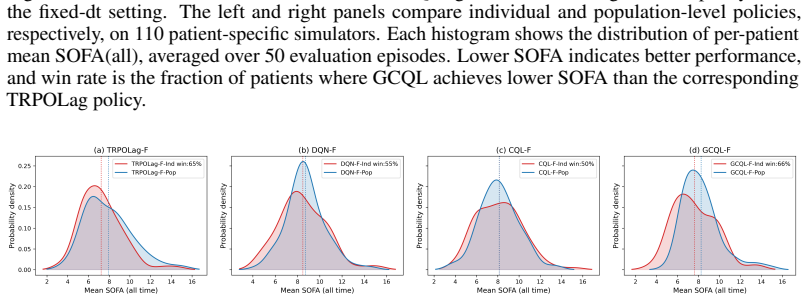
MedGym models longitudinal patient evolution in a continuous-time framework and constructs a configurable medical RL benchmark from clinical data by using Physics-Informed Neural Networks. The resulting benchmark supports both offline and online RL, and enables direct comparison between discrete-time and continuous-time methods under irregular treatment timing and patient-specific dynamics. Besides, MedGym supports evaluation from clinically important perspectives, including personalization, trajectory-level safety, and the performance gap between model-based offline learning and online deployment.
What carries the argument
MedGym benchmark environment, built by training Physics-Informed Neural Networks on clinical data to generate continuous-time patient-specific dynamics and treatment effects.
If this is right
- RL methods can be tested for handling time-interval-dependent disease progression and personalized responses.
- Direct comparisons become possible between discrete-time and continuous-time RL approaches on the same patient data.
- Evaluation can include trajectory-level safety and the gap between model-based offline policies and online deployment.
- The environment remains configurable for different clinical datasets while preserving continuous-time structure.
Where Pith is reading between the lines
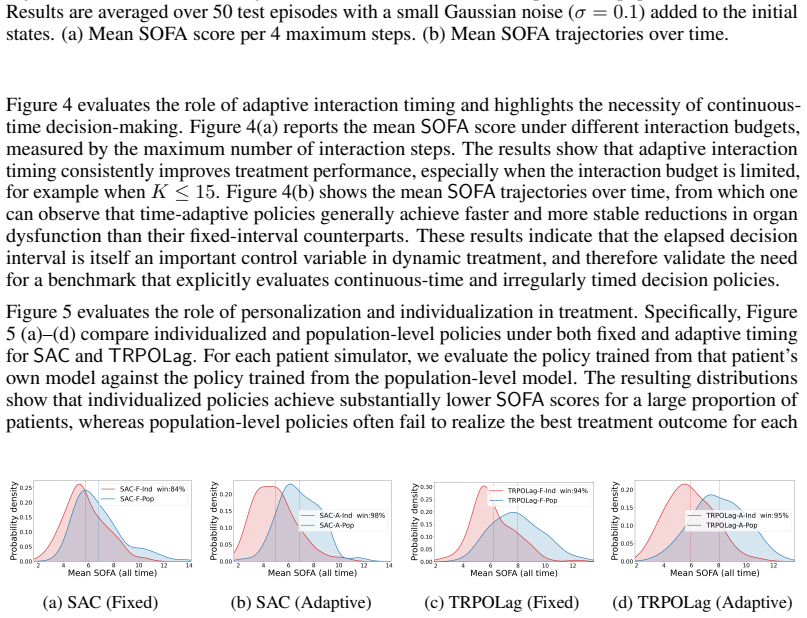
- If the simulated dynamics prove faithful, the benchmark could be used to pre-screen RL policies for safety before any real-patient testing.
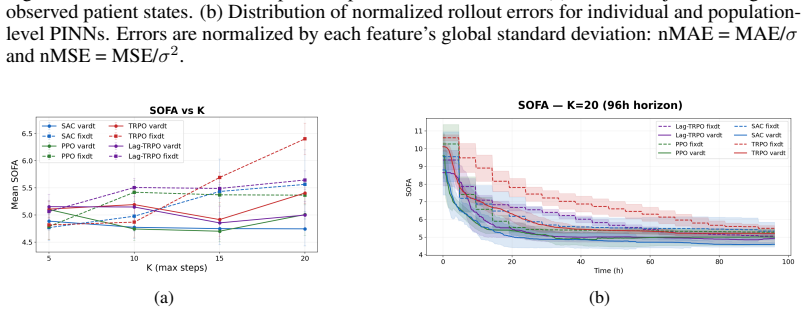
- The continuous-time formulation might expose failure modes in standard discrete-time RL algorithms when decision intervals vary widely.
