Ask4VG: Risk-Aware Question Selection for Reducing Prior-Driven Answers in Medical VQA
Pith reviewed 2026-06-28 17:19 UTC · model grok-4.3
The pith
Four-way counterfactual image probes let a risk estimator rerank medical VQA questions to cut prior-driven answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
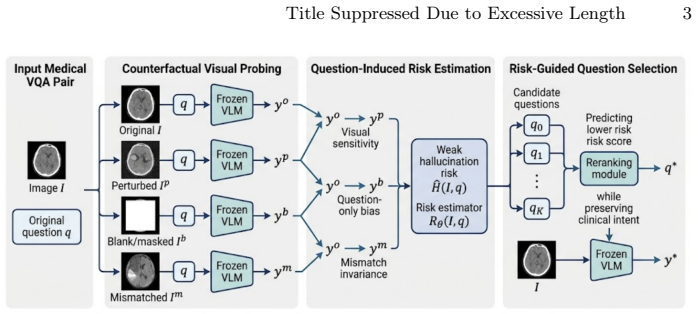
The paper establishes that counterfactual visual probing of a question (original image, perturbed image, blank image, mismatched image) supplies usable weak labels for a risk estimator; once trained, the estimator reranks question rewrites to favor those less invariant to missing or mismatched visual evidence, thereby lowering measured hallucination risk and raising exact-match accuracy on held-out medical VQA data.
What carries the argument
The counterfactual risk estimator that converts answer relations across the four probing conditions into a scalar risk score used for reranking candidate question rewrites.
If this is right
- Prompt-only rewriting without risk reranking increases counterfactual risk, so selection must be risk-aware.
- Question selection can be used as a complement to response-level hallucination mitigation techniques.
- The method requires no additional labeled data beyond the four-way probes on existing images.
- The same risk signal can be applied at inference time to choose among multiple question formulations.
Where Pith is reading between the lines
- The probing pattern may generalize to non-medical VQA domains where shortcut learning from question templates is common.
- If the risk estimator can be made lightweight, it could be inserted into interactive medical QA systems to flag high-risk questions before they reach the clinician.
- Extending the probes to additional image perturbations (e.g., color shifts, region masking) could tighten the risk signal without new annotations.
Load-bearing premise
The four probing conditions produce answer relations that serve as valid weak supervision for risk without injecting label noise that would invalidate the downstream risk reduction.
What would settle it
On a fresh medical VQA test set, applying the same reranking procedure either raises the measured held-out risk or lowers exact accuracy relative to the unreranked baseline.
Figures
read the original abstract
Medical visual question answering requires models to ground their responses in image evidence, because visually unsupported answers can mislead downstream interpretation. However, many medical VQA questions are generic, template-like, or highly similar in form, which can encourage models to learn question-answer shortcuts instead of image-dependent reasoning and thereby increase the risk of hallucinated responses. We propose Ask4VG, a label-free pilot framework for risk-aware question selection. Ask4VG estimates question-induced hallucination risk through counterfactual visual probing: the same question is asked under the original image, a perturbed image, a blank image, and a mismatched image, and the resulting answer relations are converted into weak supervision for a counterfactual risk estimator. The learned estimator then reranks candidate question rewrites to favor intent-preserving questions that are less invariant to missing or mismatched visual evidence before final answer generation. On VQA-RAD with Qwen2-VL-2B-Instruct, prompt-only rewriting increases counterfactual risk, whereas predicted-risk reranking reduces held-out risk from 0.658 to 0.623 and improves exact accuracy from 0.337 to 0.356. A 300-sample PMC-VQA external check shows the same direction of risk reduction with a small accuracy gain. These results suggest that question selection is a promising complement to response-level hallucination mitigation for reliable medical VQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Ask4VG, a label-free framework for risk-aware question selection in medical VQA to mitigate prior-driven answers and hallucinations. It uses four-way counterfactual visual probing (original, perturbed, blank, and mismatched images) to derive weak supervision signals for training a risk estimator, which then reranks candidate question rewrites to favor those less invariant to visual evidence. On VQA-RAD with Qwen2-VL-2B-Instruct, the method reduces held-out risk from 0.658 to 0.623 while improving exact-match accuracy from 0.337 to 0.356; a 300-sample PMC-VQA check shows directional consistency.
Significance. If the weak-supervision signal from counterfactual probing generalizes reliably, the approach provides a useful pre-generation complement to response-level hallucination mitigation in medical VQA. The label-free design and external PMC-VQA validation are positive features, and the concrete before/after metrics allow direct assessment. The observed deltas are modest, however, so the practical significance would remain incremental absent stronger evidence that the estimator captures true visual grounding rather than model-specific artifacts.
major comments (3)
- [Method (counterfactual risk estimator)] The risk estimator is trained directly on answer relations produced by the same four-way probing procedure that defines the risk metric; while held-out evaluation offers some separation, this creates dependence between the supervision signal and the quantity being optimized (see the description of counterfactual risk estimation and weak-supervision construction).
