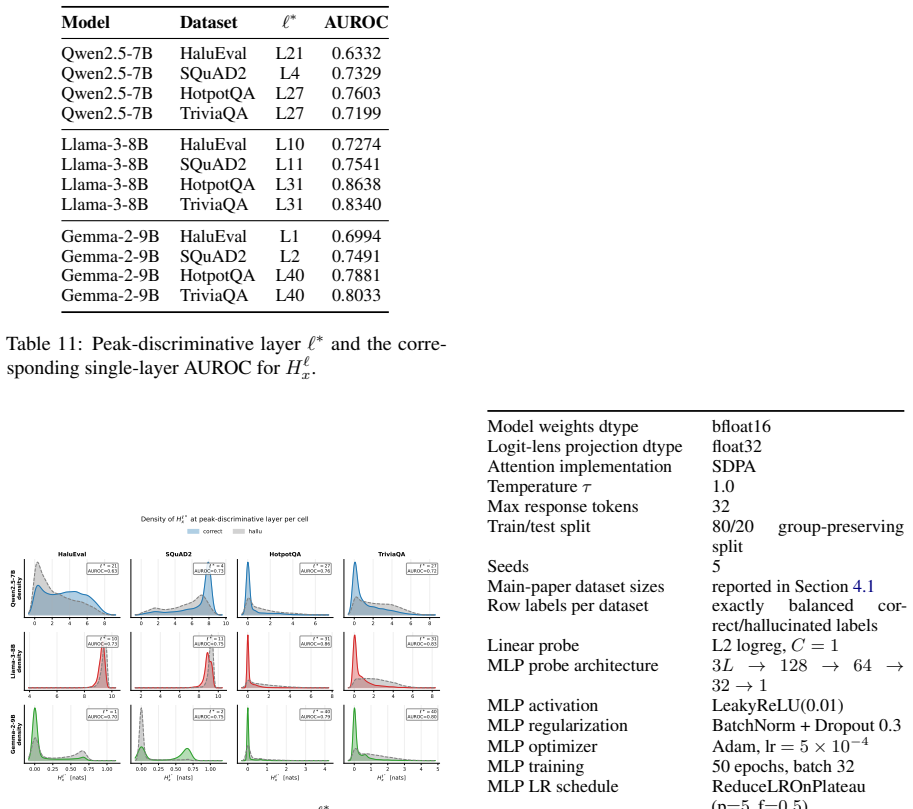
TriLens: Per-Layer Logit-Lens Entropy for White-Box Hallucination Detection
Pith reviewed 2026-06-28 17:21 UTC · model grok-4.3
The pith
TriLens detects hallucinations by tracking entropy trajectories from three module readouts per layer via the logit lens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
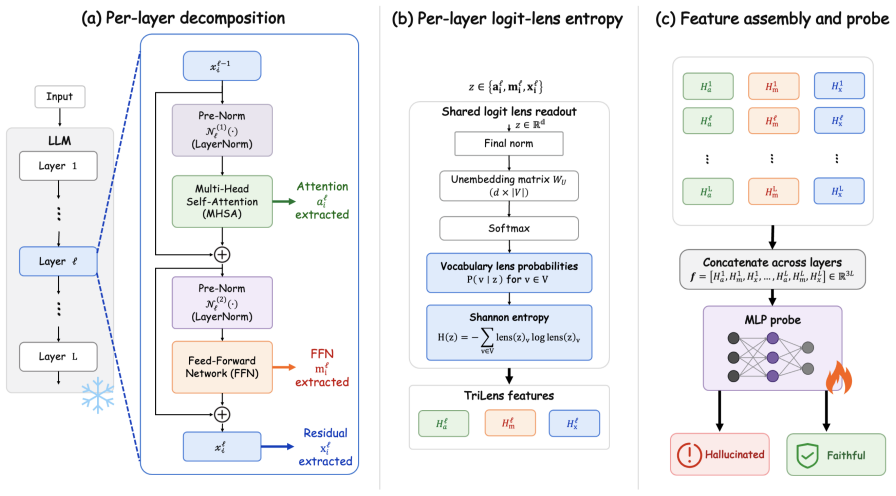
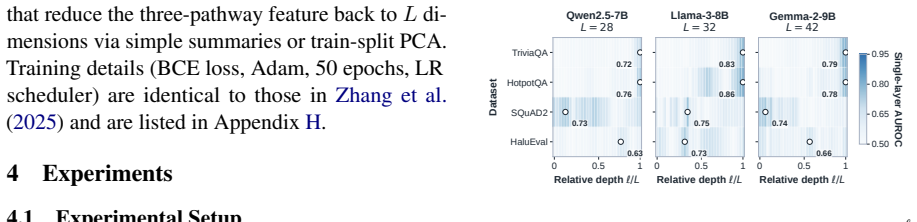
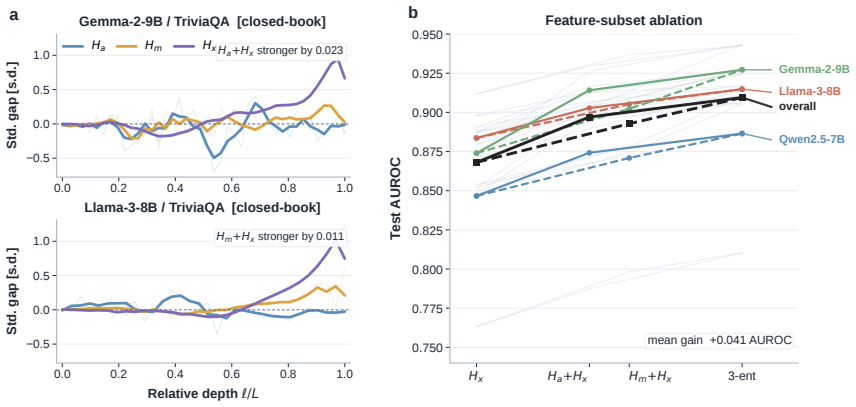
At every layer the model reads its own multi-head self-attention output, feed-forward output, and residual stream through the logit lens and records the entropy of each readout; the resulting 3L-dimensional entropy trajectory distinguishes hallucinated from non-hallucinated answers because the three module-wise trajectories supply complementary evidence about how certainty forms across depth.
What carries the argument
The 3L-dimensional entropy trajectory assembled from per-layer logit-lens readouts of the attention, feed-forward, and residual modules, which tracks how certainty settles without high-dimensional storage or repeated sampling.
If this is right
- Hallucination detection becomes possible from a compact internal signal rather than final-token probabilities alone.
- The three separate trajectories supply non-redundant information about uncertainty at different computational stages.
- No additional forward passes or token sampling are required beyond the single forward pass already used to generate the answer.
- The approach applies uniformly to multiple instruction-tuned LLMs and standard QA benchmarks.
Where Pith is reading between the lines
- Monitoring internal entropy formation could locate the layers where a hallucination first becomes likely.
- The same readout pattern might be adapted to flag other forms of internal inconsistency, such as factual contradictions that appear midway through generation.
- If the trajectories prove stable, they could serve as a lightweight monitoring signal during deployment without retraining the base model.
Load-bearing premise
The entropy values from the three per-layer readouts correlate with the presence of hallucinations in a way that holds for new models and new question sets rather than reflecting only the particular training data or evaluation choices used.
What would settle it
A test set of QA examples where the 3L entropy vectors show no statistically reliable difference between cases the model answers correctly and cases it hallucinates.
Figures