- Extending the same PINN construction process to new disease areas would require only additional clinical time-series data.
- The benchmark could serve as a common testbed for developing new continuous-time RL algorithms tailored to irregular medical observations.
Load-bearing premise
Physics-Informed Neural Networks trained on clinical data can faithfully reproduce continuous-time patient-specific dynamics and treatment effects at irregular intervals.
What would settle it
Generated trajectories in MedGym diverge substantially from held-out real patient records in measured physiological variables or observed treatment responses over multiple irregular intervals.
Figures

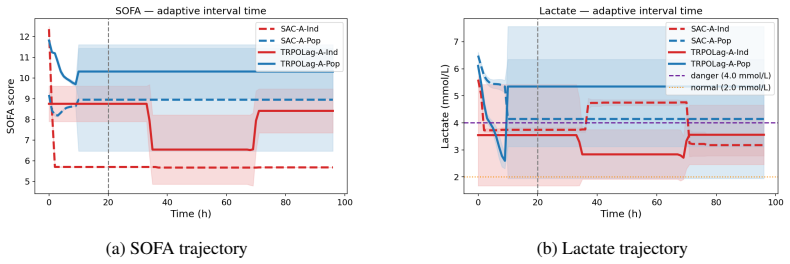
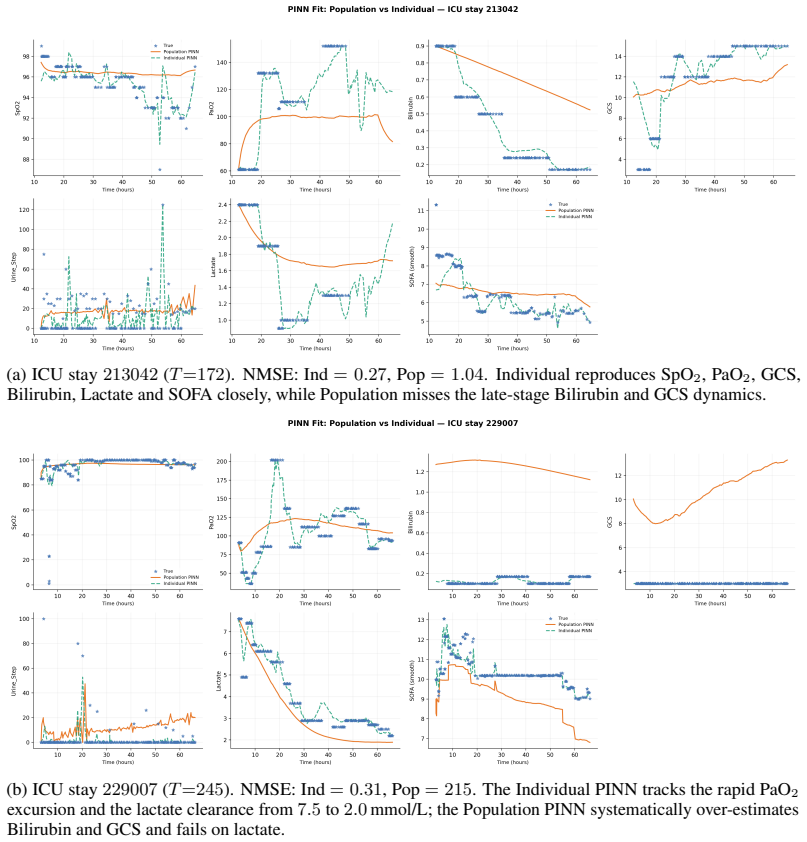
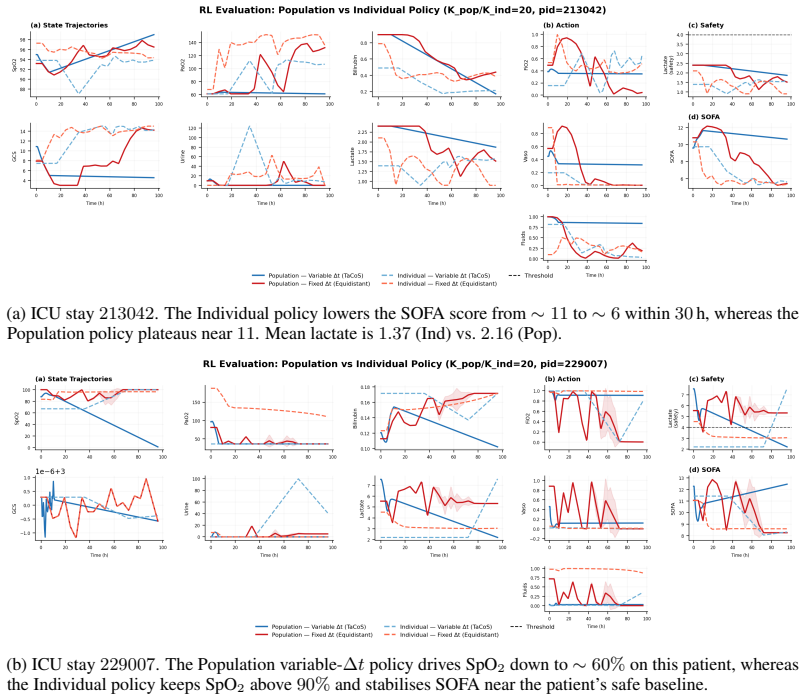
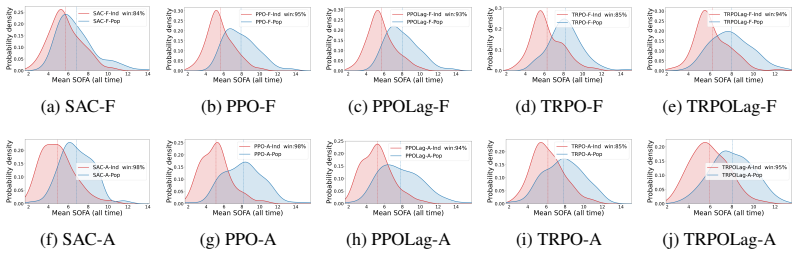

read the original abstract
Medical treatment recommendation poses several challenges to reinforcement learning (RL): patient physiology evolves in continuous time, measurements and interventions are performed at irregular intervals, and treatment effects vary substantially across individuals. Existing RL formulations and simulated environments, however, are based on discrete-time MDP or POMDP abstractions with fixed or pre-specified decision intervals. Thus, it remains difficult to evaluate whether RL methods can handle time-interval-dependent disease progression, personalized treatment response, and safety between consecutive measurement points. To address this gap, we introduce MedGym, a benchmark environment for dynamic treatment recommendation. MedGym models longitudinal patient evolution in a continuous-time framework and constructs a configurable medical RL benchmark from clinical data by using Physics-Informed Neural Networks. The resulting benchmark supports both offline and online RL, and enables direct comparison between discrete-time and continuous-time methods under irregular treatment timing and patient-specific dynamics. Besides, MedGym supports evaluation from clinically important perspectives, including personalization, trajectory-level safety, and the performance gap between model-based offline learning and online deployment. By providing a standardized and configurable benchmark for continuous-time dynamic treatment, MedGym aims to facilitate more realistic and informative evaluation of medical RL methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedGym, a benchmark environment for dynamic medical treatment recommendation in RL. It models longitudinal patient evolution in a continuous-time framework and constructs a configurable benchmark from clinical data using Physics-Informed Neural Networks (PINNs) to support offline and online RL, enable direct comparisons between discrete-time and continuous-time methods under irregular timing and patient-specific dynamics, and evaluate personalization, trajectory-level safety, and model-based offline vs. online performance gaps.