- [Method / Experiments] No derivation, training objective, or architectural details are supplied for the counterfactual risk estimator, and no ablation is reported on the individual contributions of the four probe conditions (original, perturbed, blank, mismatched).
- [Experiments (VQA-RAD and PMC-VQA results)] The results lack error bars, confidence intervals, or statistical tests, and the manuscript provides no description of how intent preservation is enforced or verified during question rewriting.
minor comments (1)
- [Abstract / Experiments] Clarify the exact size and selection criteria of the 300-sample PMC-VQA subset in the abstract and main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We respond to each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Method (counterfactual risk estimator)] The risk estimator is trained directly on answer relations produced by the same four-way probing procedure that defines the risk metric; while held-out evaluation offers some separation, this creates dependence between the supervision signal and the quantity being optimized (see the description of counterfactual risk estimation and weak-supervision construction).
Authors: We acknowledge the shared probing procedure between supervision and the risk metric. The held-out split ensures that the estimator is evaluated on questions unseen during its training, providing separation at the instance level. Nevertheless, we agree that a discussion of this design choice is warranted. In the revision we will add an explicit paragraph clarifying the weak-supervision construction, the role of the held-out split, and why the dependence does not invalidate the reported risk reduction. revision: yes
-
Referee: [Method / Experiments] No derivation, training objective, or architectural details are supplied for the counterfactual risk estimator, and no ablation is reported on the individual contributions of the four probe conditions (original, perturbed, blank, mismatched).
Authors: The referee is correct that these elements were omitted from the submitted manuscript. The revised version will include (i) the mathematical derivation of the risk score from the four-way answer relations, (ii) the precise training objective and loss function used for the estimator, (iii) its input feature representation and architecture, and (iv) an ablation table isolating the contribution of each probe condition. revision: yes
-
Referee: [Experiments (VQA-RAD and PMC-VQA results)] The results lack error bars, confidence intervals, or statistical tests, and the manuscript provides no description of how intent preservation is enforced or verified during question rewriting.
Authors: We will augment the experimental section with error bars, 95% confidence intervals, and statistical significance tests (paired t-test for risk and McNemar’s test for accuracy). We will also expand the question-rewriting subsection to detail the prompt template, the mechanism used to encourage intent preservation, and the verification procedure (semantic similarity threshold plus manual review on a 50-sample subset). revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines question-induced risk via four-way counterfactual probing (original/perturbed/blank/mismatched images) and converts the resulting answer relations into weak supervision labels for training a risk estimator. This estimator is then applied to rerank question rewrites before final generation. Evaluation reports risk reduction and accuracy gains on held-out VQA-RAD questions and an external PMC-VQA sample, both measured with the same probing procedure. This is a standard train/test separation for a learned predictor rather than any self-definitional loop, fitted-input-called-prediction, or self-citation chain that reduces the central claim to its own inputs by construction. No equations, uniqueness theorems, or ansatzes are shown that force equivalence between inputs and outputs. The derivation remains self-contained against the reported external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Answer relations across original, perturbed, blank, and mismatched images constitute valid weak supervision for hallucination risk
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Agrawal, A., Batra, D., Parikh, D., Kembhavi, A.: Don’t just assume; look and answer: Overcoming priors for visual question answering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 4971–4980 (2018)
2018
-
[2]
In: Advances in Neural Information Processing Systems
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: A visual language model for few-shot learning. In: Advances in Neural Information Processing Systems. vol. 35, pp. 23716–23736 (2022)
2022
-
[3]
In: Proceedings of the IEEE International Conference on Computer Vision
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.: Vqa: Visual question answering. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 2425–2433 (2015). https://doi.org/10.1109/ICCV.2015.279
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[6]
In: Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics
Dai, W., Li, J., Li, D., Tiong, A.M.H., Zhao, J., Wang, W., Li, B., Fung, P., Hoi, S.: Plausible may not be faithful: Probing object hallucination in vision-language pre-training. In: Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. pp. 2138–2148 (2023)
2023
-