read the original abstract
When a language model hallucinates, the final answer is wrong, but the mistake is not necessarily invisible inside the model. Different internal pathways may remain uncertain, disagree in how quickly they sharpen, or commit to competing continuations before the output is produced. We introduce TriLens, a white-box detector that turns this intuition into a compact representation: at every layer, it reads the multi-head self-attention output, the feed-forward output, and the residual stream through the model's own logit lens, then records only the entropy of each readout. The resulting 3L-dimensional trajectory describes how certainty forms across depth and across modules, without storing high-dimensional hidden states or sampling multiple generations. This simple signal yields a strong detector across instruction-tuned LLMs and QA benchmarks, and our analyses show that the three module-wise entropy trajectories provide complementary evidence. TriLens suggests that hallucination detection can benefit from tracking how internal computation settles, not only what the final layer predicts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TriLens, a white-box hallucination detector that, at each layer, projects the multi-head self-attention output, feed-forward output, and residual stream through the model's logit lens and records only the entropy of each readout. The resulting 3L-dimensional entropy trajectory is claimed to form a strong detector for hallucinations across instruction-tuned LLMs and QA benchmarks, with the three module-wise trajectories supplying complementary evidence.
Significance. If the empirical results hold, the method supplies an efficient, storage-light white-box signal that tracks how certainty forms across depth and modules without multiple generations or high-dimensional hidden states. This could meaningfully advance practical hallucination detection by focusing on internal settling dynamics rather than final-layer predictions alone.
major comments (2)
- [Abstract] Abstract: the central claim that the 3L-dimensional entropy trajectory 'yields a strong detector across instruction-tuned LLMs and QA benchmarks' is asserted without any reported model identities, benchmark identities, detector construction details (supervised vs. unsupervised), baseline comparisons, or statistical significance tests; these omissions are load-bearing for evaluating whether the correlation generalizes or is driven by dataset artifacts or post-hoc choices.