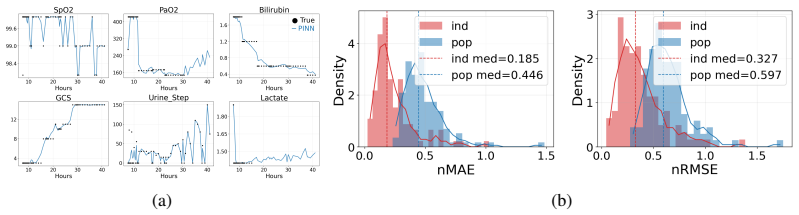
Significance. If the PINN models accurately capture patient-specific continuous-time dynamics and treatment effects from clinical data, MedGym would fill an important gap by providing a standardized, data-driven benchmark for evaluating RL methods on realistic medical challenges such as irregular measurement intervals and individual variability. The use of PINNs to derive the environments from real data is a promising direction for creating more faithful simulators than hand-crafted discrete MDPs.
major comments (2)
- [Abstract] Abstract: The central claim that MedGym enables valid discrete-vs-continuous RL comparisons rests on the PINN-derived dynamics faithfully reproducing observed state evolution at irregular times and causal treatment effects, yet the manuscript supplies no quantitative validation metrics, held-out trajectory error analysis, residual norms, or stability checks between observation points.
- [Abstract] Abstract: Without evidence that the learned vector fields match external ground truth on treatment effects or remain stable in intervals without measurements, the benchmark's utility for safety and personalization evaluations cannot be assessed, making this a load-bearing omission for the paper's contribution.
minor comments (1)
- [Abstract] The abstract would benefit from naming the specific clinical datasets used to train the PINNs and the RL algorithms included in the initial evaluations.
Simulated Author's Rebuttal
We thank the referee for identifying the critical need for explicit validation of the PINN-derived dynamics. We agree that quantitative evidence of fidelity to observed trajectories and stability is necessary to support the benchmark's claims and will add these analyses in revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that MedGym enables valid discrete-vs-continuous RL comparisons rests on the PINN-derived dynamics faithfully reproducing observed state evolution at irregular times and causal treatment effects, yet the manuscript supplies no quantitative validation metrics, held-out trajectory error analysis, residual norms, or stability checks between observation points.
Authors: We accept this assessment. The current version does not report these metrics. In the revised manuscript we will include held-out trajectory error (MSE/MAE on state predictions), PINN residual norms, and interval stability checks (e.g., forward integration error between observations) to demonstrate faithful reproduction of observed evolution. revision: yes
-
Referee: [Abstract] Abstract: Without evidence that the learned vector fields match external ground truth on treatment effects or remain stable in intervals without measurements, the benchmark's utility for safety and personalization evaluations cannot be assessed, making this a load-bearing omission for the paper's contribution.
Authors: We will add the requested stability checks between measurements. Direct external ground truth for causal treatment effects is unavailable in observational clinical data; we will instead report fidelity to observed trajectories under treatment and sensitivity analyses, while explicitly noting this limitation. revision: partial
- Direct external ground truth on causal treatment effects from observational data
Circularity Check
No circularity: benchmark is data-driven construction without self-referential derivations
full rationale
The paper presents MedGym as an environment constructed by training PINNs on clinical data to produce continuous-time patient dynamics. No equations, predictions, or uniqueness theorems are shown that reduce the benchmark outputs to fitted inputs by construction. No self-citation chains or ansatzes are invoked as load-bearing premises. The work is self-contained as an empirical benchmark generator; its validity rests on external validation of PINN fidelity rather than internal redefinition of results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bibhas Chakraborty and Susan A. Murphy. Dynamic treatment regimes.Annual Review of Statistics and Its Application, 1:447–464, 2014
2014
-
[2]
Kartik Choudhary, Dhawal Gupta, and Philip S. Thomas. Icu-sepsis: A benchmark mdp built from real medical data.arXiv preprint arXiv:2406.05646, 2024. doi: 10.48550/arXiv.2406. 05646. URLhttps://arxiv.org/abs/2406.05646
-
[3]
Lehman, Matthieu Komorowski, Aldo Faisal, Leo Anthony Celi, David Sontag, and Finale Doshi-Velez
Omer Gottesman, Fredrik Johansson, Joshua Meier, David Dent, Donghun Lee, Srivatsan Srinivasan, Linying Zhang, Yi Ding, David Wihl, Xiaoxiao Peng, Jiayu Yao, Isaac Lage, Constantin Mosch, Li-wei H. Lehman, Matthieu Komorowski, Aldo Faisal, Leo Anthony Celi, David Sontag, and Finale Doshi-Velez. Evaluating reinforcement learning algorithms in observational...