[7]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., Wu, Y., Ji, R.: MME: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the V in VQA matter: Elevating the role of image understanding in visual question an- swering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6904–6913 (2017). https://doi.org/10.1109/CVPR.2017.670
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., Manocha, D., Zhou, T.: Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[10]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Gurari, D., Li, Q., Stangl, A.J., Guo, A., Lin, C., Grauman, K., Luo, J., Bigham, J.P.: Vizwiz grand challenge: Answering visual questions from blind people. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 3608–3617 (2018). https://doi.org/10.1109/CVPR.2018.00380 10 X. Zhu et al
-
[11]
PathVQA: 30000+ Questions for Medical Visual Question Answering
He, X., Zhang, Y., Mou, L., Xing, E., Xie, P.: PathVQA: 30000+ questions for medical visual question answering. arXiv preprint arXiv:2003.10286 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[12]
Jackendoff, R.Foundations of Language: Brain, Mean- ing, Grammar, Evolution
Hudson, D.A., Manning, C.D.: GQA: A new dataset for real-world visual rea- soning and compositional question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6700–6709 (2019). https://doi.org/10.1109/CVPR.2019.00686
-
[13]
Scientific Data5, 180251 (2018).https://doi.org/10.1038/sdata.2018.251
Lau, J.J., Gayen, S., Ben Abacha, A., Demner-Fushman, D.: A dataset of clinically generated visual questions and answers about radiology images. Scientific Data5, 180251 (2018). https://doi.org/10.1038/sdata.2018.251
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., Bing, L.: Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13872–13882 (2024)
2024
-
[15]
In: Advances in Neural Information Processing Systems (2023)
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: LLaVA-Med: Training a large language-and-vision assistant for biomedicine in one day. In: Advances in Neural Information Processing Systems (2023)
2023
-
[16]
In: Proceedings of the 40th International Conference on Machine Learning
Li, J., Li, D., Savarese, S., Hoi, S.: BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: Proceedings of the 40th International Conference on Machine Learning. pp. 19730–19742 (2023)
2023
-
[17]
IEEE Transactions on Knowledge and Data Engineering37(8), 4860–4872 (2025)
Li, Q., Li, D., Nie, W., Jiao, H., Wu, Z., Liu, A.: Temporal and spatial analy- sis in early sepsis prediction via causal disentanglements. IEEE Transactions on Knowledge and Data Engineering37(8), 4860–4872 (2025)
2025
-
[18]
IEEE Transactions on Artificial Intelligence7(2), 1048–1061 (2026)
Li, Q., Liu, M., Chang, R., Nie, W., Bai, S., Liu, A.: Multilabel chest x-ray im- age classification via category disentangled causal learning. IEEE Transactions on Artificial Intelligence7(2), 1048–1061 (2026)
2026
-
[19]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hal- lucination in large vision-language models. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 292–305 (2023)
2023
-
[20]
https://doi.org/10.48550/arXiv.2102.09542,https://arxiv.org/abs/2102
Liu, B., Zhan, L.M., Xu, L., Ma, L., Yang, Y., Wu, X.M.: SLAKE: A semantically- labeled knowledge-enhanced dataset for medical visual question answering. arXiv preprint arXiv:2102.09542 (2021)
-
[21]
In: Advances in Neural Information Processing Systems (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: Advances in Neural Information Processing Systems (2023)
2023
-
[22]
Biomedical Signal Processing and Control123, 110554 (2026)
Liu, M., Li, Q., Chang, R., Xu, Z., Zhou, C., Nie, W.: Causalcompnet: Causal in- tervention meets vision-language priors for robust cxr diagnosis. Biomedical Signal Processing and Control123, 110554 (2026)
2026
-
[23]
Med-flamingo: A multimodal medical few-shot learner.arXiv preprint arXiv:2307.15189, 2023
Moor, M., Huang, Q., Wu, S., Yasunaga, M., Zakka, C., Dalmia, Y., Reis, E.P., Rajpurkar, P., Leskovec, J.: Med-flamingo: A multimodal medical few-shot learner. arXiv preprint arXiv:2307.15189 (2023)
-
[24]
In: Medical Image Computing and Computer Assisted Intervention – MICCAI 2023
Nie, W., Zhang, C., Song, D., Bai, Y., Xie, K., Liu, A.A.: Chest x-ray image classification: A causal perspective. In: Medical Image Computing and Computer Assisted Intervention – MICCAI 2023. pp. 25–35 (2023)
2023
-
[25]
In: Proceedings of the 38th International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transfer- able visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning. pp. 8748–8763 (2021)
2021
-
[26]
In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Rohrbach, A., Hendricks, L.A., Burns, K., Darrell, T., Saenko, K.: Object halluci- nation in image captioning. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 4035–4045 (2018) Title Suppressed Due to Excessive Length 11
2018
-
[27]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., Fan, Y., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J.: Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
IEEE Transactions on Medical Imaging44(8), 3476–3489 (2025)
Xu, Z., Li, Q., Nie, W., Wang, W., Liu, A.: Structure causal models and llms integration in medical visual question answering. IEEE Transactions on Medical Imaging44(8), 3476–3489 (2025)
2025
-
[29]
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering
Zhang, X., Wu, C., Zhao, Z., Lin, W., Zhang, Y., Wang, Y., Xie, W.: PMC-VQA: Visual instruction tuning for medical visual question answering. arXiv preprint arXiv:2305.10415 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.