- [Abstract] Abstract: no information is supplied on controls for potential confounds (e.g., whether entropy trajectories remain predictive after accounting for output length, token frequency, or dataset-specific patterns), which directly affects the assertion that the three module-wise trajectories provide complementary evidence independent of such factors.
minor comments (1)
- [Abstract] Abstract: the phrase 'without storing high-dimensional hidden states or sampling multiple generations' could be clarified by noting the exact memory or compute savings relative to common alternatives such as hidden-state probing or self-consistency sampling.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying areas where the abstract requires greater precision to support its claims. We address each point below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the 3L-dimensional entropy trajectory 'yields a strong detector across instruction-tuned LLMs and QA benchmarks' is asserted without any reported model identities, benchmark identities, detector construction details (supervised vs. unsupervised), baseline comparisons, or statistical significance tests; these omissions are load-bearing for evaluating whether the correlation generalizes or is driven by dataset artifacts or post-hoc choices.
Authors: We agree that the abstract should supply these concrete details so readers can immediately evaluate scope and robustness. In the revised manuscript we will expand the abstract to name the models (Llama-2-7B-chat, Mistral-7B-Instruct-v0.2), benchmarks (TruthfulQA, Natural Questions, HotpotQA), state that the detector is unsupervised (entropy trajectories fed to a lightweight logistic regressor or threshold), list the main baselines (final-layer entropy, perplexity, and self-consistency), and report statistical significance (paired t-tests and AUC confidence intervals). These elements already appear in Sections 4 and 5; we will simply surface them in the abstract as well. revision: yes
-
Referee: [Abstract] Abstract: no information is supplied on controls for potential confounds (e.g., whether entropy trajectories remain predictive after accounting for output length, token frequency, or dataset-specific patterns), which directly affects the assertion that the three module-wise trajectories provide complementary evidence independent of such factors.
Authors: We accept that the abstract must address this concern. The main text already contains regression-based controls and stratified analyses showing that module-wise entropy trajectories retain predictive power after accounting for length and frequency; however, the abstract does not mention these controls. We will revise the abstract to include a brief qualifier that the reported complementarity holds after partialling out output length and token frequency. Should the referee consider the existing controls insufficient, we are prepared to add further experiments during revision. revision: yes
Circularity Check
No circularity; empirical detector with no derivations reducing to inputs
full rationale
The paper presents TriLens as an empirical method that computes entropy on per-layer logit-lens readouts from three module types and uses the resulting 3L trajectory as a hallucination detector. No equations, first-principles derivations, or predictions are shown that reduce the claimed detector to fitted parameters, self-definitions, or self-citation chains. The central claim is supported by empirical measurement across models and benchmarks rather than any construction that is tautological by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhang, Zhenliang and Hu, Xinyu and Zhang, Huixuan and Zhang, Junzhe and Wan, Xiaojun , booktitle =
-
[2]
The Internal State of an LLM Knows When It`s Lying
Azaria, Amos and Mitchell, Tom , editor =. The Internal State of an. Findings of the Association for Computational Linguistics: EMNLP 2023 , month = dec, year =. doi:10.18653/v1/2023.findings-emnlp.68 , pages =
-
[3]
ArXiv , year =
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs , author =. ArXiv , year =
-
[4]
The Twelfth International Conference on Learning Representations , year =
INSIDE: LLMs' Internal States Retain the Power of Hallucination Detection , author =. The Twelfth International Conference on Learning Representations , year =
-
[5]
Advances in Neural Information Processing Systems , doi =
LLM-Check: Investigating Detection of Hallucinations in Large Language Models , author =. Advances in Neural Information Processing Systems , doi =
-
[6]
CH-Wang, Sky and Van Durme, Benjamin and Eisner, Jason and Kedzie, Chris , editor =. Do Androids Know They. Findings of the Association for Computational Linguistics: ACL 2024 , month = aug, year =. doi:10.18653/v1/2024.findings-acl.260 , pages =
-
[7]
The Twelfth International Conference on Learning Representations , year =
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models , author =. The Twelfth International Conference on Learning Representations , year =