Pith/arXiv arXiv 2018
-
[4]
Guidelines for reinforcement learning in healthcare.Nature Medicine, 25:16–18, 2019
Omer Gottesman, Fredrik Johansson, Matthieu Komorowski, Aldo Faisal, David Sontag, Finale Doshi-Velez, and Leo Anthony Celi. Guidelines for reinforcement learning in healthcare.Nature Medicine, 25:16–18, 2019
2019
-
[5]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1861–1870. PMLR, 10–15 Jul 2018
2018
-
[6]
Epicare: A reinforcement learning benchmark for dynamic treatment regimes.Proceedings of the 36th Advances in Neural Information Processing Systems, 2024
Mason Hargrave, Alex Spaeth, and Logan Grosenick. Epicare: A reinforcement learning benchmark for dynamic treatment regimes.Proceedings of the 36th Advances in Neural Information Processing Systems, 2024
2024
-
[7]
A.E.W. Johnson, T.J. Pollard, L. Shen, L.H. Hehman, M. Feng, M.Ghassemi, B. Moody, P. Szolovits, L.A. Celi, and R.G. Mark. Mimic-iii, a freely accessible critical care database. 3 (may. 2016), 2016. URLhttps://doi.org/10.1038/sdata.2016.35
-
[8]
Kidwell and Daniel Almirall
Kelley M. Kidwell and Daniel Almirall. Sequential, multiple assignment, randomized trial designs.JAMA, 329:336–337, 2023
2023
-
[9]
Komorowski, L.A
M. Komorowski, L.A. Celi, O. Badawi, A.C. Gordon, and A.A. Faisal. The artificial intelligence clinician learns optimal treatment strategies for sepsis in intensive care.Nature Medicine, 24: 1716–1720, 2018
2018
-
[10]
Kravitz, Naihua Duan, and Joel Braslow
Richard L. Kravitz, Naihua Duan, and Joel Braslow. Evidence-based medicine, heterogeneity of treatment effects, and the trouble with averages.The Milbank Quarterly, 82:661–687, 2004
2004
-
[11]
Kumar, A
A. Kumar, A. Zhou, G. Tucker, and S. Levine. Conservative q-learning for offline reinforcement learning.Proceedings of the 34th International Conference on Neural Information Processing Systems, 33:1179–1191, 2020. 10
2020
-
[12]
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020
Pith/arXiv arXiv 2005
-
[14]
Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602, 2013
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602, 2013
Pith/arXiv arXiv 2013
-
[15]
Susan A. Murphy. An experimental design for the development of adaptive treatment strategies. Statistics in Medicine, 24:1455–1481, 2005
2005
-
[16]
Lagrangian duality in reinforcement learning.arXiv preprint arXiv:2007.09998,
Pranay Pasula. Lagrangian duality in reinforcement learning.arXiv preprint arXiv:2007.09998,
arXiv 2007
-
[17]
URLhttps://arxiv.org/abs/2007.09998
doi: 10.48550/arXiv.2007.09998. URLhttps://arxiv.org/abs/2007.09998
-
[18]
Fazlic, Alexander Schmeink, Gerd Ascheid, Christian Thiemermann, Andreas Schuppert, Richard Kin- dle, Leo Celi, Gernot Marx, and Lukas Martin
Alexander Peine, Ahmed Hallawa, Johannes Bickenbach, Gerrit Dartmann, Lejla B. Fazlic, Alexander Schmeink, Gerd Ascheid, Christian Thiemermann, Andreas Schuppert, Richard Kin- dle, Leo Celi, Gernot Marx, and Lukas Martin. Development and validation of a reinforcement learning algorithm to dynamically optimize mechanical ventilation in critical care.npj Di...
2021
-
[19]
Prudencio, Marcos R
Rafael F. Prudencio, Marcos R. O. A. Maximo, and Esther L. Colombini. A survey on offline reinforcement learning: Taxonomy, review, and open problems.IEEE Transactions on Neural Networks and Learning Systems, pages 1–20, 2023
2023
-
[20]
Continuous state-space models for optimal sepsis treatment: a deep reinforcement learning approach
Aniruddh Raghu, Matthieu Komorowski, Leo Anthony Celi, Peter Szolovits, and Marzyeh Ghassemi. Continuous state-space models for optimal sepsis treatment: a deep reinforcement learning approach. InProceedings of the 2nd Machine Learning for Healthcare Conference, volume 68 ofProceedings of Machine Learning Research, pages 147–163. PMLR, 2017
2017
-
[21]
M. Raissi, P. Perdikaris, and G.E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019. doi: https: //doi.org/10.1016/j.jcp.2018.10.045
-
[22]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InProceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 1889–1897. PMLR, 07–09 Jul 2015
2015
-
[23]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. doi: 10.48550/arXiv. 1707.06347. URLhttps://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2017
-
[24]
Shortreed, Eric Laber, Daniel J
Susan M. Shortreed, Eric Laber, Daniel J. Lizotte, T. Scott Stroup, Joelle Pineau, and Susan A. Murphy. Informing sequential clinical decision-making through reinforcement learning: An empirical study.Machine Learning, 84:109–136, 2011
2011
-
[25]
Philip S. Thomas and Emma Brunskill. Data-efficient off-policy policy evaluation for reinforce- ment learning.arXiv preprint arXiv:1604.00923, 2016
Pith/arXiv arXiv 2016
-
[26]
When to sense and control? a time-adaptive approach for continuous-time rl.Proceedings of the 36th Advances in Neural Information Processing Systems, 2024
Lenart Treven, Bhavya Sukhija, Yarden As, Florian Dörfler, and Andreas Krause. When to sense and control? a time-adaptive approach for continuous-time rl.Proceedings of the 36th Advances in Neural Information Processing Systems, 2024
2024
-
[27]
Aysın Tumay, Sophia Sun, Sonia Fereidooni, Aaron Dumas, Elise Jortberg, and Rose Yu. Guardian-regularized safe offline reinforcement learning for smart weaning of mechanical circulatory devices.arXiv preprint arXiv:2511.06111, 2025. doi: 10.48550/arXiv.2511.06111
-
[28]
A review of off-policy evaluation in reinforcement learning, 2022
Masatoshi Uehara, Chengchun Shi, and Nathan Kallus. A review of off-policy evaluation in reinforcement learning, 2022. Review paper. 11
2022
-
[29]
Christoph V oloshin, Hoang M. Le, Nan Jiang, and Yisong Yue. Empirical study of off-policy policy evaluation for reinforcement learning.arXiv preprint arXiv:1911.06854, 2021
arXiv 1911
-
[30]
Ran Xu and et al. Medagentgym: A scalable agentic training environment for code-centric reasoning in biomedical data science.Proceedings of The Fourteenth International Conference on Learning Representations, 2026
2026
-
[31]
Offline guarded safe reinforcement learning for medical treatment optimization strategies.Proceedings of the 39th Advances in Neural Information Processing Systems, 2025
Runze Yan*, Xun Shen*, Akifumi Wachi, Sebastien Gros, Anni Zhao, and Xiao Hu. Offline guarded safe reinforcement learning for medical treatment optimization strategies.Proceedings of the 39th Advances in Neural Information Processing Systems, 2025
2025
-
[32]
Reinforcement learning in healthcare: A survey.ACM Computing Surveys, 55:5:1–5:36, 2021
Chao Yu, Jiming Liu, Shamim Nemati, and Guosheng Yin. Reinforcement learning in healthcare: A survey.ACM Computing Surveys, 55:5:1–5:36, 2021
2021
-
[33]
Continuous-time decision transformer for healthcare applications
Zhihao Zhang, Haowei Mei, and Yang Xu. Continuous-time decision transformer for healthcare applications. InProceedings of The 26th International Conference on Artificial Intelligence and Statistics, pages 6245–6262. PMLR, 2023. 12 A Limitations MedGymhas several limitations that should be taken into account when interpreting the benchmark results. First, ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.