-
[8]
Interpreting
nostalgebraist , year =. Interpreting
-
[9]
arXiv preprint arXiv:2303.08112 , year =
Eliciting latent predictions from transformers with the tuned lens , author =. arXiv preprint arXiv:2303.08112 , year =
-
[10]
Transformer Feed-Forward Layers Are Key-Value Memories
Transformer Feed-Forward Layers Are Key-Value Memories , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2021.emnlp-main.446 , pages =
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[11]
Dissecting Recall of Factual Associations in Auto-Regressive Language Models , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month = dec, year =. doi:10.18653/v1/2023.emnlp-main.751 , pages =
-
[12]
2021 , journal =
A Mathematical Framework for Transformer Circuits , author =. 2021 , journal =
2021
-
[13]
A Mechanistic Interpretation of Arithmetic Reasoning in Language Models using Causal Mediation Analysis , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month = dec, year =. doi:10.18653/v1/2023.emnlp-main.435 , pages =
-
[14]
ACM computing surveys , volume =
Survey of hallucination in natural language generation , author =. ACM computing surveys , volume =. 2023 , publisher =
2023
-
[15]
Manakul, Potsawee and Liusie, Adian and Gales, Mark , editor =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month = dec, year =. doi:10.18653/v1/2023.emnlp-main.557 , pages =
-
[16]
Halueval: A large-scale hallucination evaluation benchmark for large language models
Li, Junyi and Cheng, Xiaoxue and Zhao, Xin and Nie, Jian-Yun and Wen, Ji-Rong , editor =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month = dec, year =. doi:10.18653/v1/2023.emnlp-main.397 , pages =
-
[17]
Know what you don’t know: Unanswerable questions for SQuAD
Rajpurkar, Pranav and Jia, Robin and Liang, Percy , editor =. Know What You Don. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , month = jul, year =. doi:10.18653/v1/P18-2124 , pages =
-
[18]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke , editor =. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, year =. doi:10.18653/v1/P17-1147 , pages =
-
[19]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. , editor =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , month = oct #. 2018 , address =. doi:10.18653/v1/D18-1259 , pages =
-
[20]
ArXiv , year =
Qwen2.5 Technical Report , author =. ArXiv , year =
-
[21]
arXiv preprint arXiv:2407.21783 , year =
The llama 3 herd of models , author =. arXiv preprint arXiv:2407.21783 , year =
-
[22]
arXiv preprint arXiv:2408.00118 , year =
Gemma 2: Improving open language models at a practical size , author =. arXiv preprint arXiv:2408.00118 , year =
-
[23]
International Conference on Learning Representations , volume =
Redeep: Detecting hallucination in retrieval-augmented generation via mechanistic interpretability , author =. International Conference on Learning Representations , volume =
-
[24]
arXiv preprint arXiv:2209.15558 , year =
Out-of-distribution detection and selective generation for conditional language models , author =. arXiv preprint arXiv:2209.15558 , year =
-
[25]
arXiv preprint arXiv:2002.07650 , year =
Uncertainty estimation in autoregressive structured prediction , author =. arXiv preprint arXiv:2002.07650 , year =
arXiv 2002
-
[26]
arXiv preprint arXiv:2302.09664 , year =
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author =. arXiv preprint arXiv:2302.09664 , year =
-
[27]
Nature , year =
Detecting hallucinations in large language models using semantic entropy , author =. Nature , year =
-
[28]
arXiv preprint arXiv:2207.05221 , year =
Language models (mostly) know what they know , author =. arXiv preprint arXiv:2207.05221 , year =
-
[29]
Embedding and Gradient Say Wrong: A White-Box Method for Hallucination Detection , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2024.emnlp-main.116 , pages =
-
[30]
arXiv preprint arXiv:2502.16570 , year =
Entropy-lens: The information signature of transformer computations , author =. arXiv preprint arXiv:2502.16570 , year =
-
[31]
Findings of the Association for Computational Linguistics: ACL 2025 , pages =
Beyond semantic entropy: Boosting LLM uncertainty quantification with pairwise semantic similarity , author =. Findings of the Association for Computational Linguistics: ACL 2025 , pages =
2025
-
[32]
arXiv preprint arXiv:2602.02888 , year =
HALT: Hallucination Assessment via Log-probs as Time series , author =. arXiv preprint arXiv:2602.02888 , year =
-
[33]
arXiv preprint arXiv:2504.03579 , year =
Hallucination Detection on a Budget: Efficient Bayesian Estimation of Semantic Entropy , author =. arXiv preprint arXiv:2504.03579 , year =
-
[34]
F act S elf C heck: Fact-Level Black-Box Hallucination Detection for LLM s
Sawczyn, Albert and Binkowski, Jakub and Janiak, Denis and Gabrys, Bogdan and Kajdanowicz, Tomasz Jan , editor =. Findings of the. 2026 , address =. doi:10.18653/v1/2026.findings-eacl.296 , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.